Command Palette
Search for a command to run...
فهم ذروة الأداء في استرجاع النص إلى الفيديو: تحليل تجريبي ولغوي شامل
فهم ذروة الأداء في استرجاع النص إلى الفيديو: تحليل تجريبي ولغوي شامل
Maria-Eirini Pegia Dimitrios Stefanopoulos Björn Þór Jónsson Anastasia Moumtzidou Ilias Gialampoukidis Stefanos Vrochidis Ioannis Kompatsiaris
الملخص
تمكّن استرجاع الفيديو من النص المستخدمين من العثور على محتوى فيديو ذي صلة باستخدام استعلامات باللغة الطبيعية، وهي مهمة اكتسبت أهمية متزايدة مع التوسع السريع في فيديوهات الإنترنت. على مدار السنوات الست الماضية، أسفر البحث عن العديد من الأساليب، مثل المشفرات الثنائية (dual encoders)، والنماذج المعتمدة على الانتباه (attention-driven models)، ومنهجيات دمج الوسائط المتعددة؛ ومع ذلك، لا تزال هناك أسئلة أساسية حول سلوك النماذج، وتأثير مجموعات البيانات، وصعوبة الاستعلامات. في هذا العمل، قمنا بتقييم 14 أسلوبًا متقدمًا للاسترجاع عبر 3 مجموعات بيانات مستخدمة على نطاق واسع، ضمن إطار عمل موحد للمعالجة المسبقة والتقييم. حللنا خصائص الأوصاف النصية، بما في ذلك الطول، والوضوح، والتصنيف الدلالي، وتوازن "الحدث الحركي مقابل المشهد"، وربطنا هذه الخصائص بأداء النماذج. أظهرت نتائجنا أن الأوصاف القصيرة، الواضحة، والبسيطة، مثل تلك التي تصف أفعالًا فردية أو سمات لونية، تحقق نسبة استرجاع (recall) أعلى، في حين تظل الأحداث المعقدة، والأنشطة متعددة المراحل، أو الأوصاف الدقيقة للمشهدات تحديًا كبيرًا أمام جميع النماذج الحالية. تتميز architectures المعتمدة على الانتباه بالقدرة الأفضل على التعامل مع الاستعلامات ذات الاعتماد الزمني أو متعددة المراحل، في حين تؤدي النماذج ذات المشفرات الثنائية ونماذج دمج الوسائط المتعددة أداءً جيدًا بشكل رئيسي مع الأوصاف الأبسط أو أحادية التصنيف. يتحسن التعميم عبر مجموعات البيانات (cross-dataset generalization) مع مجموعات أوصاف أكبر وأكثر تنوعًا، لكن الأوصاف المُولَّدة (generative captions) لا تعزز دقة الاسترجاع بشكل متسق. بشكل عام، تسلط نتائجنا الضوء على العوامل الرئيسية في مجموعات البيانات، وتحديات المعايير التقييمية (benchmarks)، والتفاعل بين محتوى الاستعلام وبنية النموذج، مما يقدم إرشادات لتطوير أنظمة أكثر فعالية لاسترجاع الفيديو من النص.
One-sentence Summary
Through a comprehensive empirical and linguistic analysis evaluating fourteen state-of-the-art retrieval models across three datasets under a unified framework, this study demonstrates that attention-driven architectures outperform dual-encoder and multimodal fusion approaches on complex, temporally dependent queries, while short and semantically simple captions consistently yield higher recall across all evaluated systems.
Key Contributions
- Introduces a unified preprocessing and evaluation framework that systematically benchmarks fourteen state-of-the-art text-to-video retrieval models across three widely used datasets.
- Analyzes the correlation between query characteristics, including caption length, clarity, semantic category, and action versus scene balance, and overall retrieval performance.
- Demonstrates distinct architectural trade-offs, showing that attention-driven models excel at temporally dependent queries while dual-encoder and multimodal fusion approaches achieve higher recall on simpler, single-category captions.
Introduction
Text-to-video retrieval enables users to navigate massive video libraries using natural language, a capability that has become essential for semantic search, digital assistants, and personalized recommendation systems. Despite six years of architectural innovation, the field has stalled at a performance plateau while computational complexity continues to rise. Prior research suffers from inconsistent evaluation protocols, heavy reliance on aggregate metrics, and a fundamental lack of insight into how query difficulty, linguistic structure, and dataset composition actually drive retrieval outcomes. To address these gaps, the authors conduct a standardized evaluation of fourteen leading retrieval architectures across three major benchmarks, systematically isolating the impact of caption diversity, semantic categories, and temporal reasoning requirements. Their analysis reveals that model success hinges on query simplicity and dataset annotation quality, offering a clear framework for designing more rigorous benchmarks and next-generation retrieval systems.
Dataset

• Dataset Composition and Sources: The authors evaluate their method using three established video-text retrieval benchmarks sourced from public repositories: MSVD, MSRVTT, and LSMDC.
• Subset Details: MSVD (2012) and MSRVTT (2016) consist of short YouTube clips annotated with crowdsourced human captions. LSMDC (2015) contains movie clips from the 1990s to 2010s paired with professional audio descriptions. The LSMDC training split is filtered to 6,209 videos after removing corrupted files from the original 7,408. Each benchmark provides a fixed test set containing 1,000 queries for MSRVTT and LSMDC, and 670 queries for MSVD.
• Data Usage and Processing: The authors apply the default train and test splits provided by the original creators without modifying mixture ratios or training pipelines. To study caption diversity, they generate an extended LSMDC version by producing five additional captions per video using CLIP and Meta-Llama-3-8B-Instruct. The evaluation focuses on how models perform across different query distributions and dataset characteristics.
• Metadata Construction and Preprocessing: Textual queries are categorized into 10 semantic types using spaCy, NLTK, and sentence-transformers, with category expansions refined through Transformer similarity scores and WordNet synonyms. Queries that cannot be confidently assigned to a category are retained as unrecognized to prevent analysis noise. The authors do not implement custom cropping or frame extraction strategies, relying entirely on the original dataset preprocessing workflows and frame-splitting configurations.
Method
The authors leverage a comparative framework to analyze the relationship between textual query characteristics and video retrieval performance across multiple datasets and methods. The core of their methodology involves evaluating three distinct video retrieval architectures—LSMDC, MSVD, and MSRVTT—each representing a different model or dataset configuration. The evaluation is structured around a set of defined metrics and query difficulty classifications to assess performance under varying conditions.
Refer to the framework diagram 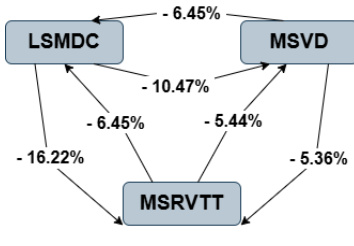 . The diagram illustrates the performance differences between the models, with percentage values indicating relative changes in retrieval performance. For instance, the MSVD model shows a 6.45% improvement over LSMDC, while MSRVTT exhibits a 16.22% improvement over LSMDC. These metrics are derived from the average ground-truth index of retrieved videos, which is used to define query difficulty. Queries are categorized into three levels based on their average rank: easy (rank < 200), medium (rank 401–600), and hard (rank > 800). This categorization enables a granular analysis of how each model handles queries of differing difficulty.
. The diagram illustrates the performance differences between the models, with percentage values indicating relative changes in retrieval performance. For instance, the MSVD model shows a 6.45% improvement over LSMDC, while MSRVTT exhibits a 16.22% improvement over LSMDC. These metrics are derived from the average ground-truth index of retrieved videos, which is used to define query difficulty. Queries are categorized into three levels based on their average rank: easy (rank < 200), medium (rank 401–600), and hard (rank > 800). This categorization enables a granular analysis of how each model handles queries of differing difficulty.
As shown in the figure below: 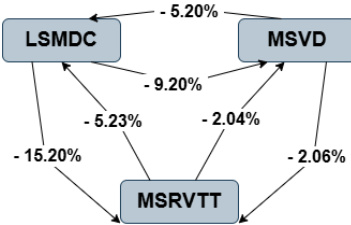 , the performance disparities among the models are further highlighted. The MSVD model again shows a 5.20% improvement over LSMDC, while MSRVTT demonstrates a 15.20% improvement. These differences are quantified through the relative performance gaps, which reflect the effectiveness of each model in retrieving relevant videos based on textual queries. The framework provides a systematic approach to understanding the impact of query composition and model architecture on retrieval outcomes.
, the performance disparities among the models are further highlighted. The MSVD model again shows a 5.20% improvement over LSMDC, while MSRVTT demonstrates a 15.20% improvement. These differences are quantified through the relative performance gaps, which reflect the effectiveness of each model in retrieving relevant videos based on textual queries. The framework provides a systematic approach to understanding the impact of query composition and model architecture on retrieval outcomes.
Experiment
This study evaluates fourteen text-to-video retrieval models across three benchmark datasets under a unified training setup to assess architectural performance, training efficiency, and data sensitivity. The experiments validate how query semantics, caption diversity, and video preprocessing directly influence retrieval outcomes, revealing that success depends more on dataset characteristics than on model architecture. Clear, medium-length queries with concrete semantics consistently perform better, while abstract descriptions remain challenging, and models trained on multi-caption datasets demonstrate substantially improved cross-dataset generalization. Furthermore, sensitivity analyses confirm that aggressive compression or low frame rates reduce computational costs at the expense of retrieval accuracy, ultimately indicating that field progress has plateaued and highlighting the need for richer datasets and architectures capable of handling complex multimodal queries.
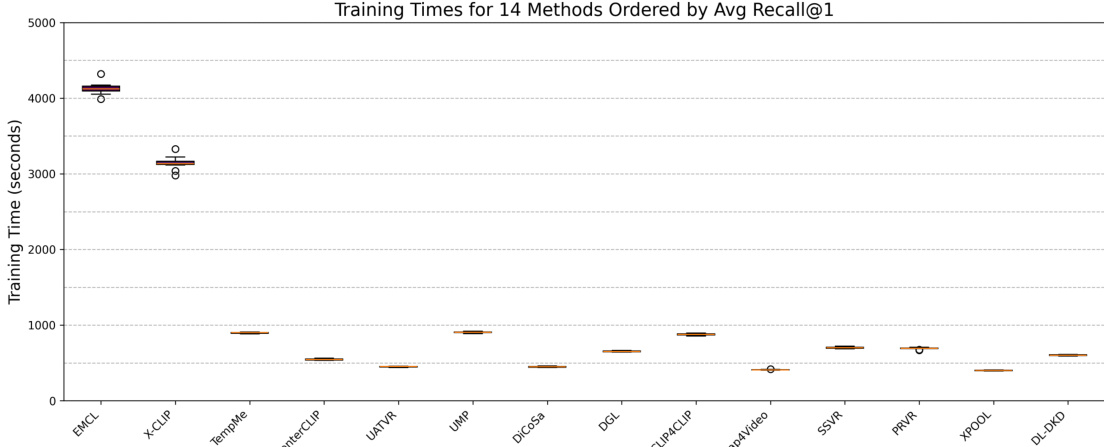
{"summary": "The authors evaluate 14 video-text retrieval methods using a consistent experimental setup across three benchmark datasets. The analysis reveals a trade-off between model performance and training efficiency, with some methods achieving high recall at the cost of significantly longer training times. The results also indicate that retrieval performance is influenced by factors such as query difficulty, caption quality, and dataset characteristics.", "highlights": ["Methods with higher average Recall@1 generally require longer training times, indicating a trade-off between performance and computational cost.", "Most methods exhibit similar training times, but a few top-performing models show substantially longer training durations.", "The evaluation highlights that model performance and efficiency are affected by dataset properties and query characteristics, not just model architecture."]
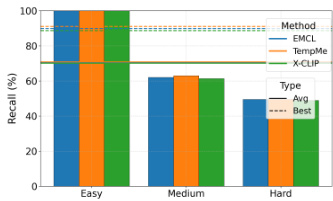
The authors analyze video-text retrieval performance across different query difficulty levels, showing that models achieve higher recall on easy queries compared to medium and hard ones. The results indicate that retrieval performance varies significantly with query difficulty, with the top-performing models demonstrating stronger performance on simpler queries. Models achieve higher recall on easy queries compared to medium and hard queries. Performance differences across difficulty levels are consistent across multiple retrieval methods. Top-performing models show stronger performance on easy queries, indicating a dependency on query simplicity.
{"summary": "The authors evaluate 14 video-text retrieval methods across three benchmark datasets, analyzing performance differences, task effects, and training efficiency under consistent settings. The study highlights that model performance is influenced by query characteristics such as length, clarity, and semantic type, as well as dataset properties like caption quantity and diversity, with datasets containing multiple captions enabling better generalization.", "highlights": ["Query characteristics such as length, clarity, and semantic type significantly affect retrieval performance, with medium-length and concrete queries performing better than complex or abstract ones.", "Datasets with multiple captions per video provide richer supervision and improve cross-dataset generalization compared to single-caption datasets.", "Top-performing models exhibit different strengths, with attention-based models handling complex queries better, while dual-encoder models perform well on simple or single-category queries."]
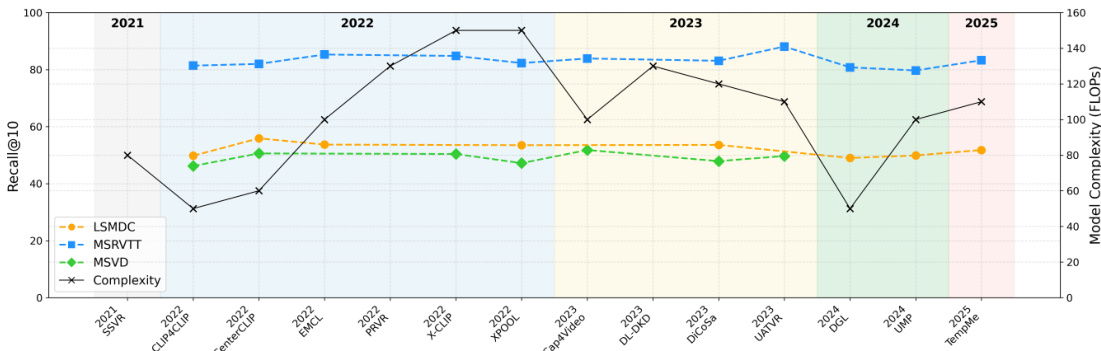
The authors analyze video-text retrieval models across multiple datasets and evaluate their performance based on recall metrics and model complexity. The results show that model performance varies significantly across datasets, with some methods achieving higher recall on certain datasets while others perform consistently. The analysis also highlights a trade-off between computational efficiency and retrieval accuracy, as more complex models tend to achieve better recall but require more training time. Performance varies across datasets, with some methods excelling on specific datasets while others maintain consistent results. There is a trade-off between model complexity and training efficiency, as more complex models achieve higher recall but require more computational resources. Model performance is influenced by dataset characteristics, including the number and quality of captions provided.
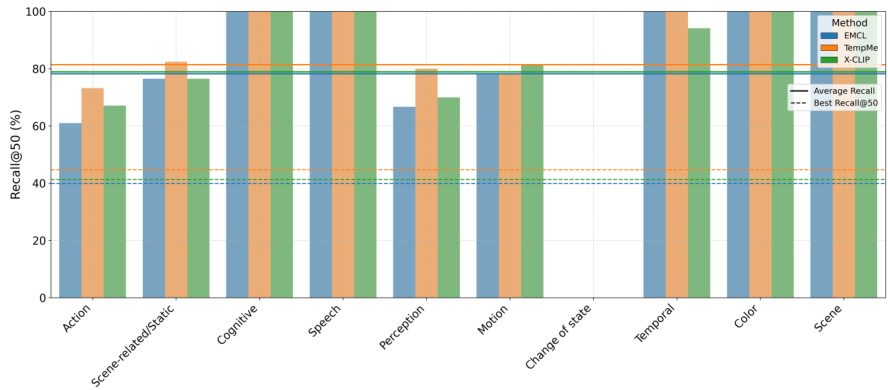
The authors analyze video-text retrieval models across different semantic categories, focusing on how query types influence performance. Results show that models achieve higher recall for concrete and simple queries such as Speech, Motion, and Color, while performance drops for more abstract or complex categories like Action and Scene-related/Static. The top-performing methods, EMCL, TempMe, and X-CLIP, exhibit varying strengths depending on the query type, with some showing consistent performance across categories and others being more sensitive to specific semantic types. Models achieve higher recall for concrete and simple query types such as Speech, Motion, and Color compared to abstract or complex categories. Performance varies significantly across semantic categories, with Action and Scene-related/Static queries being more challenging for retrieval. Top-performing methods show differing strengths across categories, indicating that model architecture influences sensitivity to query semantics.
The authors evaluate fourteen video-text retrieval methods across three benchmark datasets to assess overall performance, training efficiency, and sensitivity to input characteristics. The experiments validate that retrieval success depends heavily on query difficulty and semantic clarity, with models consistently outperforming on concrete queries compared to abstract ones, while datasets with multiple captions per video significantly improve generalization. Ultimately, the analysis reveals a clear trade-off between retrieval accuracy and computational cost, demonstrating that optimal model selection must balance architectural complexity with training efficiency and specific query demands.