Command Palette
Search for a command to run...
CoInteract: توليد فيديوهات التفاعل بين الإنسان والأشياء عبر التوليد المشترك ذي البنية المكانية المتوافقة فيزيائياً
CoInteract: توليد فيديوهات التفاعل بين الإنسان والأشياء عبر التوليد المشترك ذي البنية المكانية المتوافقة فيزيائياً
Xiangyang Luo Xiaozhe Xin Tao Feng Xu Guo Meiguang Jin Junfeng Ma
الملخص
تمتلك عملية توليد فيديوهات التفاعل بين الإنسان والأشياء (Human-Object Interaction - HOI) قيمة عملية واسعة النطاق في مجالات التجارة الإلكترونية، والإعلانات الرقمية، والتسويق الافتراضي. ومع ذلك، وعلى الرغم من قدرة نماذج الانتشار (diffusion models) الحالية على التقديم الواقعي للغاية (photorealistic rendering)، إلا أنها لا تزال تواجه إخفاقات متكررة في: (1) الاستقرار الهيكلي للمناطق الحساسة مثل اليدين والوجه، و(2) التلامس المنطقي من الناحية الفيزيائية (على سبيل المثال، تجنب تداخل اليد مع الشيء).نقدم في هذا البحث CoInteract، وهو إطار عمل شامل (end-to-end framework) لتوليد فيديوهات HOI بناءً على صورة مرجعية للشخص، وصورة مرجعية للمنتج، ومطالبات نصية (text prompts)، وصوت كلامي. يقدم CoInteract تصميمين متكاملين مدمجين في هيكل "محول الانتشار" (Diffusion Transformer - DiT).أولاً، نقترح نموذج "مزيج الخبراء المدرك للبشر" (Human-Aware Mixture-of-Experts - MoE)، الذي يقوم بتوجيه الـ tokens إلى خبراء متخصصين في مناطق محددة وخفاف الوزن عبر توجيه مُشرف مكانيًا (spatially supervised routing)، مما يحسن الدقة الهيكلية الدقيقة بأقل قدر من العبء الإضافي على المعلمات (parameter overhead).ثانياً، نقترح "التوليد المشترك ذو البنية المكانية" (Spatially-Structured Co-Generation)، وهو نموذج تدريب ثنائي المسار يعمل على نمذجة مسار مظهر RGB ومسار هيكلي مساعد لـ HOI بشكل مشترك لدمج الأولويات الهندسية للتفاعل (interaction geometry priors). أثناء التدريب، يقوم مسار HOI بالانتباه إلى الـ tokens الخاصة بـ RGB، وتعمل الرقابة الخاصة به على تنظيم أوزان الهيكل المشترك؛ أما عند الاستدلال (inference)، فيتم إزالة فرع HOI لضمان توليد RGB دون أي عبء إضافي.تُظهر النتائج التجريبية أن CoInteract يتفوق بشكل كبير على الأساليب الحالية من حيث الاستقرار الهيكلي، والاتساق المنطقي، وواقعية التفاعل.
One-sentence Summary
CoInteract is an end-to-end framework for human-object interaction video synthesis that utilizes a Diffusion Transformer backbone integrated with a Human-Aware Mixture-of-Experts for structural fidelity and a dual-stream Spatially-Structured Co-Generation paradigm to inject geometric priors, significantly outperforming existing methods in structural stability, logical consistency, and interaction realism.
Key Contributions
- The paper introduces CoInteract, an end-to-end framework for speech-driven human-object interaction video synthesis that conditions generation on person and product reference images, text prompts, and speech audio.
- A Human-Aware Mixture-of-Experts (MoE) is embedded directly into the Diffusion Transformer backbone to improve the structural fidelity of sensitive regions like hands and faces through a spatially supervised routing policy.
- The work presents a Spatially-Structured Co-Generation paradigm that utilizes a dual-stream training approach to inject interaction geometry priors via an auxiliary HOI structure stream, achieving superior structural stability and interaction realism without increasing inference overhead.
Introduction
Synthesizing human-object interaction (HOI) videos is essential for applications in e-commerce, digital advertising, and virtual marketing. While current diffusion models produce photorealistic results, they often struggle with structural stability in sensitive regions like hands and faces and frequently fail to maintain physically plausible contact, leading to issues such as hand-object interpenetration. The authors leverage a Diffusion Transformer (DiT) backbone to introduce CoInteract, an end-to-end framework that embeds structural priors directly into the generative process. Their contribution is twofold: they implement a Human-Aware Mixture-of-Experts (MoE) to improve fine-grained fidelity in hands and faces through spatially supervised routing, and they propose a Spatially-Structured Co-Generation paradigm that uses an auxiliary structure stream to teach the model interaction geometry during training without adding computational overhead during inference.
Method
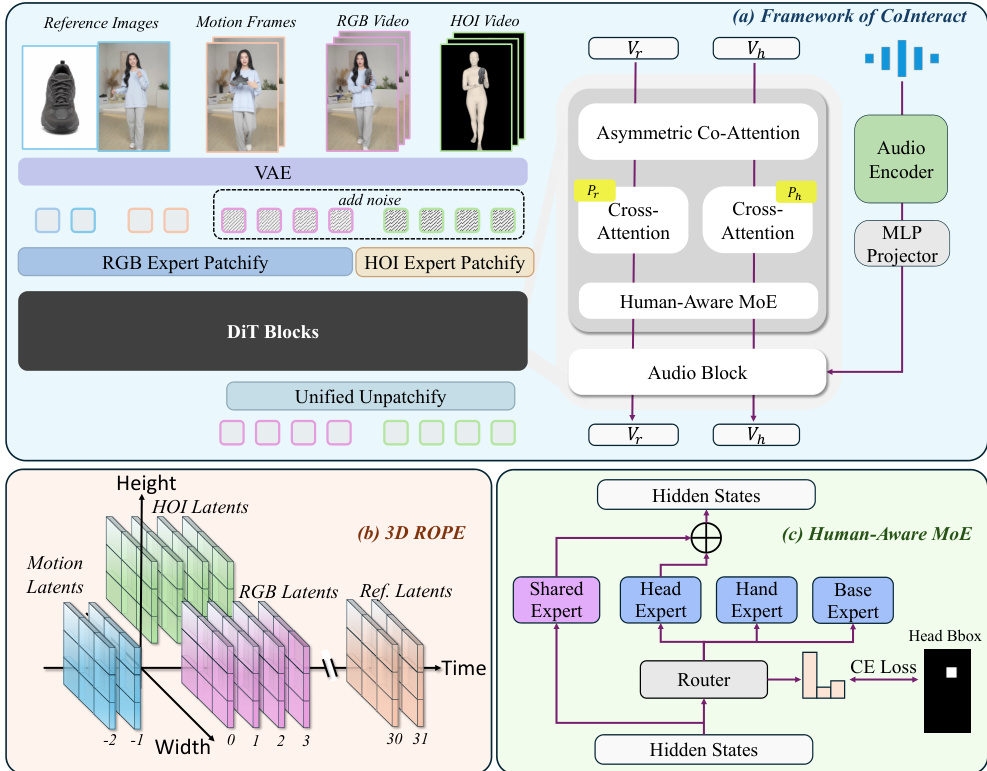
The authors leverage CoInteract, an end-to-end framework for speech-driven human-object interaction (HOI) video synthesis, which builds upon a shared Diffusion Transformer (DiT) backbone to generate structurally stable and physically plausible videos. The framework operates on dual reference images—character identity and product—and motion frames that preserve temporal continuity. Unlike conventional video diffusion models that operate purely in RGB space, CoInteract explicitly injects interaction structure and body-level consistency into the shared DiT backbone through a unified co-generation paradigm.

As shown in the figure below, the framework jointly generates an RGB appearance stream zr and an auxiliary HOI structure stream zh within a single DiT backbone. The HOI structure stream is constructed as a texture-stripped, silhouette-like 3-channel rendering obtained by projecting the recovered human mesh to the image plane and fusing the projected object mask. This produces a pixel-aligned structural target that emphasizes interaction boundaries while discarding RGB texture. The two streams are tokenized using modality-specific patch embedding layers with identical patch sizes and fed into shared DiT blocks. Within each DiT block, the streams share all transformer parameters but employ stream-specific modulation parameters (scale and shift in adaptive layer normalization), enabling the backbone to specialize feature statistics for appearance and structure without duplicating the full model.
The model is trained with a joint flow-matching objective that supervises both streams:
Lflow=Lr+λhLh. Lr=Et,z0,z1[∥vr−vθ(zr,t,t,c)∥22],Lh=Et,z0,z1[∥vh−vθ(zh,t,t,c)∥22].Here, v denotes the target velocity field, t is the diffusion timestep, and c denotes conditioning inputs including text, audio, dual reference images, and motion latents. The hyperparameter λh is set to 1 unless otherwise stated.
To seamlessly integrate heterogeneous modalities—ranging from historical motion and static references to dual-stream generative latents—the framework employs 3D Rotary Positional Encoding (3D RoPE). As illustrated in the figure below, each token is assigned a 3D coordinate (h,w,t) encoded by 3D RoPE. Spatial coordinates are assigned such that the two streams are concatenated along the width dimension, with distinct horizontal coordinates (e.g., w∈[0,W] for RGB and w∈[−W,0] for HOI) while sharing identical height and time indices, enabling cross-stream alignment through relative positional distances. Temporal causality and reference anchoring are enforced by structuring the temporal axis: historical motion frames (t<0) are assigned negative indices to encourage causal continuity, while static reference images are mapped to a far-field temporal location (e.g., t=30,31) to treat them as global identity anchors. Formally, the position of any token x is encoded as:
Pos(xi,j,k)=RoPE3D(hi,wi′,tk),where wj′ accounts for the virtual width shift in the HOI stream. This unified mapping encourages the attention mechanism to respect structural and temporal relationships across all inputs.
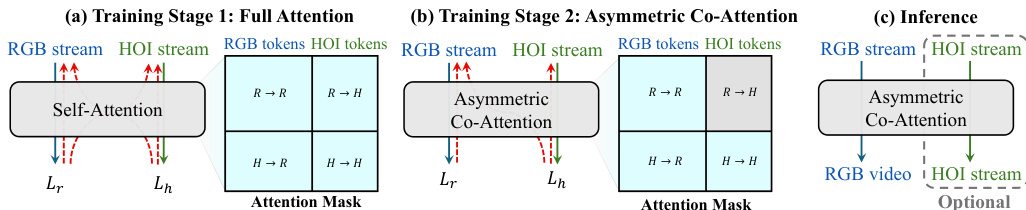
To inject interaction-structure supervision while maintaining inference efficiency, the framework adopts a two-stage training strategy with an Asymmetric Co-Attention mechanism. In Stage 1, full bidirectional attention is applied across both streams to establish coupling and enable rapid convergence. In Stage 2, an asymmetric attention mask is enforced. Let Tr and Th denote the token sets for the RGB and HOI streams, respectively. The mask M is defined as:
Mi,j=⎩⎨⎧1,1,0,if i∈Tr,j∈Tr,if i∈Th,j∈Tr∪Th,otherwise.Under this mask, RGB queries attend only to RGB tokens, making the RGB pathway independent of the HOI branch and thus removable at inference with zero overhead. HOI queries, conversely, attend to both streams, leveraging cleaner RGB features to predict interaction structure. Crucially, Lh backpropagates through the HOI←-RGB cross-attention into the shared DiT parameters, transferring interaction-structure supervision to the RGB generator even when the HOI branch is removed.
To address artifacts in hands and faces due to their high-frequency detail and articulation complexity, the framework incorporates a Human-Aware Mixture-of-Experts (MoE) module. This module routes tokens to region-specialized experts via a spatially supervised router R. The module includes a Shared expert that reuses the original DiT FFN as a shortcut path and three lightweight experts (Head, Hand, Base) implemented as small FFNs, introducing a modest parameter overhead. The routing probability for token xi is computed as:
G(xi)=Softmax(Wq⋅sg[hi]),where sg[⋅] applies a stop-gradient operation to hidden states before routing. Using face and hand bounding boxes, the router assigns tokens inside the corresponding regions to Ehead or Ehand, while remaining tokens are processed by the base expert. Specialization is enforced via a cross-entropy routing loss:
Lroute=−i∑k∈{head,hand,base}∑1(yi=k)log(G(xi)k),where yi is the ground-truth region label. The total training objective combines the flow-matching loss and the routing loss:
Ltotal=Lflow+ηLroute.
The framework's data curation process transforms raw HOI videos into paired RGB and HOI-structure representations. First, entity decoupling is performed using Qwen-Edit to create independent person and product references, followed by a validation module that filters mismatched triplets. For geometric supervision, SAM3 is used to obtain object masks and SAM3D-body to recover a human mesh, which is projected to the image plane. The projected human rendering is fused with the object mask to form the texture-stripped HOI structure stream. Both RGB video and HOI stream are encoded into a shared latent space via a pre-trained VAE. Additionally, off-the-shelf detectors provide face and hand bounding boxes, which serve as explicit supervision for the MoE router during training.
Experiment
The evaluation compares CoInteract against several baseline models using quantitative metrics, qualitative visual analysis, and a human user study to assess video quality, human-object interaction (HOI) plausibility, reference consistency, and audio-visual alignment. Results demonstrate that CoInteract achieves superior interaction rationality, hand structural stability, and identity preservation while maintaining high temporal coherence and scene consistency. Ablation studies further validate that the dual-stream co-generation and Human-Aware MoE are essential for preventing physical implausibility and structural collapse in high-frequency regions.
The authors compare CoInteract against several baselines on a set of metrics covering video quality, human-object interaction, reference consistency, and audio-visual alignment. Results show that CoInteract achieves the best or competitive performance across most metrics, particularly excelling in interaction plausibility, hand quality, and reference fidelity. The method demonstrates strong performance in both quantitative evaluations and user studies, with qualitative results highlighting its ability to maintain coherent hand-object interactions and structural consistency. CoInteract achieves the highest or competitive results across most evaluation metrics, particularly in interaction plausibility and hand quality. CoInteract outperforms baselines in reference consistency, maintaining strong alignment with both identity and product references. CoInteract receives the lowest mean rank in user studies across all criteria, with the most significant advantage in interaction plausibility.
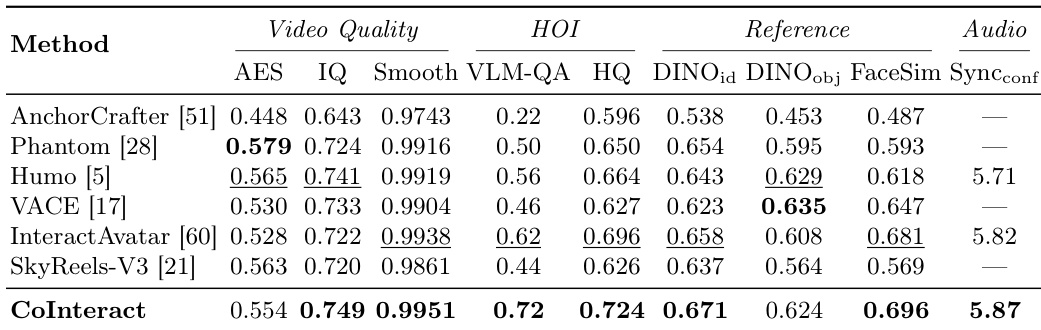
{"summary": "The authors conduct a quantitative and qualitative evaluation of CoInteract against several baselines, focusing on interaction plausibility, reference consistency, and visual quality. Results show that CoInteract achieves the best performance across most metrics, particularly in human-object interaction and structural fidelity, with user study rankings confirming its superiority in interaction plausibility and consistency. Ablation studies further demonstrate the importance of key components such as the dual-stream co-generation and human-aware mixture-of-experts architecture.", "highlights": ["CoInteract achieves the best performance across most metrics, particularly in interaction plausibility and structural fidelity.", "The model outperforms baselines in user study rankings, especially in interaction plausibility and consistency.", "Ablation studies confirm that both the dual-stream co-generation and human-aware mixture-of-experts are critical for maintaining interaction quality and structural stability."]

The authors conduct an ablation study to evaluate the impact of key components in CoInteract, comparing variants with and without the Human-Aware MoE, HOI co-generation, and asymmetric attention masking. Results show that removing the HOI stream leads to the most significant drop in interaction plausibility, while the MoE component is critical for maintaining fine-grained structural fidelity. The asymmetric mask improves efficiency without substantial loss in performance, and the full model achieves the best overall results across multiple metrics. Removing the HOI stream causes the largest drop in interaction plausibility, indicating its importance for physical interaction constraints. The Human-Aware MoE component is crucial for maintaining fine-grained structural fidelity, particularly in hand and face regions. The asymmetric attention mask improves inference efficiency with minimal performance trade-off compared to the full model.
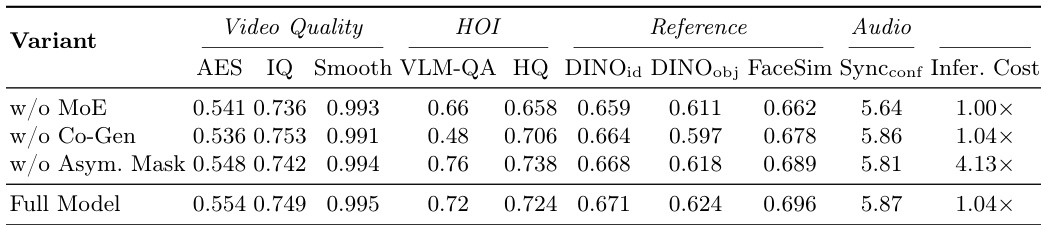
The authors evaluate CoInteract against several baselines through quantitative metrics and user studies to assess video quality, interaction plausibility, and reference consistency. The results demonstrate that CoInteract excels in maintaining coherent hand-object interactions and structural fidelity while adhering closely to identity and product references. Ablation studies further validate the necessity of key components, showing that the HOI co-generation stream is vital for physical interaction constraints and the Human-Aware MoE is essential for fine-grained structural detail.