Command Palette
Search for a command to run...
التعلم أثناء النشر: تعزيز تقني مدعوم بالتعلّم المعزز على نطاق الأسطول لسياسات الروبوتات الشاملة
التعلم أثناء النشر: تعزيز تقني مدعوم بالتعلّم المعزز على نطاق الأسطول لسياسات الروبوتات الشاملة
الملخص
تستفيد سياسات الروبوتات العامة (Generalist robot policies) بشكل متزايد من التدريب المسبق واسع النطاق، إلا أن البيانات غير المتصلة بالشبكة (Offline data) بمفردها لا تكفي لنشرها بشكل قوي في العالم الحقيقي. تواجه الروبوتات المُنتشرة تحديات مثل انحرافات التوزيع (Distribution shifts)، وفشل الحالات النادرة ذات الذيل الطويل (Long-tail failures)، وتباين المهام، وفرص التصحيح البشري، وهي جوانب لا يمكن لمجموعات بيانات العرض الثابتة (Fixed demonstration datasets) التقاطها بالكامل. نقدم هنا إطار عمل "التعلم أثناء النشر" (Learning While Deploying - LWD)، وهو إطار لتعلم التعزيز من البيانات غير المتصلة بالشبكة إلى المتصلة بالشبكة (Offline-to-online reinforcement learning) على نطاق الأسطول، يهدف إلى التدريب المستمر اللاحق (Continual post-training) لسياسات الرؤية واللغة والإجراء العامة (Vision-Language-Action - VLA). يبدأ LWD بسياسة VLA مُدربة مسبقاً، ويغلق الحلقة بين النشر، والخبرة الجسدية المشتركة، وتحسين السياسة، وإعادة النشر، من خلال استخدام عمليات الدوران المستقلة (Autonomous rollouts) والتدخلات البشرية التي يتم جمعها عبر أسطول من الروبوتات. ولتثبيت عملية التعلم استناداً إلى بيانات الأسطول المتجانسة ذات المكافآت المتفرقة (Heterogeneous, sparse-reward fleet data)، يجمع LWD بين "التعلم التوزيعي للقيمة الضمنية" (Distributional Implicit Value Learning - DIVL) من أجل تقدير قوي للقيمة، و"تعلم Q عبر المطابقة المرافقة" (Q-learning via Adjoint Matching - QAM) لاستخراج السياسة داخل مولدي إجراءات VLA المستنديين إلى التدفق (Flow-based VLA action generators). تم التحقق من صحة LWD باستخدام أسطول من 16 روبوتًا ذا بازوين مزدوجتين عبر ثمانية مهام манипуلة (Manipulation) في العالم الحقيقي، بما في ذلك إعادة تخزين البقالة ذات المعاني (Semantic grocery restocking) ومهام طويلة الأفق (Long-horizon tasks) تستغرق من 3 إلى 5 دقائق. تظهر سياسة عامة واحدة تحسناً مع تراكم خبرة الأسطول، حيث وصلت إلى معدل نجاح متوسط يبلغ 95٪، مع أكبر القفزات في المهام طويلة الأفق.
One-sentence Summary
Learning While Deploying (LWD) is a fleet-scale offline-to-online reinforcement learning framework for continual post-training of generalist Vision-Language-Action policies that combines Distributional Implicit Value Learning with Q-learning via Adjoint Matching to stabilize heterogeneous, sparse-reward fleet data, leveraging shared physical experience across 16 dual-arm robots to achieve an average success rate of 95% on eight real-world manipulation tasks.
Key Contributions
- Learning While Deploying (LWD) is presented as a fleet-scale offline-to-online reinforcement learning framework for continual post-training of generalist Vision-Language-Action policies. This system closes the loop between deployment and policy improvement by utilizing autonomous rollouts and human interventions collected across a robot fleet.
- To stabilize learning from heterogeneous fleet data, the method combines Distributional Implicit Value Learning (DIVL) for robust value estimation with Q-learning via Adjoint Matching (QAM) for policy extraction in flow-based VLA action generators. This approach enables stable training of generalist VLA policies across multiple real-world tasks using both offline data and online replay.
- Experiments validate the system on a fleet of 16 dual-arm robots across eight real-world manipulation tasks, including semantic grocery restocking and long-horizon tasks. The single generalist policy reaches an average success rate of 95% as fleet experience accumulates, with the largest gains on long-horizon tasks.
Introduction
Generalist robot policies rely on large-scale pretraining but struggle with real-world distribution shifts and long-tail failures that static datasets cannot capture. Prior reinforcement learning methods often limit scalability by focusing on task-specific settings or fail to stabilize learning from heterogeneous fleet data with sparse rewards. The authors present Learning While Deploying, a fleet-scale offline-to-online framework that continuously improves pretrained Vision-Language-Action policies using shared physical experience from a deployed robot fleet. Their approach combines Distributional Implicit Value Learning for robust value estimation with Q-learning via Adjoint Matching to stabilize policy extraction on flow-based generators. This system enables a single generalist policy to adapt rapidly across diverse tasks and achieve high success rates on long-horizon manipulation.
Method
The Learning While Deploying (LWD) framework formulates robot control as a Markov decision process where the policy operates on action chunks. The system is designed to bridge the gap between offline pre-training and continuous online improvement across a fleet of robots.
Overall Framework and Data Flywheel
The core philosophy of LWD is to treat deployment not just as evaluation but as a mechanism for continuous learning. As illustrated in the high-level overview, the system operates as a closed loop connecting model performance, asynchronous distribution, fleet deployment, and scalable post-training. Robots execute tasks in the real world, generating data that feeds back into the learning process. This creates a data flywheel where robot rollouts expand the replay buffer, mixed replay updates the policy, and refreshed checkpoints are redeployed to the fleet.
Offline-to-Online Training Pipeline
The training procedure is organized into two distinct stages that share the same optimization objectives but differ in their data sources. In the first stage, the policy, critic, and distributional value model are pre-trained on a static offline buffer containing demonstrations, expert trajectories, and play data. This provides a robust initialization for deployment. The second stage involves continuous online post-training. Here, the initialized policy is deployed to a fleet of robots for autonomous rollouts. These rollouts populate an online buffer with policy transitions and optional human interventions. The learner then updates the model parameters using mixed replay from both the static offline buffer and the continuously updated online buffer.
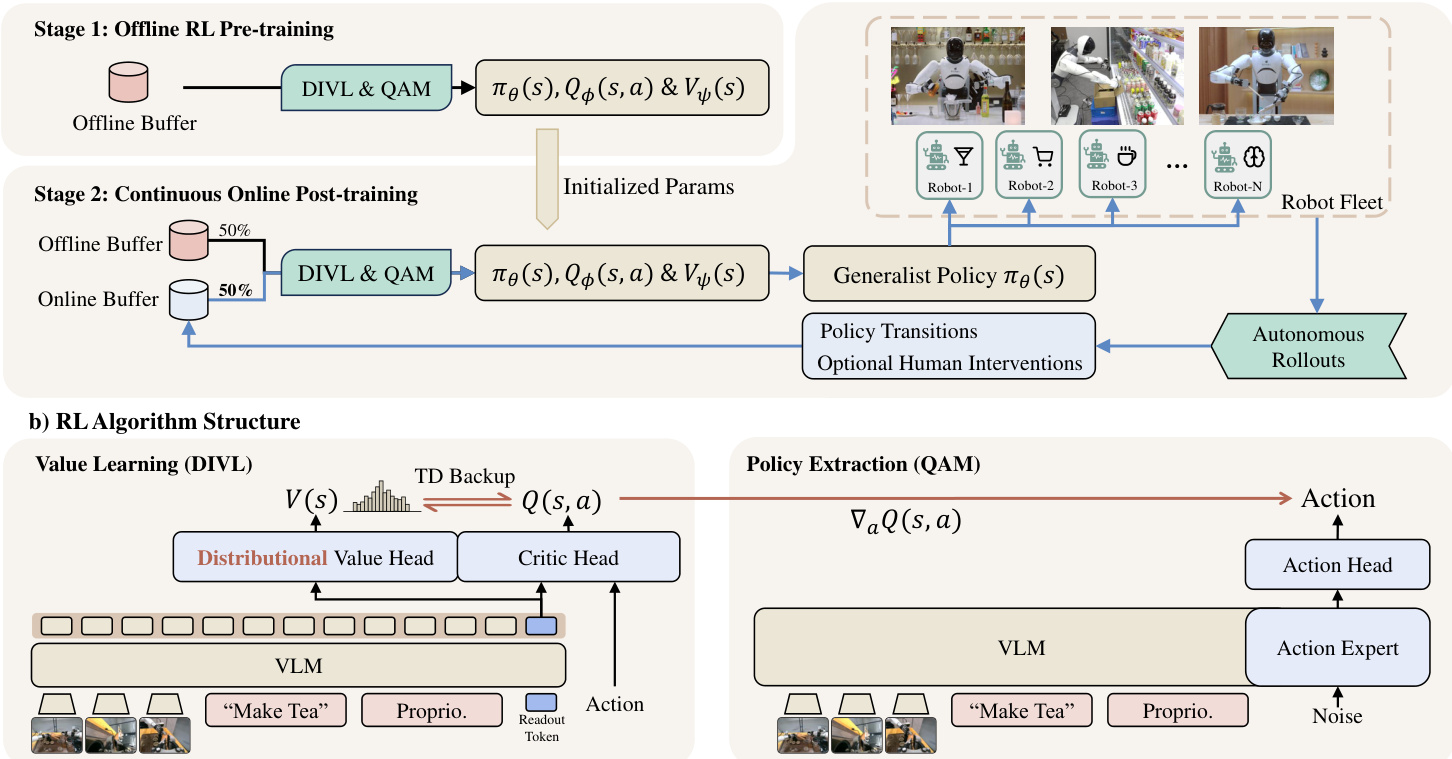
Core Algorithm Components
The algorithmic heart of LWD consists of two primary modules: Distributional Implicit Value Learning (DIVL) for value estimation and Q-learning with Adjoint Matching (QAM) for policy extraction.
DIVL replaces the scalar expectile value regression used in standard Implicit Q-Learning with a distributional value model. Instead of predicting a single scalar value, the distributional value model Vψ(s) represents the state-conditioned distribution of dataset action-values. The bootstrap target for the critic Qϕ is derived from a quantile of this distribution. This approach maintains the asymmetric bootstrap principle to favor high-value actions without extrapolating aggressively beyond the data. To handle varying levels of uncertainty in mixed-task replay, the quantile level τ is adapted based on the entropy of the learned value distribution.
For policy extraction, LWD utilizes a flow-based Vision-Language-Action (VLA) model. Direct backpropagation through the multi-step generation process of flow policies is computationally expensive and unstable. QAM addresses this by reformulating trajectory-level policy optimization into a local regression objective along the reference flow. The critic gradient from DIVL initializes the terminal adjoint state, which guides the refinement of the policy vector field.
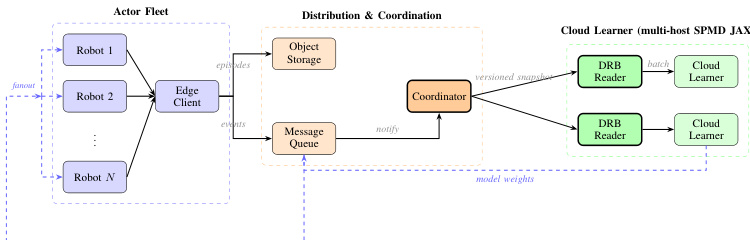
Distributed System Architecture
To support large-scale deployment, the system is architected with a clear separation between the actor fleet and the centralized learner. The actor fleet consists of multiple robots running the policy locally. These robots communicate with an edge client that handles episode storage and event notification. A coordinator manages the distribution and synchronization of model weights. On the cloud side, a multi-host SPMD JAX learner reads data from the distributed replay buffer (DRB) and performs the heavy computation required for DIVL and QAM updates. Updated model weights are then pushed back to the fleet asynchronously.
Experiment
The study evaluates LWD on eight real-world manipulation tasks using a distributed robot fleet to compare online deployment updates against static or offline policies. Results indicate that deployment-time online updates significantly improve performance, particularly on long-horizon tasks, where the learned value function successfully tracks progress despite sparse terminal rewards. Furthermore, ablation studies validate that distributional value learning and adaptive strategies drive these gains, while the distributed infrastructure ensures reliable data ingestion and policy synchronization.
The authors evaluate the proposed LWD method against several baselines across eight real-world manipulation tasks, including grocery restocking and long-horizon assembly. Results indicate that the online version of LWD achieves the highest overall performance, with significant gains observed in complex long-horizon scenarios where other methods show limited improvement. LWD with online updates attains the best average score, outperforming both static and offline policies. The method demonstrates substantial advantages on long-horizon tasks such as tea making and cocktail preparation compared to baselines. Performance remains robust on grocery restocking tasks, maintaining top-tier results even in regimes where baseline methods already achieve high success rates.

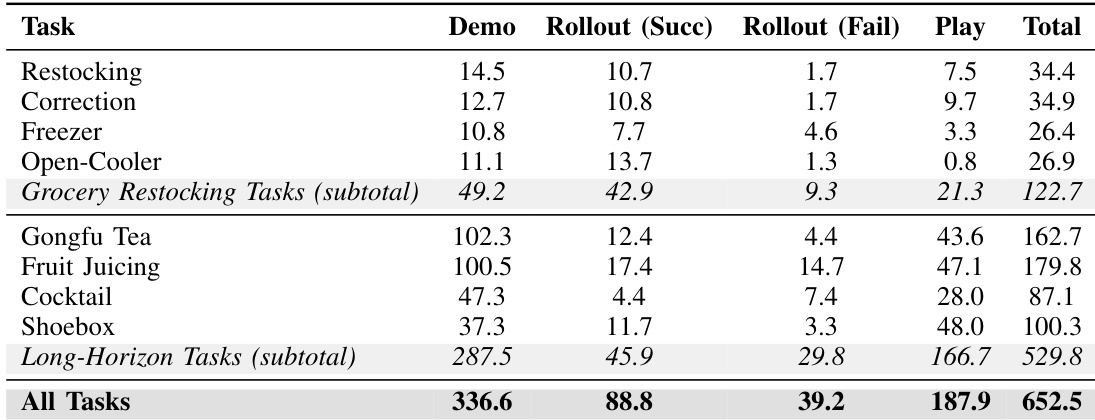
The the the table outlines the offline data composition used for training, categorizing data by task type and source including demonstrations, rollouts, and play data. Long-horizon tasks comprise the vast majority of the dataset volume due to their longer episode durations, while demonstrations provide the largest share of successful trajectories. Play data and failed rollouts constitute a significant portion of the buffer, with a higher concentration in long-horizon scenarios. Long-horizon tasks comprise the vast majority of the dataset volume compared to grocery restocking tasks. Demonstrations provide the largest share of successful trajectories, exceeding other data sources. Play data and failed rollouts are more prevalent in long-horizon tasks than in grocery restocking tasks.
The authors evaluate their proposed DIVL method against Expectile Regression across eight real-world manipulation tasks, including grocery restocking and long-horizon assembly. Results indicate that the online training setup consistently yields higher performance than offline training for both methods. Specifically, the online DIVL approach achieves the highest average scores, showing a marked improvement over the baseline on complex long-horizon tasks. Online DIVL achieves the highest average performance across all evaluated tasks. The proposed method shows significant gains over the baseline on long-horizon tasks. Both offline and online versions of DIVL outperform the Expectile Regression baseline.

The the the table quantifies the operational latency of the distributed training infrastructure, measuring the time for episodes to reach the learner and for updated policies to reach the actors. The median latency for model distribution is slightly lower than that for episode ingestion, while the 99th percentile for ingestion is substantially higher, indicating greater variance in the data upload process. Median latency for model distribution is slightly faster than for episode ingestion. The 99th percentile latency for episode availability is significantly higher than for model receipt. The 99th percentile latency for episode ingestion is more than double that of model distribution.

The authors evaluate a distributional value learning approach against a scalar expectile regression baseline to assess value estimation quality. The proposed method consistently outperforms the baseline across both short-horizon and long-horizon tasks in offline and online settings. Notably, the performance advantage is significantly more pronounced for long-horizon tasks, especially when utilizing online training data. The proposed method consistently achieves higher scores than the scalar baseline across all task horizons and training modes. Performance improvements are substantially larger for long-horizon tasks compared to short-horizon tasks. The gap between the proposed method and the baseline widens significantly during online training for complex tasks.

The authors evaluate proposed methods against baselines across eight real-world manipulation tasks, demonstrating that online training setups consistently yield superior performance compared to offline approaches. The results indicate substantial advantages for the proposed methods on complex long-horizon scenarios where baseline performance is limited, while distributional value learning further improves value estimation quality over scalar baselines. Supporting analyses confirm that long-horizon tasks dominate the dataset volume and that episode ingestion exhibits significantly higher latency variance than model distribution.