Command Palette
Search for a command to run...
Tuna-2: دمج الصور البيكسلية يتفوق على محولات الرؤية في الفهم والتوليد متعدد الوسائط
Tuna-2: دمج الصور البيكسلية يتفوق على محولات الرؤية في الفهم والتوليد متعدد الوسائط
الملخص
تعتمد النماذج متعددة الوسائط الموحَّدة عادةً على مشفرات بصرية مُدرَّبة مسبقاً، وتستخدم تمثيلات بصرية منفصلة لمهام الفهم والتوليد، مما يخلق فجوة بين هذين المهمتين ويعيق التحسين الكامل من الحافة إلى الحافة (end-to-end optimization) بدءاً من البكسلات الخام. نقدم هنا نموذج Tuna-2، وهو نموذج موحد أصلي متعدد الوسائط يؤدي مهام الفهم البصري والتوليد مباشرةً بناءً على تضمينات البكسل (pixel embeddings). يبسّط Tuna-2 بنية النموذج بشكل كبير من خلال استخدام طبقات تضمين البقع البسيطة (patch embedding layers) لتشفير الإدخال البصري، متجاهلاً تماماً التصاميم المعيارية لمشفرات الرؤية مثل VAE أو مشفر التمثيل. تظهر التجارب أن Tuna-2 يحقق أداءً متفوقاً في المعايير متعددة الوسائط، مبرهنًا على أن نمذجة الفضاء البكسلي الموحّد يمكن أن تنافس تمامًا أساليب الفضاء الكامن (latent space) في توليد الصور عالية الجودة. بالإضافة إلى ذلك، وعلى الرغم من أن النسخة القائمة على المشفر تصل إلى مرحلة التقارب بشكل أسرع في المراحل المبكرة من التدريب المسبق، فإن التصميم الخالي من المشفرات في Tuna-2 يحقق أداءً أقوى في الفهم متعدد الوسائط عند التوسع، خاصةً في المهام التي تتطلب إدراكًا بصريًا دقيقًا. توضح هذه النتائج أن مشفرات الرؤية المُدرَّبة مسبقًا ليست ضرورية للنمذجة متعددة الوسائط، وأن التعلم في الفضاء البكسلي من الحافة إلى الحافة يوفّر مسارًا قابلاً للتوسع نحو تمثيلات بصرية أقوى لمهام التوليد والإدراك معًا.
One-sentence Summary
TUNA-2 is a unified multimodal model that replaces pretrained vision encoders with direct pixel embeddings to enable fully end-to-end optimization for understanding and generation, achieving state-of-the-art benchmark performance that demonstrates pixel-space modeling competes with latent approaches for high-quality image generation and delivers stronger fine-grained visual perception at scale.
Key Contributions
- TUNA-2 is introduced as a native unified multimodal model that performs visual understanding and generation directly from raw pixel embeddings using simple patch embedding layers instead of pretrained VAE or representation encoders. The architecture integrates a unified vision-language backbone with a pixel-space flow matching head to support image understanding, text-to-image generation, and image editing within a single framework.
- A masking-based visual feature learning scheme stabilizes training and encourages robust representation learning in high-dimensional pixel space. This technique addresses the inherent challenges of learning unified representations directly from raw pixels without relying on compact latent spaces.
- Benchmark evaluations demonstrate that the encoder-free TUNA-2 architecture achieves state-of-the-art or highly competitive performance across diverse multimodal understanding and generation tasks. The model consistently outperforms encoder-based variants on fine-grained visual perception benchmarks while matching latent-space approaches for high-quality image generation.
Introduction
Unified multimodal models aim to integrate visual understanding and generation within a single framework, enabling more efficient AI systems that can both interpret and create visual content. Existing approaches typically rely on pretrained vision encoders or variational autoencoders to compress images into latent spaces, which creates representation mismatches between tasks and prevents fully end-to-end optimization directly from raw pixels. To address these limitations, the authors introduce TUNA-2, a native unified model that completely discards modular vision encoders and processes raw pixels through simple patch embedding layers. By combining this streamlined architecture with a masking-based stabilization technique, the authors demonstrate that end-to-end pixel-space learning not only matches state-of-the-art generation quality but significantly outperforms prior latent-space models on fine-grained visual understanding benchmarks.
Dataset
-
Dataset Composition & Sources
- The authors construct a hybrid corpus that merges proprietary image-text pairs with external public datasets to support both multimodal comprehension and generative capabilities.
-
Subset Details
- Stage 1 Pretraining: 550 million in-house image-text pairs divided into 70% image captioning data and 30% text-to-image generation data. This is combined with Nemotron text-only samples, which represent 20% of the total pretraining mix.
- Stage 2 Supervised Fine-Tuning: A curated collection targeting instruction following, editing, and high-quality generation. It comprises 13 million conversational examples from FineVision and approximately 2 million editing examples from OmniEdit.
-
Data Usage & Training Configuration
- Qwen2.5-7B-Instruct acts as the foundational language decoder. Pretraining runs end-to-end for 300k steps using AdamW with a learning rate of 1e-4. Supervised fine-tuning follows for 50k steps at a learning rate of 2e-5. For the TUNA-R variant, a SigLIP 2 So400M vision encoder is integrated, and the connector alignment phase trains for 3k steps at 5e-4.
-
Processing & Technical Handling
- All training stages uniformly pad input sequences to a maximum of 16k tokens per GPU. The provided documentation does not specify image cropping strategies or metadata construction pipelines, focusing instead on sequence length standardization, optimizer selection, and learning rate scheduling.
Method
The authors leverage a progressive architectural simplification to derive TUNA-2, a native unified multimodal model designed for both visual understanding and generation in pixel space. The framework begins with a standard encoder-based approach, as illustrated in Figure 1, where a vision encoder processes input images into visual tokens, which are then combined with text tokens in a large language model (LLM) decoder. This design, referred to as TUNA-R, retains a pretrained representation encoder and a variational autoencoder (VAE) for image generation. The authors then remove the VAE to simplify the architecture, resulting in TUNA-R, which relies solely on a representation encoder and an LLM decoder. Building on this, TUNA-2 introduces a fully encoder-free design by eliminating the pretrained representation encoder entirely. Instead, raw image patches are directly embedded into visual tokens via a patchify layer, which are then processed jointly with text tokens within the LLM decoder. This approach removes the inductive biases of fixed resolutions and limited low-level detail access associated with pretrained encoders, leading to a single unified transformer architecture. 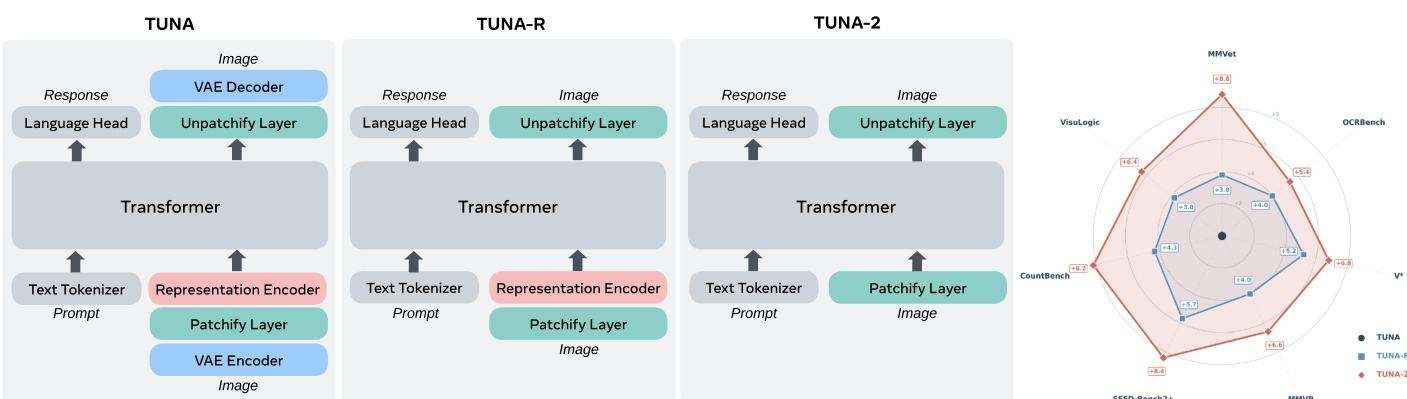
To enable high-fidelity pixel-space image generation without a VAE, the model adopts the x-prediction and v-loss paradigm from JiT for flow matching. The process involves constructing a noisy sample in pixel space using a linear schedule: xt=tx1+(1−t)x0, where x1 is the source image, x0∼N(0,I) is the sampled noise, and t∈[0,1]. The model is trained to predict the clean image xθ=πθ(xt,c,t), where πθ represents the unified model and c is the conditioning signal. However, the learning objective is formulated as regressing the velocity term vθ=(xθ−xt)/(1−t), with the loss function defined as Lflow=Et,c,x1,x0∣∣vθ−v∣∣22, where v=x1−x0 is the ground truth velocity. During inference, the Euler solver is used to denoise the image, predicting xt′=xt+(t′−t)vθ from a noisier image at t<t′, where vθ is derived from the model prediction xθ. 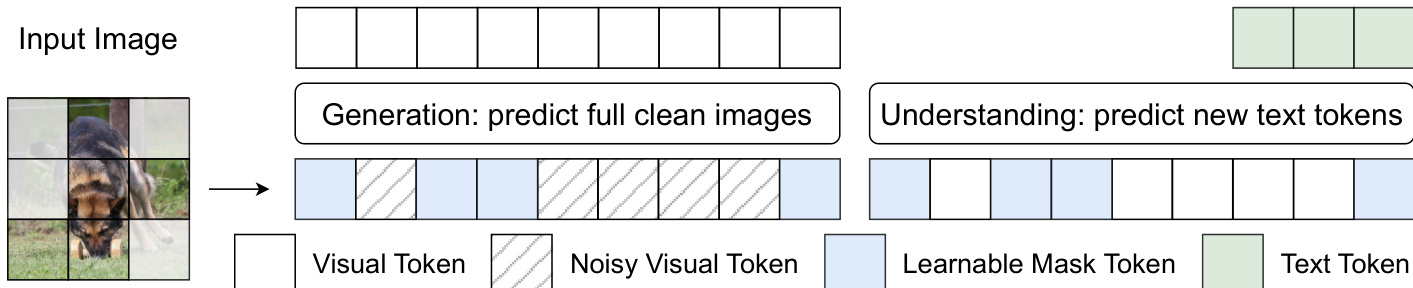
To address the challenge of learning robust visual representations in the high-dimensional pixel space, the authors introduce a masking-based feature learning scheme. As shown in the figure below, during training, a subset of image patches is randomly selected and masked according to a masking ratio, with the masked visual tokens replaced by a learnable mask token. This masking operation is applied to both generation and understanding examples, but serves different purposes. For generation, the model predicts the full clean image, including both masked and unmasked regions, which creates a harder denoising task and encourages the learnable mask token to absorb useful context information. For understanding, the model generates text responses based on the masked visual input, acting as a regularization mechanism that forces multimodal reasoning under partial visual observation. This scheme is analogous to masked modelling techniques in vision, such as MAE and MaskGIT, and empirically enhances model performance during pretraining.
The training pipeline for TUNA-2 consists of two fully end-to-end stages. In Stage 1, full model pretraining, the model is jointly trained on image captioning and text-to-image generation tasks to establish a strong initialization for the flow matching head and adapt pixel-space inputs for unified multimodal tasks. In Stage 2, supervised fine-tuning (SFT), the model undergoes further refinement using datasets for image editing, image instruction-following, and high-quality image generation at a lower learning rate to enhance performance and generalization. This end-to-end design eliminates the need for separate connector layer training, which is required in encoder-based approaches like TUNA-R, thereby streamlining the training process.
Experiment
The evaluation encompasses comprehensive image understanding, generation, editing, and reconstruction benchmarks alongside ablation studies on training data ratios and feature learning strategies. These experiments validate that pixel-space unified representations consistently outperform latent-space and modular architectures, particularly for fine-grained visual reasoning, while a balanced data mixture and masking-based feature learning significantly enhance model robustness. Comparative analysis demonstrates that although encoder-based variants leverage initial semantic priors for faster convergence, the encoder-free design ultimately achieves superior multimodal understanding and more accurate cross-modal alignment. Overall, the findings confirm that large-scale joint training of a monolithic pixel-space architecture effectively supports high-quality generation and robust instruction-guided editing without relying on pretrained visual encoders.
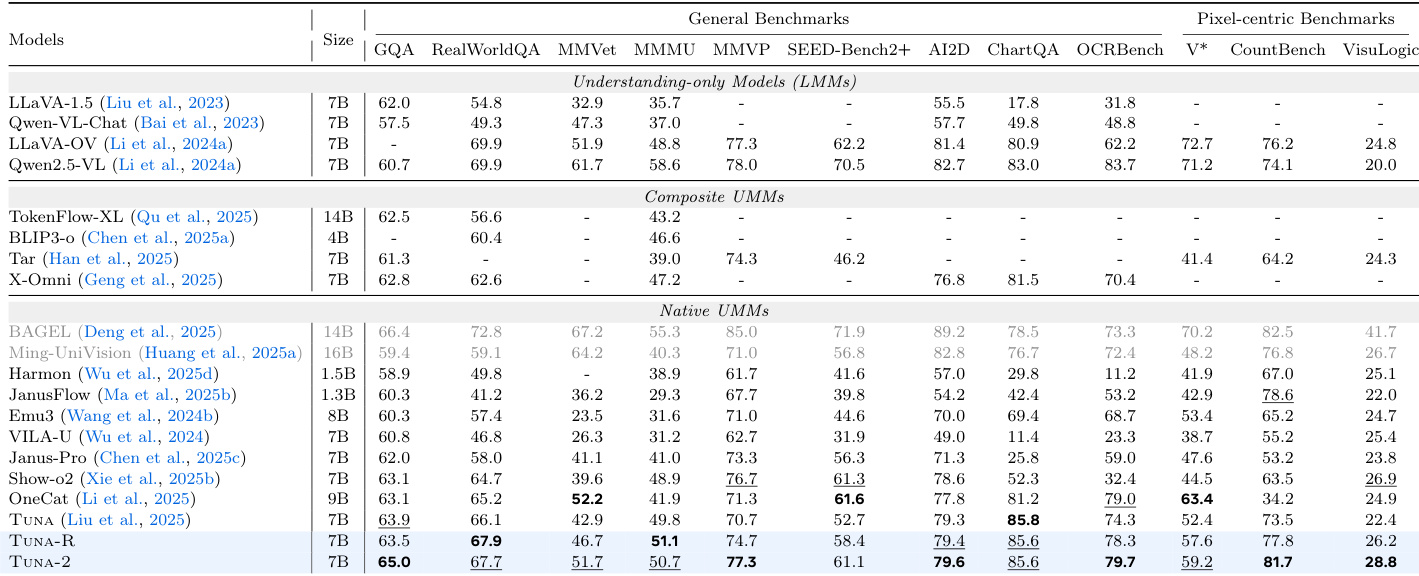
The authors evaluate the performance of TUNA-2 and related models across various benchmarks for image understanding, generation, editing, and reconstruction. Results show that TUNA-2 achieves strong performance in understanding and generation tasks, often outperforming or competing with other state-of-the-art unified multimodal models, particularly in pixel-space settings. The model demonstrates robust cross-modal alignment and effective learning dynamics, especially when trained with balanced data ratios and masking-based feature learning. TUNA-2 achieves competitive results across image understanding and generation benchmarks, often outperforming or matching state-of-the-art models in pixel-space settings. The model shows strong performance in image reconstruction and generation, with competitive quality and diversity compared to encoder-based approaches. TUNA-2 exhibits more accurate and robust cross-modal alignment, particularly in challenging scenarios with misleading linguistic cues or visual distractors.
The authors evaluate the image reconstruction performance of various visual tokenizers, comparing unified models with specialized ones. Results show that TUNA-R and TUNA-2 achieve strong reconstruction quality, ranking among the top unified tokenizers and approaching the performance of specialized models like FLUX.1. The unified models outperform non-KL-regularized VAE approaches, indicating effective pixel-space representation learning. TUNA-R and TUNA-2 achieve top-tier reconstruction performance among unified tokenizers. The models' reconstruction quality is competitive with specialized tokenizers like FLUX.1. TUNA-R and TUNA-2 outperform non-KL-regularized VAE approaches in reconstruction tasks.
The authors evaluate the image generation performance of TUNA-2 and TUNA-R on GenEval and DPG-Bench, comparing them against various generation-only and unified multimodal models. Results show that both TUNA-R and TUNA-2 achieve state-of-the-art results on these benchmarks, with TUNA-R slightly outperforming TUNA-2. The models rank among the top performers in both datasets, demonstrating strong competitive performance without relying on vision encoders or VAEs. TUNA-R and TUNA-2 achieve top performance on GenEval and DPG-Bench, outperforming multiple generation-only and unified models. TUNA-R consistently performs slightly better than TUNA-2 on image generation benchmarks. Both models achieve competitive results despite operating entirely in pixel space without vision encoders or VAEs.
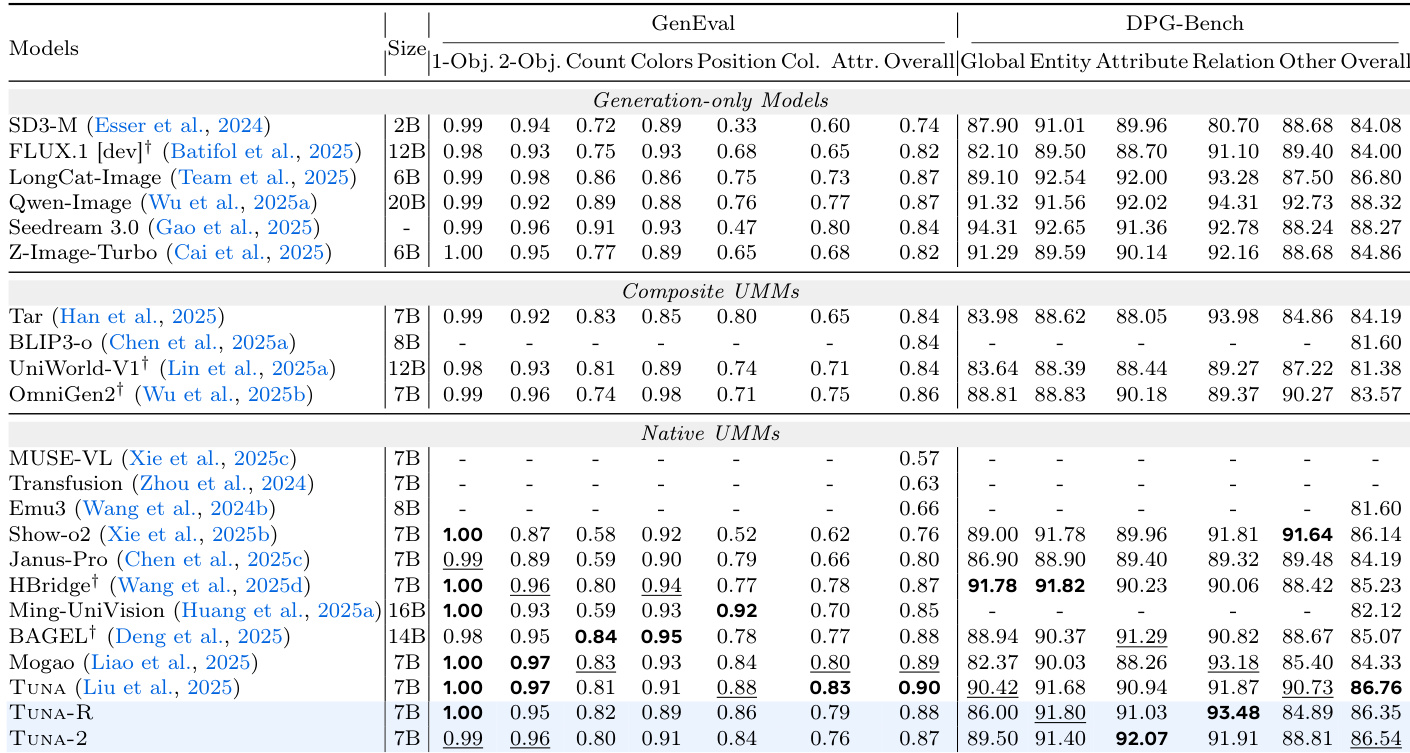
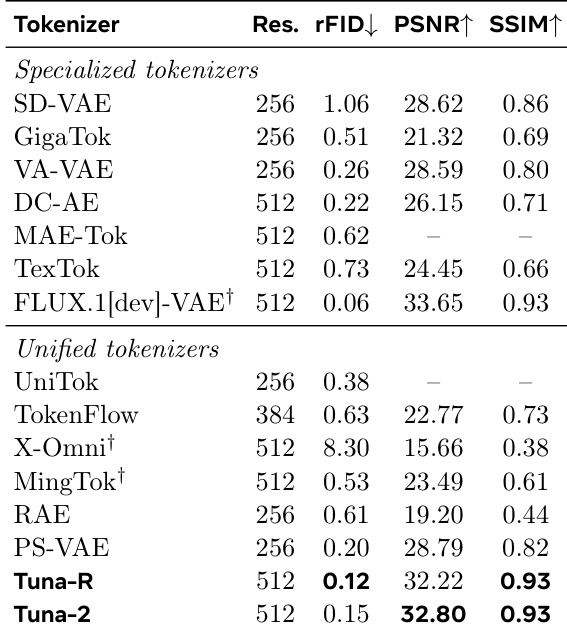
The authors evaluate image reconstruction performance across various visual tokenizers, comparing specialized and unified approaches. TUNA-2 achieves the highest scores on PSNR and SSIM among unified tokenizers, demonstrating strong reconstruction quality. It also outperforms specialized tokenizers like VA-VAE and DC-AE in PSNR and SSIM, while showing competitive results in resolution and FID metrics. TUNA-2 achieves the highest PSNR and SSIM scores among unified tokenizers, indicating strong image reconstruction quality. TUNA-2 outperforms specialized tokenizers such as VA-VAE and DC-AE in PSNR and SSIM, suggesting effective pixel-space representation learning. TUNA-2 maintains competitive resolution and FID metrics, demonstrating balanced reconstruction performance across multiple evaluation criteria.
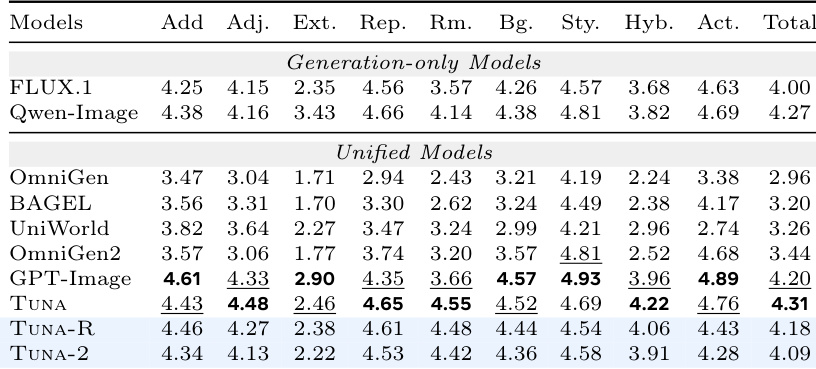
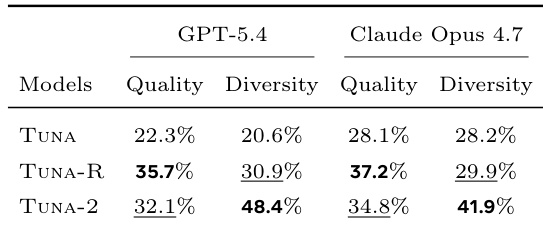
The authors evaluate the image generation performance of TUNA-2, TUNA-R, and TUNA using LLM judges to assess quality and diversity. Results show that TUNA-2 achieves competitive quality and significantly higher diversity compared to the other models. TUNA-R performs best in quality while TUNA-2 demonstrates superior diversity across both judges. TUNA-2 achieves competitive image quality and significantly higher diversity than TUNA and TUNA-R. TUNA-R outperforms TUNA-2 in quality across both LLM judges. TUNA-2 is preferred in diversity, indicating a stronger ability to generate varied images from the same prompt.
The authors evaluate TUNA-2 and its variants across comprehensive benchmarks for image understanding, generation, editing, and reconstruction, comparing them against both specialized and unified multimodal architectures. These experiments validate the models' capacity for robust cross-modal alignment and effective pixel-space representation learning, demonstrating strong performance even with misleading linguistic cues or visual distractors. Generation assessments reveal a clear trade-off where TUNA-R prioritizes output quality while TUNA-2 emphasizes diversity, both operating competitively without traditional vision encoders or VAEs. Overall, the unified framework proves highly versatile, with balanced data sampling and masking-based training enabling it to match or exceed specialized systems across diverse visual tasks.