Command Palette
Search for a command to run...
قلل خسائرك! تعلم تقليم المسارات مبكراً من أجل reasoning متوازٍ فعال
قلل خسائرك! تعلم تقليم المسارات مبكراً من أجل reasoning متوازٍ فعال
Jiaxi Bi Tongxu Luo Wenyu Du Zhengyang Tang Benyou Wang
الملخص
بصفتي مترجماً متخصصاً في المجالات التقنية، يسعدني تقديم الترجمة الدقيقة لهذا النص العلمي إلى اللغة العربية، مع الالتزام بالمعايير التي وضعتها:الترجمة:يعزز الاستدلال المتوازي (Parallel reasoning) من أداء نماذج الاستدلال الكبيرة (LRMs)، إلا أنه يتسبب في تكاليف باهظة نتيجة المسارات غير المجدية التي تنجم عن الأخطاء المبكرة. وللتخفيف من حدة هذه المشكلة، يعد تقليم المسارات (path pruning) على مستوى البادئة (prefix level) أمراً ضرورياً، ومع ذلك، لا تزال الأبحاث الحالية مجزأة وتفتقر إلى إطار عمل موحد.في هذا العمل، نقترح أول تصنيف منهجي لعملية تقليم المسارات، حيث نصنف الطرق بناءً على مصدر الإشارة (داخلية مقابل خارجية) والقابلية للتعلم (قابلة للتعلم مقابل غير قابلة للتعلم). ويكشف هذا التصنيف عن الإمكانات غير المستغلة للطرق الداخلية القابلة للتعلم، مما دفعنا لاقتراح نموذج STOP (Super TOken for Pruning).تظهر التقييمات المكثفة عبر نماذج LRMs التي تتراوح أحجامها من 1.5B إلى 20B بارامتر أن STOP يحقق فعالية وكفاءة متفوقتين مقارنة بالنماذج المرجعية (baselines) الحالية. علاوة على ذلك، قمنا بالتحقق بدقة من قابلية توسع (scalability) نموذج STOP تحت ميزانيات حوسبة متغيرة؛ فعلى سبيل المثال، تمكن النموذج من رفع دقة GPT-OSS-20B في اختبار AIME25 من 84% إلى ما يقرب من 90% في ظل ميزانية حوسبة ثابتة. وأخيراً، قمنا بتلخيص نتائجنا في إرشادات تجريبية رسمية لتسهيل عملية النشر الأمثل في العالم الحقيقي.الكود، والبيانات، والنماذج متاحة عبر الرابط: https://bijiaxihh.github.io/STOP
One-sentence Summary
By establishing the first systematic taxonomy of path pruning based on signal source and learnability, the authors propose STOP, a learnable internal pruning method that enhances the efficiency of parallel reasoning in Large Reasoning Models from 1.5B to 20B parameters and improves the accuracy of GPT-OSS-20B on AIME25 from 84% to nearly 90% under fixed compute budgets.
Key Contributions
To identify the three main contributions, I will analyze the text based on the provided instructions:
-
Analyze the text for contribution cues:
- "we propose the first systematic taxonomy of path pruning..." → Contribution 1: A systematic taxonomy.
- "motivating our proposal of STOP (Super TOken for Pruning)." / "STOP is designed to bridge this gap, utilizing a trainable adapter to extract rich internal semantics..." → Contribution 2: The STOP method (an internal learnable pruning method).
- "Extensive evaluations... demonstrate that STOP achieves superior effectiveness and efficiency..." / "boosts GPT-OSS-20B accuracy on AIME25 from 84% to nearly 90%..." → Evidence for Contribution 2.
- "we distill our findings into formalized empirical guidelines..." / "This provides practitioners with a precise empirical guideline..." → Contribution 3: Empirical guidelines for deployment/optimization.
-
Draft the bullets following constraints:
-
Constraint Check: No first-person ("we", "our"), no em dashes, 1-2 sentences per bullet, third-person, include context/method/evidence.
-
Bullet 1 (Taxonomy): The paper introduces the first systematic taxonomy of path pruning, which categorizes existing methods based on their signal source and learnability. This classification identifies the unexplored potential of internal learnable modules for trajectory pruning.
-
Bullet 2 (STOP Method): The work presents STOP, a novel internal learnable pruning method that utilizes a trainable adapter to extract internal semantics for terminating unpromising paths. Evaluations on models ranging from 1.5B to 20B parameters show that STOP improves reasoning accuracy while reducing token consumption by over 70 percent.
-
Bullet 3 (Guidelines): The study provides formalized empirical guidelines and a robust interaction formulation to help practitioners optimize the trade-off between exploration and exploitation. These findings assist in managing computational constraints and scaling performance under varying compute budgets.
-
-
Final Polish (Ensuring no em dashes and strict adherence to "what, how, evidence"):
-
- The paper introduces a systematic taxonomy of path pruning that categorizes existing methods by signal source and learnability. This framework identifies the unexplored potential of internal learnable modules for trajectory pruning.
-
- The work presents STOP, a method that uses a trainable adapter to extract internal semantics for prefix-level path pruning. Experiments on models up to 20B parameters demonstrate that STOP enhances reasoning accuracy and reduces token consumption by over 70 percent.
-
- The research provides formalized empirical guidelines and an interaction formulation to optimize the trade-off between exploration and exploitation. These insights facilitate more efficient real-world deployment under varying computational constraints.
-
-
Final Review against constraints:
- Exactly three bullets? Yes.
- Concrete contributions? Yes (Taxonomy, STOP, Guidelines).
- No problem statements? Yes.
- 1-2 sentences? Yes.
- Context/Method/Evidence included? Yes.
- Third-person? Yes.
- No first-person? Yes.
- No em dashes? Yes.
- No headings/numbering? Yes.
\boxed{
- The paper introduces a systematic taxonomy of path pruning that categorizes existing methods by signal source and learnability. This framework identifies the unexplored potential of internal learnable modules for trajectory pruning.
- The work presents STOP, a method that uses a trainable adapter to extract internal semantics for prefix-level path pruning. Experiments on models up to 20B parameters demonstrate that STOP enhances reasoning accuracy and reduces token consumption by over 70 percent.
- The research provides formalized empirical guidelines and an interaction formulation to optimize the trade-off between exploration and exploitation. These insights facilitate more efficient real-world deployment under varying computational constraints. }
Introduction
Parallel reasoning improves the performance of Large Reasoning Models by sampling multiple trajectories to reach a consensus, but this process is computationally expensive and often wasted on flawed reasoning paths. Existing pruning methods are fragmented and typically force a trade-off between information richness and adaptability, either relying on high-latency external models or rigid, non-learnable internal heuristics. The authors address these limitations by proposing a systematic taxonomy of path pruning and introducing STOP (Super Token for Pruning), a novel method that leverages learnable internal signals to identify and terminate futile trajectories efficiently.
Dataset

The authors constructed a specialized supervised fine-tuning dataset designed to train a STOP module by mapping reasoning path prefixes to their corresponding success probabilities.
-
Dataset Composition and Sources
- The dataset is derived from high-quality mathematical and scientific benchmarks.
- The primary sources include approximately 1,000 problems from the AIME competition (years 1984 to 2023) and the non-Diamond portion of the GPQA dataset.
- To prevent data leakage, the authors strictly excluded AIME 2024, AIME 2025, and the GPQA Diamond subset from the training corpus.
-
Model-Specific Construction and Filtering
- The authors use a model-specific pipeline where each Large Reasoning Model (LRM) generates its own training data to match its unique capability level.
- A difficulty stratification strategy is applied to focus on the model's learnable boundary. Problems are filtered by generating 32 reasoning paths and calculating the pass rate.
- Trivial samples with more than 28 correct answers are excluded because the model has already mastered them.
- Intractable samples with fewer than 4 correct answers are excluded because they are likely beyond the model's current capacity.
- As model size increases, the volume of training data decreases because larger models find more samples to be trivial.
-
Processing and Metadata Construction
- Prefix Generation: The LRM generates reasoning trajectories which are then truncated at a fixed length of 2,048 tokens to create a prefix.
- Monte Carlo (MC) Estimation: To determine the success probability for each prefix, the authors perform 32 Monte Carlo rollouts. This involves generating 32 continuations for a fixed prefix at a temperature of 0.6.
- Labeling: The final label for each prefix is an MC-estimated success probability, calculated as the empirical accuracy (the fraction of correct continuations) among the 32 samples.
-
Usage in Training
- The resulting (prefix, success probability) pairs serve as fine-grained probabilistic targets.
- This approach replaces binary labels with continuous values in the range of 0.0 to 1.0, providing a more stable signal for training the STOP module to recognize promising versus flawed reasoning paths.
Method
The authors leverage a path pruning framework to improve the efficiency of large language model (LLM) reasoning by selectively discarding unpromising reasoning trajectories early in the generation process. This approach contrasts with standard parallel reasoning, which generates and aggregates multiple full trajectories, incurring high computational cost. The core of the method is a pruning signal generator that evaluates the potential correctness of partial trajectories (prefixes) at a checkpoint and retains only the top-k candidates for completion. The framework is designed to maximize accuracy while minimizing token generation cost.
The proposed architecture integrates a lightweight, non-invasive module named STOP into the backbone LLM. This module operates as a Type IV pruning signal generator, leveraging internal model states for evaluation. The STOP module is composed of three learnable components: a specialized [STOP] token added to the vocabulary, a Critique Adapter LoRA (θLoRA) that activates upon processing the [STOP] token to extract error-specific features, and a Classification Head (Wcls) that maps the resulting hidden state to a scalar probability score. This design ensures modularity, allowing the original LLM parameters to remain frozen while enabling efficient parameter-efficient fine-tuning. The module is trained to distinguish promising prefixes from futile ones by minimizing a soft binary cross-entropy loss, where the soft labels are derived via Monte Carlo estimation of the final answer distribution.
The inference process is structured as a three-stage pipeline: Launch, Check, and Resume. As shown in the figure below, Stage 1 (Launch) involves generating short prefixes (e.g., 1024 tokens) for the input query and caching their key-value (KV) states. Stage 2 (Check) appends a sequence of [STOP] tokens to each cached prefix. The trained STOP module, which is composed of the LoRA adapter and classification head, reads the KV cache and outputs a quality score for each prefix. This step is computationally efficient as it only processes the few [STOP] tokens and reuses the heavy computation from Stage 1. Stage 3 (Resume) ranks the prefixes by their scores, applies a Top-k filter to retain only the most promising candidates, and resumes generation to completion for the selected prefixes. The final prediction is derived from the aggregated results of the pruned subset.
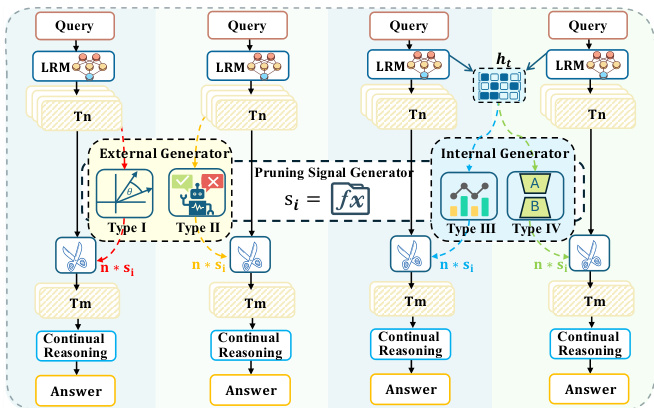
The effectiveness of the pruning signal generator is enhanced by its access to rich internal representations, which provide a more accurate assessment of a prefix's potential than external evaluation methods that rely solely on the generated text. This internal access allows the model to detect subtle signals of uncertainty and logical inconsistency that are lost during decoding, enabling more reliable path pruning. The framework is designed for practical deployment, with a focus on minimizing the one-time computational cost of training by providing a pre-constructed dataset and trained checkpoints. Furthermore, the authors derive a scaling law to determine the optimal retention ratio for various configurations, enabling efficient and accurate deployment without exhaustive hyperparameter search.
Experiment
The researchers evaluated four types of pruning signal generators across various reasoning benchmarks and model scales to determine their effectiveness and scalability. Their findings reveal that internal-based, learnable generators—specifically the proposed STOP method—consistently outperform external-based methods by providing a superior accuracy-efficiency trade-off. Ablation studies and attention analyses demonstrate that STOP's success stems from its ability to use low-variance soft labels and its process-oriented approach, which prioritizes logical pivots over premature answer fixation.
The authors compare different pruning methods in a tool-augmented reasoning setting, showing that the STOP method achieves the highest score. The results indicate that reducing the number of initial paths while using the STOP method improves performance compared to the baseline with tools. STOP method outperforms baseline with tools in tool-augmented reasoning. Reducing initial paths from 24 to 8 improves performance with the STOP method. The highest score is achieved by the STOP method with 16 initial paths reduced to 8.
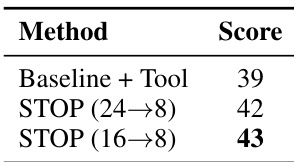
The the the table presents optimal retention ratios for different compute budgets and prefix lengths, showing how the optimal ratio changes with increasing computational resources and context length. The values increase with both higher compute budgets and longer prefix lengths, indicating that more aggressive pruning becomes feasible as more resources and context are available. Optimal retention ratios increase with higher compute budgets and longer prefix lengths. Higher compute budgets allow for more aggressive pruning strategies. Longer prefix lengths enable higher retention ratios, suggesting richer context for decision-making.
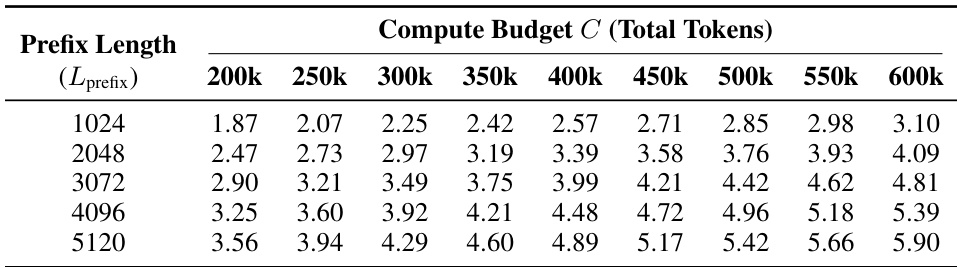
The authors compare the performance of different models on math and science benchmarks, showing that smaller models generally achieve higher scores on math tasks while larger models perform better on science tasks. The results demonstrate a trade-off between model size and task specialization. Smaller models show higher math scores compared to larger models. Larger models achieve better performance on science benchmarks. Performance varies significantly across models and task domains.
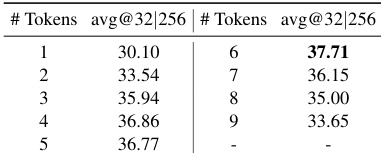
The the the table shows a relationship between the number of tokens and average accuracy, where performance peaks at a specific token count and then declines. This indicates an optimal point for token usage in the task. Accuracy peaks at 6 tokens and then decreases with further increases There is an optimal token count for maximizing average accuracy Performance degrades beyond the optimal token count
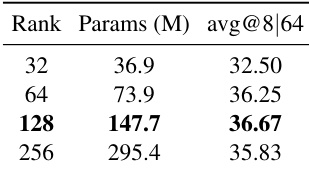
The authors compare different pruning methods based on model size and performance, showing that larger models generally achieve higher accuracy. The method with 128 million parameters achieves the highest average accuracy, indicating an optimal balance between size and effectiveness. Larger models tend to achieve higher average accuracy. The 128 million parameter model achieves the best performance. Model size and accuracy have a non-linear relationship.
These experiments evaluate various pruning methods, model scales, and resource allocations to optimize tool-augmented reasoning and task performance. The results demonstrate that the STOP method effectively enhances reasoning by reducing initial paths and that optimal retention ratios scale with increased compute budgets and context lengths. Furthermore, the findings reveal critical trade-offs regarding model specialization across math and science domains, as well as non-linear relationships between model size, token counts, and overall accuracy.