Command Palette
Search for a command to run...
SmartPhotoCrafter: توحيد عمليات الاستدلال والتوليد والتحسين لتحرير الصور الفوتوغرافية آلياً
SmartPhotoCrafter: توحيد عمليات الاستدلال والتوليد والتحسين لتحرير الصور الفوتوغرافية آلياً
الملخص
إليك الترجمة الاحترافية للنص إلى اللغة العربية، مع الالتزام بالمعايير التقنية والأكاديمية المذكورة:تتطلب عملية تحرير الصور الفوتوغرافية التقليدية عادةً امتلاك المستخدمين لفهم جمالي كافٍ لتقديم تعليمات مناسبة لضبط جودة الصورة ومعايير الكاميرا. ومع ذلك، يعتمد هذا النموذج على التعليمات البشرية الصريحة للنوايا الجمالية، والتي غالباً ما تكون غامضة، أو غير مكتملة، أو يصعب على المستخدمين غير الخبراء الوصول إليها. علاوة على ذلك، تعتمد نماذج التحرير الحديثة في الغالب على التعليمات التي يقدمها المستخدم، بينما تفتقر إلى القدرة على فهم أوجه القصور الجمالية والاستنتاج المنطقي لاستراتيجيات التحسين.في هذا العمل، نقترح SmartPhotoCrafter، وهو منهجية آلية لتحرير الصور الفوتوغرافية تصيغ عملية تحرير الصور كعملية مترابطة وثيقة بين الاستنتاج المنطقي والتوليد (reasoning-to-generation). يقوم النموذج المقترح أولاً بإجراء فهم لجودة الصورة وتحديد أوجه القصور من خلال وحدة "ناقد الصور" (Image Critic module)، ومن ثم تقوم وحدة "الفنان الفوتوغرافي" (Photographic Artist module) بتنفيذ تعديلات مستهدفة لتعزيز جاذبية الصورة، مما يلغي الحاجة إلى تعليمات بشرية صريحة.تم اعتماد pipeline تدريب متعدد المراحل يتكون من:(i) التدريب المسبق الأساسي (Foundation pretraining) لإرساء الفهم الجمالي الأساسي وقدرات التحرير.(ii) التكيف مع إشراف متعدد التعديلات موجه بالاستنتاج (reasoning-guided multi-edit supervision) لدمج توجيهات دلالية غنية.(iii) التعلم التعزيزي المنسق بين الاستنتاج والتوليد (Coordinated reasoning-to-generation reinforcement learning) لتحسين عمليات الاستنتاج والتوليد بشكل مشترك.
One-sentence Summary
SmartPhotoCrafter is an automatic photographic image editing method that formulates editing as a tightly coupled reasoning-to-generation process employing an Image Critic module for deficiency identification and a Photographic Artist module for targeted edits to enhance image appeal via a multi-stage training pipeline comprising foundation pretraining, adaptation with reasoning-guided multi-edit supervision, and coordinated reasoning-to-generation reinforcement learning to eliminate the need for explicit human instructions.
Key Contributions
- SmartPhotoCrafter is proposed as an automatic photographic image editing method that formulates the task as a tightly coupled reasoning-to-generation process utilizing an Image Critic module and a Photographic Artist module, eliminating the need for explicit human instructions.
- A multi-stage training pipeline is adopted comprising foundation pretraining, adaptation with reasoning-guided multi-edit supervision, and coordinated reasoning-to-generation reinforcement learning to jointly optimize reasoning and generation.
- Experimental results demonstrate that SmartPhotoCrafter achieves strong performance across diverse enhancement scenarios while enabling automatic photorealistic edits that are semantically guided and photometrically sensitive.
Introduction
Automatic photographic editing requires balancing aesthetic perception with technical adjustments, yet existing instruction-driven models depend heavily on user expertise to define improvement strategies. Current approaches often lack the capability to diagnose image deficiencies or perform subtle photometric refinements necessary for high-quality enhancement. To address these gaps, the authors propose SmartPhotoCrafter, a unified framework that integrates multimodal reasoning with image generation. Their method employs an Image Critic module to assess quality and guide a Photographic Artist module through a tightly coupled reasoning-to-generation process. The authors implement a multi-stage training pipeline featuring coordinated reinforcement learning to jointly optimize semantic understanding and photometric fidelity without explicit human instructions.
Dataset
-
Overall Strategy The authors design stage-specific datasets to progressively shape reasoning capability, controllable generation, and cross-module collaboration across the training pipeline.
-
Image Critic Dataset
- Sources: Combines IQA datasets (KonIQ, KADID, SPAQ) with image distortion datasets (FoundIR, RealBlur, TMM22, LOL, ISTD, RDD, SRD) and editing-related data (GoPro).
- Processing: Uses Qwen2.5-VL-72B to generate Chain-of-Thought reasoning, scalar quality assessments, and structured edit suggestions.
- Filtering: Retains original MOS scores for IQA data while replacing model-predicted scores to reduce noise. Excludes samples where generated reasoning conflicts with annotated distortion labels.
- Training Size: Approximately 80K annotated samples are used for foundation pretraining.
- Output Format: Autoregressive SFT generates structured output in the form of [reasoning → suggestion → score].
-
Photographic Artist Dataset
- Sources: Utilizes public restoration pairs and the FilmSet dataset for color grading. Depth-of-field data comes from RealBokeh and BokehDiff.
- Processing: Constructs task-specific prompts for restoration (e.g., remove blur). Generates synthetic retouching pairs by applying parameterized adjustments to exposure, contrast, saturation, and CCT. Creates multi-level blur pairs for depth-of-field control and stacks random retouching adjustments on restoration data for multi-edit capability.
- Training Size: Approximately 160K paired images with instruction prompts are used during Stage I.
-
Unified Understanding and Generation
- Sources: Leverages image pairs from the FiveK dataset and high-aesthetic images from the AVA dataset.
- Processing: Applies random synthetic degradations to AVA images to create degraded-GT pairs with corresponding edit operations.
- Training Size: Incorporates around 30K samples in Stage II and 18K samples in Stage III to optimize both modules jointly.
Method
The SmartPhotoCrafter framework addresses the challenge of automatic photographic enhancement by formulating it as a reasoning-guided image enhancement problem. The architecture is built upon two complementary modules: an Image Critic (fc) responsible for aesthetic understanding and a Photographic Artist (fa) responsible for high-fidelity generation. The system aims to produce an enhanced output image Xe that is visually appealing and semantically consistent with the input X.
Refer to the framework diagram for an overview of the data construction and unified understanding pipeline.
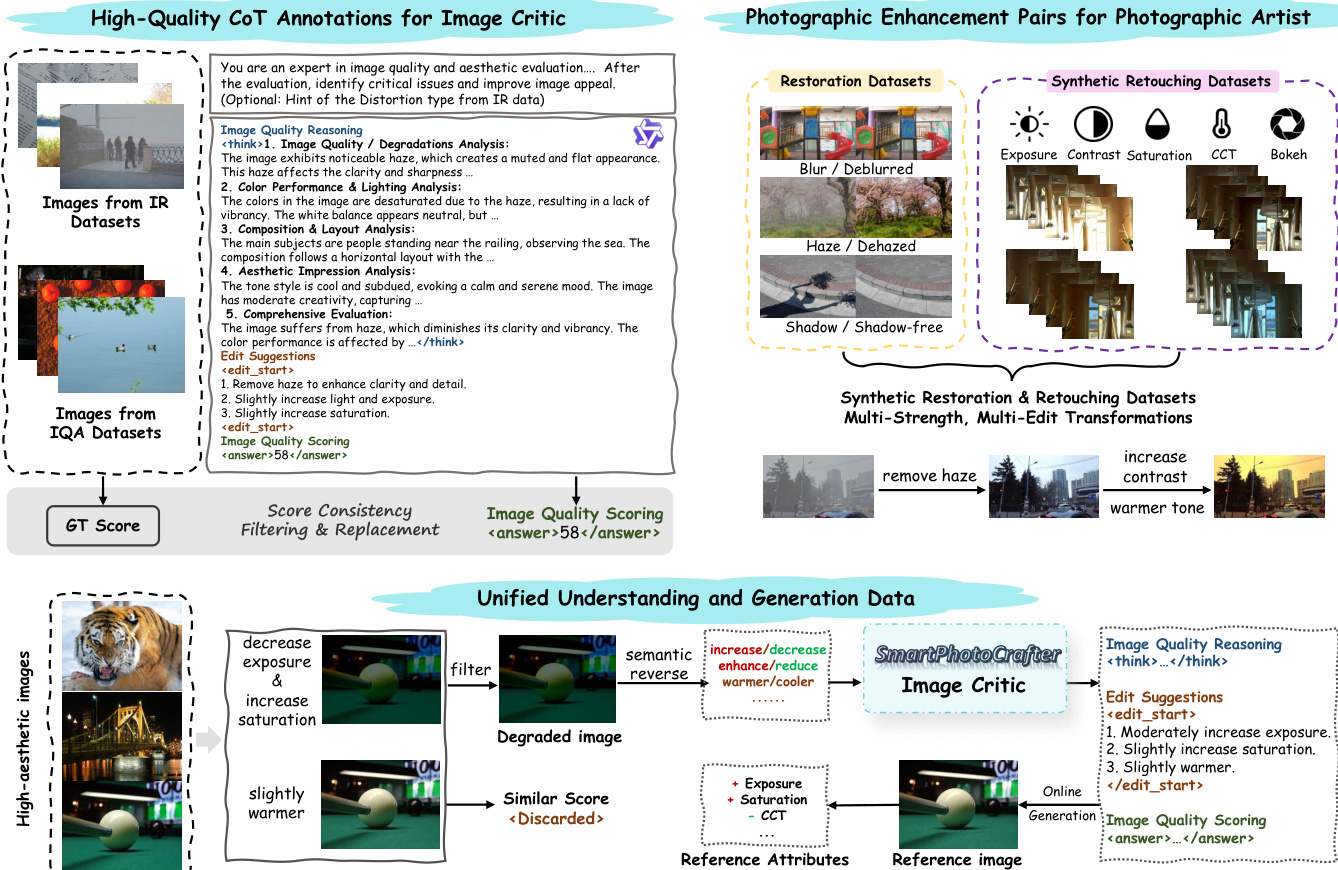
The Image Critic interprets an input image X into a structured output comprising three components: a chain-of-thought aesthetic reasoning statement R, edit suggestions E specifying actionable transformations, and a predicted quality score S. This module leverages high-quality CoT annotations derived from diverse sources, including image quality assessment datasets and photographic enhancement pairs involving restoration and retouching. The Photographic Artist then generates the edited image Xe conditioned on the input image X and the reasoning latent Hc derived from the Image Critic. This design ensures that the generated edits are semantically grounded in the reasoning process rather than relying solely on textual prompts.
To enable unified aesthetic understanding and faithful editing, the authors adopt a multi-stage training pipeline. In the first stage, Foundation Pre-training, both modules undergo supervised fine-tuning (SFT) independently. The Image Critic is trained on IQA and editing datasets to learn quality assessment and suggestion generation, while the Photographic Artist is trained on large-scale restoration and retouching datasets using a flow matching objective.
The second stage, Reasoning-Conditioned Adaptation, semantically couples the two modules. The Photographic Artist is adapted to reasoning-guided editing by conditioning it on the reasoning-based latent states generated by the Image Critic. The generation process is defined as:
Xe=fa(X,Hc),Hc=Concat(h0(L),h1(L),…,hT−1(L)),where Hc denotes the reasoning-based latent produced by the Critic. This latent representation is obtained by concatenating the context and reasoning hidden states, serving as a conditioning signal that moves the model beyond simple instruction following.
The final stage involves Coordinated Reasoning-to-Generation Reinforcement Learning. Here, the authors propose a unified RL framework where GRPO optimizes the Image Critic for discrete reasoning, and DiffusionNFT optimizes the Photographic Artist for continuous generation. This closed-loop optimization addresses the limitations of supervised data alone, allowing the system to explore the full space of photographic adjustments.
Refer to the training pipeline diagram for a detailed visualization of the reward mechanisms applied to each module.
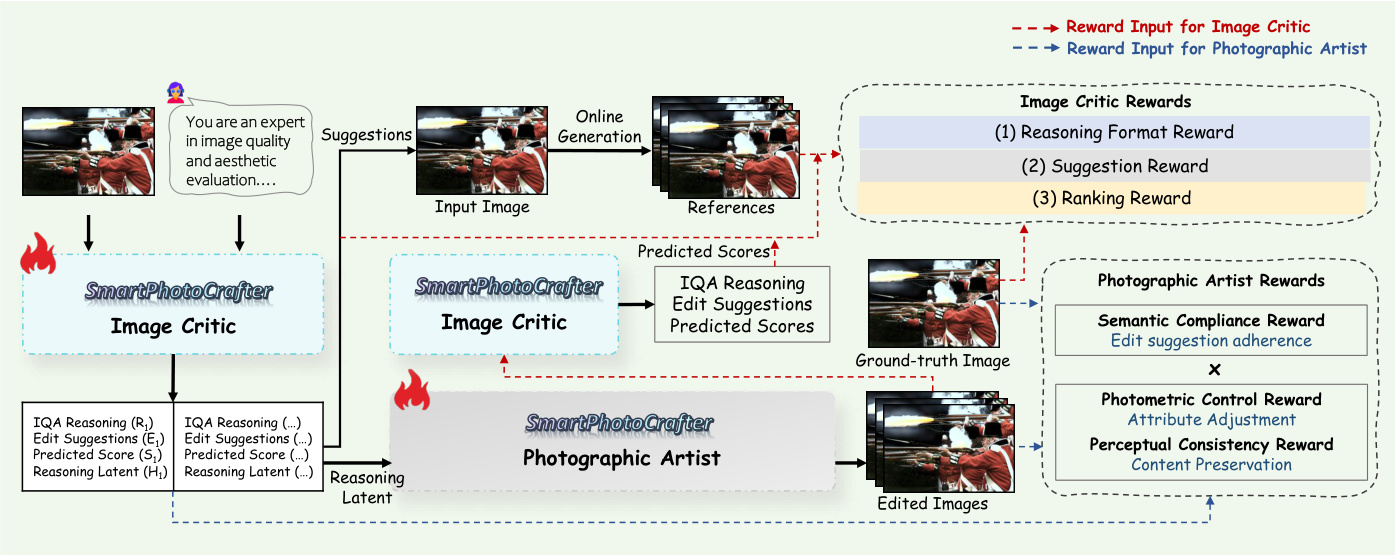
The reward design is critical for aligning the model with photographic aesthetics. For the Photographic Artist, a multi-level reward mechanism is employed, defined as rPA=rcomp×(λ1rphoto+λ2rperc). The Semantic Compliance Reward (rcomp) acts as a gating factor to ensure the generated image follows the editing intentions of the Critic. The Photometric Control Reward (rphoto) regulates the magnitude of adjustments like exposure and contrast by measuring attribute-wise deviations from the ground truth. Finally, the Perceptual Consistency Reward (rperc) uses LPIPS to enforce structural and textural fidelity.
For the Image Critic, the reward design focuses on Reasoning Format, Score Ranking, and Edit Suggestion quality. The Score Ranking Reward constructs input-edited pairs to ensure the Critic correctly recognizes improvements, while the Edit Suggestion Reward encourages the exploration of plausible editing strategies by evaluating whether suggested operations move the image closer to a high-aesthetic target in photometric attribute space.
Experiment
SmartPhotoCrafter is evaluated across automatic photographic enhancement, multi-edit instruction adherence, and image restoration tasks to assess its ability to improve aesthetics while preserving content. The model outperforms baselines by achieving a superior balance between perceptual quality and distributional consistency without introducing artifacts or unnatural stylization. Furthermore, ablation studies highlight the necessity of the retouching-aware reward design in guiding realistic tonal adjustments and preventing distribution drift during optimization. These findings collectively validate the system's robustness in executing complex editing instructions and generalizing to various low-level restoration scenarios.
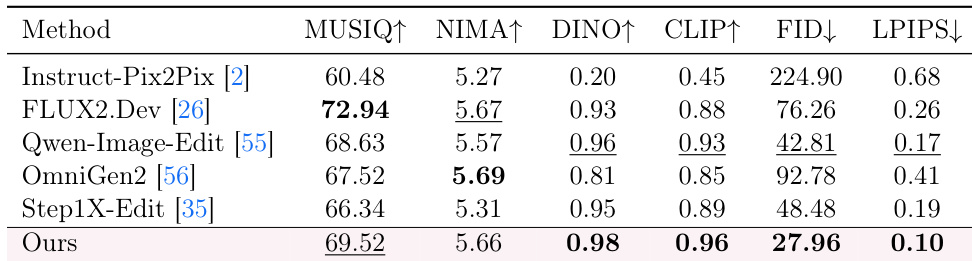
The authors evaluate the automatic photographic enhancement capability of their method against several open-source generative baselines using a suite of perceptual and semantic metrics. Results indicate that the proposed method achieves the best performance in semantic alignment and distribution fidelity while maintaining competitive perceptual quality scores. This suggests the model effectively enhances visual quality while preserving high-level semantics and ensuring consistency with photographic image distributions. The proposed method achieves the highest scores in semantic consistency and distribution fidelity metrics compared to all baselines. The model demonstrates competitive perceptual quality, ranking second in both MUSIQ and NIMA evaluations. Results show a more balanced improvement across perceptual quality and distributional consistency compared to methods that prioritize aesthetic scores.
The authors conduct an ablation study to evaluate the impact of reinforcement learning and photometric rewards on model performance. Results indicate that while standard reinforcement learning improves perceptual quality, it degrades distributional fidelity. Incorporating the full reward design, including photometric constraints, achieves the best balance, yielding superior scores across perceptual, aesthetic, and semantic metrics. The full reinforcement learning configuration achieves the highest performance across all evaluated metrics including MUSIQ, NIMA, and CLIP. Reinforcement learning without photometric rewards leads to a significant increase in FID, indicating a drift from the natural image distribution. The proposed reward design effectively guides the model toward realistic tonal adjustments while maintaining high semantic alignment.

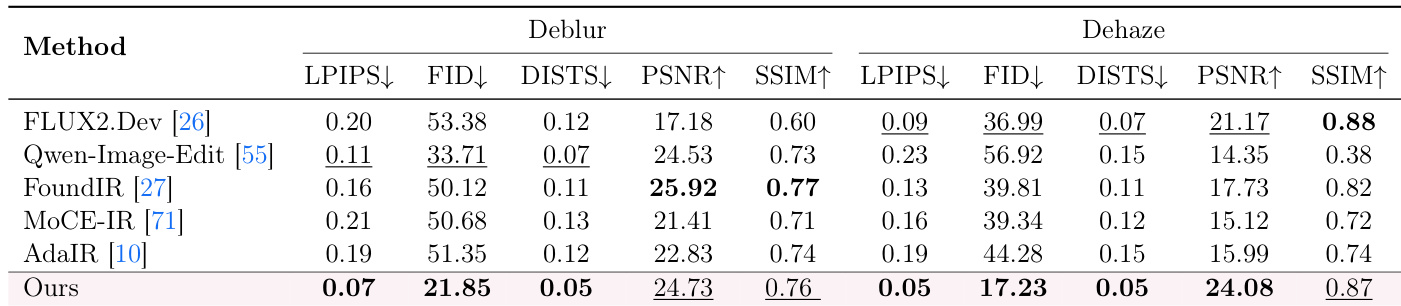
The authors evaluate the restoration capability of their method on deblurring and dehazing tasks against several baselines. The results indicate that their approach achieves the best performance in perceptual similarity and distribution fidelity metrics, while maintaining competitive scores in reconstruction fidelity. This suggests the method generalizes well to classical restoration scenarios by balancing enhancement strength with content preservation. The proposed method achieves the best scores in perceptual metrics such as LPIPS, FID, and DISTS for both deblurring and dehazing. It demonstrates strong reconstruction fidelity, ranking among the top performers in PSNR and SSIM across the tested restoration tasks. The method generalizes effectively to low-level image restoration, showing a favorable balance between perceptual quality and structural consistency.
The authors evaluate the model's ability to follow complex multi-edit instructions that combine image restoration and retouching tasks. The proposed method outperforms all baselines across all metrics, demonstrating superior adherence to instructions while maintaining high structural and semantic fidelity. The method achieves the highest scores in structural consistency and semantic alignment compared to other approaches. It significantly reduces perceptual discrepancies and distributional shifts, outperforming baselines in LPIPS and FID. Results confirm the model's capability to execute combined restoration and retouching tasks effectively.
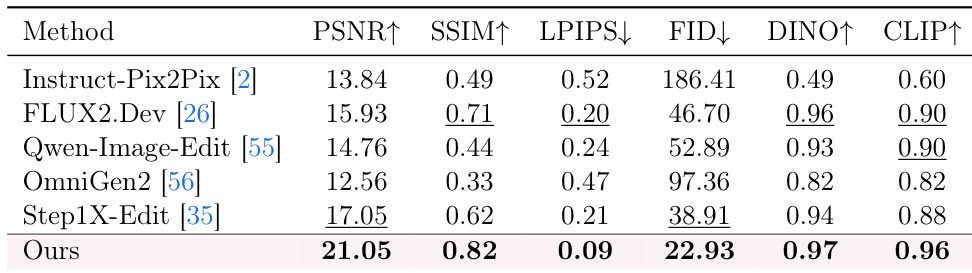
The authors evaluate their method against open-source baselines across photographic enhancement, restoration, and multi-edit instruction following tasks using perceptual and semantic metrics. Results indicate that the proposed approach achieves superior semantic alignment and distribution fidelity while maintaining competitive perceptual quality, particularly when utilizing the full reinforcement learning reward design. Furthermore, the model generalizes effectively to classical restoration scenarios and complex combined editing tasks by balancing enhancement strength with structural consistency.