Command Palette
Search for a command to run...
HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
HY-World 2.0: نموذج عالم متعدد الوسائط لإعادة بناء وتوليد ومحاكاة العوالم ثلاثية الأبعاد
HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds HY-World 2.0: نموذج عالم متعدد الوسائط لإعادة بناء وتوليد ومحاكاة العوالم ثلاثية الأبعاد
الملخص
نقدم لكم HY-World 2.0، وهو إطار عمل لنموذج عالمي متعدد الوسائط (multi-modal world model framework) يمثل تطويراً لمشروعنا السابق HY-World 1.0. يدعم HY-World 2.0 وسائط إدخال متنوعة، بما في ذلك text prompts، والصور أحادية المنظور (single-view images)، والصور متعددة المناظر (multi-view images)، ومقاطع الفيديو، ويقوم بإنتاج تمثيلات ثلاثية الأبعاد للعالم (3D world representations).من خلال مدخلات نصية أو صور أحادية المنظور، يقوم النموذج بعملية توليد العالم (world generation)، حيث يقوم بتخليق مشاهد 3D Gaussian Splatting (3DGS) عالية الدقة وقابلة للتنقل (navigable). ويتم تحقيق ذلك من خلال منهجية مكونة من أربع مراحل:أ) توليد الصور البانورامية باستخدام HY-Pano 2.0.ب) تخطيط المسار (Trajectory Planning) باستخدام WorldNav.ج) توسيع العالم (World Expansion) باستخدام WorldStereo 2.0.د) تكوين العالم (World Composition) باستخدام WorldMirror 2.0.وعلى وجه التحديد، قدمنا ابتكارات جوهرية لتعزيز دقة الصور البانورامية، وتمكين فهم المشاهد ثلاثية الأبعاد والتخطيط لها، بالإضافة إلى ترقية WorldStereo، وهو نموذجنا لتوليد المناظر القائم على الإطارات الرئيسية (keyframe-based) مع ذاكرة متسقة (consistent memory). كما قمنا بترقية WorldMirror، وهو نموذج feed-forward للتنبؤ ثلاثي الأبعاد الشامل، عبر تحسين بنية النموذج واستراتيجية التعلم، مما يتيح إعادة بناء العالم (world reconstruction) من الصور متعددة المناظر أو مقاطع الفيديو.علاوة على ذلك، قدمنا WorldLens، وهي منصة رندر (rendering platform) عالية الأداء بتقنية 3DGS، تتميز ببنية مرنة غير مرتبطة بمحرك معين (engine-agnostic architecture)، وإضاءة IBL تلقائية، وكشف فعال للتصادم (collision detection)، وتصميم مشترك لعمليات الـ training والـ rendering، مما يسمح بالاستكشاف التفاعلي للعوالم ثلاثية الأبعاد مع دعم الشخصيات.تُظهر التجارب المكثفة أن HY-World 2.0 يحقق أداءً رائدًا (state-of-the-art) في العديد من الـ benchmarks مقارنة بالأساليب مفتوحة المصدر، ويقدم نتائج تضاهي النموذج مغلق المصدر Marble. ونحن نقوم بإصدار جميع أوزان النماذج (model weights)، والكود، والتفاصيل التقنية لتسهيل عملية إعادة الإنتاج (reproducibility) ودعم المزيد من الأبحاث حول نماذج العوالم ثلاثية الأبعاد.
One-sentence Summary
Tencent Hunyuan introduces HY-World 2.0, a multi-modal world model framework that reconstructs and generates navigable 3D Gaussian Splatting scenes from text, single-view images, multi-view images, or videos through a four-stage method involving HY-Pano 2.0, WorldNav, WorldStereo 2.0, and WorldMirror 2.0, while utilizing the WorldLens rendering platform for interactive 3D simulation.
Key Contributions
- The paper introduces HY-World 2.0, a multi-modal framework that transforms diverse inputs like text, single-view images, and videos into navigable 3D Gaussian Splatting scenes through a four-stage pipeline of panorama generation, trajectory planning, world expansion, and world composition.
- The framework incorporates several specialized components, including HY-Pano 2.0 for high-fidelity panorama synthesis, WorldNav for semantic-aware trajectory planning, WorldStereo 2.0 for memory-driven view generation, and WorldMirror 2.0 for universal 3D reconstruction.
- The researchers developed WorldLens, a high-performance 3DGS rendering platform featuring an engine-agnostic architecture and automatic lighting to enable interactive 3D world exploration with character support.
Introduction
3D world models are essential for advancing spatial intelligence in robotics, virtual reality, and game development by enabling agents to simulate and interact with complex environments. However, current research is often split between generative models that create immersive scenes from sparse inputs but lack geometric accuracy, and reconstruction methods that recover precise structures from dense data but cannot hallucinate unseen regions. The authors leverage a unified multi-modal framework called HY-World 2.0 to bridge this gap, providing a single system capable of both high-fidelity world generation from text or single images and accurate world reconstruction from multi-view videos. Their contribution includes a novel four-stage pipeline consisting of panorama generation, trajectory planning, memory-driven world expansion, and world composition to produce navigable 3D Gaussian Splatting scenes.
Dataset
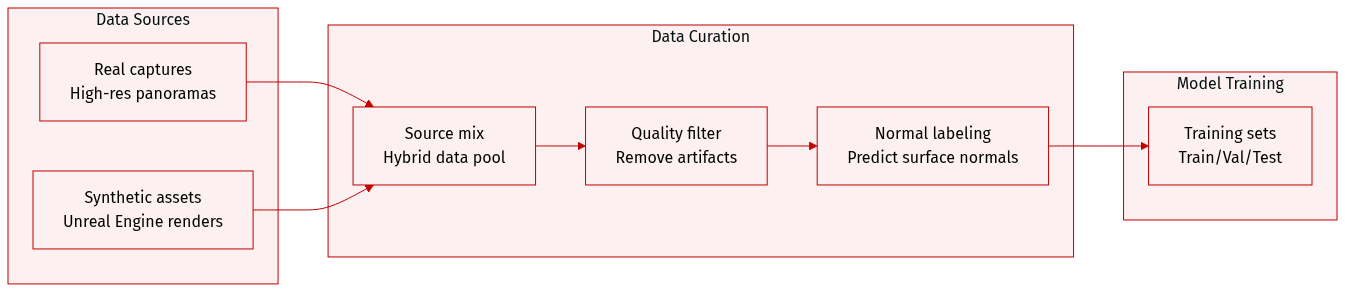
The authors construct a large-scale hybrid dataset for HY-World 2.0 by scaling up the original HY-World 1.0 framework. The dataset composition and processing details are as follows:
- Dataset Composition and Sources: The dataset integrates two primary sources to enhance semantic diversity and bridge the domain gap between real and synthetic environments.
- Real-world captures: A massive collection of high-resolution panoramas used to provide authentic lighting, complex textures, and natural structural priors.
- Synthetic assets: Large-scale environments rendered via high-end engines like Unreal Engine (UE) to provide diverse scene configurations and pixel-accurate ground-truth geometry.
- Data Filtering and Quality Control: The authors implement a rigorous filtering stage to remove low-quality samples, specifically targeting images with visible stitching artifacts or exposed capturing equipment such as panoramic cameras.
- Pseudo-Label Enhancement Strategy: To improve real-world data, the authors utilize a normal-only pseudo-labeling approach rather than monocular depth estimation. Because independent depth predictions often cause multi-view geometric inconsistencies, the authors use a monocular normal estimation teacher model to predict dense surface normals.
- Training and Supervision: These predicted normals serve as pseudo-supervision targets in two ways. They are used directly for the normal head via an angular loss and indirectly for the depth head through a specialized depth-to-normal loss.
Method
The HY-World 2.0 framework operates as a four-stage pipeline, integrating multi-modal inputs into immersive, navigable 3D worlds. The process begins with Panorama Generation, where arbitrary text or image inputs are translated into a high-fidelity 360° world initialization. This stage leverages a Multi-Modal Diffusion Transformer (MMDiT) to perform an implicit, adaptive mapping from perspective inputs to equirectangular projection (ERP) space. The MMDiT processes both the conditional input and the target panoramic output within a unified latent space, concatenating their respective latent sequences. This self-attention mechanism enables the network to autonomously learn the underlying perspective-to-ERP transformation without requiring explicit camera priors, allowing it to hallucinate missing details and maintain global structural coherence. To address the discontinuity at the left and right edges of the ERP, a combined refinement strategy is employed. At the latent level, circular padding enforces periodic boundary conditions during the denoising process, while in the pixel space, a linear blending strategy smooths the 360^\\circ wrap-around transition, ensuring a perfectly seamless and structurally coherent panoramic output.

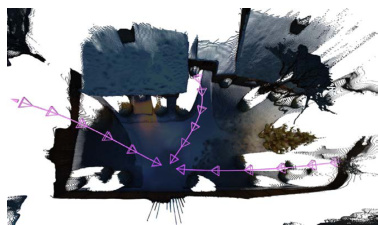
Following the generation of a high-fidelity panorama, the system proceeds to Trajectory Planning. This stage, implemented by the WorldNav strategy, aims to derive exploration trajectories that maximize navigable space coverage. The process begins with a comprehensive geometric and semantic scene parsing of the panorama. This involves constructing a global panoramic point cloud mathbfPpan by aligning monocular depth maps from subdivided perspective views using an optimized LSMR solver. A hybrid filtering strategy, combining vision-language grounding and depth discontinuity removal, is applied to enhance geometric quality. Concurrently, semantic parsing identifies key landmarks and obstacles, with their 3D centroids localized to create 3D masks. A Navigation Mesh (NavMesh) is also constructed using Recast Navigation to define traversable regions. This NavMesh is refined through geometric corrections, such as snapping vertices to the ground and eroding boundaries, to ensure physically plausible camera movement. Based on the parsed scene, WorldNav designs five heuristic trajectory modes: Regular, Surrounding, Reconstruct-Aware, Wandering, and Aerial. Regular trajectories provide a general orbital expansion from the origin. Surrounding trajectories circle significant objects at an adaptive radius to ensure foreground quality. Reconstruct-Aware trajectories are designed to target under-observed regions, identified by degenerate mesh faces, to mitigate gaps in the subsequent 3D reconstruction. Wandering trajectories simulate autonomous agent exploration to reach environmental boundaries, while Aerial trajectories are an auxiliary mode to eliminate blind viewpoints by applying an upward pitch to other trajectories.
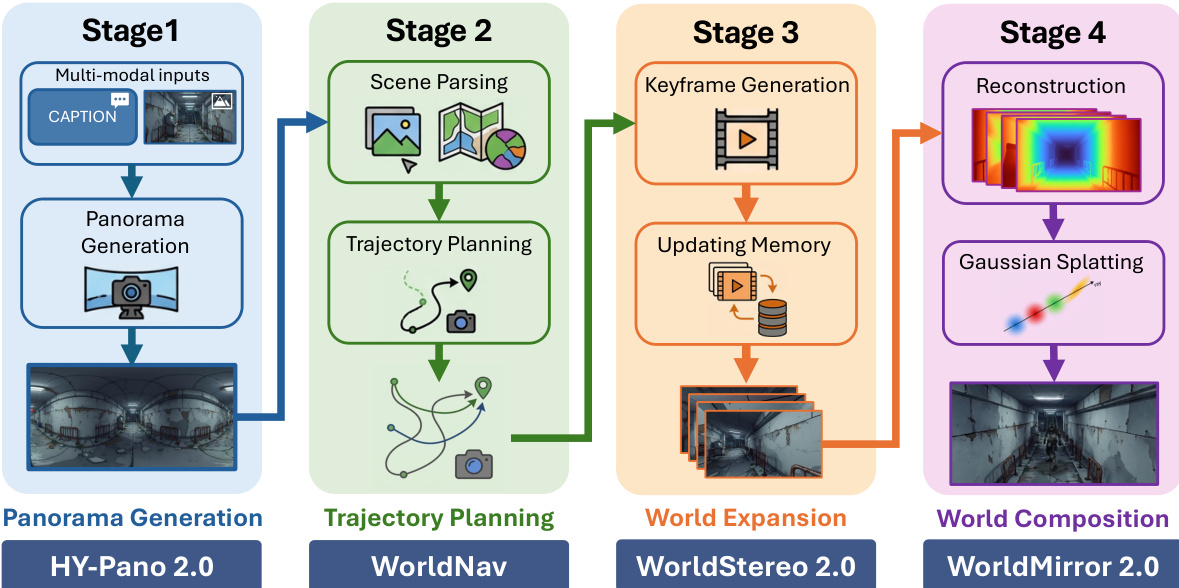
The third stage, World Expansion, is handled by WorldStereo 2.0, which synthesizes extensive novel views for world expansion. This stage is structured in three progressive training stages to enable camera control, memory-based consistency, and fast inference. The core of WorldStereo 2.0 is its keyframe latent space, which rethinks the limitations of standard Video-VAEs. Instead of spatio-temporal compression, it uses a Keyframe-VAE that applies spatial-only compression to each keyframe independently. This approach preserves high-frequency details and reduces artifacts caused by motion blur and geometric distortion, which are common in standard VAEs. Explicit camera control is achieved by integrating a lightweight transformer-based camera adapter with the pre-trained video DiT. This adapter uses both camera Plücker rays and point clouds as complementary guidance. The point cloud mathbfPref from the reference view is warped into each target view to obtain mathbfPitar, which is then rendered and encoded into latent features to guide the generation.
![Keyframe-VAE in WorldStereo 2.0 versus a standard Video-VAE [64]. Unlike (a) Video-VAE, which performs spatio-temporal compression, (b) Keyframe-VAE applies spatial-only compression to better preserve high-frequency details and reduce artifacts essentially caused by Video-VAE encoding (e.g., motion blur and geometric distortion).](https://api-rsrc.hyper.ai/paper2blog/991ed478-56a8-4c73-ae44-be1bc7697765/2604.14268/cache/tex_resource/monkeyocr/images/0205ffa4833062126c52ee183f527f4db88fec7397bd0289dd6a19e1a22f3c9c.jpg)
To ensure frame consistency across diverse trajectories, WorldStereo 2.0 incorporates two complementary memory modules. The Global-Geometric Memory (GGM) maintains globally consistent coarse scene structure. It is fine-tuned using videos rendered by extended global point clouds mathbfPglo, which include not only the reference points but also additional points sampled from novel views, thereby forcing the model to adhere more strictly to the 3D representations. The Spatial-Stereo Memory (SSM++) reinforces local correspondence and fine-grained details. It is advanced by directly integrating retrieved keyframes into the main DiT branch, modifying the Rotary Positional Embedding (RoPE) to accommodate this integration, and employing a selective retrieval strategy to reduce computational overhead. During mid-training, the model is trained with full self-attention, allowing it to learn global context. For inference, perspective views from the input panorama serve as the initial memory bank, which is incrementally updated with generated keyframes.
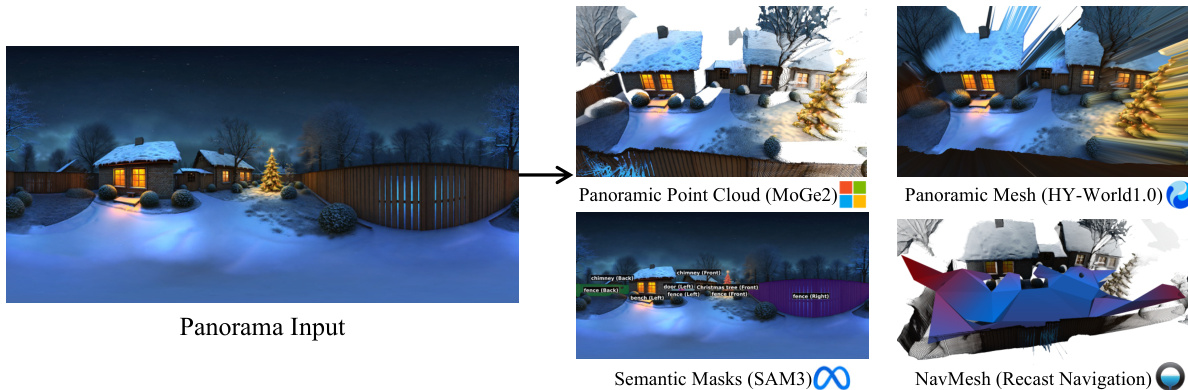
The final stage, World Composition, integrates the generated data into a unified 3D representation. This process starts with the reconstruction of globally aligned point clouds and depth maps using the upgraded WorldMirror 2.0 model. WorldMirror 2.0 is a unified feed-forward model that takes multi-view images and optional geometric priors as input and predicts various 3D attributes in a single forward pass. It introduces several key improvements over its predecessor: normalized position encoding for flexible resolution inference, explicit normal-based supervision for depth via a depth-to-normal loss, and a dedicated depth mask prediction head for robust handling of invalid pixels. The depth maps estimated by WorldMirror 2.0 are then aligned with the initial panoramic point cloud mathbfPpan to resolve scale ambiguity. This alignment is achieved through a RANSAC-based linear transformation, which is refined using an outlier detection and revision strategy based on the global distribution of alignment coefficients.
Finally, the expanded point cloud is used to initialize a 3D Gaussian Splatting (3DGS) model. The optimization process employs a dual strategy to resolve the dilemma between rendering efficiency and detail preservation. It applies a standard growth strategy exclusively to the non-sky portion of the point cloud to densify texture-rich regions, while integrating a MaskGaussian mechanism to dynamically prune redundant Gaussians in over-populated areas like the sky. This probabilistic masking, regularized by a squared loss, allows for implicit sparsity and effectively suppresses floating artifacts. The training objective combines photometric and geometric losses, with depth supervision applied sparsely to the aligned depth maps and dense normal supervision applied across all frames. The optimized 3DGS model can be further processed to extract a mesh for applications requiring collision detection or physics simulation.
Experiment
The evaluation assesses the HY-World 2.0 pipeline through component-wise analysis of panorama generation, trajectory planning, scene reconstruction, and 3DGS composition, alongside a standalone evaluation of the WorldMirror 2.0 reconstruction foundation. The results demonstrate that the system produces highly coherent, aesthetically pleasing, and geometrically consistent 3D worlds that strictly adhere to text or image inputs while outperforming commercial and state-of-the-art models. Furthermore, the framework exhibits robust multi-resolution generalization and efficient scaling through optimized inference techniques, enabling the creation of high-fidelity, interactive 3D environments.
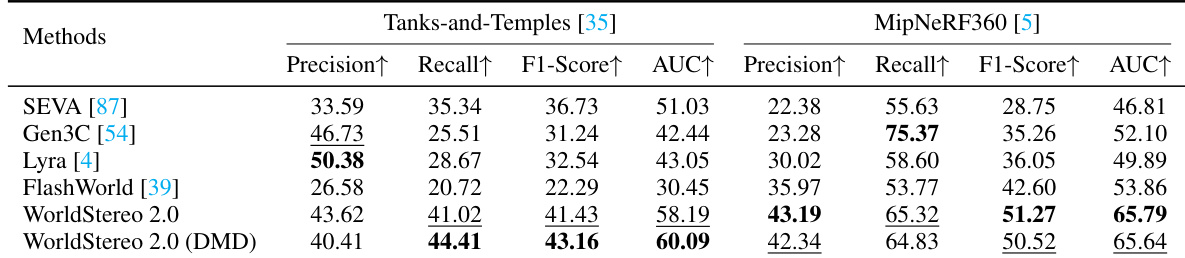
The the the table presents a comparison of single-view 3D reconstruction methods on two benchmarks, Tanks-and-Temples and MipNeRF360. Results show that the proposed WorldStereo 2.0 method achieves the highest performance across most metrics on both datasets, with particularly strong improvements in precision and F1-score. The method also demonstrates superior geometric consistency and physically plausible 3D structures compared to existing approaches. WorldStereo 2.0 achieves the best scores on most metrics for single-view 3D reconstruction It shows significant improvements in precision and F1-score over prior methods The results confirm the ability to synthesize highly consistent and plausible 3D structures
The the the table presents an ablation study on trajectory planning components, showing the maximum number of views generated by each trajectory type and whether they are attached to objects or iterative. Regular and surrounding trajectories generate the highest numbers, with surrounding views being attached to objects and iterative. Aerial and wandering trajectories generate fewer views, with none attached to objects or iterative. Regular and surrounding trajectories generate the most views, with surrounding views attached to objects. Aerial and wandering trajectories generate fewer views and are not attached to objects or iterative. Surrounding and recon-aware trajectories are iterative, while regular and wandering are not.

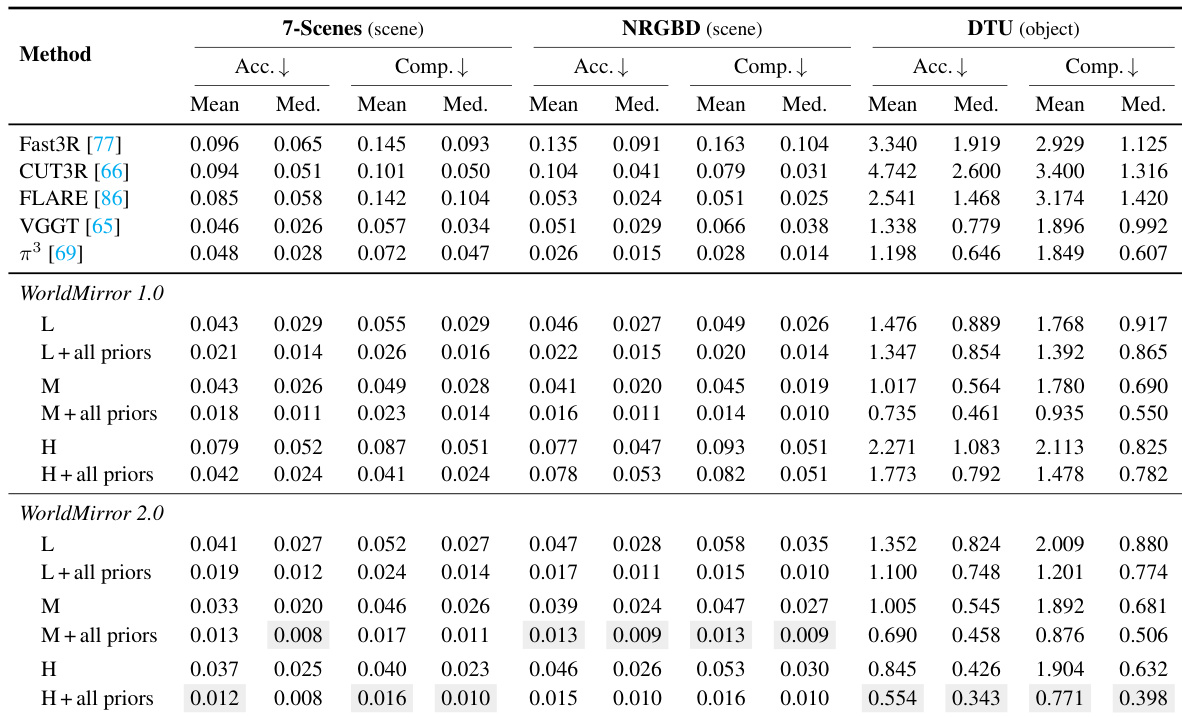
The the the table compares the performance of WorldMirror 1.0 and WorldMirror 2.0 across different datasets and resolutions. Results show that WorldMirror 2.0 consistently outperforms WorldMirror 1.0, particularly at higher resolutions, and benefits from the integration of geometric priors. The improvements are most pronounced in the 7-Scenes dataset. WorldMirror 2.0 achieves better performance than WorldMirror 1.0 across all datasets and resolutions. The integration of geometric priors significantly improves results for both versions, with the largest gains seen in WorldMirror 2.0. WorldMirror 2.0 maintains stable performance at high resolutions, while WorldMirror 1.0 degrades significantly.
The the the table presents a detailed runtime analysis of the HY-World 2.0 pipeline, showing the time taken for each major stage. The results indicate that world expansion is the most time-consuming component, followed by trajectory planning, while panorama generation is the fastest step. The total runtime for the complete pipeline is summarized, providing insight into the computational efficiency of the system. World expansion is the most time-consuming stage in the pipeline. Trajectory planning takes significantly longer than panorama generation. The total runtime for the full world generation process is 712 seconds.
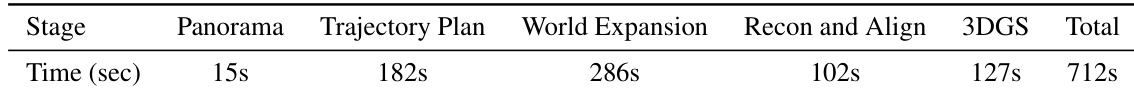
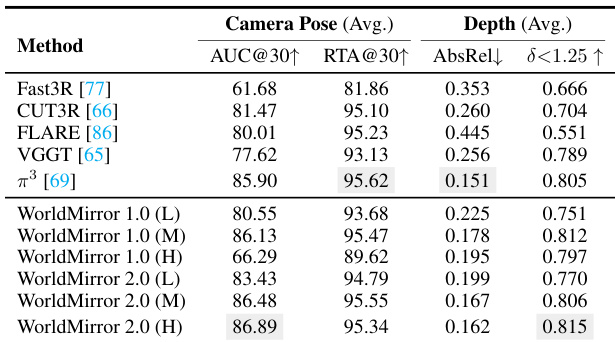
The the the table compares camera pose estimation performance across different methods and resolutions. WorldMirror 2.0 achieves the highest AUC@30 score at high resolution, demonstrating improved accuracy over previous versions and other methods. It also shows consistent improvements in RTA@30 and depth metrics across resolutions. WorldMirror 2.0 achieves the highest AUC@30 score at high resolution WorldMirror 2.0 maintains superior performance across all metrics compared to WorldMirror 1.0 WorldMirror 2.0 shows consistent improvements in RTA@30 and depth metrics across resolutions
The evaluation compares WorldStereo 2.0 and WorldMirror 2.0 against existing methods and previous versions through benchmarks on 3D reconstruction, trajectory planning, point map reconstruction, camera pose estimation, and pipeline runtime. The results demonstrate that WorldStereo 2.0 produces more geometrically consistent and physically plausible 3D structures, while WorldMirror 2.0 benefits significantly from geometric priors to maintain stable performance at high resolutions. Additionally, the ablation study identifies the most effective trajectory types for view generation, and the runtime analysis highlights world expansion as the primary computational bottleneck in the pipeline.