Command Palette
Search for a command to run...
UniT: نحو لغة فيزيائية موحدة لتعلم السياسات من البشر إلى الروبوتات الشبيهة بالبشر ونمذجة العالم
UniT: نحو لغة فيزيائية موحدة لتعلم السياسات من البشر إلى الروبوتات الشبيهة بالبشر ونمذجة العالم
Boyu Chen Yi Chen Lu Qiu Jerry Bai Yuying Ge Yixiao Ge
الملخص
تتمثل العقبة الرئيسية في توسيع نطاق النماذج الأساسية للروبوتات البشرية (humanoid foundation models) في ندرة البيانات الروبوتية. وبينما توفر البيانات البشرية الضخمة المأخوذة من منظور الشخص الأول (egocentric human data) بديلاً قابلاً للتوسع، إلا أن سد الفجوة بين مختلف التجسيدات (cross-embodiment) لا يزال يمثل تحدياً جوهرياً بسبب عدم التطابق الحركي (kinematic mismatches).نقدم في هذا البحث UniT (Unified Latent Action Tokenizer via Visual Anchoring)، وهو إطار عمل يضع لغة فيزيائية موحدة لنقل المعرفة من البشر إلى الروبوتات البشرية. وانطلاقاً من فلسفة مفادها أن الحركات الميكانيكية غير المتجانسة تشترك في نتائج بصرية عالمية، يستخدم UniT آلية إعادة بناء مشتركة ثلاثية الفروع (tri-branch cross-reconstruction mechanism): حيث تقوم الأفعال (actions) بالتنبؤ بالرؤية لربط الخصائص الحركية بالنتائج الفيزيائية، بينما تقوم الرؤية بإعادة بناء الأفعال لتصفية المتغيرات البصرية غير ذات الصلة. وبالتزامن مع ذلك، يعمل فرع الدمج (fusion branch) على دمج هذه الأنماط المنقاة في فضاء كامن منفصل (shared discrete latent space) يعبر عن مقاصد فيزيائية مجردة من خصائص التجسيد (embodiment-agnostic physical intents).لقد قمنا بالتحقق من كفاءة UniT عبر نموذجين:1) تعلم السياسات (VLA-UniT): من خلال التنبؤ بهذه الـ tokens الموحدة، نجح النموذج في الاستفادة بفعالية من البيانات البشرية المتنوعة لتحقيق كفاءة بيانات رائدة (state-of-the-art data efficiency) وقدرة قوية على التعميم خارج نطاق التوزيع (out-of-distribution (OOD) generalization)، سواء في اختبارات محاكاة الروبوتات البشرية أو في عمليات النشر في العالم الحقيقي، حيث أظهر بشكل ملحوظ القدرة على نقل المهام بنمط "التعلم الصفري" (zero-shot task transfer).2) نمذجة العالم (WM-UniT): من خلال محاذاة الديناميكيات عبر مختلف التجسيدات باستخدام الـ tokens الموحدة كشروط (conditions)، حقق النموذج نقلاً مباشراً للأفعال من البشر إلى الروبوتات البشرية. تضمن هذه المحاذاة ترجمة البيانات البشرية بسلاسة إلى تحكم معزز في الأفعال لتوليد فيديوهات للروبوتات البشرية.في الختام، ومن خلال استنباط تمثيل عابر للتجسيدات عالي المحاذاة (تم التحقق منه تجريبياً عبر تصورات t-SNE التي كشفت عن تقارب السمات البشرية وسمات الروبوتات البشرية في فضاء مشترك/manifold)، يوفر UniT مساراً قابلاً للتوسع لاستخلاص المعرفة البشرية الهائلة وتحويلها إلى قدرات عامة للروبوتات البشرية.
One-sentence Summary
UniT establishes a unified physical language for human-to-humanoid transfer through a tri-branch cross-reconstruction mechanism that anchors heterogeneous kinematics to shared visual consequences in a discrete latent space, enabling efficient policy learning via VLA-UniT and direct world modeling via WM-UniT to achieve robust zero-shot task transfer.
Key Contributions
- The paper introduces UniT, a framework that establishes a unified physical language for human-to-humanoid transfer through a shared discrete latent space of embodiment-agnostic physical intents.
- The method utilizes a tri-branch cross-reconstruction mechanism where actions predict vision to anchor kinematics to physical outcomes and vision reconstructs actions to filter out irrelevant visual confounders.
- Experiments demonstrate that the framework achieves state-of-the-art data efficiency and robust out-of-distribution generalization in policy learning, while also enabling direct human-to-humanoid action transfer in world modeling paradigms.
Introduction
Scaling humanoid foundation models is currently limited by the scarcity of high-quality robotic data. While massive datasets of human motion offer a scalable alternative, bridging the gap between human and humanoid embodiments is difficult due to mismatched kinematics and varying degrees of freedom. Existing approaches often rely on labor-intensive motion retargeting or suffer from distribution shifts and visual confounders like lighting and texture. The authors leverage a framework called UniT (Unified Latent Action Tokenizer via Visual Anchoring) to establish a shared physical language. By employing a tri-branch cross-reconstruction mechanism, UniT anchors heterogeneous kinematics to universal visual consequences, effectively distilling embodiment-agnostic physical intent into a unified latent space.
Dataset
The authors utilize several datasets to train and evaluate their models across simulation and real-world environments:
-
Dataset Composition and Sources
- RoboCasa GR1 Tabletop Simulation: A benchmark consisting of 24 tabletop tasks, including 18 pick-and-place rearrangement tasks and 6 articulated tasks such as opening cabinets or microwaves.
- EgoDex Dataset: A collection of human demonstrations used to study human-to-humanoid transfer. This includes the basic_pick_place subset (27,419 trajectories) and a pouring subset (3,205 trajectories).
- DROID Dataset: A large-scale dataset containing 95,599 diverse trajectories from 564 scenes, consisting of approximately 76,000 successful and 19,000 failed trajectories.
- Proprietary Robot Data: A collection of 32,000 robot trajectories used for pre-training.
-
Training and Evaluation Regimes
- Pre-training: Models are pre-trained on a mixture of 32,000 proprietary robot trajectories and 30,000 EgoDex trajectories.
- Co-training and Fine-tuning: For human-to-humanoid transfer, the authors combine the EgoDex basic_pick_place subset with a few-shot robot subset (2,400 trajectories) for co-training, followed by fine-tuning exclusively on robot data.
- RoboCasa Evaluation Splits: The authors test under two regimes: Full Data (24,000 trajectories) and Few-Shot (2,400 trajectories).
- Real-World Validation: The authors collect 120 robot trajectories per task for two specific tasks: Pick and Place and Pouring.
-
Generalization and Testing Scenarios
- RoboCasa Generalization: Testing is performed across three axes: Unseen Appearance (novel textures), Unseen Combinations (novel object and container pairings), and Unseen Object Types (novel object categories).
- Real-World Out-of-Distribution (OOD) Testing: The authors evaluate five axes of generalization: Geometry (new 3D shapes), Distractor (scenes with additional objects), Target (alternative placement destinations), Background (varying table textures), and Combinational (instruction following among multiple known objects).
Method
The authors propose UniT, a unified physical language framework designed to bridge the gap between human and humanoid action spaces through a shared discrete latent representation. The core of UniT is a visual-anchored tri-branch tokenizer that maps heterogeneous actions into a unified latent space, enabling cross-embodiment transfer for both policy learning and world modeling. The overall framework operates by first encoding observation transitions, actions, and fused visuo-motor features into a shared discrete latent space using a Residual Quantization VAE (RQ-VAE) with a shared codebook. This process is guided by a cross-reconstruction mechanism that ensures consistency across modalities and embodiments. Refer to the framework diagram 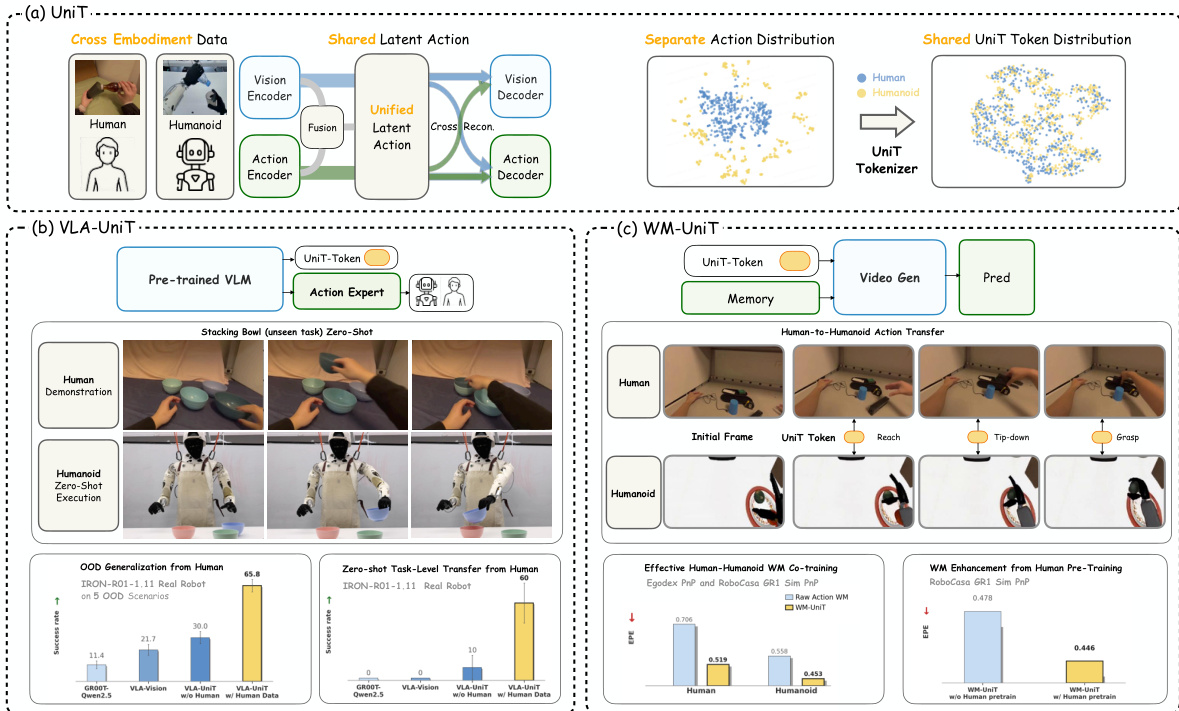 .
.
The UniT tokenizer architecture consists of three parallel branches: a visual branch, an action branch, and a fusion branch. The visual branch, Ev, acts as an inverse dynamics model (IDM) by taking frozen DINOv2 features of a visual observation pair (ot,ot+k) as input, providing a domain-invariant visual anchor across different embodiments. The action branch, Ea, encodes the current state st and action chunk at:t+k. To handle the heterogeneity in action parameterization across human and humanoid embodiments, raw actions are first padded to a unified maximum length and projected through embodiment-specific MLPs before being summarized into a compact latent control representation. The fusion branch, Em, combines the features from the visual and action branches to produce a fused visuo-motor latent representation that captures complementary cross-modal structure, resulting in more compact and robust tokens. As shown in the figure below: 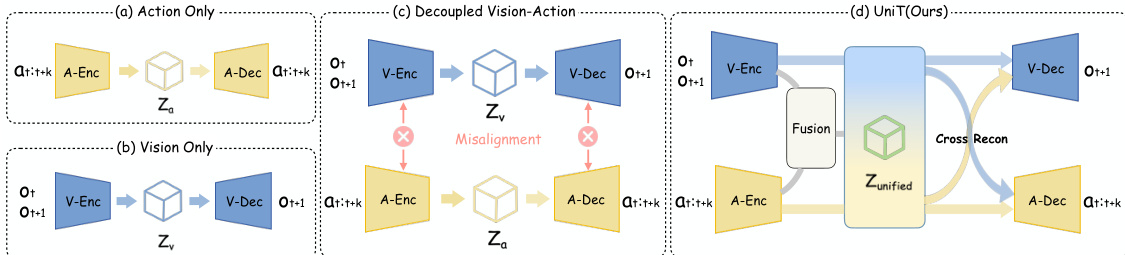 .
.
All three continuous latent representations are quantized into a shared discrete space using a Residual Quantization VAE (RQ-VAE) with a common codebook C, resulting in unified latent action tokens. The core mechanism of UniT is cross-reconstruction, where each quantized token z^i from any branch is decoded by both a shared visual decoder Dv and an embodiment-specific action decoder Dn. The visual decoder reconstructs future visual features f^t+k(i) conditioned on the current observation, supervised by cosine similarity with the ground-truth future feature ft+k. The action decoder reconstructs the action chunk a^t:t+k(i) conditioned on the current state st. This bidirectional constraint enforces that tokens capturing similar physical transitions are mapped to nearby codebook entries, regardless of the embodiment, thereby anchoring heterogeneous motor representations into a unified manifold. The training objective aggregates the cross-reconstruction and quantization losses across all three branches.
Leveraging this shared token representation, UniT is deployed in two complementary paradigms. For policy learning, VLA-UniT integrates UniT into a Vision-Language-Action (VLA) architecture. The model predicts UniT tokens in the shared latent space from a current observation and language instruction, using a pre-trained VLM. A lightweight flow-matching action expert then generates embodiment-specific actions conditioned on the same vision-language context. This decomposition allows the VLM to learn a unified cross-embodiment policy decision process, while the action expert handles the embodiment-specific control generation. For world modeling, WM-UniT uses UniT tokens as a universal conditioning interface. Instead of raw actions, the action-branch features are used as control signals for an action-conditioned video generation model. This enables the world model to leverage human priors for predicting future visual observations, facilitating effective human-to-humanoid action transfer. The use of UniT tokens as a control interface ensures that the world model does not leak future observations at deployment time, as the conditioning is derived solely from the current state and action chunk. 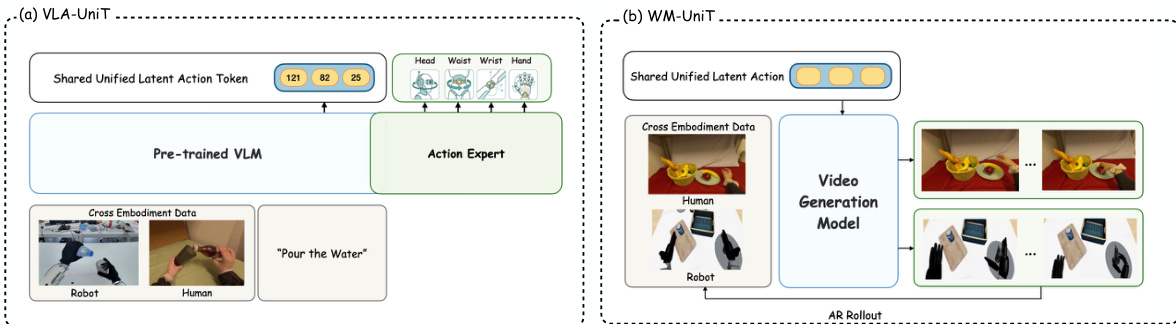
Experiment
The experiments evaluate the UniT tokenizer across policy learning, world modeling, and representational alignment tasks to validate its ability to establish a unified physical language. Results demonstrate that UniT enables superior data efficiency, robust cross-embodiment transfer from human to humanoid demonstrations, and improved zero-shot task generalization. Furthermore, the findings confirm that bidirectional cross-reconstruction and the synergy between vision and action are essential for creating a shared latent space that supports both controllable video generation and embodiment-agnostic downstream representations.
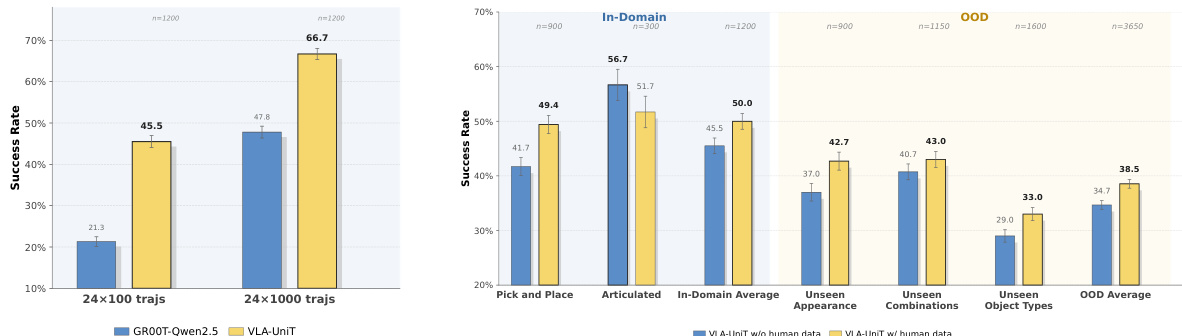
The the the table compares different methods for world modeling across two datasets: a single-embodiment setting using DROID and a human-humanoid co-training setup combining EgoDex and RoboCasa-GR1. For both datasets, the WM-UniT method consistently outperforms baselines in most metrics, particularly in perceptual quality and controllability, indicating that the visual-anchored tokenization improves generation fidelity and cross-embodiment alignment. The results show that WM-UniT achieves higher PSNR and SSIM, lower LPIPS and FVD, and better EPE compared to Raw Action and WM-Action, highlighting the benefits of jointly modeling vision and action with cross-reconstruction. In the co-training scenario, WM-UniT demonstrates strong performance on both human and humanoid data, suggesting effective transfer of dynamics across embodiments. WM-UniT achieves superior performance across multiple metrics in both single-embodiment and human-humanoid co-training settings, indicating improved generation quality and controllability. The visual-anchored tokenization in WM-UniT leads to better perceptual similarity and lower reconstruction error compared to action-only or raw action baselines. WM-UniT enables effective cross-embodiment dynamics transfer, as evidenced by consistent performance improvements on both human and humanoid data in the co-training setup.
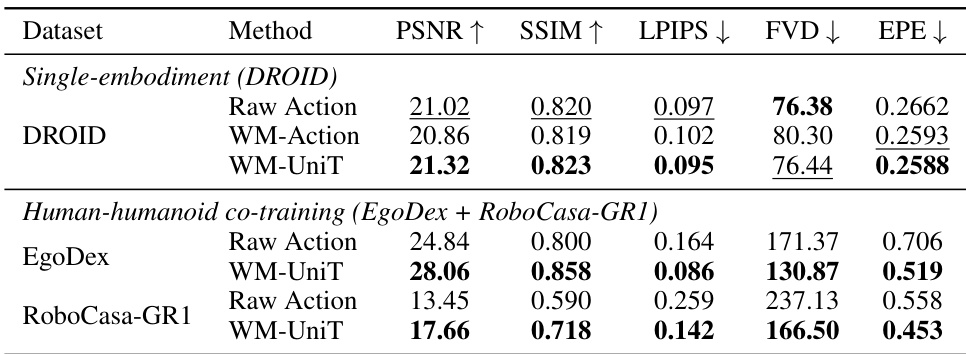
{"summary": "The experiments demonstrate that VLA-UniT achieves superior performance compared to baseline methods across various tasks and settings. Results show that VLA-UniT outperforms other models in both in-domain and out-of-distribution scenarios, with significant improvements in success rates on tasks such as pick-and-place and articulated manipulation. The model also exhibits strong data efficiency and benefits from human demonstrations, leading to enhanced generalization and transfer capabilities.", "highlights": ["VLA-UniT achieves higher success rates than baselines across in-domain and out-of-distribution tasks.", "VLA-UniT shows improved data efficiency, performing well even with limited training data.", "Human demonstrations enhance VLA-UniT's performance, particularly in out-of-distribution and zero-shot generalization scenarios."]
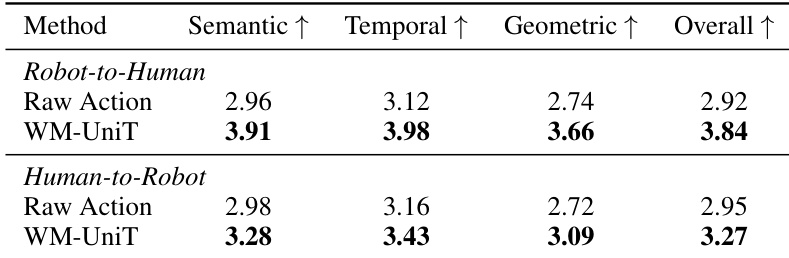
The the the table compares cross-embodiment conditioning performance between Raw Action and WM-UniT in terms of semantic, temporal, and geometric consistency for both robot-to-human and human-to-robot directions. WM-UniT achieves higher scores than Raw Action across all metrics and both transfer directions, indicating more faithful and consistent video generation when conditioning on actions from one embodiment to generate videos for another. The results highlight the effectiveness of UniT in preserving fine-grained action semantics, magnitude sensitivity, and temporal coherence during cross-embodiment transfer. WM-UniT outperforms Raw Action in semantic, temporal, and geometric consistency across both robot-to-human and human-to-robot transfer directions. WM-UniT achieves higher scores in all evaluation dimensions, indicating more faithful cross-embodiment video generation. The improvement of WM-UniT over Raw Action demonstrates the effectiveness of visual-anchored tokenization in preserving action semantics and fine-grained motion details during cross-embodiment transfer.
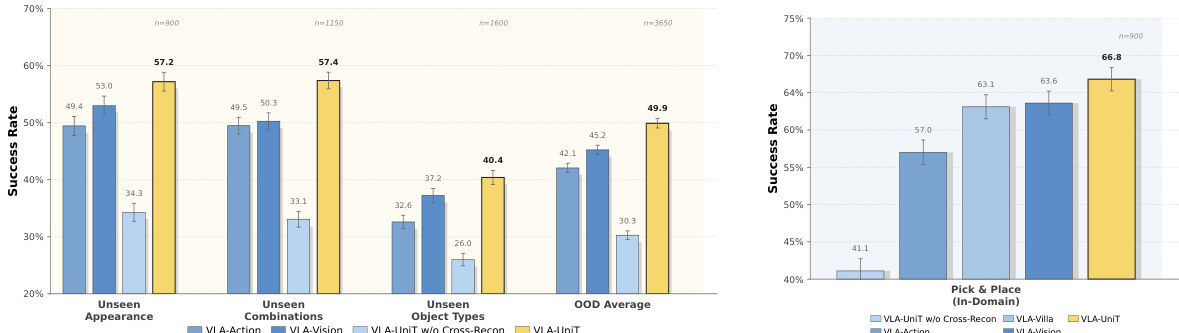
The authors evaluate the effectiveness of UniT in enabling cross-embodiment transfer for policy learning and world modeling, focusing on its ability to create a unified physical language through visual-anchored tokenization. Results show that UniT-based models achieve superior performance in both in-domain and out-of-distribution settings compared to baselines that use single-modality or unidirectional reconstruction. The visual-anchored representation enables effective human-to-humanoid transfer, improving generalization and zero-shot task transfer in real-world deployment. UniT enables effective human-to-humanoid transfer, improving both in-domain and out-of-distribution performance compared to single-modality or unidirectional baselines. The visual-anchored tokenization in UniT provides a shared latent space that enhances cross-embodiment alignment and enables zero-shot task transfer. UniT-based models outperform baselines in both policy learning and world modeling tasks, demonstrating the benefits of bidirectional cross-reconstruction and vision-action synergy.
The the the table compares two configurations of a world modeling system, WM-UniT, with and without human pre-training. Results show that the full configuration, which includes human pre-training, achieves better performance across all metrics, indicating that human data enhances the model's ability to generate high-quality and controllable video sequences. The improvements are consistent across measures of frame fidelity, perceptual similarity, video realism, and controllability. WM-UniT with human pre-training outperforms the version without it across all evaluation metrics. The full configuration achieves higher PSNR and SSIM, indicating better frame fidelity and perceptual similarity. The full configuration shows improved controllability, as evidenced by lower EPE and FVD values.

The experiments evaluate WM-UniT across single-embodiment and human-humanoid co-training settings to validate its effectiveness in world modeling, cross-embodiment transfer, and policy learning. The results demonstrate that visual-anchored tokenization significantly improves perceptual quality, controllability, and the preservation of fine-grained action semantics during cross-embodiment conditioning. Furthermore, incorporating human pre-training enhances video realism and enables effective zero-shot task transfer, establishing a unified physical language between different embodiments.