Command Palette
Search for a command to run...
استخدام التعزيز القائم على المصحح في تعديل الصور
استخدام التعزيز القائم على المصحح في تعديل الصور
Hanzhong Guo Jie Wu Jie Liu Yu Gao Zilyu Ye Linxiao Yuan Xionghui Wang Yizhou Yu Weilin Huang
الملخص
بينما أصبح التعزيز التعلم من التغذية الراجعة البشرية (RLHF) نموذجاً محورياً في مجال توليد الصور من النص، لا تزال تطبيقاته في تحرير الصور غير مستكشفة إلى حد كبير. يتمثل أحد العوائق الرئيسية في افتقارنا إلى نموذج مكافأة عام قوي يناسب جميع مهام التحرير. عادةً ما تقدم نماذج المكافأة للتحرير درجات عامة دون فحوصات تفصيلية، متجاهلة متطلبات التعليمات المختلفة، مما يؤدي إلى مكافآت متحيزة. لمعالجة هذه المشكلة، نجادل بأن المفتاح يكمن في الانتقال من مجرد مُقيِّم بسيط إلى مُحققٍ قائم على الاستدلال. نقدم إطار عمل Edit-R1، والذي يبني نموذج مكافأة استدلال (RRM) يعتمد على مُحقق سلسلة التفكير (CoT)، ثم يستغله في تحرير الصور في المهام اللاحقة. يقسم نموذج Edit-RRM التعليمات إلى مبادئ منفصلة، ويقيّم الصورة المُحررة مقابل كل مبدأ، ثم يجمع هذه الفحوصات للحصول على مكافأة قابلة للتفسير ودقيقة. لبناء مثل هذا النموذج RRM، نطبق أولاً ضبطاً دقيقاً بإشراف (SFT) كبداية باردة لتوليد مسارات مكافأة لسلسلة التفكير. ثم نقدم تحسين تفضيل التباين الجماعي (GCPO)، وهو خوارزمية تعزز التعلم من التفضيلات الزوجية البشرية لتعزيز نموذج RRM لدينا. بعد بناء نموذج RRM، نستخدم GRPO لتدريب نماذج التحرير باستخدام نموذج المكافأة هذا، وهو غير قابل للاشتقاق لكنه قوي. تُظهر التجارب الشاملة أن نموذج Edit-RRM يتفوق على نماذج VLM القوية مثل Seed-1.5-VL وSeed-1.6-VL كنموذج مكافأة متخصص في التحرير، ونلاحظ اتساقاً في تحسين الأداء مع زيادة حجم النموذج من 3B إلى 7B من المعلمات. بالإضافة إلى ذلك، يُظهر إطار Edit-R1 تحسناً ملحوظاً في نماذج التحرير مثل FLUX.1-kontext، مما يبرز فعاليته في تعزيز جودة تحرير الصور.
One-sentence Summary
The authors propose Edit-R1, a reinforcement learning framework for image editing that replaces generic reward scorers with a chain-of-thought verifier-based reasoning reward model, decomposing instructions into distinct principles for fine-grained evaluation and utilizing Group Contrastive Preference Optimization to train interpretable rewards that outperform existing vision-language models.
Key Contributions
- Edit-R1 establishes a verifier-based reasoning paradigm that transitions image editing reward modeling from holistic scoring to principle decomposition. By generating chain-of-thought analyses for each principle, the model delivers structured and interpretable feedback for diverse visual editing tasks.
- To align this reasoning model with human preferences, the method employs Group Contrastive Preference Optimization (GCPO), a reinforcement learning algorithm that contrasts groups of winning and losing trajectories. This approach refines reward alignment while circumventing the differentiability requirements and reward hacking risks inherent to prior preference optimization techniques.
- Evaluations demonstrate that the resulting 7B reward model surpasses leading vision-language models and existing baselines on EditRewardBench. When integrated into a GRPO training loop, the system yields substantial performance improvements on state-of-the-art editors including FLUX.1-kontext and Qwen-Image-Edit.
Introduction
Modern diffusion-based image editing has advanced rapidly, yet it still lags behind text-to-image generation in adopting Reinforcement Learning from Human Feedback for model alignment. Prior approaches largely rely on supervised fine-tuning and treat reward models as holistic scorers that output a single score via general-purpose vision-language models. This simplistic scoring fails to capture nuanced editing requirements such as instruction fidelity and unedited region preservation, often producing biased or hallucinated feedback. Furthermore, standard reinforcement learning algorithms struggle to optimize these models because reasoning-based reward signals are inherently non-differentiable. To overcome these hurdles, the authors introduce Edit-R1, a framework that replaces holistic scoring with a verifier-based Reasoning Reward Model. They decompose editing prompts into verifiable principles, generate structured Chain-of-Thought analyses, and train the model using a novel Group Contrastive Preference Optimization algorithm. The resulting reward model then acts as a reliable verifier within a GRPO-based reinforcement learning loop, delivering substantial performance gains for downstream image editing systems.
Dataset

- Dataset Composition and Sources: The authors construct a supervised dataset for cold-starting a Reasoning Reward Model by curating 200,000 samples from a public image-editing benchmark. This initial collection is expanded into approximately 2 million data quadruples through multi-model generation and systematic verification.
- Subset Details: The dataset is divided into two 100,000-sample subsets. The Random subset is drawn directly from the benchmark to capture a general distribution of editing tasks. The Hard subset is filtered using GPT-4o to retain only complex instructions requiring multi-step visual modifications, fine-grained detail adjustments, implicit semantic understanding, or precise spatial control, while explicitly excluding simple single-step edits.
- Data Processing and Metadata Construction: Each sample begins as a reference image paired with an edit instruction. The authors decompose these instructions into verifiable principles covering preservation, required modifications, and overall quality using the Seed-1.5-VL API. They then generate diverse edited candidates using models like Flux-Kontext, Bagel, and SeedEdit3.0 to form quadruples containing the edited image, reference image, instruction, and principle set. Vision-Language Models process these quadruples with Chain-of-Thought prompting to produce point-wise principle verification and weighted final scores. Multiple reasoning traces are generated by varying system prompts, sampling temperatures, and model variants. An external verifier re-evaluates each trace against the principles to compute accuracy, and only the highest-accuracy reasoning traces are retained.
- Usage and Training Pipeline: This curated dataset serves as the initial Supervised Fine-Tuning data to cold-start the Reasoning Reward Model. The processed quadruples, principle sets, reasoning traces, and final scores are used to train the model on accurate verification and scoring. During subsequent preference optimization, the trained reward model generates multiple thinking-score candidates per image, which are compared pairwise to compute win and loss ratios alongside weighted advantages for policy optimization.
Method
The proposed Edit-R1 framework centers on a Verifier-based Reasoning Reward Model (RRM) designed to evaluate image editing outputs with fine-grained, interpretable feedback. The overall architecture, as illustrated in the framework diagram, consists of two primary phases: a cold-start supervised fine-tuning (SFT) stage and a reinforcement learning (RL) refinement stage using a novel optimization algorithm. The RRM operates as a pointwise, generative model that evaluates an edited image against a set of decomposed principles derived from the editing instruction. This process begins with the decomposition of the instruction into distinct evaluation points, which are then used to guide the RRM's chain-of-thought (CoT) reasoning. The RRM analyzes the edited image based on these principles, generating a detailed textual justification for each evaluation and producing a final holistic score. 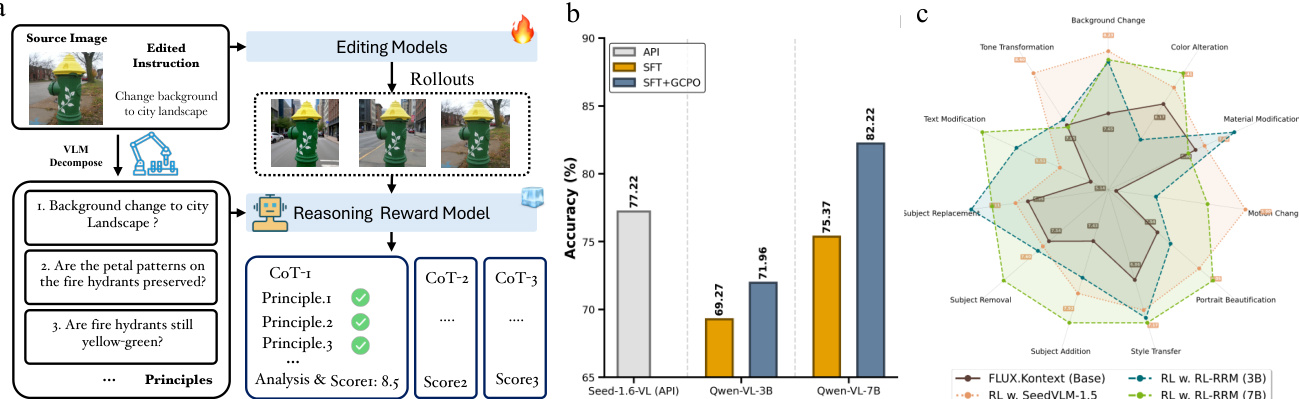
The training of the RRM is a two-stage process. The first stage, a "cold-start" SFT, constructs a large-scale dataset for initial training. This is achieved through a VLM-based verification pipeline that generates high-quality, fine-grained evaluation data. As shown in the diagram, a powerful VLM acts as a verifier to produce gold-standard judgments for each evaluation point based on the source image, edited image, instruction, and a pool of candidate CoT trajectories. A second VLM then acts as a selector to objectively choose the best-performing candidate based on these verified judgments. This process ensures the quality of the training data. The SFT phase trains the RRM to generate CoT reward trajectories, providing a rationale-based starting point for the model. 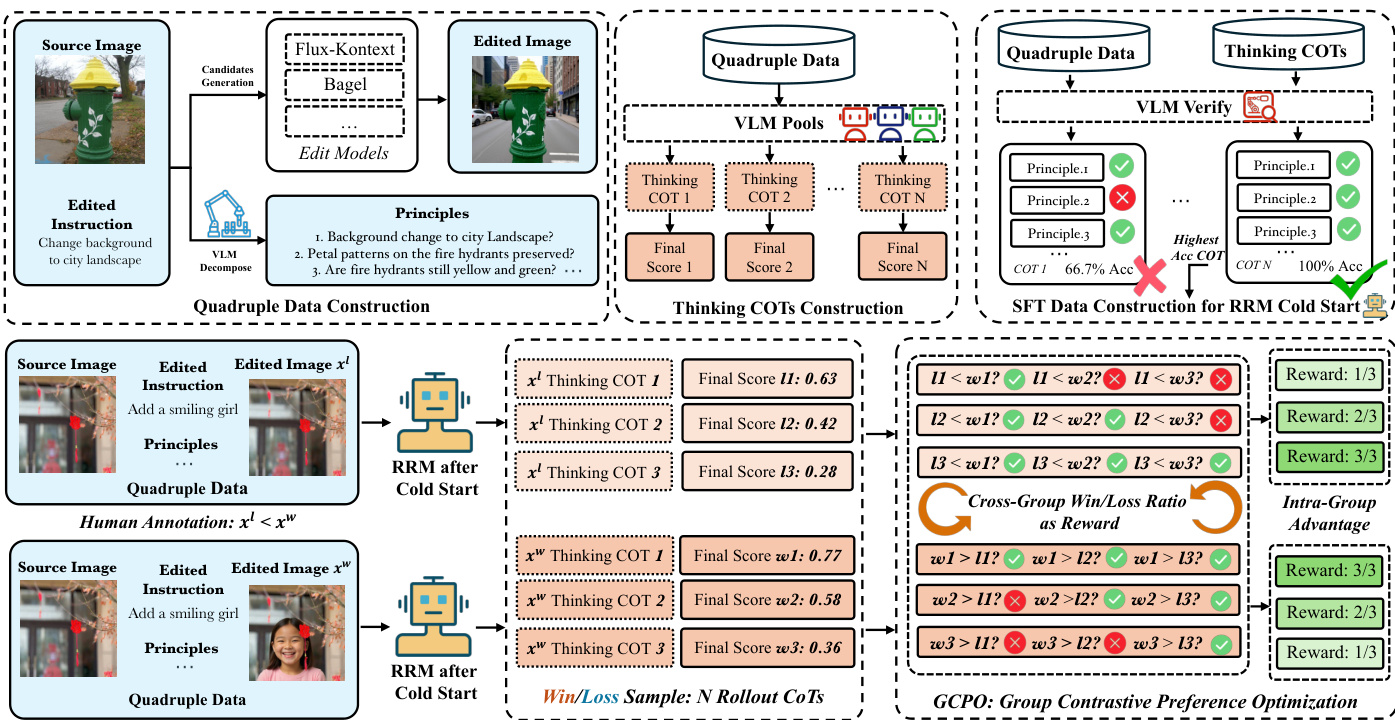
The second stage refines the RRM using human pairwise preference data through a novel reinforcement learning algorithm called Group Contrastive Preference Optimization (GCPO). This phase is necessary to align the model's judgments with human preferences. The RRM is treated as the policy being optimized, where its actions are the generated reasoning traces and final scores. A preference dataset is constructed by presenting human annotators with a source image, an instruction, and a pair of edited images, asking them to select the better image. For each preference pair, the reward model generates multiple reasoning traces and scores for each image. The win/loss ratio rewards are computed by comparing the scores from the preferred image against those from the non-preferred image, ignoring ties. The GCPO objective function then maximizes the expected advantage, calculated within each group of rollouts (preferred and non-preferred), using a clipped surrogate loss to prevent large policy updates. This allows the RRM to learn from the relative quality of outputs without requiring a single absolute score.
Finally, the trained RRM is integrated with a standard Group Relative Policy Optimization (GRPO) algorithm to train downstream image editing models. The editing model acts as the policy, generating a group of edited images for a given context. The RRM evaluates each image in the group, providing a fine-grained score. The advantage for each image is calculated by normalizing its reward against the group's mean and standard deviation. The GRPO objective maximizes the expected advantage, incorporating a clipped objective and a KL-divergence penalty to ensure stable and effective policy updates, thereby directly optimizing the editing model for human-perceived quality and instruction fidelity.
Experiment
The evaluation setup employs a curated benchmark of pairwise human preferences alongside standardized automatic metrics to assess both the reward model and optimized image editing frameworks. These experiments validate that a two-stage training pipeline combining reasoning-based data curation with preference alignment produces a stricter, more reliable evaluator that significantly improves human preference prediction. Qualitative analysis further demonstrates that optimizing editing models with this refined reward signal consistently enhances instruction adherence, visual fidelity, and feature preservation, particularly in complex editing scenarios. Ultimately, the framework effectively mitigates common hallucination and attribute leakage issues, confirming that precise reward modeling serves as a robust catalyst for high-quality image generation.
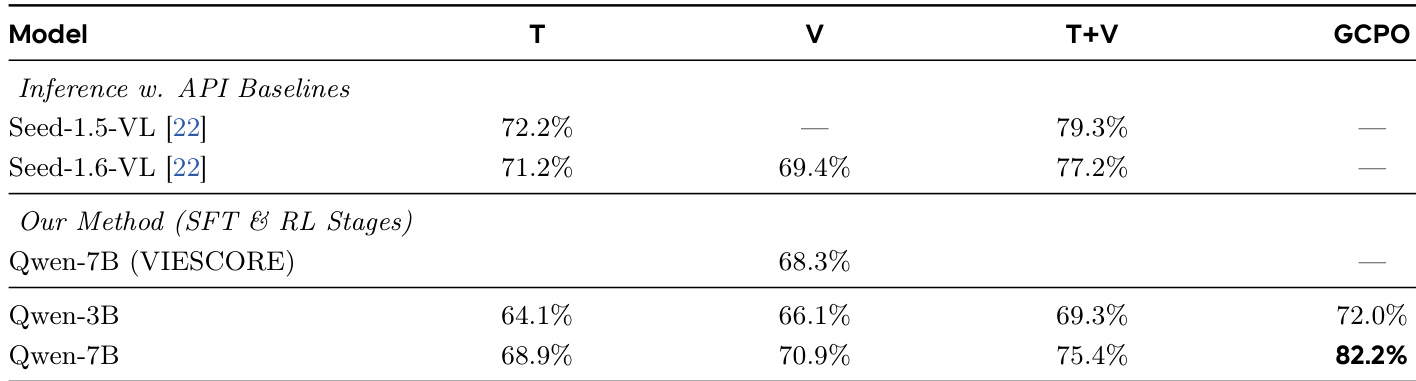
The authors evaluate their reward model training pipeline by comparing different configurations and stages. Results show that their full two-stage approach, including GCPO, achieves the highest performance, with the Qwen-7B model outperforming other variants and closed-source baselines. The training strategy emphasizes principled data curation and human alignment, leading to improved reward model accuracy. The full two-stage training pipeline with GCPO achieves the highest accuracy among all evaluated models. Qwen-7B trained with the full pipeline outperforms both smaller variants and closed-source baselines. Principled data curation and the inclusion of both reasoning and verification components significantly improve model accuracy.
The authors evaluate the performance of their reward model by optimizing the FLUX.Kontext model using their Edit-R1 framework. The results show that the optimized model achieves a significant improvement in human evaluation, as measured by the GSB score, compared to the baseline. This indicates that the reward model effectively guides the editing process to produce outputs that are preferred by humans. The optimized FLUX.Kontext model achieves a GSB score of +23.2, indicating strong human preference over the baseline. The reward model successfully guides the editing process to produce outputs that better adhere to user instructions. The improvement in human evaluation demonstrates the effectiveness of the reward model in enhancing image editing quality.

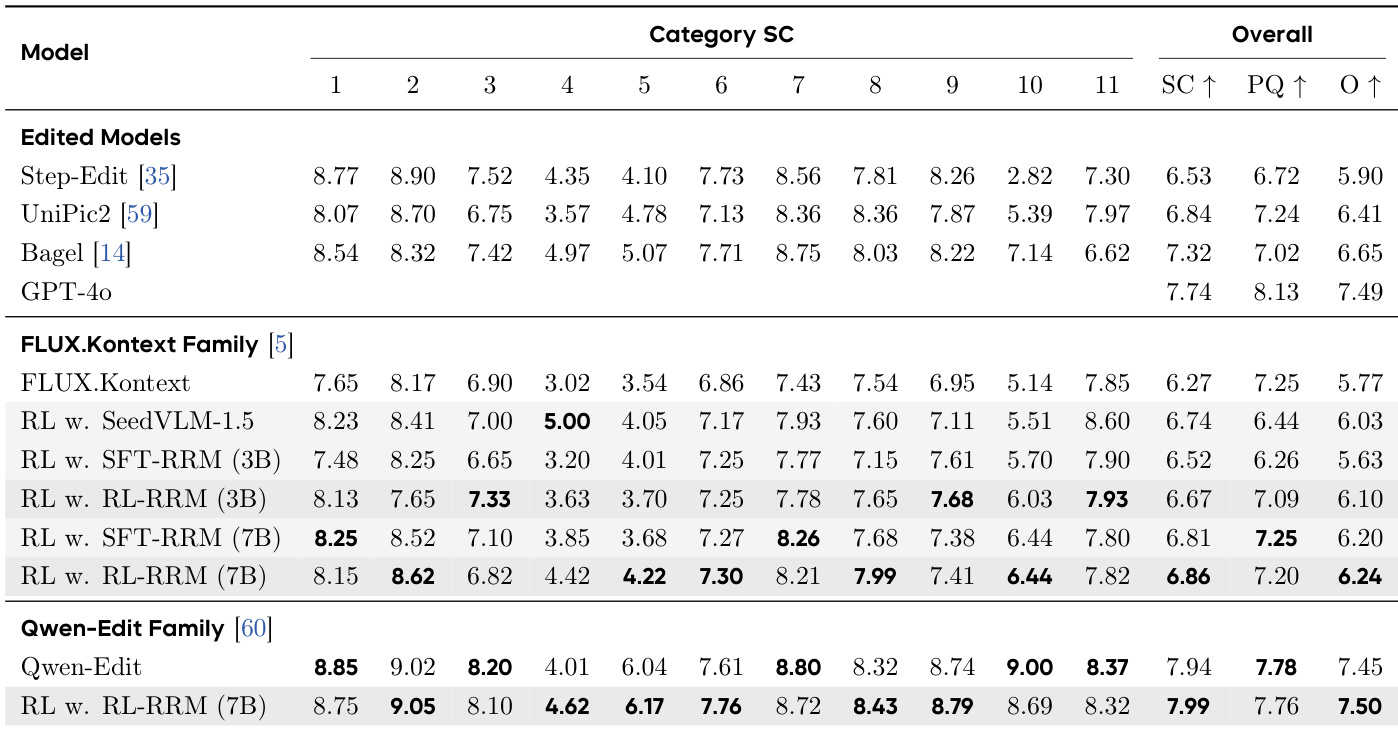
The authors evaluate their reward model and image editing framework on multiple benchmarks, demonstrating improved performance in semantic consistency and perceptual quality across different editing categories. Results show that their approach consistently outperforms baseline models, particularly in challenging tasks like motion changes and subject manipulation, with significant gains observed when using the refined reward model for policy optimization. The framework also achieves strong results on public benchmarks, indicating its effectiveness in aligning with human preferences. The framework achieves superior performance on semantic consistency and perceptual quality across various editing categories, especially in challenging tasks like motion changes and subject manipulation. Refining the reward model with GCPO leads to consistently higher evaluation rewards, indicating improved alignment with human preferences. The approach shows strong results on public benchmarks, outperforming existing models in both overall and category-specific metrics.
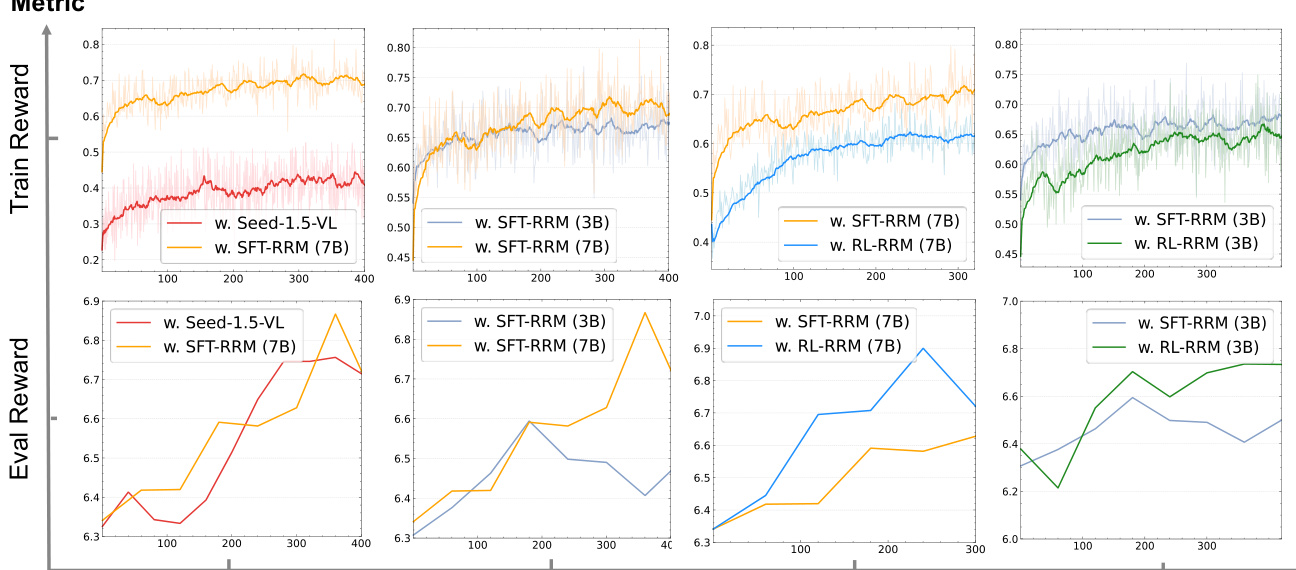
The authors analyze the training dynamics of reward models during image editing optimization, comparing models trained with and without a reinforcement learning refinement step. Results show that models refined with this step provide more stable and effective reward signals, leading to higher evaluation rewards and improved performance on image editing tasks. The refinement process also makes the reward model act as a stricter evaluator, which helps the editing models better adhere to human preferences. Models refined with reinforcement learning produce more stable and effective reward signals compared to their initial supervised counterparts. The refined reward models lead to higher evaluation rewards, indicating better alignment with human preferences. The refinement process transforms the reward model into a stricter evaluator, which improves the quality of the generated edits.
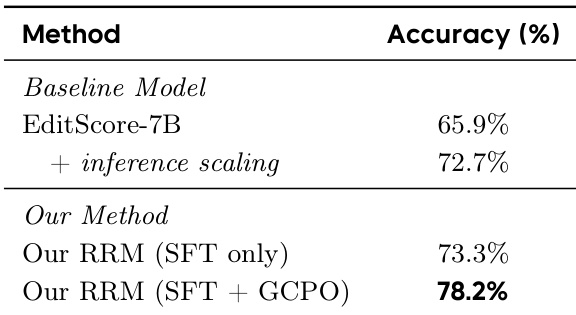
The authors evaluate their reward model's performance on a benchmark for predicting human preferences in image editing tasks. Results show that their method, which combines supervised fine-tuning with a post-training phase using GCPO, achieves higher accuracy compared to baseline models and their own SFT-only version. The improvement from GCPO indicates that the refined reward model provides stricter and more reliable supervision. The proposed reward model achieves higher accuracy than baseline models and the SFT-only version. The performance gain from GCPO indicates that the refined reward model acts as a stricter and more robust evaluator. The method's effectiveness is demonstrated through improved accuracy and better alignment with human preferences.
The authors evaluate their reward model pipeline across multiple image editing benchmarks, comparing various training configurations to validate the impact of principled data curation and reinforcement learning refinement. Experiments demonstrate that the complete two-stage approach incorporating GCPO consistently outperforms baseline models by producing more stable and stringent reward signals that reliably predict human preferences. This refined evaluation framework effectively guides the editing process to enhance semantic consistency and perceptual quality, particularly in complex manipulation tasks. Ultimately, the results confirm that structured reward model optimization significantly improves both the reliability of preference prediction and the overall alignment of generated outputs with human intent.