Command Palette
Search for a command to run...
قوالب الانتشار: إطار عمل إضافي موحد للتحكم في عمليات الانتشار
قوالب الانتشار: إطار عمل إضافي موحد للتحكم في عمليات الانتشار
Zhongjie Duan Hong Zhang Yingda Chen
الملخص
وسّعت الطرق الانتشارية القابلة للتحكم بشكل كبير من الفائدة العملية لنماذج الانتشار، إلا أنها تُطوّر عادةً كنُظم منفصلة ومحدّدة لكل بنية أساسية (backbone)، وتتسم بآليات تدريب غير متوافقة، وتنسيقات معلمات مختلفة، وواجهات زمنية (runtime hooks) غير متجانسة. ويؤدي هذا التفتت إلى صعوبة إعادة استخدام البنى التحتية عبر المهام، أو نقل القدرات بين البنى الأساسية المختلفة، أو تركيبة عدة وسائل تحكم داخل خط إنتاج (pipeline) واحد للتوليد.نقدّم هنا "قوالب الانتشار" (Diffusion Templates)، وهو إطار عمل موحد ومفتوح قائم على الإضافات (plugins)، يفصل عملية الاستدلال للنموذج الأساسي عن حقن القدرات القابلة للتحكم. ويُنظَّم هذا الإطار حول ثلاث مكونات رئيسية: نماذج القوالب التي تربط مدخلات محددة بالمهمة إلى تمثيل وسيط للقدرات، ومخزن مؤقت للقوالب يعمل كواجهة موحّدة لحقن القدرات، وخط إنتاج للقوالب يقوم بتحميل، ودمج، وحقن مخزن مؤقت واحد أو أكثر للقوالب في وقت تشغيل الانتشار الأساسي. ونظراً لأن الواجهة مُعرَّفة على مستوى النظام ولا ترتبط ببنية تحكم محددة، فإنها تدعم حاملات قدرات غير متجانسة مثل ذاكرة التخزين المؤقت للقيم-المفاتيح (KV-Cache) والـ LoRA تحت نفس التجريدية.استناداً إلى هذا التصميم، قمنا ببناء مجموعة نماذج متنوعة تغطي التحكم الهيكلي، وتعديل السطوع، وتعديل اللون، وتحرير الصور، والدقة الفائقة، وتعزيز الحدة، والمحاذاة الجمالية، والإشارة المرجعية للمحتوى، وملء الفراغات موضعياً، والتحكم في العمر. وتُظهر دراسات الحالة هذه أن قوالب الانتشار يمكن أن توحد مجموعة واسعة من مهام التوليد القابلة للتحكم، مع الحفاظ على الوحدات النمطية، والقابلية للتركيب، والقابلية العملية للتوسع عبر البنى الأساسية للتطور السريع. سيتم فتح جميع الموارد برمجياً، بما في ذلك الأكواد البرمجية، والنماذج، ومجموعات البيانات.
One-sentence Summary
The authors present Diffusion Templates, a unified plugin framework that decouples base-model inference from controllable capability injection by standardizing heterogeneous carriers like LoRA and KV-Cache through a systems-level interface, unifying diverse generation tasks such as structural control, editing, and super-resolution while preserving modularity and composability across evolving diffusion backbones.
Key Contributions
- The paper introduces Diffusion Templates, a unified plugin framework that decouples base-model inference from controllable capability injection. The architecture coordinates three components: template models that map task-specific inputs to intermediate representations, a standardized template cache for capability injection, and a template pipeline that loads and merges multiple caches into the base diffusion runtime.
- By establishing a systems-level interface for capability injection, the framework enables heterogeneous control carriers such as KV-Cache and LoRA to operate under a single abstraction. This design removes architecture-specific adaptations and supports cross-backbone composability across rapidly evolving diffusion foundations.
- The framework consolidates over ten distinct generation tasks into a single model zoo, covering structural control, image editing, super-resolution, and aesthetic alignment. All associated code, models, and datasets are publicly released to enable modular deployment across diverse diffusion architectures.
Introduction
Diffusion models have established themselves as the foundation for high-quality visual generation, yet practical applications demand precise control over structure, style, and content. This requirement has spurred the development of numerous control techniques, including parameter-efficient adaptations like LoRA and conditional modules such as ControlNet, which are essential for advanced image synthesis and editing tasks. However, these methods are typically deployed as isolated, backbone-specific systems with incompatible training pipelines, parameter formats, and runtime hooks. This fragmentation creates a systems bottleneck that hinders infrastructure reuse, capability transfer across backbones, and the composition of multiple controls, often necessitating complex handcrafted engineering to resolve conflicts in conditioning pathways. The authors leverage a plugin-based abstraction to introduce Diffusion Templates, a unified framework that decouples base-model inference from capability injection via a standardized interface comprising Template models, a Template cache, and a Template pipeline. By treating heterogeneous capability carriers like KV-Cache and LoRA as pluggable modules, the framework allows task-specific inputs to be converted into intermediate representations that can be loaded, merged, and injected independently, enabling modular composition without modifying the underlying diffusion architecture.
Method
The Diffusion Templates framework presents a unified plugin architecture for controllable diffusion generation, decoupling base-model inference from control-capability injection. The framework operates through three core components: the Template cache, Template model, and Template pipeline. The Template cache serves as a standardized interface for representing model capabilities, constrained to a subset of input arguments accepted by the diffusion pipeline of base models. This design aligns with existing engineering abstractions of diffusion frameworks, enabling new capabilities to be integrated by extending pipeline arguments rather than rewriting denoising internals, while providing a stable contract between plugins and base pipelines. Among candidate interfaces, KV-Cache is the most practical and recommended type due to its strong representational capacity, direct influence on generation behavior, and natural support for sequence-level concatenation, which is critical when multiple templates are active. However, the framework does not restrict the cache format, allowing alternative representations such as lightweight parameterizations like LoRA to be supported.
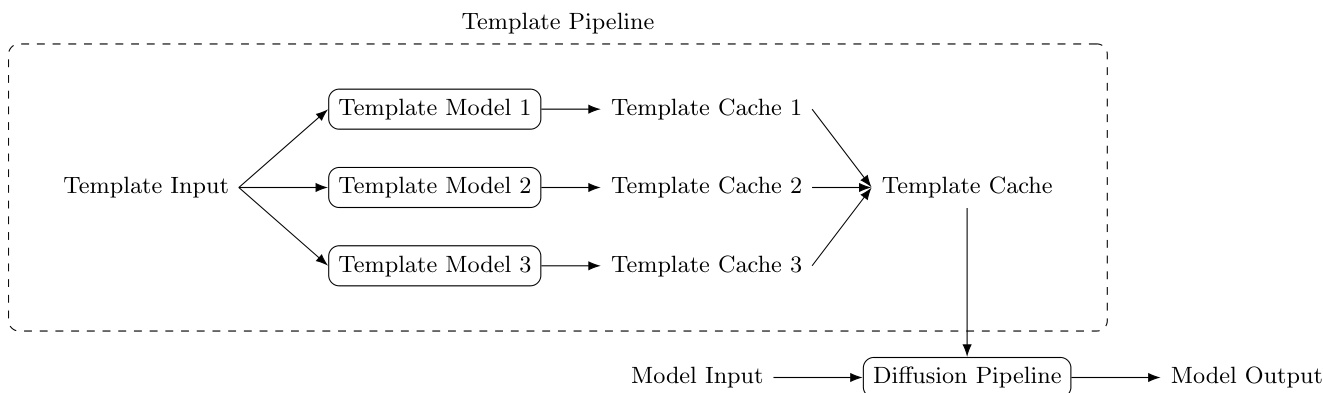
A Template model is any model that maps arbitrary input to the standardized Template cache format. Its architecture is unrestricted, and it can be packaged as a local directory or hosted in remote model hubs. Each Template model exposes two interfaces: processInputs for no-gradient preprocessing and feature preparation, and forward for gradient-related computation that produces Template cache outputs. This interface split maintains model flexibility while ensuring framework-level compatibility, allowing heterogeneous architectures to run under a unified runtime.

The Template pipeline orchestrates the loading, execution, and composition of multiple Template models. During inference, given one or more enabled Template models, the process proceeds in three steps: first, each Template model processes its input to produce a Template cache; second, caches are merged according to their type—direct concatenation is used for KV-Cache; third, the merged cache is passed into the base diffusion pipeline alongside normal generation arguments. Because KV-Cache supports concatenation, multiple Template models can operate jointly without altering the base denoising logic. Template models execute outside the iterative denoising process, so runtime overhead remains low, and inference remains efficient. In practice, template inference can be scheduled in a round-robin manner with lazy loading to reduce peak memory usage when many templates are configured.
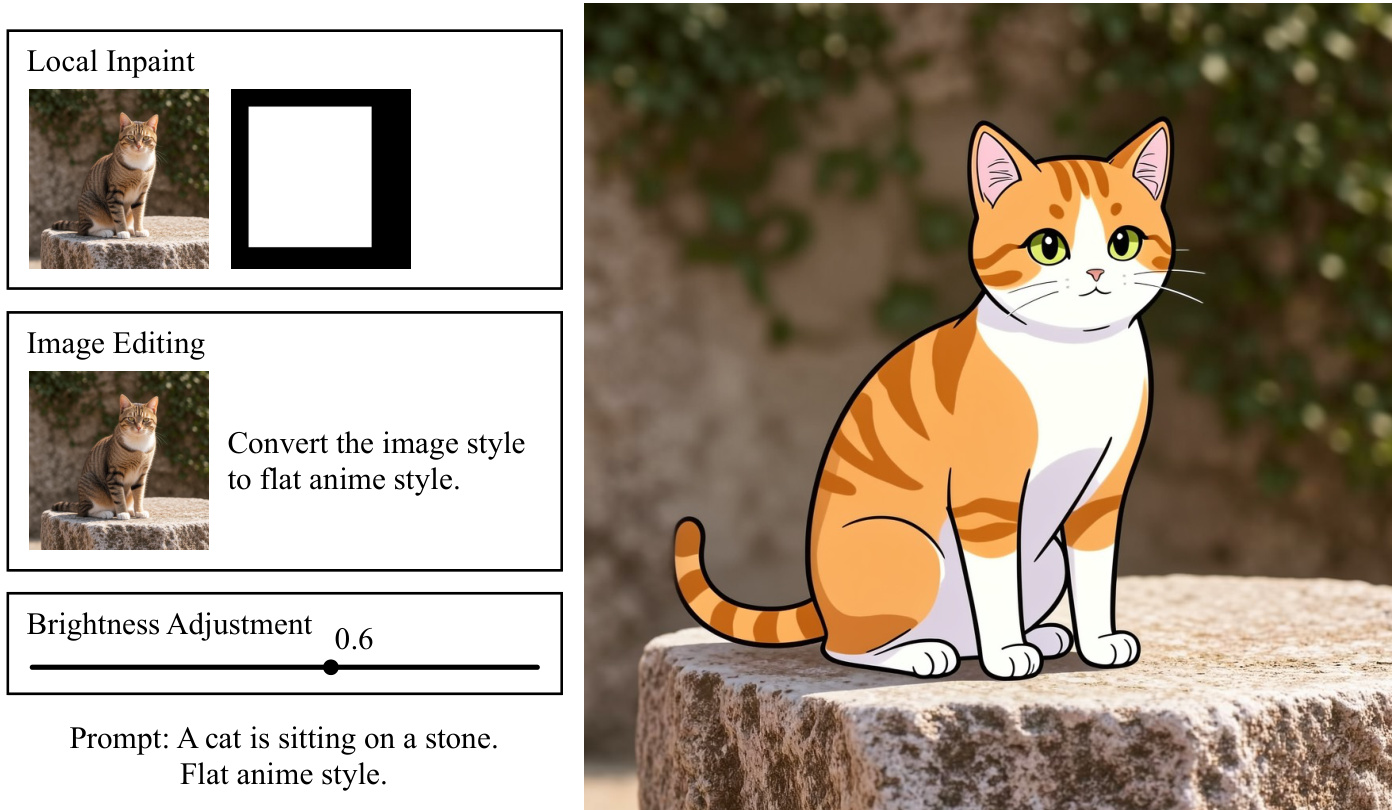
Template models are trained using a standard paradigm similar to ControlNet and LoRA, where trainable side branches are attached to the pretrained base model, with all base-model parameters frozen. Optimization targets the new branches using the original pretraining loss of the base model, preserving the learning objective while transferring task-specific capabilities into the Template pathway. Training is organized into two stages: Stage I executes input processing in a no-gradient pipeline to produce reusable intermediate features that can be aggressively cached; Stage II restricts optimization to the gradient-relevant forward path under training objectives defined on the Template cache. This separation reduces redundant computation and improves training efficiency. The training framework is built on DiffSynth-Studio, which supports the standardized processInputs and forward interfaces. Template models can be trained for diverse tasks, including structural control, brightness and color adjustment, image editing, super-resolution, and local inpainting, each with distinct architectural designs tailored to the control task. For instance, structural control models use an architecture similar to ControlNet but communicate control signals through KV-Cache instead of residual branches, while brightness and color adjustment models follow a lightweight design with positional encoding and fully connected layers. Image editing and super-resolution models use architectures similar to the structural-control model, transferring editing and upscaling capabilities into the Template pathway. Local inpainting models provide soft control and are combined with pipeline-level hard constraints to enforce content preservation outside masked regions. Multiple Template models can be fused effectively within a single generation pipeline, with fusion strategies depending on the cache format: KV-Cache models are fused by concatenating caches along the sequence dimension, while LoRA-based models are fused by concatenating parameters along the rank dimension. When different models emit caches in heterogeneous formats, their modules can be enabled simultaneously without conversion, enabling on-demand loading and supporting the fusion of an arbitrary number of capabilities without significant GPU memory growth.
Experiment
By training diverse Template models on a base diffusion architecture with standardized generation parameters, the experiments validate the framework's expressiveness and extensibility across multiple control domains. Sharpness control demonstrates reliable adjustment of perceptual detail through edge density proxies, while aesthetic alignment successfully translates discrete human preference data into continuous conditioning that enhances composition and generalizes beyond training ranges. Additionally, age control confirms the method's capacity for semantically rich, continuous manipulation of portrait features while preserving identity and quality. Collectively, these results establish Template models as a flexible mechanism for both low-level visual tuning and high-level subjective alignment.