Command Palette
Search for a command to run...
التدريب الفعّال على عدة وحدات معالجة رسوميات (GPUs) استهلاكية باستخدام RoundPipe
التدريب الفعّال على عدة وحدات معالجة رسوميات (GPUs) استهلاكية باستخدام RoundPipe
Yibin Luo Shiwei Gao Huichuan Zheng Youyou Lu Jiwu Shu
الملخص
يُعد ضبط نماذج اللغات الكبيرة (LLMs) الدقيقاً (Fine-tuning) على وحدات معالجة الرسومات الموجهة للمستهلكين (consumer-grade GPUs) أمراً فعالاً من حيث التكلفة للغاية، إلا أنه مقيد بذاكرة GPU المحدودة وبنية التوصيل PCI Express (PCIe) البطيئة. وتعمل موازاة الأنابيب (Pipeline parallelism) مقترنة بإفراغ البيانات إلى وحدة المعالجة المركزية (CPU offloading) على التخفيف من هذه الاختناقاتHardware عبر تقليل عبء الاتصال بين المكونات. ومع ذلك، تعاني جداول موازاة الأنابيب (PP schedules) الموجودة من قيد جوهري يُعرف بمشكلة «ربط الأوزان» (weight binding issue). فربط مراحل النموذج غير المتوازنة (مثل رأس نموذج اللغة LM الذي يتميز بحجمه الكبير) بوحدات GPU يحد من إنتاجية الأنبوب (pipeline throughput) لتلك الخاصة بـ GPU الأكثر حمولة، مما يؤدي إلى فقاعات أنبوبية (pipeline bubbles) شديدة.في هذا المقال، نقترح RoundPipe، وهو جدول أنابيب مبتكّر يكسر قيد ربط الأوزان على خوادم GPU الموجهة للمستهلكين. يعامل RoundPipe وحدات GPU كمجمع من عمال التنفيذ عديمي الحالة (stateless execution workers)، ويقوم بتوزيع مراحل الحساب ديناميكياً عبر الأجهزة بطريقة الدوران (round-robin manner)، مما يتيح تحقيق أنبوب يعمل بكفاءة عالية مع فقاعات قريبة من الصفر. ولضمان صحة عملية التدريب وكفاءة النظام، يدمج RoundPipe محرك جدولة لنقل البيانات واعٍ بالأولوية (priority-aware transfer scheduling engine)، وبروتوكول مزامنة موزّع قائم على الأحداث وبدرجة دقة عالية (fine-grained distributed event-based synchronization protocol)، وخوارزمية تلقائية لتقسيم الطبقات (layer partitioning algorithm).أظهرت التقييمات على خادم مزود بثمانية من بطاقات RTX 4090 أن RoundPipe يحقق تسريعات تتراوح بين 1.48 و 2.16 مرة مقارنة بأفضل الأسس المرجعية (state-of-the-art baselines) عند ضبط نماذج تتراوح أحجامها بين 1.7 مليار و 32 مليار معلمة بدقة. وبشكل لافت للنظر، يمكّن RoundPipe من إجراء الضبط الدقيق باستخدام تقنية LoRA لنموذج Qwen3-235B بطول تسلسل يصل إلى 31 ألف رمز (token) على خادم واحد فقط.يتوفر RoundPipe كمكتبة بايثون مفتوحة المصدر، مصحوبة بوثائق شاملة ومفصلة.
One-sentence Summary
ROUNDPIPE is a pipeline scheduling method that eliminates the weight binding bottleneck in consumer GPU training by dynamically dispatching computation stages in a round-robin fashion across a unified GPU pool, supported by priority-aware transfer scheduling, fine-grained event-based synchronization, and automated layer partitioning to achieve a near-zero-bubble pipeline, yielding 1.48–2.16× speedups over state-of-the-art baselines when fine-tuning 1.7B to 32B models on an 8× RTX 4090 server.
Key Contributions
- ROUNDPIPE introduces a novel pipeline schedule that overcomes weight binding limitations on consumer-grade GPUs by treating devices as stateless workers and dynamically dispatching computation stages in a round-robin manner to eliminate pipeline bubbles.
- The framework integrates a priority-aware transfer scheduling engine to overlap parameter movement with computation, a fine-grained event-based synchronization protocol to enforce data consistency during asynchronous optimizer updates, and an automated layer partitioning algorithm to balance execution across asymmetrically split stages.
- Evaluations across 8× RTX 4090 and A800 servers demonstrate that the system achieves 1.48–2.16× throughput speedups over state-of-the-art baselines, extends maximum sequence lengths by up to 5.6×, and enables LoRA fine-tuning of a 235B MoE model on 24 GB consumer GPUs.
Introduction
Fine-tuning large language models on consumer-grade GPUs offers a cost-effective path to democratize AI, but it is severely bottlenecked by limited video memory and slow PCIe interconnects. To overcome these hardware constraints, researchers typically combine CPU offloading with pipeline parallelism. However, traditional pipeline schedules suffer from a weight binding issue where model stages are statically assigned to specific devices. This static allocation creates severe pipeline bubbles whenever uneven stages, such as a large language model head, force faster GPUs to wait, resulting in substantial idle time. The authors leverage this offloading architecture to propose ROUNDPIPE, a dynamic scheduling framework that treats GPUs as a stateless execution pool. By dispatching computation stages in a round-robin manner and integrating a priority-aware transfer engine with fine-grained event-based synchronization, ROUNDPIPE eliminates structural pipeline bubbles and achieves up to 2.16 times faster training throughput compared to existing baselines.
Method
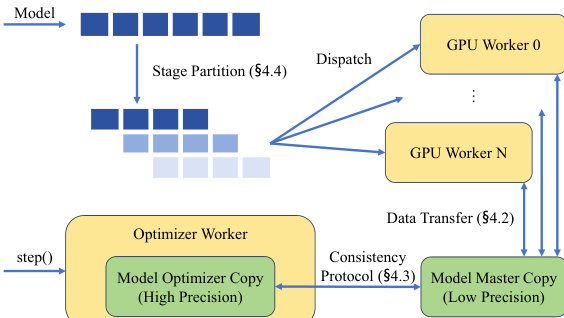
The authors leverage a novel pipeline parallelism framework, ROUNDPIPE, designed to efficiently train large models on consumer-grade GPU servers by addressing both memory constraints and communication bottlenecks inherent in existing approaches. The core of the system is built upon a computation dispatch paradigm that decouples pipeline stages from fixed physical GPUs, enabling dynamic and flexible scheduling. This paradigm is enabled by offloading model states—parameters, gradients, and optimizer states—to host memory, which allows any GPU to execute any stage as soon as its required data is ready. The framework's architecture, as shown in the system overview, consists of a central controller that orchestrates the entire training process, GPU workers responsible for executing computations and handling data transfers, and an optimizer worker that performs asynchronous updates on the model's master copy in host memory. The controller manages the dispatch of micro-batches and stages, ensuring that the pipeline progresses efficiently across the available hardware.
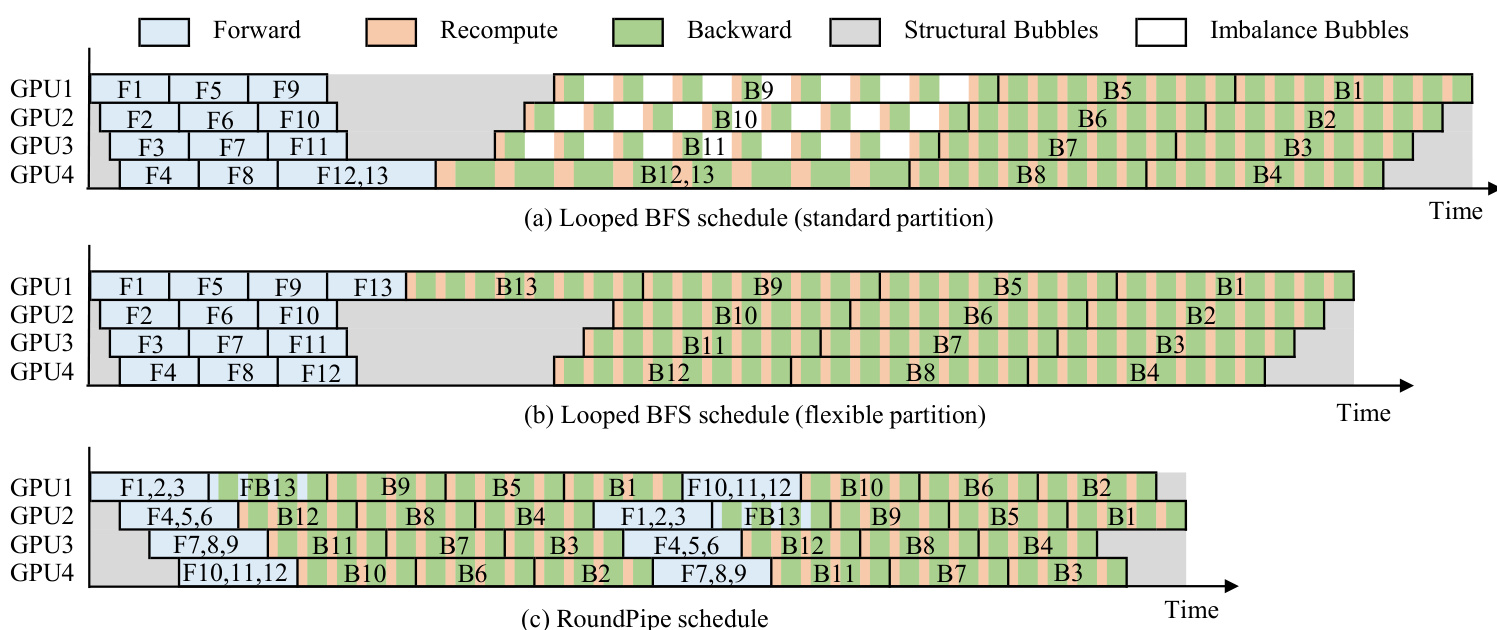
The ROUNDPIPE schedule is implemented through two key mechanisms. First, a round-robin dispatch pattern distributes the forward and backward stages of a micro-batch across all available GPUs in a continuous sequence, ensuring a smooth and zero-bubble flow of computation. This is achieved by processing multiple micro-batches per round and seamlessly resuming dispatch from the last assigned GPU. Second, asymmetric stage splitting allows for separate partitioning of the forward and backward passes. Since the backward pass is typically slower due to recomputation, ROUNDPIPE partitions the layers such that the forward and backward stages have approximately equal execution times, thereby eliminating idle time at the transition between the two phases. This approach breaks the symmetry of traditional pipeline parallelism, leading to a more balanced and efficient pipeline.
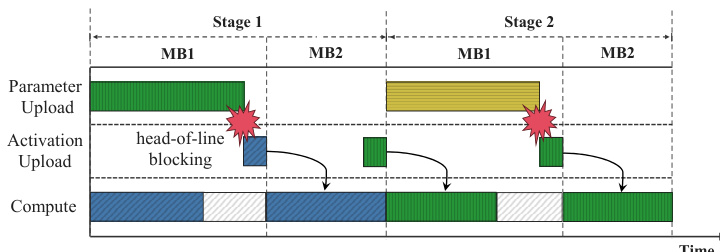
To manage the data movement required by the dispatch paradigm, ROUNDPIPE employs a multi-stream architecture for data transfer overlap. The system maintains four dedicated communication streams per GPU to handle parameter uploads, gradient downloads, activation uploads, and activation downloads. By prioritizing activation transfers on the critical path and scheduling lower-priority parameter and gradient transfers into idle windows between activation transfers, the framework ensures that data transfers are efficiently overlapped with computation. This is further enhanced by a priority-aware transfer scheduling engine that prevents head-of-line blocking.
A critical challenge in this concurrent execution model is maintaining parameter consistency for asynchronous optimizer updates. ROUNDPIPE resolves this with a fine-grained, event-based protocol. Instead of blocking the pipeline during synchronization, the system offloads weight and gradient copies to the optimizer worker and uses per-layer CUDA events to enforce the necessary ordering constraints. This allows synchronization to be performed at the individual layer level, enabling the pipeline to progress on earlier layers without waiting for the completion of synchronization on deeper layers, thus eliminating unnecessary pipeline bubbles.
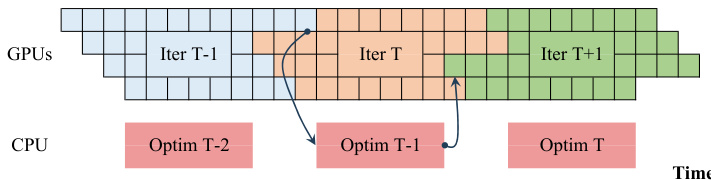
Finally, ROUNDPIPE includes an automatic stage partitioning algorithm to optimize performance. The system collects per-layer execution time and memory data during the initial iterations and uses a greedy approach to find the optimal partitioning that minimizes the maximum stage runtime while respecting GPU memory constraints. This automated process ensures a balanced workload across the pipeline without requiring manual tuning. The overall system is designed to preserve full compute-bound throughput, as confirmed by a roofline analysis that shows data transfers can be entirely overlapped with computation for typical training batch sizes.
Experiment
Evaluated across consumer and datacenter GPU servers, the experiments assess end-to-end throughput, maximum sequence length, scaling behavior, and internal pipeline efficiency to validate ROUNDPIPE's memory offloading and asynchronous optimization strategies. Throughput and sequence length tests demonstrate that the framework consistently outperforms existing systems by mitigating pipeline bubbles and avoiding memory bottlenecks. Scaling and ablation studies further confirm that the custom scheduling and event-based consistency protocol eliminate communication overhead and maintain robust performance across varying context lengths. Ultimately, the findings establish ROUNDPIPE as a highly efficient training solution that enables cost-effective consumer hardware to rival datacenter performance.
The authors evaluate ROUNDPIPE's performance on consumer-grade GPU servers, demonstrating that it achieves higher training throughput and supports longer sequence lengths compared to existing systems across various model sizes. Results show that ROUNDPIPE maintains robust performance as sequence length increases and significantly reduces pipeline bubbles through its novel scheduling and communication strategies. The system scales effectively with the number of GPUs, outperforming baselines even on hardware with limited memory and bandwidth. ROUNDPIPE achieves higher training throughput than existing systems across multiple model sizes and GPU counts. ROUNDPIPE supports longer sequence lengths compared to other frameworks, especially on models with large parameter counts. The system maintains stable performance as sequence length increases, showing robustness across different context lengths.
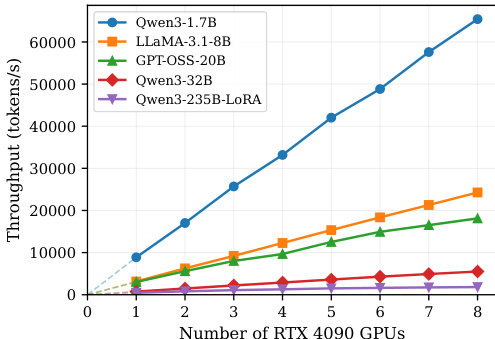
The authors evaluate ROUNDPIPE's performance on both consumer-grade and datacenter-grade GPU servers, demonstrating its ability to achieve high training throughput and support long sequence lengths across various model sizes. Results show that ROUNDPIPE consistently outperforms existing systems by reducing pipeline bubbles and effectively managing memory through offloading techniques, even on hardware with limited VRAM. ROUNDPIPE achieves higher training throughput than existing systems by reducing pipeline bubbles and improving communication-computation overlap. ROUNDPIPE supports longer sequence lengths than baselines by offloading activations to CPU memory and recomputing on demand. ROUNDPIPE maintains robust performance across different sequence lengths, showing smooth throughput degradation as attention cost increases.
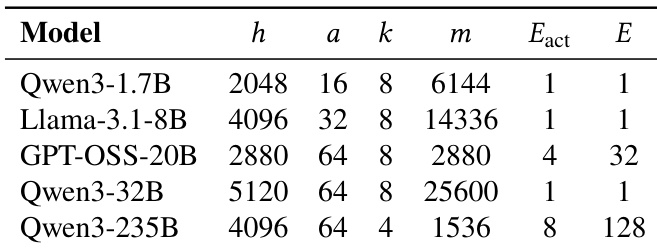
The authors evaluate ROUNDPIPE on various GPU servers, including consumer-grade and datacenter-grade hardware, and analyze its performance in terms of throughput and maximum sequence length. Results show that ROUNDPIPE achieves higher throughput and supports longer sequences compared to existing systems, particularly on hardware with limited memory, by effectively managing pipeline bubbles and communication-computation overlap. The system's performance scales well across different model sizes and GPU configurations, maintaining robustness even as sequence length increases. ROUNDPIPE achieves higher training throughput and supports longer sequences compared to existing systems, especially on hardware with limited memory. The system maintains robust performance across a wide range of sequence lengths, with throughput decreasing smoothly as attention costs grow. ROUNDPIPE reduces pipeline bubbles significantly and effectively overlaps weight and gradient synchronization with GPU computation, enhancing overall efficiency.
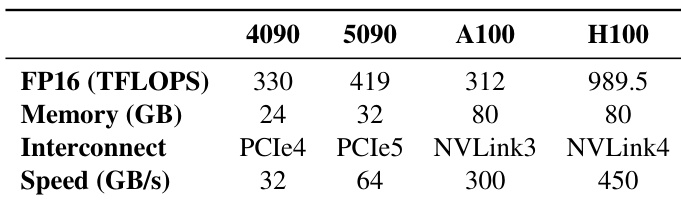
The authors evaluate ROUNDPIPE's performance on consumer and datacenter-grade GPUs, focusing on throughput and maximum sequence length. Results show that ROUNDPIPE achieves higher throughput and supports longer sequences compared to existing systems, particularly due to its efficient pipeline design and reduced communication-computation bubbles. The system maintains robust performance across different sequence lengths and scales effectively with model size and GPU count. ROUNDPIPE achieves higher training throughput than existing systems across various model sizes on both consumer and datacenter GPUs. ROUNDPIPE supports longer sequences than other baselines by efficiently managing memory and reducing communication overhead. The system's performance is robust across different sequence lengths and scales well with model size and GPU count.
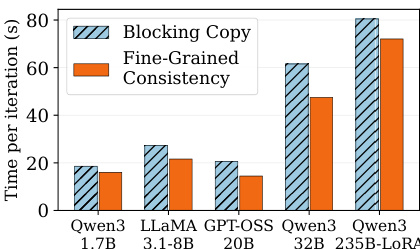
The authors evaluate ROUNDPIPE across consumer-grade and datacenter-grade GPU servers, validating its efficiency and scalability across diverse model sizes and hardware configurations. The system consistently outperforms existing frameworks by delivering higher training throughput and supporting significantly longer sequence lengths. These improvements stem from optimized scheduling and memory offloading strategies that effectively minimize pipeline bubbles and enhance communication-computation overlap. Consequently, ROUNDPIPE maintains robust and stable performance as sequence lengths increase, demonstrating reliable scalability even on hardware with constrained memory and bandwidth.