Command Palette
Search for a command to run...
StyleID: مجموعة بيانات ومقياس مدركان للإدراك من أجل التعرف على هوية الوجه غير المتأثر بالأسلوب (Stylization-Agnostic)
StyleID: مجموعة بيانات ومقياس مدركان للإدراك من أجل التعرف على هوية الوجه غير المتأثر بالأسلوب (Stylization-Agnostic)
Kwan Yun Changmin Lee Ayeong Jeong Youngseo Kim Seungmi Lee Junyong Noh
الملخص
يهدف أسلوب التنميط الإبداعي للوجه (Creative face stylization) إلى تقديم الصور الشخصية بقوالب بصرية متنوعة، مثل الرسوم الكرتونية، والرسومات التخطيطية (sketches)، واللوحات الفنية، مع الحفاظ في الوقت ذاته على الهوية الملامح المميزة للشخص. ومع ذلك، فإن مشفرات الهوية (identity encoders) الحالية، والتي يتم تدريبها ومعايرتها عادةً بناءً على الصور الفوتوغرافية الطبيعية، تُظهر هشاشة شديدة عند التعامل مع الأنماط الفنية (stylization). فهي غالبًا ما تخطئ في تفسير التغيرات في الملمس (texture) أو لوحة الألوان على أنها انحراف في الهوية (identity drift)، أو تفشل في اكتشاف المبالغات الهندسية (geometric exaggerations). ويكشف هذا عن الافتقار إلى إطار عمل محايد للنمط (style-agnostic framework) لتقييم والإشراف على اتساق الهوية عبر مختلف الأنماط ودرجات قوتها.ولمعالجة هذه الفجوة، نقدم StyleID، وهو عبارة عن مجموعة بيانات وإطار تقييم مدرك للإدراك البشري للهوية الوجهية تحت تأثير التنميط الفني. يتكون StyleID من مجموعتي بيانات: (i) StyleBench-H، وهي معيار مرجعي (benchmark) يرصد أحكام التحقق البشرية (التشابه والاختلاف) عبر عمليات التنميط القائمة على تقنيات الانتشار (diffusion-based) ومطابقة التدفق (flow-matching-based) عند مستويات قوة نمط متعددة، و(ii) StyleBench-S، وهي مجموعة إشراف مستمدة من منحنيات قوة الإدراك النفسي (psychometric recognition-strength curves) التي تم الحصول عليها من خلال تجارب الاختيار القسري بين بديلين (2AFC) المحكومة.وبالاعتماد على StyleBench-S، نقوم بإجراء ضبط دقيق (fine-tune) للمشفرات الدلالية (semantic encoders) الحالية لمواءمة ترتيب تشابهها مع الإدراك البشري عبر مختلف الأنماط ودرجات القوة. وتثبت التجارب أن نماذجنا المعايرة تحقق ارتباطًا أعلى بكثير مع الأحكام البشرية، وتُظهر متانة (robustness) معززة عند التعامل مع الصور الشخصية المرسومة من قبل فنانين والتي تقع خارج نطاق البيانات الأصلية (out-of-domain).جميع مجموعات البيانات، والأكواد البرمجية، والنماذج المدربة مسبقًا متاحة للعموم عبر الرابط التالي: https://kwanyun.github.io/StyleID_page/
One-sentence Summary
To address the brittleness of current identity encoders under artistic stylization, the authors propose StyleID, a perception-aware framework and dataset comprising StyleBench-H for human verification benchmarks and StyleBench-S for supervision via psychometric recognition-strength curves, which fine-tunes semantic encoders to align similarity orderings with human perception and enhances robustness for out-of-domain, artist-drawn portraits.
Key Contributions
- The paper introduces StyleBench-H, a human-annotated benchmark designed to evaluate identity preservation by capturing perception-aligned same-different verification judgments across various stylization methods and strengths.
- This work presents StyleBench-S, a large-scale synthetic supervision dataset derived from psychometric recognition-strength curves that provides a structured training signal for learning identity representations stable under stylization.
- The researchers developed StyleID, a stylization-agnostic facial identity recognition model that achieves higher correlation with human judgments than existing encoders and includes lightweight variants for improved computational efficiency.
Introduction
Creative face stylization is essential for personalized avatars and digital content, yet maintaining recognizable identity remains a significant challenge. Current identity encoders are typically trained and calibrated on natural photographs, making them brittle when applied to stylized images. These models often fail to distinguish between actual identity drift and changes in texture, color, or exaggerated geometry.
The authors address this gap by introducing StyleID, a perception-aware framework designed for identity recognition under diverse stylization methods and strengths. They contribute two novel datasets: StyleBench-H, a human-judged benchmark for identity verification, and StyleBench-S, a large-scale synthetic supervision set derived from human psychometric recognition curves. By fine-tuning semantic encoders on StyleBench-S, the authors develop a model that aligns similarity orderings with human perception, demonstrating superior robustness and correlation with human judgment across various artistic styles.
Dataset
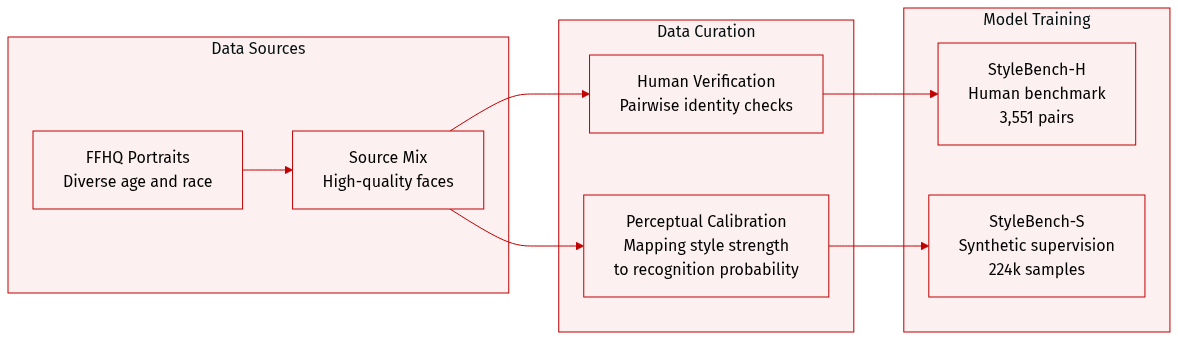
The authors introduce StyleBench, a dataset framework designed to align algorithmic identity metrics with human perception through two specialized subsets:
-
StyleBench-H (Human Perception Benchmark):
- Composition and Source: A rigorous benchmark consisting of 3,551 valid datapoints. The authors sampled high-quality source portraits from FFHQ, filtering for diverse racial and age attributes while removing images with large head rotations or multiple people.
- Processing and Annotation: For each source identity, the authors generated stylized counterparts using three different methods across 10 artistic styles and seven discrete strength levels. Human annotators performed a pairwise verification task to determine if the source and stylized images depicted the same person.
- Filtering Rules: To ensure data quality, the authors discarded responses based on latency (too fast or exceeding 100 seconds) and inconsistency (failed repeated questions). The final set was balanced to include only true-positive and true-negative pairs.
- Evaluation Splits: The authors created Cross-Style and Cross-Method splits to test robustness under stricter distribution shifts, using unseen identities, styles, and stylization methods like MTG and Flux.2.
-
StyleBench-S (Large-Scale Synthetic Supervision Set):
- Composition and Size: A massive synthetic dataset containing approximately 224,000 stylized samples derived from 4,073 unique identities. Each identity is associated with 55 stylized images.
- Calibration Strategy: To ensure the synthetic data reflects human judgment, the authors first conducted a calibration study using a Two-Alternative Forced-Choice (2AFC) protocol. This allowed them to derive psychometric recognition curves that map stylization strength to the probability of human recognition.
- Selection Logic: The authors used these curves to select perceptual positives. They only included image pairs where the estimated human recognition probability remained high (above a 90% threshold). To maintain strict identity consistency, they prioritized samples from the highest and second-highest recognition levels for each method-style combination.
- Usage: The authors use StyleBench-S as a large-scale supervision set to train a style-robust identity encoder, providing scalable training signals that are calibrated to human perceptual thresholds.
Method
The authors leverage a multi-stage pipeline to develop a stylization-agnostic identity recognition model, beginning with a controllable stylization framework and culminating in a perception-calibrated identity encoder. The overall process is structured around three primary components: a stylization pipeline, a training dataset, and a model architecture designed for robust identity embedding.
The stylization pipeline enables the generation of portraits with controlled deviations from the source identity. The authors employ three state-of-the-art diffusion-based and flow-based methods—IP-Adapter, InstantID, and InfiniteYou—each supporting explicit control over stylization strength. For IP-Adapter, identity information is injected via cross-attention mechanisms, with stylization strength modulated by the scale of attention layers and text conditioning, parameterized as sip∈[0,1]. InstantID combines ControlNet with an IP-Adapter-like attention injection, where stylization strength is governed by the ControlNet strength and style conditioning, denoted as sid∈[0,1]. InfiniteYou, a flow-matching approach, uses a style-strength parameter sinf∈[0,1]. All methods normalize their strength parameters such that s=0 yields minimal stylization and s=1 represents maximum stylization. For dataset construction, these parameters are discretized into seven levels. However, due to differing mechanisms, the same normalized value does not guarantee perceptual equivalence across methods. Example outputs at varying strengths are shown in Figure 2.
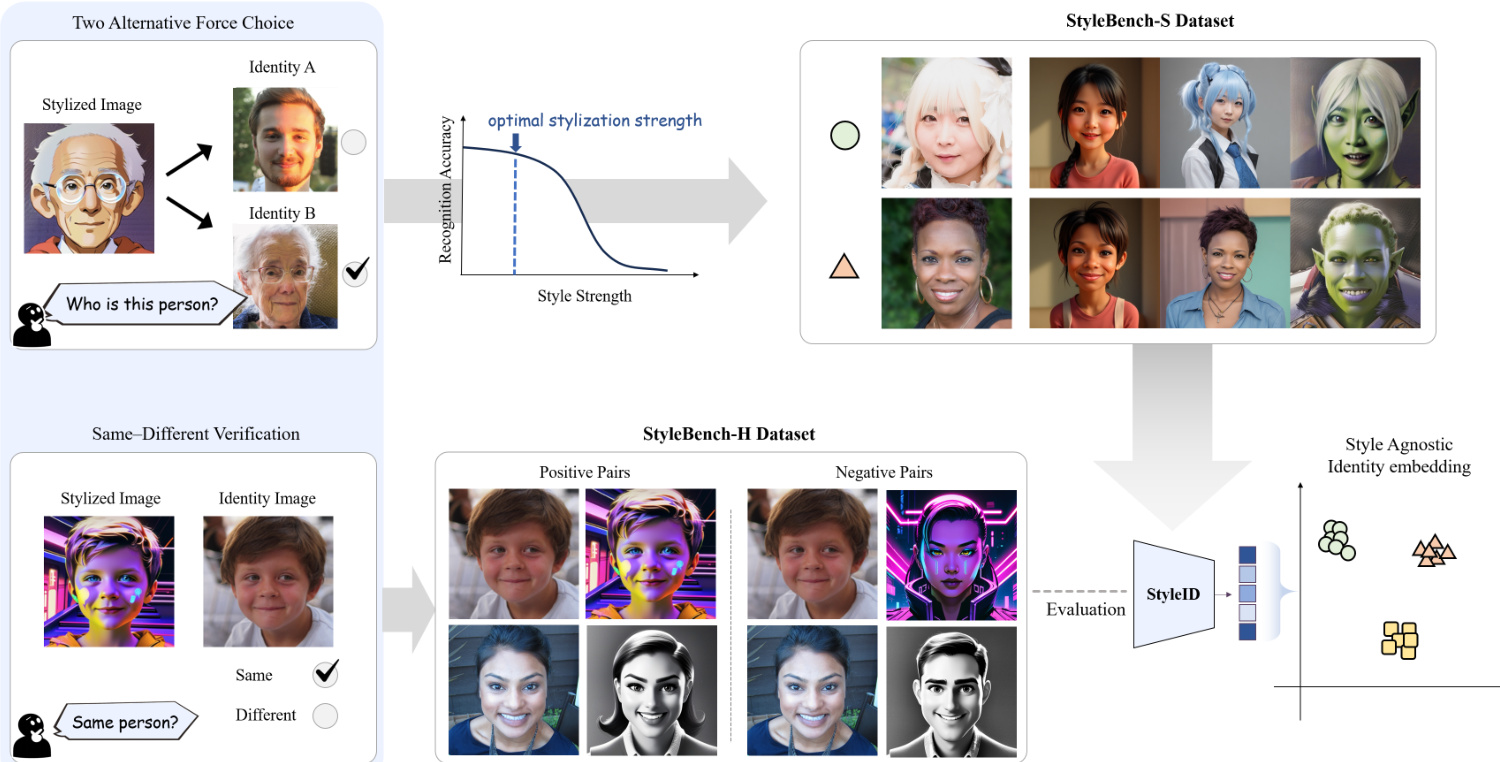
The framework diagram illustrates the core components of the system, including the stylization process and the evaluation of recognition accuracy as a function of style strength. As shown in the figure below, recognition accuracy peaks at an optimal stylization strength and degrades as stylization increases, highlighting the need for a model that remains robust across varying levels of artistic transformation.
The authors introduce StyleID, a stylization-agnostic identity encoder, built upon CLIP, a large-scale text-image semantic encoder known for its robustness to appearance and texture variations. To adapt CLIP to stylized identity recognition while preserving its pretrained representations, the image encoder is frozen, and LoRA adapters are injected into attention and linear layers to learn a lightweight, style-robust identity representation. This adaptation prevents overfitting and catastrophic drift from CLIP’s pretrained manifold. On top of the resulting embedding, an angular margin function similar to ArcFace is applied to enforce discriminative angular margins between identities, ensuring consistent separation even under significant stylistic shifts.
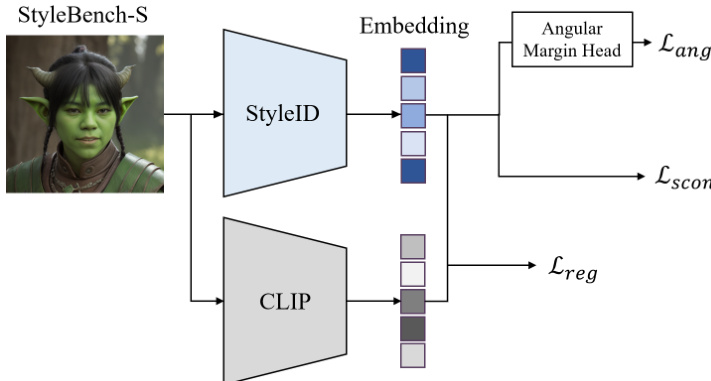
The training objective for StyleID combines three terms: an angular identity loss, a supervised contrastive loss, and an embedding regularization loss. The angular identity loss uses the ArcFace formulation. For a sample i with embedding zi, after ℓ2-normalization to z^i, the cosine logit for class c is cosθi,c=z^i⊤w^c, where w^c are normalized class weights. With additive angular margin m and scale α, the ArcFace loss for sample i is computed as:
ℓiang=−logexp(α⋅cos(θi,yi+m))+∑c=yiexp(α⋅cosθi,c)exp(α⋅cos(θi,yi+m)),and the batch loss is Lang=B1∑i=1Bℓiang.
In addition, a supervised contrastive loss is employed to enhance instance-level separation between identities. For each anchor i, positives are defined as samples in the minibatch sharing the same identity, P(i)={p∈{1,…,B}∖{i}∣yp=yi}. Using temperature τ, the loss for anchor i is:
ℓiscon=−∣P(i)∣1p∈P(i)∑log∑a∈{1,…,B}∖{i}exp(z^i⊤z^a/τ)exp(z^i⊤z^p/τ),with the batch loss Lscon=B1∑i=1Bℓiscon.
Finally, to stabilize training and prevent overfitting, an embedding regularization term constrains the adapted representation to remain close to the original frozen CLIP embedding:
Lreg=B1i=1∑Bz^i−z^i(0)22,where z^i(0) is the embedding from the frozen CLIP encoder. The total training loss is:
L=Lang+λsconLscon+λregLreg,with balancing weights λscon and λreg.
Experiment
The researchers evaluated StyleID against various identity-focused and semantic representation models using human-annotated benchmarks and artist-drawn sketch datasets to assess identity preservation under significant stylization. Experiments across verification, retrieval, and pose robustness tasks demonstrate that StyleID consistently outperforms baselines by maintaining high discriminability and human-aligned identity cues despite extreme appearance shifts. Furthermore, integrating StyleID into generative frameworks improves the quality of stylized outputs by better disentangling identity from artistic texture and color.
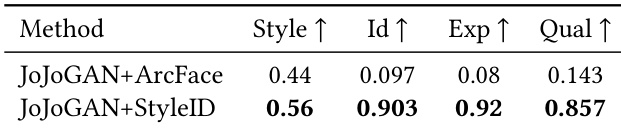
The authors compare the performance of JoJoGAN with ArcFace and StyleID as identity constraints in stylization. Results show that StyleID significantly outperforms ArcFace across all metrics, achieving higher scores in style, identity, expression, and quality. This indicates that StyleID provides a more effective identity representation for stylization, enabling better disentanglement of identity from appearance attributes and producing visually superior outputs. StyleID outperforms ArcFace in all evaluation metrics for stylization fidelity and quality. StyleID enables better disentanglement of identity from appearance, resulting in more coherent and artifact-free stylized outputs. The improvement with StyleID is consistent across both automated and human evaluations, indicating stronger alignment with perceptual identity preservation.
The authors compare StyleID against several baseline methods on identity verification tasks, using multiple datasets and metrics. Results show that StyleID outperforms all baselines across nearly all evaluation metrics, demonstrating superior performance in maintaining identity consistency under stylization. The model achieves the highest true positive rate, verification accuracy, and area under the ROC curve, indicating robustness and strong separability of identity embeddings even under significant appearance changes. StyleID achieves the highest performance across all evaluation metrics, including true positive rate, verification accuracy, and AUROC, outperforming all baseline methods. Semantic encoders like CLIP and SigLIP2 show weak agreement with human identity judgments, while identity-focused models like ArcFace and AdaFace perform better but still fall short under stylization. StyleID consistently outperforms baselines on both StyleBench-H and SKSF-A, demonstrating robustness under diverse and challenging stylization conditions.
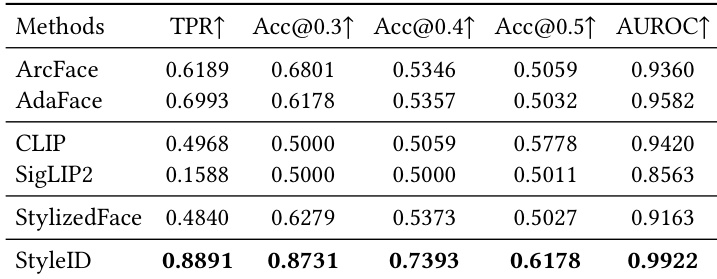
The authors compare StyleID against several baseline methods on two datasets, demonstrating that StyleID achieves superior performance in identity verification tasks under stylization. The results show that StyleID outperforms identity-focused models and semantic encoders across multiple metrics, particularly in challenging cross-style and cross-method scenarios. StyleID also maintains strong performance under extreme artistic transformations and exhibits robustness to pose variations, while its lightweight variants remain competitive even with reduced computational cost. StyleID consistently outperforms all baselines in identity verification across both datasets and evaluation splits. StyleID achieves the highest verification accuracy and AUROC values, especially in challenging cross-style and cross-method scenarios. Lightweight variants of StyleID maintain strong performance despite reduced computational cost, outperforming conventional face recognition models.
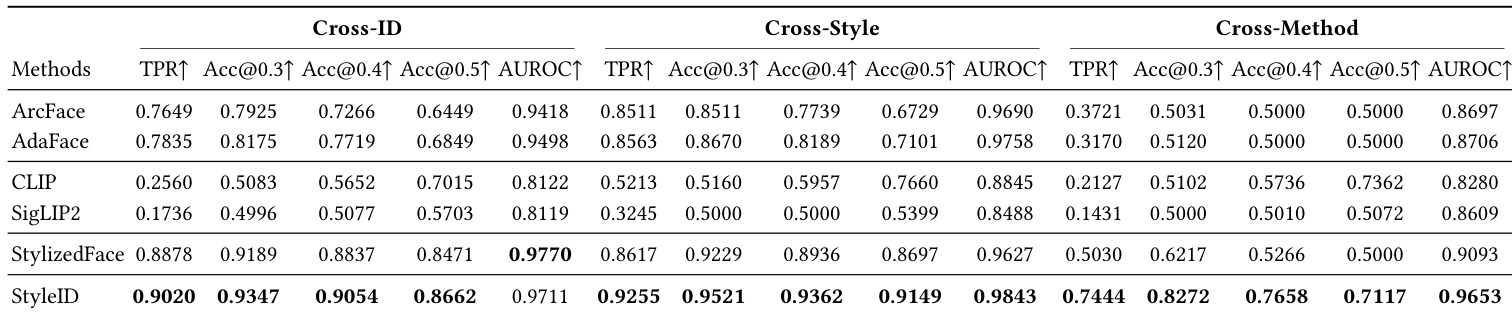
The authors compare StyleID with baseline methods on two datasets, StyleBench-H and SKSF-A, using verification metrics such as true positive rate, accuracy, and AUROC. Results show that StyleID consistently outperforms other methods across both datasets, achieving the highest values in all reported metrics. The performance gap is particularly notable in cross-style and cross-method scenarios, where StyleID maintains robust identity verification under significant stylization changes. StyleID achieves the highest performance across all metrics on both StyleBench-H and SKSF-A, outperforming all baseline methods. The improvement is most pronounced in challenging cross-style and cross-method settings, indicating robustness under significant stylization. StyleID demonstrates superior verification performance, with the highest true positive rate and AUROC values, suggesting strong separability of same-identity and different-identity pairs.
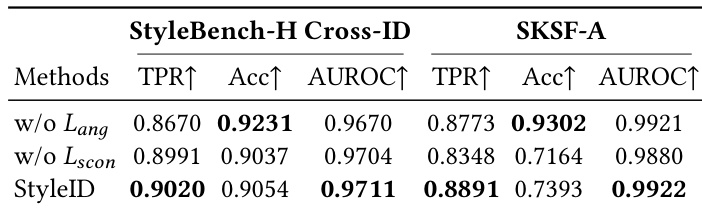
The authors compare StyleID against a baseline method on two datasets, StyleBench-H and SKSF-A, using verification metrics including true positive rate, accuracy, and AUROC. StyleID consistently outperforms the baseline across all metrics on both datasets, demonstrating superior identity preservation under stylization. The results indicate that StyleID maintains high performance even under challenging conditions, while the baseline shows significant degradation. StyleID outperforms the baseline across all metrics on both StyleBench-H and SKSF-A. StyleID achieves higher true positive rates, accuracy, and AUROC values compared to the baseline. The baseline shows significant performance degradation under stylization, while StyleID maintains robust verification performance.
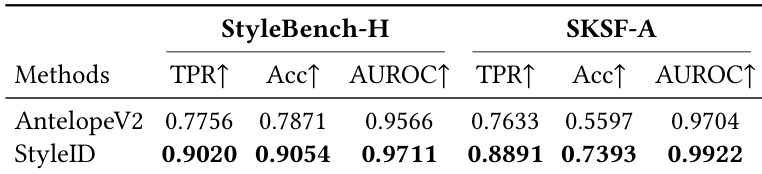
The authors evaluate StyleID against various identity constraints and baseline models, including ArcFace, CLIP, and SigLIP2, through stylization fidelity tests and identity verification tasks across multiple datasets. The results demonstrate that StyleID provides superior identity representation by effectively disentangling identity from appearance attributes, leading to more coherent and artifact-free stylized outputs. Even under extreme artistic transformations and challenging cross-style scenarios, StyleID maintains robust identity consistency and outperforms both semantic encoders and traditional identity-focused models.