Command Palette
Search for a command to run...
الاسترجاع المهاري المعزز للذكاء الاصطناعي الوكيل
الاسترجاع المهاري المعزز للذكاء الاصطناعي الوكيل
Weihang Su Jianming Long Qingyao Ai Yichen Tang Changyue Wang Yiteng Tu Yiqun Liu
الملخص
مع تطور النماذج اللغوية الكبيرة (LLMs) لتصبح وكلاءً قادرين على حل المشكلات بشكل مستقل، تزداد اعتماديتها على مهارات خارجية وقابلة لإعادة الاستخدام لمعالجة المهام التي تتجاوز قدراتها البارامترية المدمجة. في أنظمة الوكلاء الحالية، تمثل الاستراتيجية السائدة لإدماج المهارات في سردٍ صريح للمهارات المتاحة ضمن نافذة السياق. ومع ذلك، تفشل هذه الاستراتيجية في التوسع: فمع توسع مجموعات المهارات، تُستهزن ميزانيات السياق بسرعة، ويصبح الوكيل أقل دقة بشكل ملحوظ في تحديد المهارة المناسبة. ومن هذا المنطلق، تصف هذه الورقة منهج "التعزيز بالاسترجاع المهاري" (Skill Retrieval Augmentation - SRA)، وهو نموذج جديد حيث يقوم الوكلاء بالاسترجاع الديناميكي، والدمج، والتطبيق按需 للمهارات ذات الصلة من مجموعات مهارات خارجية كبيرة. لجعل هذه المشكلة قابلة للقياس، قمنا ببناء مجموعة مهارات واسعة النطاق، وأدخلنا "SRA-Bench"، وهو أول معيار لتقييم متكامل ومنقسم لمجرى SRA الكامل، الذي يغطي استرجاع المهارات، ودمجها، وتنفيذ المهمة النهائية. يحتوي SRA-Bench على 5400 حالة اختبار مكثفة القدرة و636 مهارة ذهبية مُنشأة يدوياً، والتي تم خلطها مع مهارات مشتتة تم جمعها من الويب لتكوين مجموعة مهارات واسعة النطاق تضم 26,262 مهارة. تُظهر التجارب الواسعة أن التعزيز القائم على الاسترجاع للمهارات يمكن أن يحسن أداء الوكيل بشكل كبير، مما يؤكد إمكانات هذا النموذج.
One-sentence Summary
This paper proposes Skill Retrieval Augmentation (SRA), enabling agents to dynamically retrieve, incorporate, and apply skills from external corpora instead of explicit enumeration, and introduces SRA-Bench, the first benchmark for decomposed evaluation of retrieval, incorporation, and execution comprising 5,400 capability-intensive test instances and 26,262 skills including 636 gold skills, to demonstrate that retrieval-based augmentation substantially improves agent performance.
Key Contributions
- This work formulates Skill Retrieval Augmentation (SRA) as a new paradigm where agents dynamically retrieve, incorporate, and apply relevant skills from large external corpora on demand. This formulation provides a concrete foundation for studying scalable skill augmentation as a distinct problem in agent systems.
- The study constructs a large-scale skill corpus containing 26,262 skills and introduces SRA-Bench as the first benchmark for decomposed evaluation of the full SRA pipeline. This resource includes 5,400 capability-intensive test instances and 636 manually constructed gold skills mixed with web-collected distractor skills.
- Extensive experiments demonstrate that retrieval-based skill augmentation can substantially improve agent performance when relevant capabilities are correctly accessed and utilized. The work establishes SR-Agents as a baseline family for systematic empirical study and validates the promise of the paradigm.
Introduction
As large language models evolve into agentic problem solvers, they increasingly rely on external reusable skills to handle tasks beyond their native parametric capabilities. Existing agent systems typically enumerate available skills within the context window, but this strategy fails to scale as skill corpora expand and rapidly consumes context budgets. To overcome this limitation, the authors formulate Skill Retrieval Augmentation (SRA), a new paradigm where agents dynamically retrieve, incorporate, and apply relevant skills from large external corpora on demand. They construct a large-scale skill corpus and introduce SRA-Bench, the first benchmark designed for decomposed evaluation of the full SRA pipeline. Their experiments validate the promise of retrieval-based skill augmentation while uncovering that current agents struggle with need-aware skill loading and effective incorporation.
Dataset
-
Dataset Composition and Sources
- The authors construct SRA-Bench from three components: capability-intensive test instances, manually annotated gold skills, and a large external skill corpus.
- Test instances are curated from six existing benchmarks including THEOREMQA, LOGICBENCH, TOOLQA, MEDCalc-Bench, CHAMP, and BIGCODEBENCH.
- The external corpus is formed by crawling public web sources such as GitHub, Skills.sh, and the Hugging Face Hub.
-
Key Details for Each Subset
- The benchmark contains 5,400 test instances associated with 636 unique gold skills.
- Source datasets undergo filtering to ensure capability intensity, such as removing image-dependent questions from THEOREMQA and excluding GSM8K from TOOLQA.
- The final skill corpus totals 26,262 documents, where only 2.4% are gold skills mixed with 25,626 noisy distractors.
-
Usage and Mixture
- This dataset serves as an evaluation benchmark rather than a training set, testing a system's ability to retrieve and apply correct capabilities from the noisy corpus.
- Each test instance is linked to one or more gold skills based on structured signals from the source data like theorem names or library imports.
- The evaluation requires the model to identify the correct skill from the large corpus and execute it to improve downstream task performance.
-
Processing and Metadata Construction
- Gold skills are created through a two-stage process involving LLM drafting followed by expert revision to ensure generality and correctness.
- Skills are stored as standardized Markdown artifacts containing procedural content, applicability conditions, and runnable resources like Python implementations.
- Leakage control measures include replacing overlapping examples with newly constructed ones and removing benchmark-specific constants to prevent trivializing the evaluation.
Method
The authors formalize the core operational pipeline of Skill Retrieval Augmentation (SRA) as a multi-stage process that separates the retrieval of relevant skills, their incorporation into the active problem-solving state, and their ultimate application to task performance. This framework is designed to augment an agent with relevant external capabilities on demand rather than relying on a fixed set of pre-exposed skills.
A standard skill is defined as a reusable capability package that enables an agent to solve a recurring class of problems. Formally, let C={s1,s2,…,sN} denote a skill corpus containing N skills. Each skill si∈C is represented as a tuple:
si=(ni,ri,ci,πi),where ni is the name serving as a semantic identifier, ri is a short description, ci is the main content including instructions and constraints, and πi is the executable payload such as code or tools.
The overall architecture follows a three-stage pipeline illustrated in the framework diagram below.
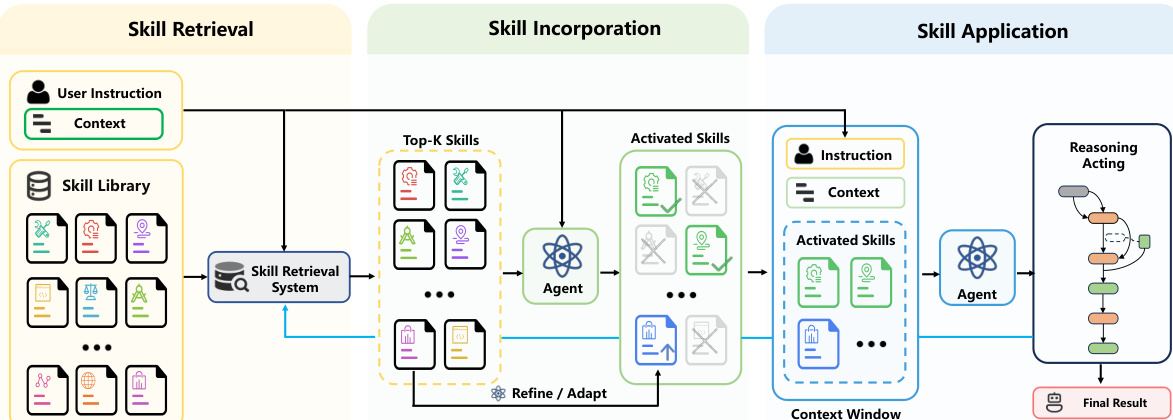
The first stage is Skill Retrieval. A retriever R maps the user query q and the skill corpus C to a ranked list of candidate skills:
Lk=R(q,C)=[s(1),s(2),…,s(k)],s(j)∈C, k≪N.This stage reduces a massive external capability space into a manageable ranked list where earlier positions indicate higher relevance to the current task.
The second stage is Skill Incorporation. Given the retrieved candidates Lk, the agent determines whether external skills should be used and how they should be integrated into the active problem-solving state. This process is denoted as:
S=G(q,Lk;M),where M is the underlying base language model and S represents the skill representations prepared for downstream solving. These representations may be a selected subset of retrieved skills or transformed variants such as rewritten or model-adapted forms. Importantly, S may be empty if the agent determines its parametric capability is sufficient or if no retrieved skill is deemed useful.
The final stage is Skill Application. Conditioned on the incorporated skills S, the agent applies the corresponding capabilities during task solving to produce a final response:
A^=F(q,S;M).This stage assesses whether the incorporated skills are effectively leveraged to improve downstream behavior, including correct invocation, integration into reasoning, and behavioral adaptation. Successful incorporation does not guarantee successful application, as the model must properly operationalize the skills during the solving process.
Experiment
This systematic study evaluates Scalable Skill Augmentation across six benchmarks using various LLMs and skill use strategies such as full injection and progressive disclosure. Results demonstrate that while external skills substantially improve performance, gains depend heavily on controlled utilization rather than retrieval alone. Agents prove brittle to retrieval noise and generally lack relevance or need awareness when loading skills, indicating that robust augmentation requires reliable mechanisms for selective skill incorporation.
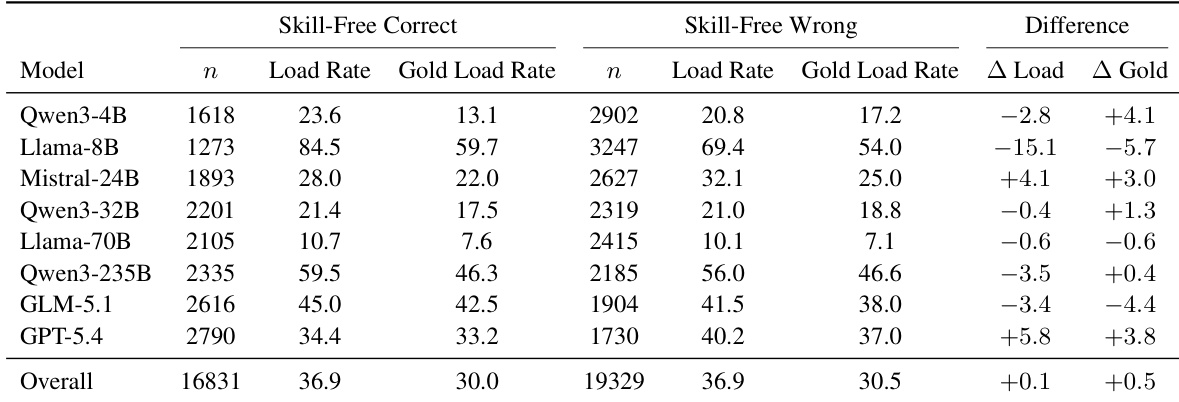
The authors evaluate whether language models exhibit need-aware skill loading by comparing loading rates on tasks they can solve natively versus those they cannot. Results indicate that most models do not significantly increase their skill-loading frequency when facing tasks they fail to solve without assistance, suggesting that skill loading remains largely indiscriminate rather than compensatory. While some frontier models show modest improvements in aligning loading behavior with need, the overall trend points to a disconnect between capability gaps and the decision to utilize external skills. The overall difference in skill-loading rates between tasks solved natively and those failed is negligible, indicating a general lack of need-awareness across models. While some frontier models show a positive correlation between task difficulty and loading frequency, several open-source models exhibit negative differences, loading skills less often when they fail. Analysis of gold skill loading rates reveals that even when the correct skill is available, models do not consistently prioritize loading it more during instances where they lack native capability.
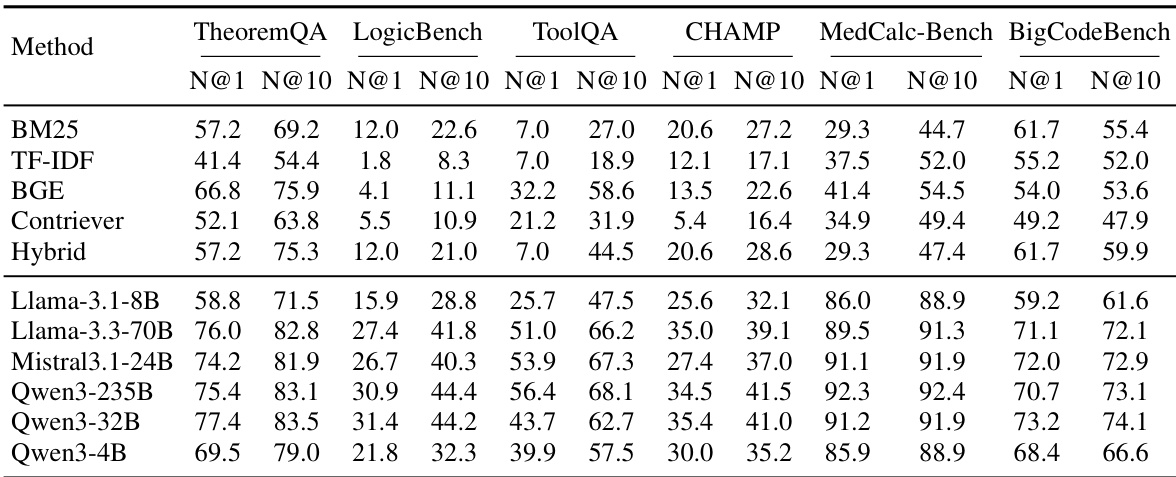
The experiment compares traditional retrieval methods against LLM-based rerankers across six benchmarks to assess skill retrieval quality. Results demonstrate that LLM-based reranking significantly improves ranking performance over standard retrievers, with larger models generally achieving better results. However, effectiveness varies by dataset, indicating that retrieval difficulty is task-dependent. LLM-based rerankers consistently outperform traditional retrievers like BM25 and BGE in ranking relevant skills. Larger models generally achieve higher ranking scores, though performance varies across specific benchmarks. MedCalc-Bench yields the highest retrieval scores while LogicBench presents the most challenging retrieval task.
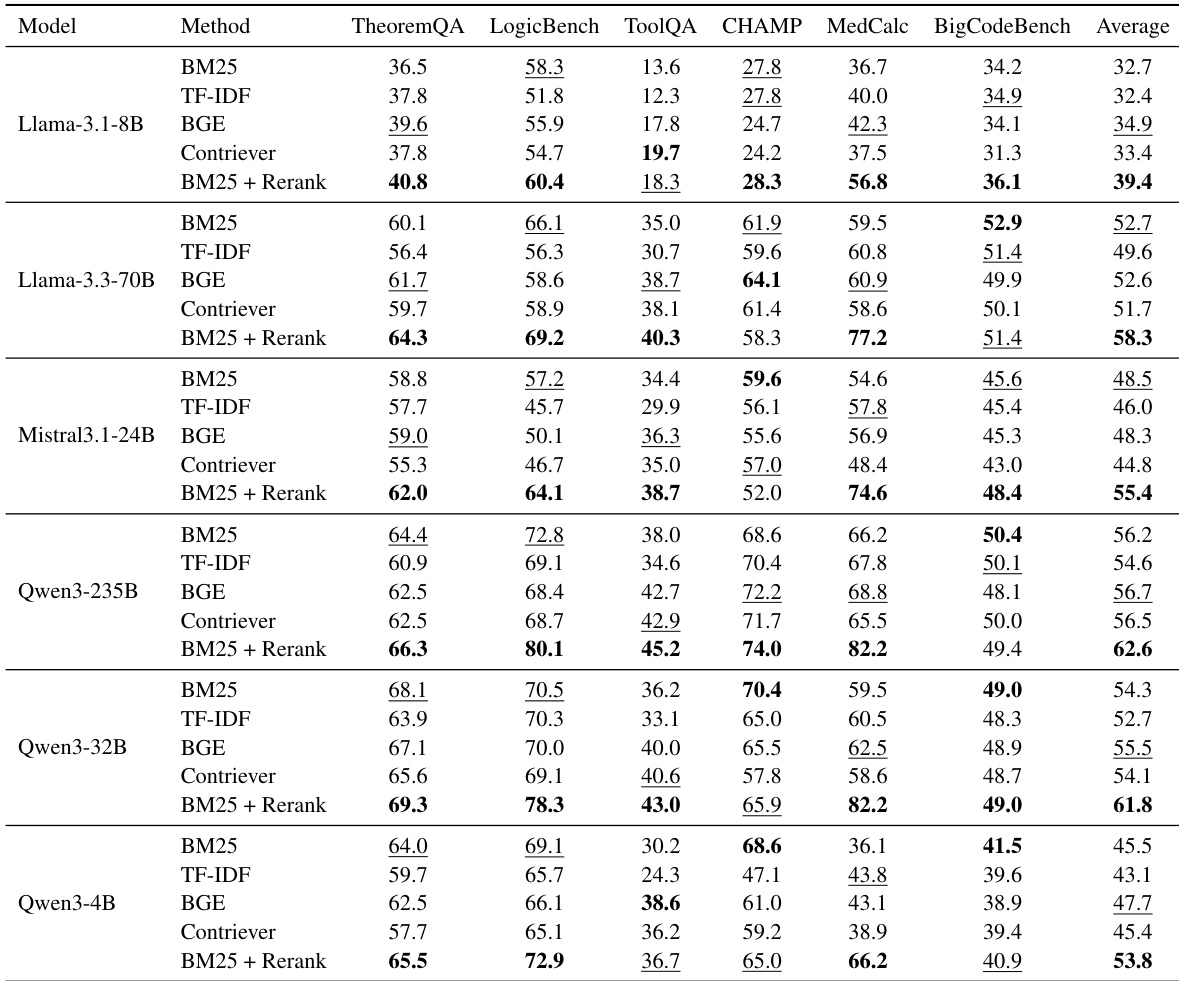
The authors evaluate the impact of different retrieval strategies on end-task performance across six LLMs and six benchmarks. Results indicate that combining BM25 retrieval with a reranking step consistently yields the highest average performance compared to standalone sparse or dense retrieval methods. This trend holds across various model sizes, suggesting that precise skill selection is critical for effective augmentation. The BM25 + Rerank method achieves the highest average scores across all evaluated model families. Standalone retrieval baselines exhibit more variable performance, with dense methods like BGE often trailing the reranking approach. The performance advantage of reranking persists regardless of the underlying model scale, from smaller to larger parameter counts.
The authors evaluate various skill-use strategies across multiple large language models and benchmarks to determine if external skills improve agent performance. Results indicate that while providing gold skills consistently yields the best results, practical retrieval-based methods like LLM Selection can meaningfully outperform direct prompting without external support. Oracle Skill consistently achieves the highest performance across all tested model families and benchmarks. LLM Selection generally outperforms Full-Skill Injection and Progressive Disclosure in average scores. LLM Direct baseline performance is consistently lower than skill-augmented methods, confirming the value of external knowledge.
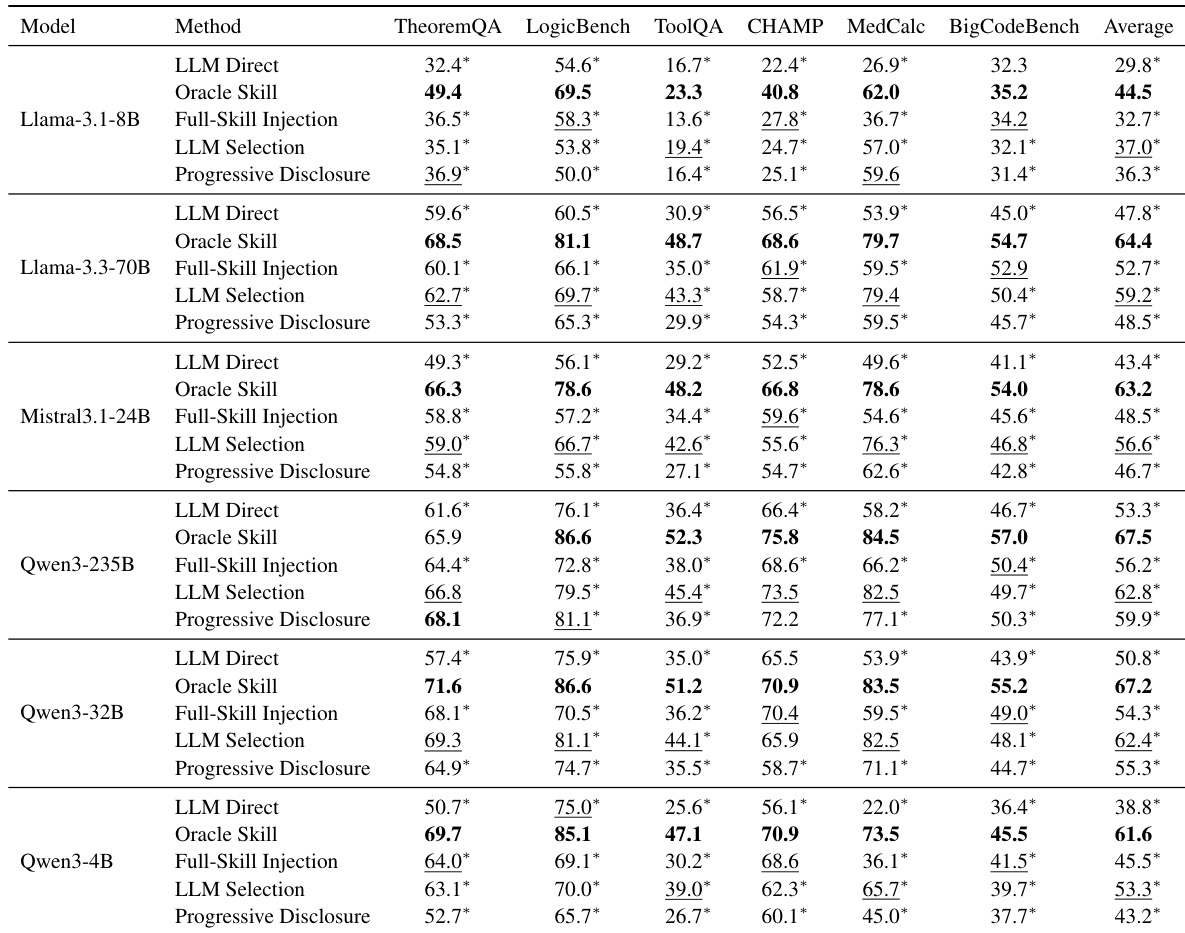
The authors evaluate multiple large language models across six diverse benchmarks to assess the impact of skill retrieval augmentation on agent performance. Results demonstrate that while providing the correct skill significantly boosts capability, practical retrieval methods yield uneven gains that depend heavily on how the skills are exposed to the model. Selection-based strategies generally prove more robust and effective than direct injection or progressive disclosure methods. Providing the correct external skill consistently outperforms using native parametric knowledge alone. Selection-based skill exposure strategies translate retrieval results into downstream gains more reliably than other methods. Performance improvements vary significantly across different models and task domains, highlighting challenges in robust skill utilization.
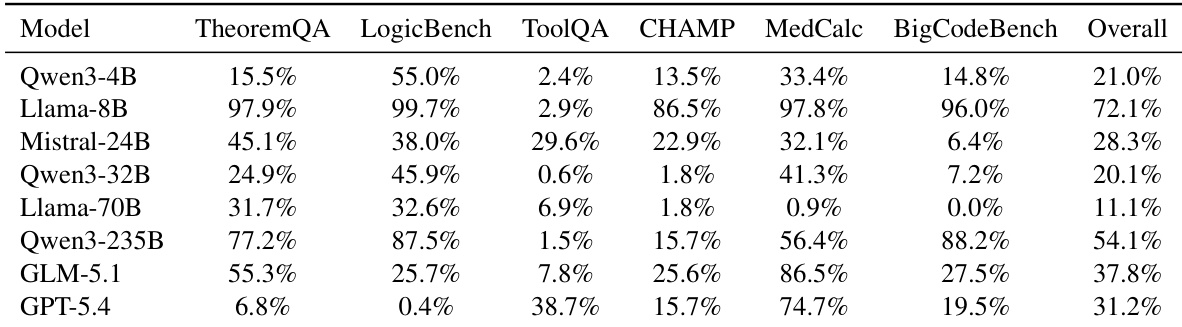
The experiments evaluate skill loading awareness, retrieval quality, and skill-use strategies across multiple large language models and diverse benchmarks. Results indicate that most models lack need-awareness by failing to prioritize external skills when native capabilities are insufficient, although LLM-based rerankers and combined retrieval strategies significantly outperform traditional methods. Furthermore, selection-based skill exposure proves more robust than direct injection, yet overall performance gains remain dependent on the specific model and task domain.