Command Palette
Search for a command to run...
EasyVideoR1: تعزيز التعلم المعزز (RL) لتسهيل فهم الفيديو
EasyVideoR1: تعزيز التعلم المعزز (RL) لتسهيل فهم الفيديو
Chuanyu Qin Chenxu Yang Qingyi Si Naibin Gu Dingyu Yao Zheng Lin Peng Fu Nan Duan Jiaqi Wang
الملخص
أثبت التعلم التعزيزي من المكافآت القابلة للتحقق (Reinforcement learning from verifiable rewards - RLVR) فعالية ملحوظة في تحسين قدرات الاستدلال لدى النماذج اللغوية الكبيرة. ومع تطور النماذج لتتحول إلى بنيات متعددة الوسائط (multimodal architectures) بشكل أصيل، أصبح توسيع نطاق RLVR ليشمل فهم الفيديو أمراً بالغ الأهمية، ومع ذلك لا يزال هذا المجال غير مستكشف إلى حد كبير؛ ويعود ذلك إلى تنوع أنواع مهام الفيديو، والأعباء الحسابية الناتجة عن فك التشفير المتكرر والمعالجة المسبقة للمدخلات البصرية عالية الأبعاد، وصعوبة التقييم القابل لإعادة الإنتاج عبر العديد من المعلمات الفائقة (hyperparameters) الحساسة. وتوفر أطر تدريب RL مفتوحة المصدر الحالية بنية تحتية قوية لسيناريوهات النصوص والصور، ولكنها تفتقر إلى تحسينات منهجية مصممة خصيصاً للوسائط المرئية (video modality).في هذا العمل، نقدم EasyVideoR1، وهو إطار عمل كامل وفعال للتعلم التعزيزي مصمم خصيصاً لتدريب النماذج اللغوية البصرية الكبيرة (large vision-language models) على مهام فهم الفيديو. يقدم EasyVideoR1 المساهمات التالية:(1) خط تدريب كامل لـ RL الخاص بالفيديو مع معالجة مسبقة دون اتصال (offline preprocessing) وتخزين مؤقت للموترات (tensor caching)، مما يلغي الحاجة إلى فك تشفير الفيديو بشكل متكرر ويحقق تحسناً في معدل الإنتاجية (throughput) بمقدار 1.47 مرة.(2) نظام مكافآت شامل وواعٍ بالمهام (task-aware reward system) يغطي 11 نوعاً مختلفاً من مشكلات الفيديو والصور، مع توجيه موحد وقابلية للتوسع النمطي (modular extension).(3) نموذج تدريب بيانات مختلط بين الـ offline والـ online يجمع بين المسارات (trajectories) عالية الجودة المنسقة والاستكشاف القائم على السياسة (on-policy exploration)، مما يفيد في تعلم المهام الأكثر صعوبة.(4) تدريب مشترك للصور والفيديو مع ميزانيات بكسل (pixel budgets) قابلة للضبط بشكل مستقل، مما يسمح للوسيطين بتعزيز بعضهما البعض بشكل متبادل.(5) إطار تقييم غير متزامن متعدد المعايير (asynchronous multi-benchmark evaluation framework) يغطي 22 معياراً رئيساً لفهم الفيديو، مع دقة مُعاد إنتاجها تتوافق تماماً مع النتائج المعلنة رسمياً.
One-sentence Summary
Researchers from Microsoft and other institutions propose EasyVideoR1, a specialized reinforcement learning framework that enhances video understanding in large vision-language models by utilizing offline preprocessing and tensor caching to eliminate redundant decoding and reduce computational overhead.
Key Contributions
- This work introduces EasyVideoR1, an efficient reinforcement learning framework specifically optimized for training large vision-language models on video understanding tasks.
- The framework implements a specialized training pipeline featuring offline preprocessing with metadata-consistent tensor caching and pipeline-level adaptations for mixed-modality training to eliminate redundant decoding and CPU-bound I/O bottlenecks.
- The paper provides a high-throughput evaluation framework built on vLLM's AsyncLLMEngine that utilizes asynchronous processing to eliminate CPU-GPU serialization and maintain high GPU utilization during multi-benchmark testing.
Introduction
As large language models evolve into natively multimodal architectures, applying reinforcement learning from verifiable rewards (RLVR) to video understanding becomes essential for applications like autonomous driving and embodied intelligence. However, existing RL frameworks primarily target text or image modalities and struggle with the unique demands of video, such as high computational overhead from redundant decoding, complex multi-task reward design, and slow evaluation processes. The authors leverage these challenges to introduce EasyVideoR1, a complete and efficient reinforcement learning framework specifically optimized for video. Their contribution includes a high-throughput pipeline featuring offline preprocessing and tensor caching, a task-aware reward system for diverse video tasks, a hybrid offline-online training paradigm, and an asynchronous multi-benchmark evaluation framework that ensures reproducible accuracy.
Dataset
The authors utilize a comprehensive evaluation suite consisting of 22 video understanding benchmarks to assess model performance across diverse dimensions. The dataset composition and usage details are as follows:
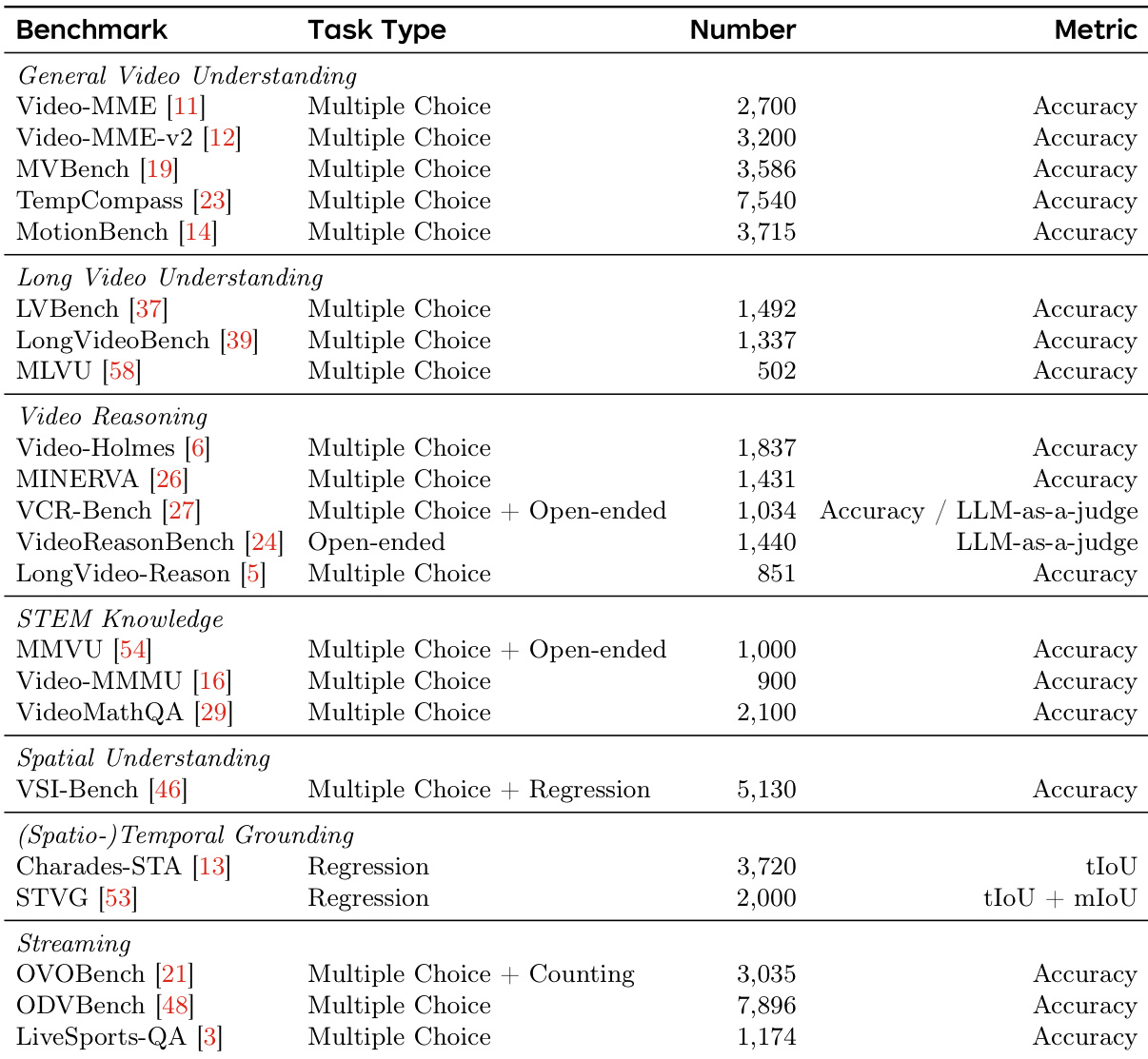
- Benchmark Composition and Categories: The benchmarks are organized into six distinct categories: general video understanding, long video understanding, video reasoning, STEM knowledge, spatial understanding, and (spatio-)temporal grounding and streaming video.
- Scope of Capabilities: The collection covers a wide spectrum of tasks, ranging from fine-grained motion perception and temporal reasoning to expert-level knowledge question answering and spatio-temporal localization.
- Modular Framework Integration: Each benchmark is integrated via a lightweight configuration that defines specific data loading logic, prompt formatting, answer extraction, and scoring functions.
- Processing and Reproducibility: The authors employ a modular adapter design that allows for consistent inference configurations across the entire suite. This ensures that the accuracy produced by the framework closely matches officially reported scores, facilitating fair and reproducible comparisons.
Method
The authors design EasyVideoR1 as a comprehensive framework for video understanding reinforcement learning, structured around three core dimensions: adapting the RL pipeline for video modalities, providing research-friendly interfaces for algorithm development, and enabling high-throughput evaluation. The overall architecture integrates these components into a unified training pipeline, as illustrated in the framework diagram below.

The framework begins with an offline preprocessing stage that decouples computationally expensive video decoding from the training loop. Videos are processed into .pt cache files containing temporally sampled and spatially resized frames, with each cache entry keyed by (video_path, fps, max_frames, max_pixels) to ensure automatic invalidation upon parameter changes. This preprocessing is parallelized across multiple worker processes with hash-based deduplication, minimizing redundant computation. During training, the dataset stage references only the lightweight cache file paths, avoiding large tensor transfers between nodes. When no cache exists, the system transparently falls back to on-the-fly decoding. To prevent double processing, VideoMetadata—including frame rate, sampling indices, and spatial dimensions—is propagated alongside cached frames throughout the pipeline, ensuring consistent behavior across stages.
The training pipeline consists of three sequential stages: dataset loading, rollout generation using vLLM, and actor training with FSDP. Each stage is adapted to handle mixed image-video inputs. For mixed-modality forward passes, the framework generates zero-valued dummy tensors for the inactive modality and connects them via zero-weighted addition, ensuring all parameters participate in every forward pass without introducing spurious gradients. Resolution budgets are decoupled into separate parameters—image_max_pixels, video_max_pixels, and video_max_frames—allowing independent tuning of compute resources for each modality. This enables efficient training on diverse data types while maintaining computational balance.
A task-aware reward system provides modular support for various video understanding tasks through a unified dispatcher that routes each sample to the appropriate reward module based on problem_type. Each task is implemented as an independent module, allowing for incremental extension. Prompt formatting is managed via Jinja2 templates that are dynamically rendered per task, facilitating flexible and consistent evaluation.
To address the cold-start problem in on-policy training, EasyVideoR1 implements a hybrid online-offline training paradigm. Each training sample may include a pre-collected offline trajectory, which replaces the final response in a group of n responses during rollout. This allows the framework to incorporate high-quality trajectories from stronger models or prior checkpoints while maintaining standard GRPO updates. The mechanism is controlled by a single flag and operates entirely at the rollout layer, preserving algorithmic integrity.
Joint image-video training leverages abundant image data to strengthen foundational visual reasoning while learning video-specific temporal understanding. Each sample includes a data_type field that routes it to the appropriate preprocessor, with decoupled resolution budgets ensuring independent tuning. A unified multimodal field schema across image and video samples removes modality-conditional branching, simplifying mixed-batch assembly. The framework enforces strict semantic consistency between textual placeholders and visual features by raising exceptions for mismatched token counts, preventing silent data corruption.
The evaluation framework introduces two key optimizations to achieve high throughput. Precomputed frame caching eliminates redundant CPU-bound preprocessing by storing video frames as cache files, reducing per-video latency from tens of seconds to milliseconds. This caching is parallelized across worker processes for efficient initial construction. An asynchronous inference design replaces the synchronous vLLM interface with a three-stage pipeline: IO, Prefill, and Decode. The IO stage continuously loads cached frames and submits inputs without blocking; the Prefill stage immediately processes incoming sequences and constructs key-value caches; the Decode stage generates tokens in an interleaved fashion, overlapping with prefetch operations. Chunked prefetch partitions long inputs into fixed-size chunks, ensuring consistent GPU occupancy regardless of sequence length. Together, these optimizations maintain continuous GPU utilization, achieving approximately 6–7× speedup over vanilla inference frameworks.
Experiment
The experiments evaluate the effectiveness of EasyVideoR1 training on the Qwen3-VL-8B-Instruct model and the efficiency gains provided by an offline preprocessing and caching mechanism. Results demonstrate that reinforcement learning significantly enhances the model's deliberative reasoning and mathematical capabilities, allowing it to achieve performance comparable to specialized thinking variants without additional inference overhead. Furthermore, the implementation of cache-based loading substantially improves training throughput by eliminating redundant video decoding during the rollout and reference model phases.
The authors conduct experiments to evaluate the impact of RL training with EasyVideoR1 on a base video-language model, comparing its performance to a thinking variant and analyzing the efficiency gains from offline preprocessing. Results show that RL training improves average accuracy, with significant gains on reasoning and mathematical tasks, while achieving performance comparable to the thinking variant without additional inference overhead. The offline caching mechanism substantially reduces training step time and increases token throughput by eliminating redundant video decoding. RL training with EasyVideoR1 improves average accuracy and achieves gains on reasoning and mathematical tasks, matching or surpassing the performance of a thinking variant. Offline caching reduces training step time and increases token throughput by eliminating redundant video decoding during inference. The training framework maintains consistent training semantics while enabling faster end-to-end pipeline execution through optimized data loading.
The authors compare three model variants across multiple benchmarks, showing that training with EasyVideoR1 improves average accuracy and achieves gains across various task categories, particularly in reasoning and mathematical tasks. The RL-trained model performs comparably or better than a thinking variant without requiring additional inference overhead. The results demonstrate that offline preprocessing and caching significantly enhance training efficiency by reducing video decoding time and eliminating redundant computations. EasyVideoR1 training improves accuracy across all benchmark categories, with the largest gains observed in reasoning and mathematical tasks. The RL-trained model achieves comparable or superior results to the thinking variant on most benchmarks while operating in standard inference mode. Offline preprocessing and caching reduce step time and increase token throughput by eliminating redundant video decoding during training.
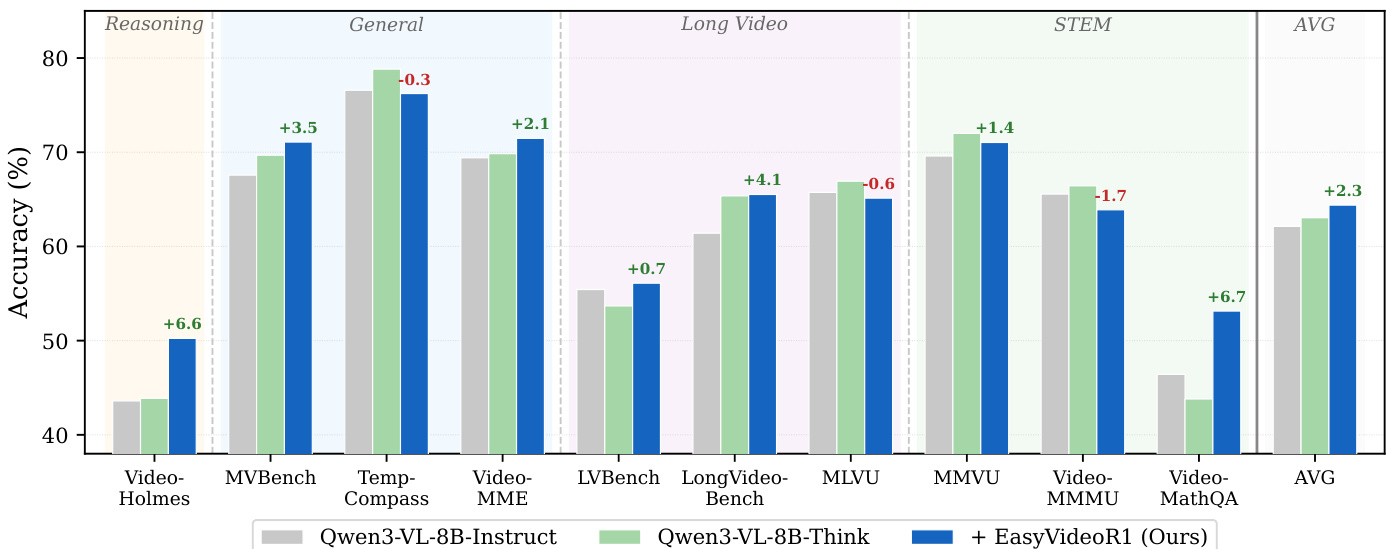
The authors evaluate the impact of RL training using EasyVideoR1 on a base video-language model by comparing it to a thinking variant and testing the efficiency of an offline preprocessing mechanism. The results demonstrate that RL training enhances overall accuracy, particularly in reasoning and mathematical tasks, while matching the performance of the thinking variant without increasing inference overhead. Additionally, the implementation of offline caching significantly improves training efficiency by eliminating redundant video decoding and increasing token throughput.