Command Palette
Search for a command to run...
تحليل وتوليد الفيديو عبر دالة التقدم الدلالي (Semantic Progress Function)
تحليل وتوليد الفيديو عبر دالة التقدم الدلالي (Semantic Progress Function)
Gal Metzer Sagi Polaczek Ali Mahdavi-Amiri Raja Giryes Daniel Cohen-Or
الملخص
غالبًا ما تتطور التحولات التي تنتجها نماذج توليد الصور والفيديو بطريقة غير خطية للغاية؛ حيث تتبع فترات طويلة يكاد لا يتغير فيها المحتوى قفزات دلالية مفاجئة وحادة. ولتحليل هذا السلوك وتصحيحه، نقدم "دالة التقدم الدلالي" (Semantic Progress Function)، وهي تمثيل أحادي البعد يلتقط كيفية تطور معنى تسلسل معين بمرور الوقت. لكل إطار (frame)، نقوم بحساب المسافات بين الـ semantic embeddings ونقوم بملاءمة منحنى سلس يعكس التحول الدلالي التراكمي عبر التسلسل. وتكشف انحرافات هذا المنحنى عن الخط المستقيم عن عدم انتظام الإيقاع الدلالي (semantic pacing).وبناءً على هذه الرؤية، نقترح إجراءً للخطية الدلالية (semantic linearization procedure) يعيد تمثيل المعلمات (reparameterizes) -أو إعادة ضبط التوقيت (retimes)- للتسلسل بحيث يتكشف التغيير الدلالي بمعدل ثابت، مما يؤدي إلى انتقالات أكثر سلاسة وتماسكًا. وإلى جانب عملية الخطية، يوفر إطار عملنا أساسًا غير مرتبط بنموذج معين (model-agnostic) لتحديد الاضطرابات الزمنية، ومقارنة الإيقاع الدلالي عبر المولدات (generators) المختلفة، وتوجيه كل من تسلسلات الفيديو المولدة والواقعية نحو إيقاع مستهدف عشوائي.
One-sentence Summary
The authors introduce a Semantic Progress Function that captures semantic evolution by fitting a smooth curve to semantic embedding distances to reveal uneven pacing and propose a semantic linearization procedure that retimes sequences for constant semantic change to yield smoother transitions, providing a model-agnostic foundation for identifying temporal irregularities and steering both generated and real-world video sequences toward arbitrary target pacing.
Key Contributions
- A Semantic Progress Function is introduced to represent semantic evolution as a one-dimensional curve by computing distances between semantic embeddings across a sequence. This metric objectively quantifies temporal linearity and reveals uneven semantic pacing.
- A semantic linearization procedure is proposed to reparameterize video sequences so that semantic change unfolds at a constant rate. This method warps temporal positions based on measured semantic content via the Semantic Progress Function to yield smoother and more coherent transitions.
- The framework provides a model-agnostic foundation for identifying temporal irregularities and steering both generated and real-world video sequences toward arbitrary target pacing. This approach enables the transformation of in-the-wild videos into a constant pace without requiring the manual user annotation necessitated by existing guidance-based methods.
Introduction
Generative video models frequently produce transitions where semantic meaning evolves unevenly, causing abrupt jumps after long static periods that undermine perceptual coherence. While prior work addresses temporal smoothness or latent interpolation, these methods fail to quantify the rate of semantic change or compare pacing across different generators. To resolve this, the authors introduce the Semantic Progress Function, a one-dimensional representation that measures cumulative semantic shift to identify irregularities. Building on this metric, they propose a model-agnostic linearization procedure that reparameterizes video sequences to ensure transformations unfold at a constant rate without requiring fine-tuning.
Method
The authors introduce the Semantic Progress Function (SPF) as a model-agnostic formulation to capture semantic evolution over time. Formally, given a video consisting of T frames {x1,x2,…,xT}, the SPF is defined as a scalar-valued function Si∈R mapped from the frame index i. This representation distills complex visual transformations into a one-dimensional trajectory. The construction proceeds in two stages: first computing pairwise semantic distances between frames, and then integrating these differences over time.
To measure semantic differences, the method utilizes pretrained semantic image embedders such as SigLIP. Each video frame xi is mapped to a semantic embedding zi∈Rd. The semantic distance between frames i and j is computed using an angular metric in the embedding space: dij=arccos(zi⊤zj) The SPF vector S∈RT is estimated such that its pairwise temporal differences approximate these semantic distances. This is formulated as a regularized, weighted least-squares objective: minS∈RT(AS−b)⊤W(AS−b)+λS⊤S where A encodes the linear constraints for frame pairs, b collects the distances, and W is a diagonal weighting matrix that favors temporally local constraints.
As shown in the figure below, the SPF effectively visualizes semantic pacing. The top graph depicts the SPF of a raw input video where a cat abruptly transforms into a lion. The slope of the function increases sharply at the transition point, reflecting the semantic discontinuity. The bottom graph illustrates the SPF after retiming, where the semantic progression appears significantly steadier.
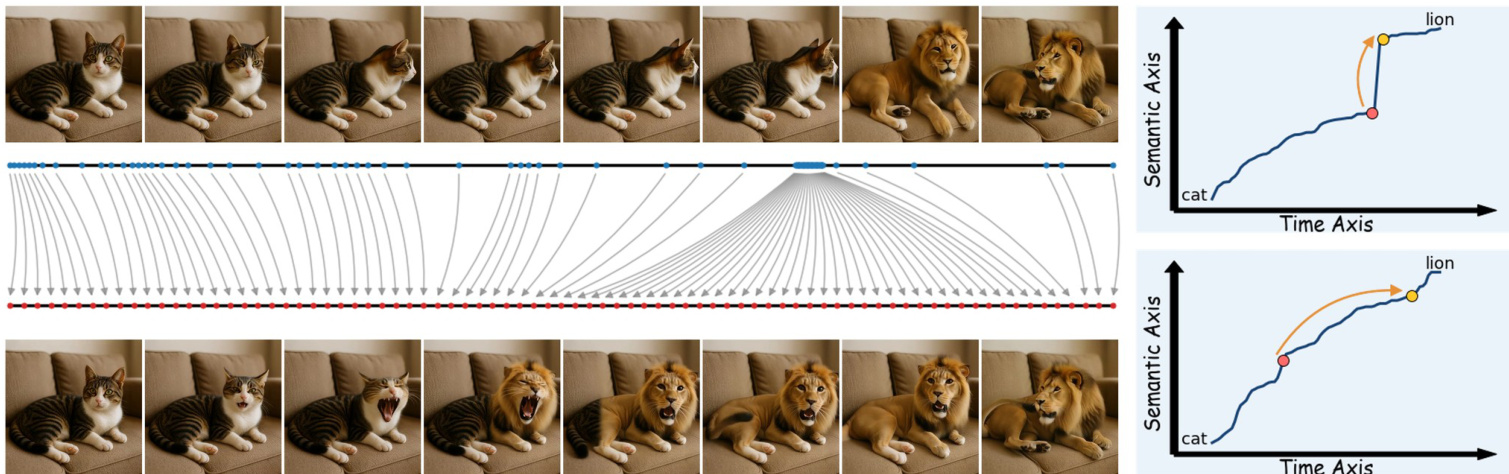
Building on this analysis, the authors propose semantic linearization via ReTime to reparameterize time so that semantic change progresses at a constant rate. For generated videos, this is achieved by warping the model's temporal positional encodings. The SPF S is normalized to [0,1], and warped temporal positions τk are computed via inversion: τk=S−1(T−1k) This stretches time in regions of rapid semantic change and compresses stable regions. Since modern video diffusion transformers employ Rotary Position Embeddings (RoPE), the authors introduce frequency-aware warping. Low-frequency bands, which control long-range structure, are warped more strongly, while high-frequency bands remain closer to linear time to preserve local motion smoothness: pt(b)=(1−αb)t+αbτt The warping strength αb decays exponentially across frequency bands. Additionally, a timestep-dependent modulation applies stronger warping early in the denoising process to concentrate semantic correction during structure formation.
For existing videos where generation is not controllable, the method segments the SPF into piecewise linear components using segmented least squares. This isolates regions of near-constant semantic velocity. Refer to the framework diagram for an example of this process on a cinematic clip, where the segmented SPF (dotted line) guides the redistribution of temporal capacity to smooth abrupt transitions.
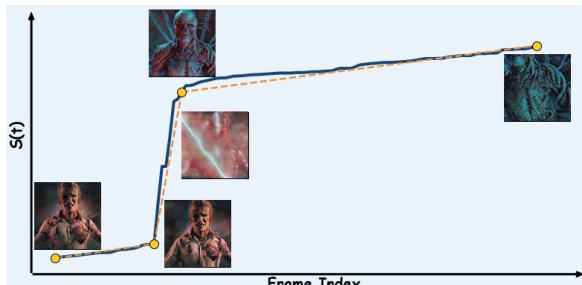
Intermediate clips are then regenerated for each segment to ensure uniform pacing. The first and last frames of each segment serve as semantic keyframes for regeneration. This approach allows the use of various open or closed-source models, as long as they can be conditioned on keyframes or first-last frames, ensuring that the duration of each segment is proportional to the magnitude of the semantic change between its boundary frames.
Experiment
The evaluation suite validates the framework by comparing retiming strategies against baselines, applying the method to real cinematic footage, and verifying accuracy through controlled synthetic experiments. Qualitative findings show that operating directly on model features prevents ghosting artifacts and external quality bottlenecks, enabling smooth semantic transitions that baseline methods fail to resolve. Synthetic benchmarks confirm the Semantic Progress Function accurately tracks pacing profiles independent of pixel motion, while ablation studies identify SigLIP as the optimal embedder for capturing semantic shifts. Finally, quantitative metrics and user studies demonstrate that the approach maintains visual fidelity while significantly improving semantic pacing.
The authors evaluate the visual fidelity of their retiming framework by comparing original and retimed outputs from Wan2.2 and LTX-2 models using VBench metrics. The results demonstrate that the retimed videos maintain quality levels nearly identical to the original generations across aesthetic, motion, and temporal dimensions. This confirms that the proposed temporal manipulation preserves the intrinsic visual capabilities of the base models. Aesthetic quality scores for retimed videos remain comparable to the original model outputs. Motion smoothness and temporal fidelity metrics show negligible deviation between original and retimed sequences. The evaluation confirms that the retiming process preserves the visual fidelity of the underlying generative models.
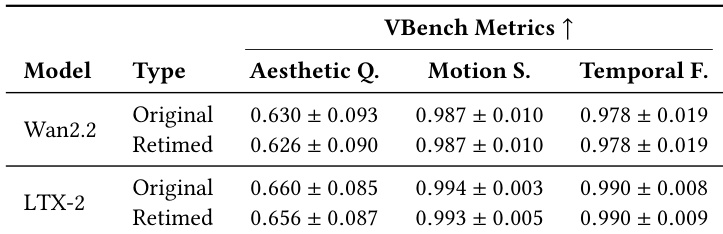
The authors evaluate the visual fidelity of their retiming framework by comparing original and retimed outputs from Wan2.2 and LTX-2 models using VBench metrics. Results demonstrate that retimed videos maintain quality levels nearly identical to the original generations across aesthetic, motion, and temporal dimensions. This confirms that the proposed temporal manipulation preserves the intrinsic visual capabilities of the base models.