Command Palette
Search for a command to run...
DiffNR: تحسين التمثيل العصبي المعزز بالانتشار لإعادة البناء المقطعي ثلاثي الأبعاد من زوايا نادرة
DiffNR: تحسين التمثيل العصبي المعزز بالانتشار لإعادة البناء المقطعي ثلاثي الأبعاد من زوايا نادرة
Shiyan Su Ruyi Zha Danli Shi Hongdong Li Xuelian Cheng
الملخص
تُعد التمثيلات العصبية (Neural representations - NRs)، مثل الحقول العصبية (neural fields) وGaussians ثلاثية الأبعاد (3D Gaussians)، وسيلة فعالة لنمذجة البيانات الحجمية في التصوير المقطعي المحوسب (CT)، إلا أنها تعاني من ظهور عيوب تصويرية (artifacts) حادة في حالات التصوير من زوايا محدودة (sparse-view settings). ولمعالجة هذه المشكلة، نقترح DiffNR، وهو إطار عمل مبتكر يعمل على تعزيز تحسين التمثيلات العصبية (NR optimization) باستخدام مسبقات الانتشار (diffusion priors).يعتمد هذا الإطار في جوهره على SliceFixer، وهو نموذج انتشار أحادي الخطوة (single-step diffusion model) صُمم لتصحيح العيوب التصويرية في المقاطع المتضررة. وقد قمنا بدمج طبقات تكييف (conditioning layers) متخصصة في الشبكة، كما طورنا استراتيجيات مخصصة لتنظيم البيانات (data curation strategies) لدعم عملية الضبط الدقيق (finetuning) للنموذج. وأثناء عملية إعادة البناء (reconstruction)، يقوم SliceFixer بإنشاء أحجام مرجعية زائفة (pseudo-reference volumes) بشكل دوري، مما يوفر إشرافًا إدراكيًا ثلاثي الأبعاد (3D perceptual supervision) مساعدًا لإصلاح المناطق التي تفتقر إلى القيود الكافية (underconstrained regions).وبالمقارنة مع الطرق السابقة التي تدمج أدوات حل التصوير المقطعي (CT solvers) ضمن عمليات إزالة ضجيج تكرارية تستهلك وقتًا طويلاً، تتجنب استراتيجيتنا القائمة على "الإصلاح والتعزيز" (repair-and-augment) الاستعلامات المتكررة من نموذج الانتشار، مما يؤدي إلى أداء أفضل من حيث وقت التشغيل (runtime performance). وقد أظهرت التجارب المكثفة أن DiffNR يحسن نسبة ذروة نسبة الإشارة إلى الضجيج (PSNR) بمتوسط قدره 3.99 ديسيبل (dB)، ويتمتع بقدرة عالية على التعميم عبر نطاقات مختلفة، مع الحفاظ على كفاءة عملية التحسين.
One-sentence Summary
To address artifact issues in sparse-view 3D tomographic reconstruction, the proposed DiffNR framework enhances neural representation optimization by integrating SliceFixer, a single-step diffusion model that periodically generates pseudo-reference volumes for 3D perceptual supervision through an efficient repair-and-augment strategy that improves average PSNR by 3.99 dB.
Key Contributions
- The paper introduces DiffNR, a novel optimization framework for sparse-view 3D tomographic reconstruction that enhances neural representations using conditional diffusion priors.
- This work presents SliceFixer, a single-step diffusion model specifically designed to correct artifacts in reconstructed CT slices through specialized conditioning layers and tailored data curation strategies.
- The proposed repair-and-augment strategy utilizes SliceFixer to periodically generate pseudo-reference volumes for 3D perceptual supervision, achieving an average PSNR improvement of 3.99 dB while maintaining high optimization efficiency.
Introduction
Sparse-view CT reconstruction is critical for reducing radiation exposure during medical imaging and security screening. While neural representation (NR) methods like neural fields and 3D Gaussians provide high-quality volumetric modeling, they often produce severe artifacts in underconstrained regions when projection data is limited. Existing neural prior approaches that use diffusion models to address this often suffer from slow processing times, inter-slice jitters, and hallucinations. The authors leverage a repair-and-augment strategy through a novel framework called DiffNR. They introduce SliceFixer, a single-step diffusion model finetuned to correct artifacts in reconstructed slices, which periodically generates pseudo-reference volumes to provide 3D perceptual supervision. This approach avoids the computational burden of frequent diffusion queries while significantly improving reconstruction accuracy and volumetric consistency.
Dataset
The authors developed a specialized dataset for training SliceFixer by synthesizing paired slices consisting of artifact-heavy reconstructions and clean ground truth volumes. The dataset composition and processing involve the following:
- Data Sources and Synthesis: The authors utilize public 3D CT volumes as the foundation. Using the tomography toolbox, they synthesize K dense projections over a full 360∘ angular range to create high-quality ground truth data.
- Artifact Simulation: To create the paired artifact samples, the authors simulate sparse-view scenarios by randomly sampling subsets of the dense projections. They employ both uniform and non-uniform view distributions to introduce a variety of artifact patterns, which improves model robustness.
- Underfitting Strategy: To increase the difficulty and diversity of the training examples, the authors intentionally underfit the neural reconstruction models. By limiting the optimization to only 25% to 50% of the standard training iterations, they produce reconstructions with pronounced artifacts caused by incomplete convergence.
- Dataset Mixture: The final training set uses a mixed neural representation approach. The authors combine reconstruction results from neural fields and 3D Gaussians in a 1:1 ratio to prevent the diffusion model from overfitting to a single reconstruction pattern and to encourage the learning of generalized priors.
Method
The authors propose SliceFixer, a diffusion-based model designed to refine corrupted CT slices produced by neural representations (NRs), and integrate it into a broader optimization framework for enhanced volumetric reconstruction. The overall approach leverages the strengths of diffusion models for high-fidelity image generation while addressing the limitations of standalone post-processing in maintaining volumetric consistency.
SliceFixer is built upon SD-Turbo, a single-step diffusion model, to enable efficient inference. The architecture, as shown in the framework diagram, consists of a Variational Autoencoder (VAE) and a U-Net. The VAE encodes a corrupted slice from an NR into a latent representation. This latent representation, along with conditioning information and a denoising timestep, is fed into the U-Net, which predicts the target latent features. The refined slice is then reconstructed by decoding this predicted latent representation using the VAE decoder.
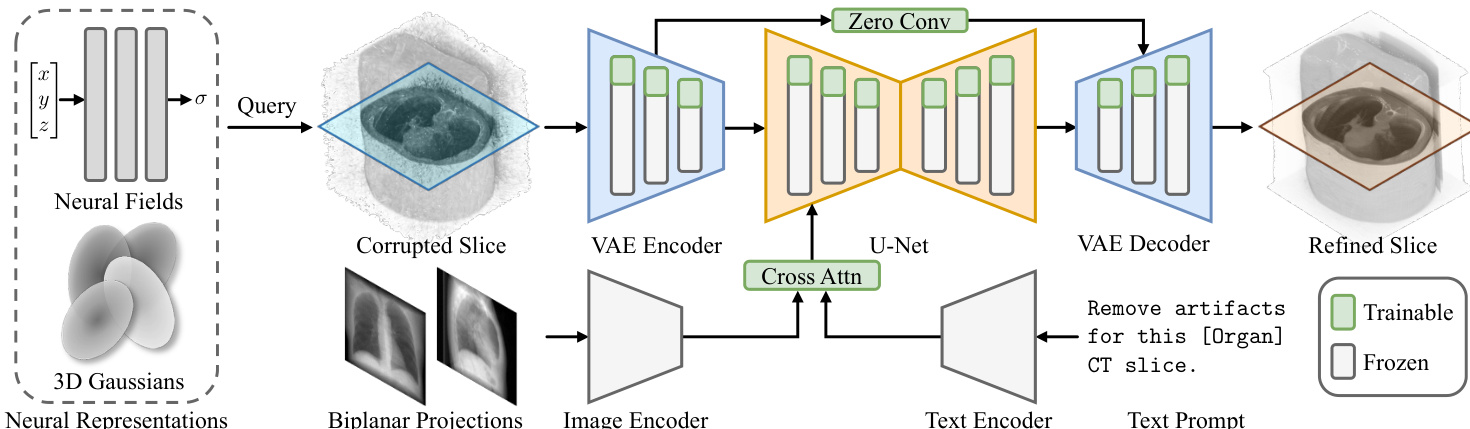
The model is conditioned on both biplanar X-ray projections and a text prompt to guide the refinement process. The biplanar projections provide global structural cues, while the text prompt offers high-level semantic guidance. The image features from the projections are extracted using a pretrained RAD-DINO encoder, and these are aggregated with the text embedding via a cross-attention mechanism to form the final conditioning input for the diffusion model.
To adapt the pretrained SD-Turbo model, the authors employ a finetuning strategy that injects trainable LoRA adapters into the VAE and U-Net modules and incorporates zero-convolution layers for skip connections. This allows the model to learn the specific task of CT slice repair while preserving the rich visual priors of the base model. The training objective integrates multiple loss functions: L2 loss, LPIPS loss, CLIP alignment loss, a GAN-based adversarial loss, and a structural similarity (SSIM) loss to ensure perceptual quality and anatomical fidelity.
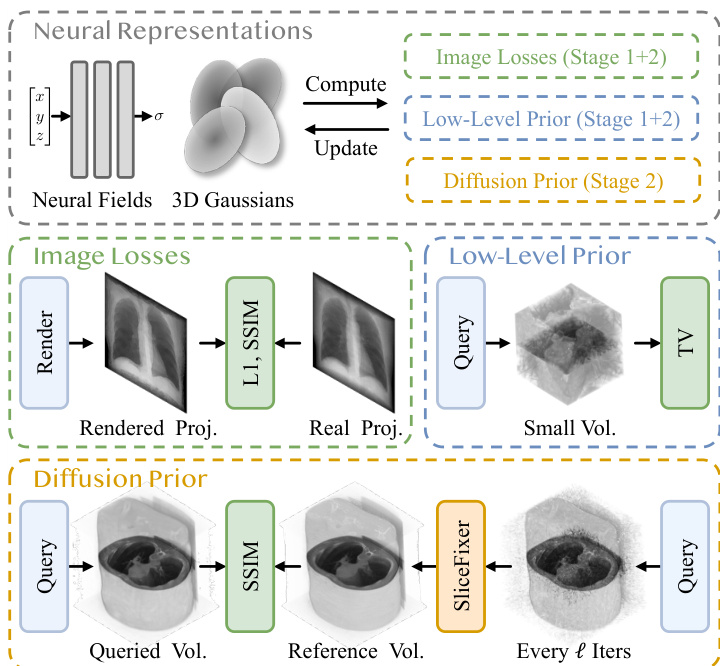
The authors further extend this framework into a diffusion-enhanced NR optimization pipeline called DiffNR. This approach integrates SliceFixer not as a post-processing step but as an active component within the NR training loop. As illustrated in the pipeline diagram, the neural representation is first optimized using standard image losses and low-level regularization. Periodically, a volume is queried from the current model, and its slices are processed through SliceFixer to generate a pseudo-reference volume. This reference volume is then used to provide additional 3D supervision in the form of a 3D SSIM loss, which helps maintain volumetric consistency and reduces interslice jitters. This repair-and-augment strategy allows the model to leverage the high-quality, artifact-free slices generated by SliceFixer as a powerful form of augmented supervision, improving the overall reconstruction quality while maintaining training efficiency.
Experiment
The experiments evaluate the proposed DiffNR method using the ToothFairy and LUNA16 datasets, alongside out-of-distribution testing and downstream lung segmentation tasks to validate reconstruction quality and generalization. Results demonstrate that DiffNR effectively suppresses artifacts and hallucinations common in traditional and diffusion-based methods while recovering finer structural details. Furthermore, the method shows strong practical utility by producing reconstructed volumes that yield more accurate results in medical segmentation tasks.
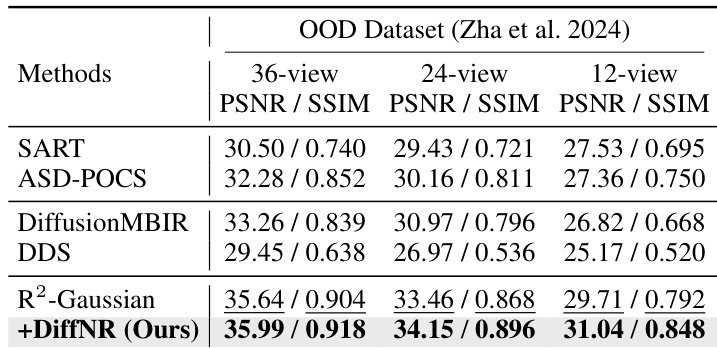
The authors evaluate their method, DiffNR, on an out-of-distribution dataset and compare it against several state-of-the-art reconstruction methods. Results show that DiffNR achieves the highest performance across all view settings, significantly improving upon the baseline R2-Gaussian method and outperforming other diffusion-based and iterative approaches. The method effectively suppresses artifacts and hallucinations, demonstrating strong generalization and reconstruction quality. DiffNR achieves the best performance on the out-of-distribution dataset across all view settings. DiffNR significantly improves upon the R2-Gaussian baseline, showing strong generalization and artifact suppression. DiffNR outperforms other diffusion-based and iterative methods, indicating superior reconstruction quality and robustness.
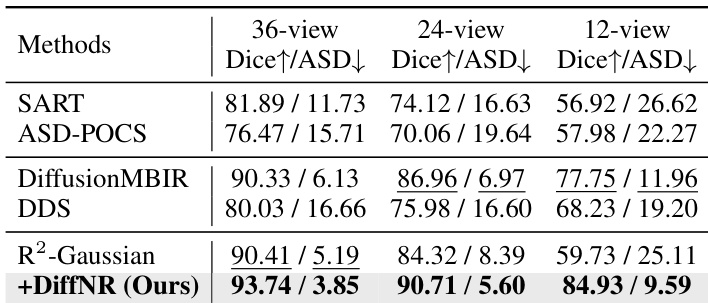
The authors compare their method, DiffNR, against several existing reconstruction approaches on multiple datasets and view settings. Results show that DiffNR achieves superior performance in terms of reconstruction quality and artifact suppression, particularly in both in-distribution and out-of-distribution scenarios, with improvements over baseline methods in key metrics. The method demonstrates strong generalization and effectiveness in downstream applications like segmentation, outperforming other approaches in consistency with ground truth. DiffNR outperforms existing methods across different view settings and datasets, achieving higher scores in both Dice and ASD metrics. DiffNR demonstrates strong generalization, improving results on out-of-distribution data where other methods struggle with artifacts and hallucinations. The method maintains high consistency with ground truth volumes, leading to more accurate downstream segmentation results compared to baselines.
The authors conduct an ablation study to evaluate the impact of different components in their proposed method, DiffNR, on reconstruction quality. The results show that integrating SliceFixer with SSIM loss and using it as part of the optimization pipeline leads to the best performance, significantly improving both PSNR and SSIM metrics compared to baseline approaches. Integrating SliceFixer with SSIM loss improves reconstruction quality over using it alone. Using SliceFixer as a standalone post-processing step leads to slice jitter and hallucinations. Combining SliceFixer with SSIM loss within the optimization pipeline achieves the highest performance in both PSNR and SSIM.

The authors conduct an ablation study to evaluate the impact of different design choices in SliceFixer and DiffNR on reconstruction quality. The results show that using higher resolution during finetuning and incorporating SSIM loss improves performance, while adding biplanar projections further enhances reconstruction. Integrating SliceFixer into the optimization pipeline is essential, and voxel-wise L1 loss leads to degradation compared to a 3D perceptual loss. Finetuning SliceFixer at higher resolution and with SSIM loss improves reconstruction quality. Adding biplanar projections as conditioning inputs boosts performance by providing richer structural cues. Integrating SliceFixer into the optimization pipeline prevents slice jitter and hallucinations observed with standalone post-processing.

The authors evaluate their method, DiffNR, against various baseline approaches on two datasets under different view conditions. Results show that DiffNR outperforms other methods in reconstruction quality, particularly in terms of PSNR and SSIM, while maintaining reasonable computational efficiency compared to previous diffusion-based methods. The method demonstrates consistent improvements over baseline neural representation approaches and achieves competitive performance with significantly reduced processing time. DiffNR achieves higher reconstruction quality than traditional and diffusion-based methods, particularly in PSNR and SSIM metrics. DiffNR is substantially faster than prior diffusion-based methods, reducing processing time from hours to minutes. DiffNR consistently improves upon baseline neural representation methods, showing robust performance across different datasets and view conditions.
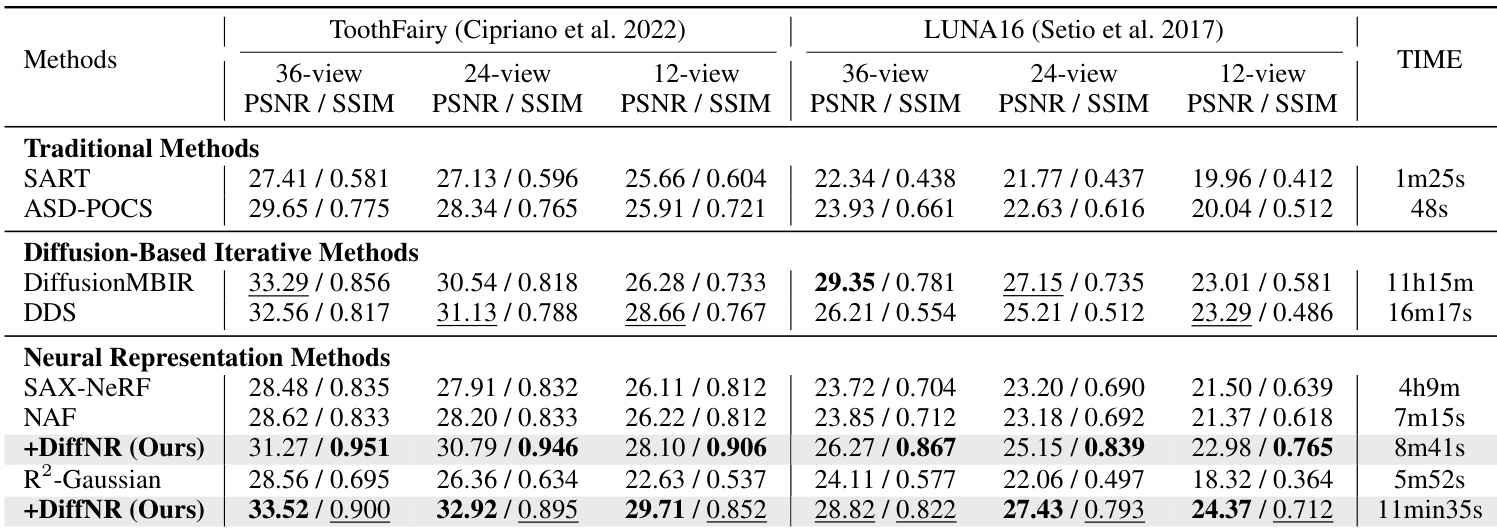
The authors evaluate DiffNR against various state-of-the-art reconstruction methods across multiple datasets and view settings to test generalization and downstream segmentation accuracy. Ablation studies further validate the importance of integrating SliceFixer into the optimization pipeline with SSIM loss and biplanar projections to prevent artifacts and hallucinations. Overall, DiffNR demonstrates superior reconstruction quality, robust generalization to out-of-distribution data, and significantly improved computational efficiency compared to existing diffusion-based approaches.