Command Palette
Search for a command to run...
ميتا-كو تي: تعزيز الدقة والتعميم في تحرير الصور
ميتا-كو تي: تعزيز الدقة والتعميم في تحرير الصور
الملخص
أظهرت النماذج الموحَّدة للفهم/التوليد متعدد الوسائط تحسُّناً في أداء تعديل الصور من خلال دمج الفهم الدقيق (Fine-grained) في عملية تسلسل التفكير (Chain-of-Thought - CoT). ومع ذلك، لا تزال هناك مسألة حاسمة غير مستكشفة بعمق: ما هي أشكال تسلسل التفكير واستراتيجيات التدريب التي يمكنها معاً تعزيز كل من دقة الفهم والقدرة على التعميم؟ لمعالجة هذا الأمر، نقترح نموذج "الميتا-سلسلة التفكير" (Meta-CoT)، وهو نموذج إجرائي يقوم بتحليل عمليتين لتعديل أي صورة فردية، ويتميز بخاصيتين رئيسيتين:(1) القابلية للتفكيك (Decomposability): نلاحظ أن أي نية للتعديل يمكن تمثيلها كـ "ثلاثي" يتكون من (المهمة، الهدف، والقدرة المطلوبة على الفهم). مستلهمين من هذا المبدأ، يقوم Meta-CoT بتفكيك كلٍ من مهمة التعديل والهدف، مما يولّد سلسلة تفكير محددة للمهمة، ويجري عمليات التعديل على جميع الأهداف. يعزّز هذا التفكيك دقة فهم النموذج لعمليات التعديل، ويوجّهه لتعلم كل عنصر من عناصر الثلاثي خلال التدريب، مما يحسّن بشكل كبير من قدرته على التعديل.(2) القدرة على التعميم (Generalizability): في مستوى التفكيك الثاني، نقوم进一步 بتقسيم مهام التعديل إلى خمس مهام ميتا أساسية. نكتشف أن التدريب على هذه المهام الخمس، بالإضافة إلى العنصرين الآخرين من الثلاثي، يكفي لتحقيق قدرة تعميم قوية عبر مجموعة متنوعة من مهام التعديل غير المرئية سابقاً. ولتقريب سلوك تعديل النموذج من منطق تسلسل التفكير الخاص به، نقدم "مكافأة اتساق سلسلة التفكير مع التعديل" (CoT-Editing Consistency Reward)، والتي تشجّع على الاستخدام الأدق والأكثر فعالية لمعلومات سلسلة التفكير أثناء التعديل.أظهرت التجارب أن طريقتنا تحقق تحسناً شاملاً بنسبة 15.8% عبر 21 مهمة تعديل، وتتعمم بشكل فعّال على مهام تعديل غير مرئية سابقاً عند التدريب على مجموعة صغيرة فقط من المهام الميتا. تم إصدار الكود الخاص بنا، والمعيار المرجعي (Benchmark)، والنموذج على الرابط: https://shiyi-zh0408.github.io/projectpages/Meta-CoT/
One-sentence Summary
Meta-CoT enhances image editing by decomposing operations into a task-target-understanding triplet and five fundamental meta-tasks, which guide task-specific Chain-of-Thought reasoning and training to simultaneously improve fine-grained understanding and cross-task generalization.
Method
The authors leverage a two-level decomposition framework in Meta-CoT to enhance both the understanding granularity and generalization of chain-of-thought (CoT) guided image editing. The core of the method begins with Triplet Decomposition, which breaks down any editing instruction into a triplet comprising the task, target, and required understanding capability. This decomposition enables the model to reason about editing operations at a fine-grained level by explicitly learning each element of the triplet during training. As shown in the framework diagram, the process unfolds in three steps: (1) Task Summary, where the model infers the task type from the instruction; (2) Task Thinking, where it generates a task-specific reasoning process based on the inferred task type; and (3) Target-wise Editing Traversal, where it traverses all targets in the image to determine whether and how each should be edited, ensuring spatial and semantic consistency. 
To further improve generalization, the authors introduce Meta-task Decomposition as a second level of decomposition. This approach identifies a set of fundamental operations, termed meta-tasks, which serve as a basis for the editing task space. The authors define five distinct meta-tasks, including camera motion, object addition, and object deletion, which can be combined to produce more complex editing operations. The triplet is then refined to (meta-task, target, required understanding capability), and the initial task summary step is replaced with a meta-task summary, decomposing the instruction into a combination of basic meta-tasks. This enables the model to generalize effectively to unseen editing tasks when trained on a small set of meta-tasks. 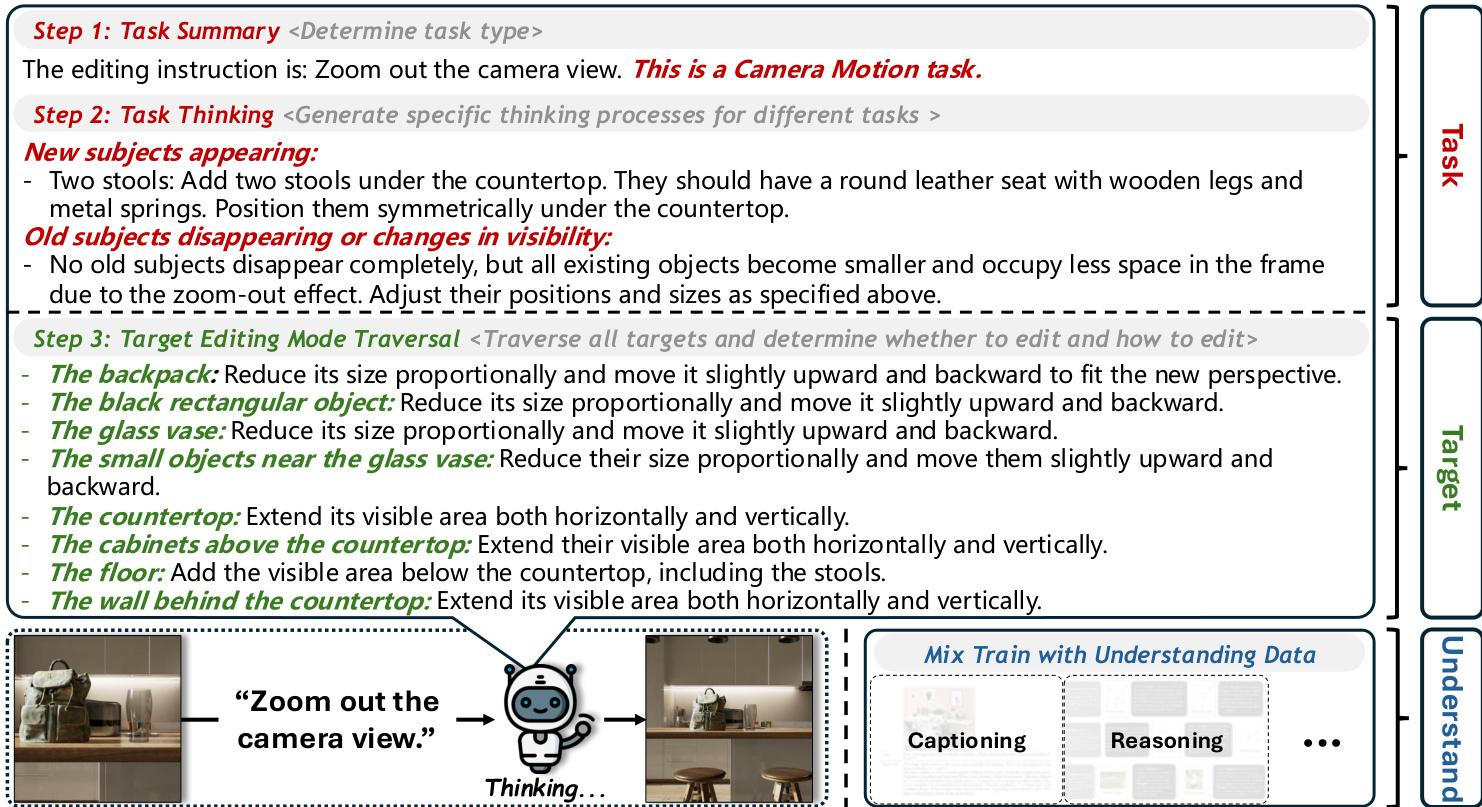
The training pipeline consists of two stages. In Stage I and II, both the understanding expert and generation expert are fine-tuned to train CoT reasoning and image editing, with the image understanding encoder also updated. In the subsequent reinforcement learning stage, the image understanding encoder is frozen, and only the generation expert is trained. This design is motivated by the observation that the model already achieves highly accurate CoTs after the initial fine-tuning stage, and training both modules during reinforcement learning can lead to unstable optimization and degradation of the reasoning ability learned in the first stage. 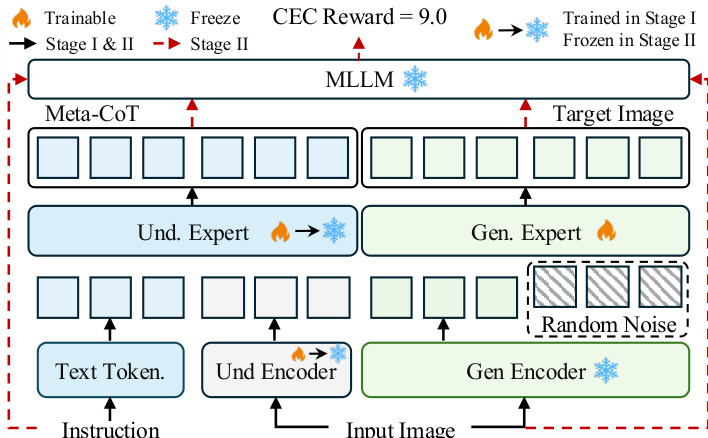
To align the CoT reasoning with the actual editing behavior, the authors introduce the CoT-Editing Consistency (CEC) Reward. This reward measures the semantic alignment between the generated CoT and the editing results from both task and target perspectives. A vision-language model (VLM) evaluates whether the generated edit aligns with the CoT reasoning, producing a score from 0 to 10. The CEC Reward is optimized using Flow-GRPO, with the optimization focused on early denoising timesteps where semantic fidelity is most critical, and updates on later timesteps are omitted to reduce noise artifacts. 
The Meta-CoT data construction pipeline, illustrated in Figure 5, processes the source image, target image, and instruction to generate the necessary training data. The process begins by determining the editing task type using Qwen2.5, followed by a consistency check with Gemini-2.5-Flash. The source image, target image, instruction, and task type are then input into Qwen2.5-VL, which, guided by a carefully designed prompt, generates the (Meta-)Task Summary, Task Thinking, and Target Editing Mode Traversal. This pipeline also includes an evaluation step to verify the alignment between the generated Meta-CoT and the actual editing process. 
Experiment
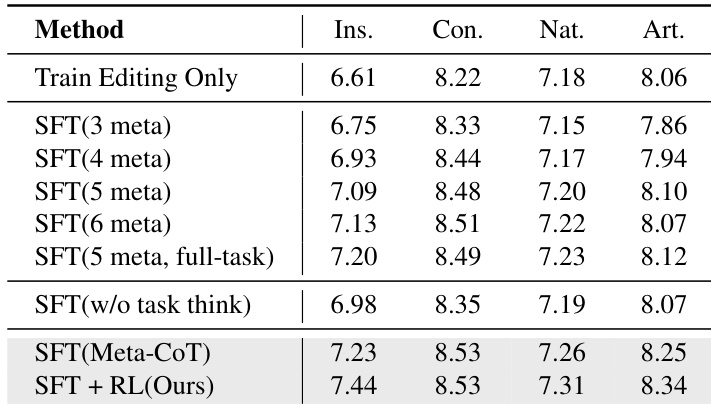
As shown in the table, the paper replace the first step of the CoT ("Task Summary") with Meta-task Summary and conduct training under five distinct settings, each corresponding to different definitions of meta-tasks and the number of training task types. Starting from the basic 3-meta-tasks setting (add, delete, replace), the paper gradually increase the number of meta-tasks. The results show that, first, the model trained only on the five meta-tasks already achieves performance comparable to the full-data model on the 21-task benchmark and significantly outper
the table. Ablation study on (1) the number of meta-tasks defined and tasks trained, and (2) the Task Thinking in Meta-CoT. (n meta) denotes defining n meta-tasks and training only on them. (5 meta, full-task) indicates defining 5 meta-tasks, training on full tasks, and decomposing each task's data into meta-tasks.
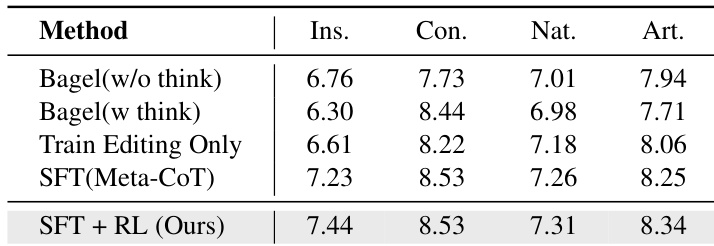
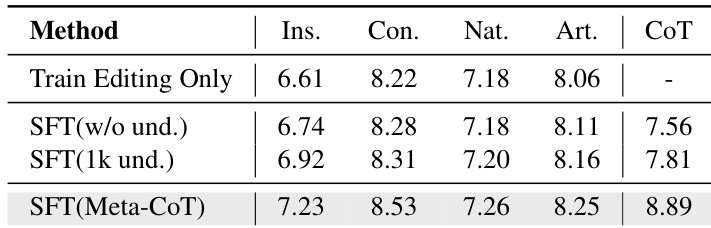
the table. Ablation study on the amount of visual understanding data mixed during training. w/o und. denotes training without mixing visual understanding data. CoT measures the completeness and accuracy of Task Thinking and Target Editing Traversal.

forms the train-edit-only version. This demonstrates the strong generalization capability of the meta-task training strategy: training on a small set of meta-tasks while learning task decomposition suffices to generalize to unseen tasks. In other words, mastering universal meta-tasks and task decomposition reasoning enhances the model's ability to generalize. Second, results show that the defined five meta-tasks strike a good balance between generalization and performance: defining fewer meta-tasks leads to a significant drop in instruction-following, while defining more meta-tasks provides little additional improvement across all tasks.
Does the Task Thinking in Meta-CoT benefit the editing process? As shown in the table, the paper compare the method with a variant that removes the Task Thinking (the second step of Meta-CoT). Results show a significant drop in instruction-following performance, confirming that reasoning based on task characteristics is crucial for the editing.
How does joint training with understanding data affect editing performance? In the table, the paper compare two reduced settings: (a) removing all understanding data and (b) using only 1K samples, against the default 100K. In addition to the four VIEScore components, GPT-4.1 also evaluates CoT quality in terms of the completeness and accuracy of Task Thinking and Target Editing Traversal in Meta-CoT. Results show that both reduced settings cause significant drops in editing performance, particularly in in
the figure. Qualitative results across diverse editing tasks, including conventional editing, reasoning-based editing, and multi-instruction editing (Zoom in to view). the paper present a partial visualization of the Meta-CoT reasoning process. Meta-CoT can decompose instructions, categorize them into specific tasks, generate reasoning based on the task characteristics, and accurately determine whether each target should be edited or not, ultimately achieving better editing results. Please see the supplementary materials for additional task examples.
struction following, as limited understanding data weakens the model's comprehension of editing instructions. This is further corroborated by the notable decline in CoT quality, underscoring the necessity of balancing all three triplet elements during training and demonstrating that higher-quality Meta-CoT reasoning leads to better editing results.
- 4.4. Qualitative Evaluation
As shown in the figure, the paper present comparisons across diverse editing tasks, including conventional, reasoning-based editing, and multi-instruction editing. the method significantly improves instruction following, logical reasoning, and multi-instruction understanding compared with baseline methods. This demonstrates that the approach more effectively activates and leverages the model's inherent understanding capability during the editing process.
The authors compare their method against various baselines on multiple editing benchmarks, demonstrating improvements in overall performance across diverse editing tasks. The results show that incorporating Meta-CoT reasoning significantly enhances instruction following and overall editing quality, particularly in complex and multi-instruction scenarios, while also highlighting the importance of joint training with visual understanding data. Meta-CoT reasoning leads to significant improvements in instruction following and overall editing performance compared to baseline methods. The method outperforms existing models across diverse editing tasks, especially in multi-instruction and complex editing scenarios. Joint training with visual understanding data is crucial for maintaining high-quality Meta-CoT reasoning and overall editing results.
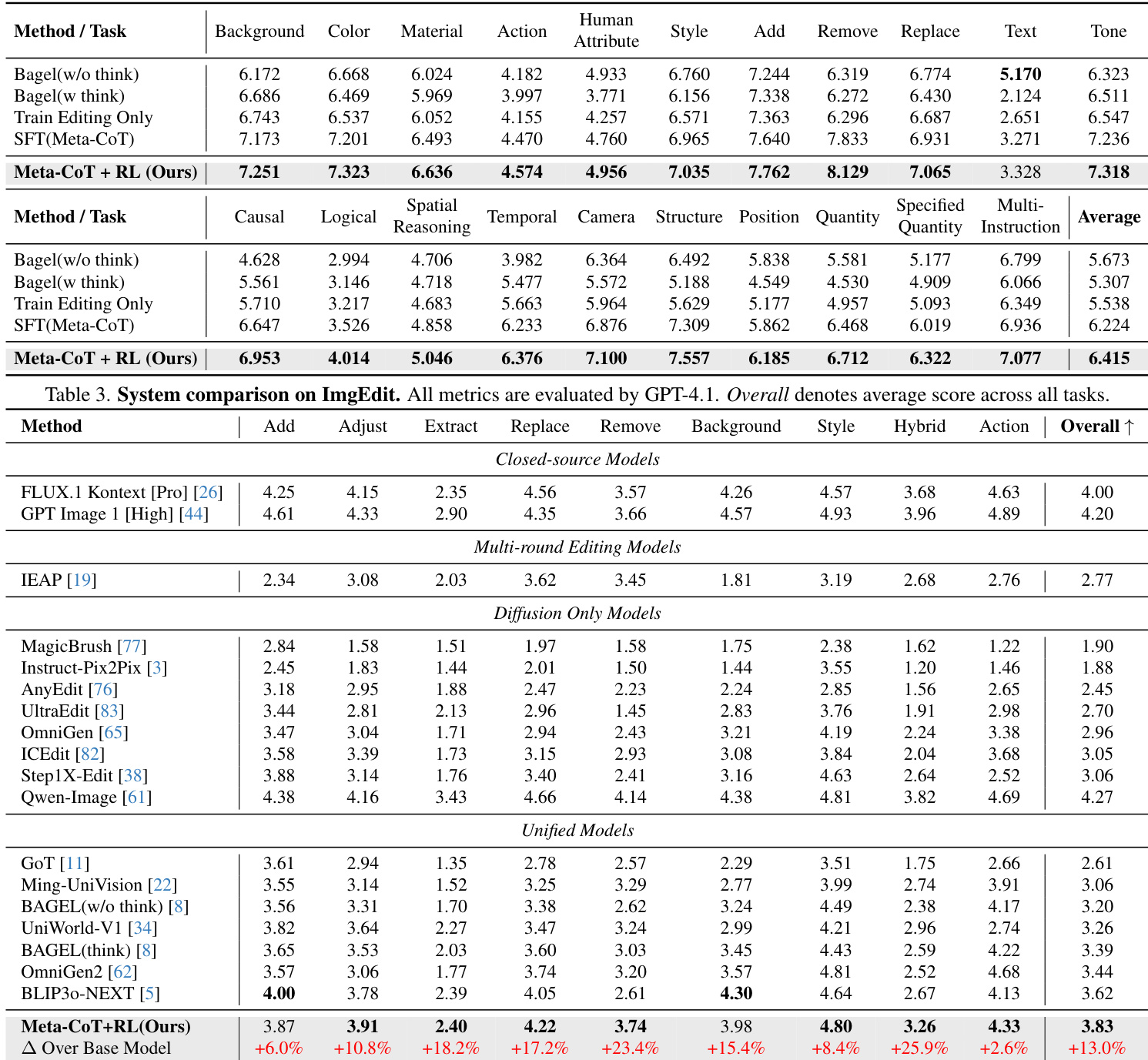
The authors conduct an ablation study to evaluate the impact of different training configurations on editing performance, focusing on the number of meta-tasks, the inclusion of task reasoning, and the integration of visual understanding data. Results show that increasing the number of meta-tasks improves performance up to a point, and that including task reasoning and sufficient understanding data are critical for achieving high-quality editing outcomes. The proposed method with full Meta-CoT and reinforcement learning achieves the best overall performance across all evaluation dimensions. Increasing the number of meta-tasks improves performance up to five, after which additional meta-tasks provide diminishing returns. Including task reasoning in Meta-CoT significantly enhances instruction following and overall editing quality. The integration of visual understanding data is crucial for maintaining high-quality reasoning and achieving optimal editing results.
{"summary": "The authors compare different training configurations to evaluate the impact of meta-task learning and visual understanding on editing performance. Results show that incorporating meta-task reasoning and sufficient visual understanding data leads to consistent improvements across multiple dimensions of editing quality. The method achieves the highest scores in all evaluated aspects, particularly in instruction following and reasoning quality.", "highlights": ["Incorporating meta-task reasoning significantly improves instruction following and overall editing performance compared to training without such reasoning.", "Adding visual understanding data during training enhances the model's ability to follow instructions and produce high-quality edits.", "The method consistently outperforms baseline configurations across all evaluation dimensions, with the largest gains observed in instruction adherence and reasoning quality."]
The authors evaluate their method on a benchmark of editing tasks, comparing it against several baselines including Bagel and a variant trained without Meta-CoT. Results show that their method achieves higher scores across all evaluation dimensions, with the most significant improvement in instruction following. The effectiveness of the Meta-CoT framework is further demonstrated through ablation studies that highlight the importance of task reasoning and joint training with understanding data. The proposed method outperforms baselines across all evaluation dimensions, particularly in instruction following. Ablation studies confirm that the Meta-CoT reasoning process and joint training with understanding data are critical for strong performance. The method shows improved instruction adherence and logical reasoning compared to baseline approaches in qualitative results.
The authors evaluate their approach against multiple baselines across diverse editing benchmarks while conducting ablation studies to assess the impact of training configurations such as meta-task quantity, task reasoning, and visual understanding data integration. These experiments validate that incorporating Meta-CoT reasoning and joint training with visual understanding data substantially enhances instruction following and logical reasoning, particularly in complex and multi-instruction scenarios. Overall, the proposed method consistently outperforms existing approaches across all evaluation dimensions, demonstrating that structured reasoning and multimodal data alignment are critical for achieving high-quality image editing outcomes.