Command Palette
Search for a command to run...
AgentSPEX: لغة مواصفات وتنفيذ الـ agent
AgentSPEX: لغة مواصفات وتنفيذ الـ agent
Pengcheng Wang Jerry Huang Jiarui Yao Rui Pan Peizhi Niu Yaowenqi Liu Ruida Wang Renhao Lu Yuwei Guo Tong Zhang
الملخص
تعتمد أنظمة language-model agent بشكل شائع على "التلقين التفاعلي" (reactive prompting)، حيث توجه تعليمات مفردة النموذج عبر تسلسل مفتوح من خطوات الاستدلال واستخدام الأدوات، مما يترك تدفق التحكم والحالة الوسيطة (intermediate state) ضمنية، ويجعل سلوك الـ agent صعب التحكم فيه احتماليًا. توفر أطر العمل التنظيمية (Orchestration frameworks) مثل LangGraph وDSPy وCrewAI هيكلية أكبر من خلال تعريفات صريحة لسير العمل، إلا أنها تربط منطق سير العمل بشكل وثيق بلغة Python، مما يجعل صيانة الـ agents وتعديلها أمرًا صعبًا.في هذه الورقة البحثية، نقدم AgentSPEX، وهي لغة لتوصيف وتنفيذ الـ agent (Agent SPecification and EXecution Language) تهدف إلى تحديد سير عمل LLM-agent مع تدفق تحكم صريح وبنية نموذجية (modular structure)، بالإضافة إلى منصة تشغيل (agent harness) قابلة للتخصيص. يدعم AgentSPEX الخطوات المحددة النوع (typed steps)، والتفرع (branching)، والحلقات التكرارية (loops)، والتنفيذ المتوازي، والوحدات الفرعية القابلة لإعادة الاستخدام، والإدارة الصريحة للحالة. وتُنفذ هذه المسارات ضمن منصة تشغيل توفر الوصول إلى الأدوات، وبيئة افتراضية معزولة (sandboxed virtual environment)، ودعمًا لعمليات نقاط التحقق (checkpointing)، والتحقق (verification)، وتسجيل الأحداث (logging).علاوة على ذلك، نوفر محررًا مرئيًا مع عرض متزامن للرسم البياني (graph) وسير العمل (workflow) لأغراض التأليف والفحص. كما قمنا بتضمين agents جاهزة للاستخدام في الأبحاث العميقة والبحث العلمي، وقمنا بتقييم AgentSPEX بناءً على 7 معايير مرجعية (benchmarks). وأخيرًا، نوضح من خلال دراسة مستخدمين أن AgentSPEX يوفر نموذجًا لتأليف سير العمل أكثر قابلية للتفسير والوصول مقارنة بأحد أطر عمل الـ agent الشائعة حاليًا.
One-sentence Summary
To address the limitations of reactive prompting and tightly coupled Python orchestration frameworks, the paper introduce AgentSPEX, an agent specification and execution language that enables controllable and maintainable LLM-agent workflows through explicit control flow, modular structures, and a customizable harness featuring typed steps, state management, and a sandboxed environment, which the paper evaluate across seven benchmarks using ready-to-use agents for deep and scientific research.
Key Contributions
- The paper introduces AgentSPEX, an agent specification and execution language that uses declarative YAML files to define LLM-agent workflows with explicit control flow, branching, loops, and modular submodules.
- A customizable agent harness is provided to execute these workflows, offering a sandboxed virtual environment, tool access, and advanced capabilities such as state checkpointing, trajectory logging, and replay functionality.
- The work includes a bidirectional visual editor for drag-and-drop workflow construction and demonstrates the framework's utility through ready-to-use research agents and evaluations across seven benchmarks in science, writing, and software engineering.
Introduction
Modern language model agent systems often rely on reactive prompting, where a single instruction guides an open ended sequence of reasoning. While simple, this approach lacks precise control over intermediate states and can struggle with long horizon tasks. Existing orchestration frameworks attempt to provide structure but typically couple workflow logic tightly with Python code, which creates steep learning curves and makes agents difficult to maintain or share with non-programmers. The authors leverage a new approach called AgentSPEX, an agent specification and execution language that uses declarative YAML syntax to define workflows. This contribution provides explicit control over branching, loops, and state management while offering a customizable execution harness and a visual editor to make agent authoring more accessible and interpretable.
Dataset
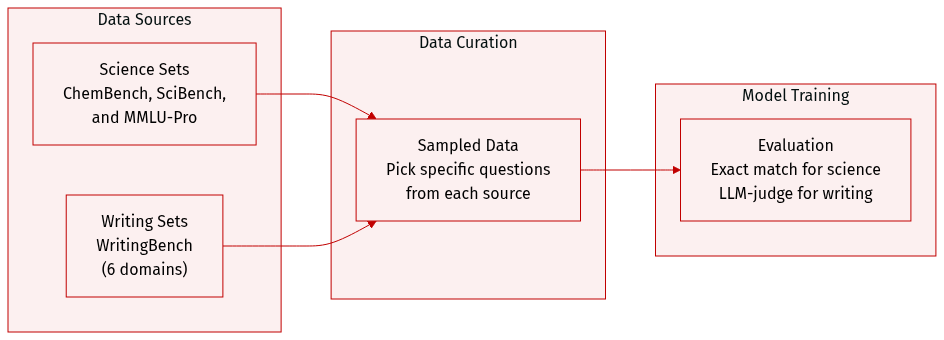
The authors utilize several specialized datasets to evaluate scientific reasoning and generative writing capabilities:
- Science Datasets:
- ChemBench: A subset of 90 question-answer pairs is created by randomly sampling 10 questions from each of the 9 domains within the original framework.
- SciBench: The authors use a collection of 213 collegiate-level chemistry problems sourced from four specific textbooks: Atkins' Physical Chemistry (101 problems), Chemistry by McMurry & Fay (33 problems), Properties of Matter (47 problems), and Quantum Chemistry (32 problems).
- MMLU-Pro Stemez: The Physical Chemistry subset is used, consisting of 216 problems sourced from the Stemez website.
- Generative Writing Dataset:
- WritingBench: To evaluate writing, the authors construct a 120-question subset by randomly sampling 20 questions from each of the 6 major domains.
- Evaluation and Processing:
- For the science benchmarks, the authors employ exact match evaluation against reference solutions.
- For the writing benchmark, the authors follow an LLM-as-Judge protocol where a critic model assesses responses based on 5 instance-specific criteria using a 10-point scale.
Method
The core architecture of AgentSPEX is structured around a declarative workflow specification language and an agent harness that executes these workflows in a controlled, observable, and durable environment. The system begins with a YAML-based workflow definition that specifies an agent's name, goal, configuration, and a sequence of operations. This workflow defines a structured execution plan using primitives such as task and step, which determine how the agent interacts with tools and maintains conversation history. A task initiates a fresh interaction with no prior context, while a step allows for multi-turn reasoning by preserving conversation history across multiple interactions. These operations are supported by control flow constructs, including if, while, for_each, and call, enabling complex logic and modular composition. The call construct allows workflows to invoke other workflows as reusable submodules, promoting modularity and code reuse. The framework supports state management through context variables that are passed between steps using Mustache-style templates, such as {{variable}}, and can be saved using the save_as directive. This enables the seamless flow of intermediate results across the workflow.

The workflow definition is designed to be human-readable and editable, allowing domain experts to author and modify workflows without requiring programming expertise. Workflows are self-contained YAML files, facilitating version control and collaboration. To assist in workflow development, AgentSPEX provides a visual editor that renders workflows as interactive flowcharts, where each node corresponds to an operation. Users can modify the workflow graphically or directly in the synchronized YAML editor, with changes immediately reflected in both views. This visual interface supports rapid prototyping and debugging, enhancing the development experience. The visual editor is demonstrated in Figure 3, which illustrates a deep research agent workflow with reusable submodules.
The execution of these workflows is managed by an agent harness that orchestrates the entire process. The harness includes an interpreter that validates the workflow structure, resolves configuration parameters, and expands template variables. It then dispatches each operation to the appropriate handler, managing recursion for nested constructs such as loops and conditionals. Each operation is assigned a hierarchical step identifier for tracking and checkpointing. The executor implements the interaction loop between the language model and external tools, managing multi-turn conversations until the model returns a response with no further tool calls or reaches a configured limit. Execution occurs within a Docker-based sandbox environment, providing isolation and access to a comprehensive suite of tools, including web search, file operations, and browser automation. This sandbox is equipped with a browser, file system access, and a Model Context Protocol (MCP) client for tool execution.
The agent harness also features a robust observability dashboard that provides real-time monitoring and debugging capabilities. This dashboard logs agent actions and intermediate reasoning steps, allowing developers to inspect behavior at each stage of execution. For long-running workflows, the system ensures durability through checkpointing and execution tracing. Checkpoints are saved after each step, capturing the current context, variables, and sandbox state, enabling the workflow to resume from any point in case of interruption. Execution tracing records a full history of model responses, tool calls, and conversation states. The system supports selective trace replay, allowing developers to isolate the impact of changes to specific steps without re-executing the entire workflow. Furthermore, the declarative nature of AgentSPEX enables formal verification of workflows. By making control flow, variable dependencies, and step boundaries explicit in the YAML specification, the framework supports static and runtime verification of both structural and semantic correctness. This is demonstrated through the verification of the extract_single_citation_module, where pre- and post-conditions for each step are defined and verified using formal methods. The verification process checks that variables satisfy expected properties at each node, ensuring the workflow executes correctly and reliably. This capability provides a pathway for regulating agentic behavior and ensuring the reliability of complex autonomous systems.
Experiment
AgentSPEX was evaluated across seven diverse benchmarks in domains such as science, mathematics, writing, and software engineering to compare its performance against chain-of-thought and ReAct baselines. The results demonstrate that AgentSPEX consistently outperforms existing frameworks, particularly on tasks requiring complex reasoning or the processing of extensive documents where enforced step-by-step execution and explicit context management are beneficial. Additionally, a user study revealed that while developers find AgentSPEX more readable and accessible for creating new workflows, they perceive existing tools like LangGraph as more suitable for highly complex constructions.
The authors evaluate AgentSPEX on a benchmark comparing its performance against other agent frameworks across different models. Results show that AgentSPEX maintains consistent performance across model versions, with minimal degradation when upgrading from one model to another, while other frameworks exhibit more significant drops in performance. AgentSPEX shows minimal performance drop across model versions compared to other frameworks. AgentSPEX maintains stable results when switching between model versions. Other frameworks exhibit larger performance declines when transitioning between model versions.
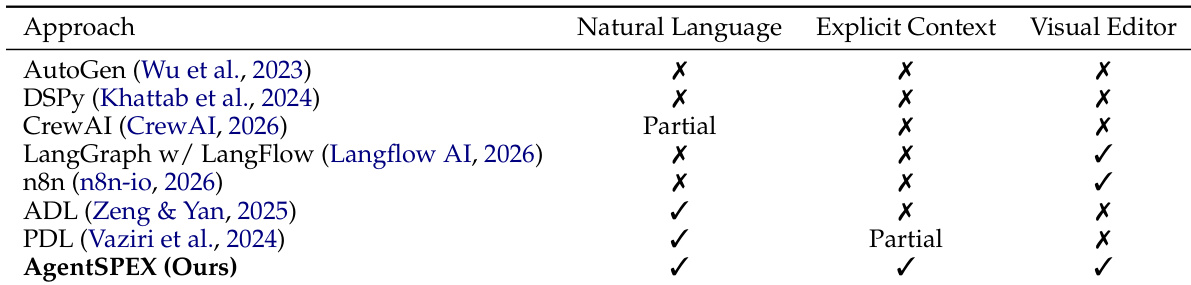
The authors compare AgentSPEX with several existing agent frameworks across three key capabilities: natural language specification, explicit context management, and visual editing. Results show that AgentSPEX supports natural language and explicit context, while also offering a visual editor, positioning it as a comprehensive framework. Other frameworks either lack one or more of these features or only partially support them. AgentSPEX supports natural language specification, explicit context management, and a visual editor, unlike most other frameworks. Several frameworks, including LangGraph and n8n, support a visual editor but lack full support for natural language or explicit context. AgentSPEX is positioned as a more comprehensive framework by combining all three capabilities, while others offer partial or limited support.
The authors evaluate AgentSPEX across multiple benchmarks in science, mathematics, writing, paper understanding, and software engineering, comparing it against baselines such as CoT and ReAct. Results show that AgentSPEX consistently outperforms the baselines across all domains, with notable improvements on tasks requiring extended reasoning or complex input processing. The framework also demonstrates strong performance on software engineering benchmarks, achieving competitive results against specialized agents. A user study indicates that participants find AgentSPEX more interpretable and easier to use, especially for non-coders, though they perceive LangGraph as more suitable for complex workflows. AgentSPEX achieves the highest performance across all evaluated benchmarks compared to CoT and ReAct baselines. The framework shows significant improvements on tasks involving extensive input or multi-step reasoning, such as paper understanding and chemistry problems. Users rate AgentSPEX as more interpretable and accessible, particularly for those without coding expertise.
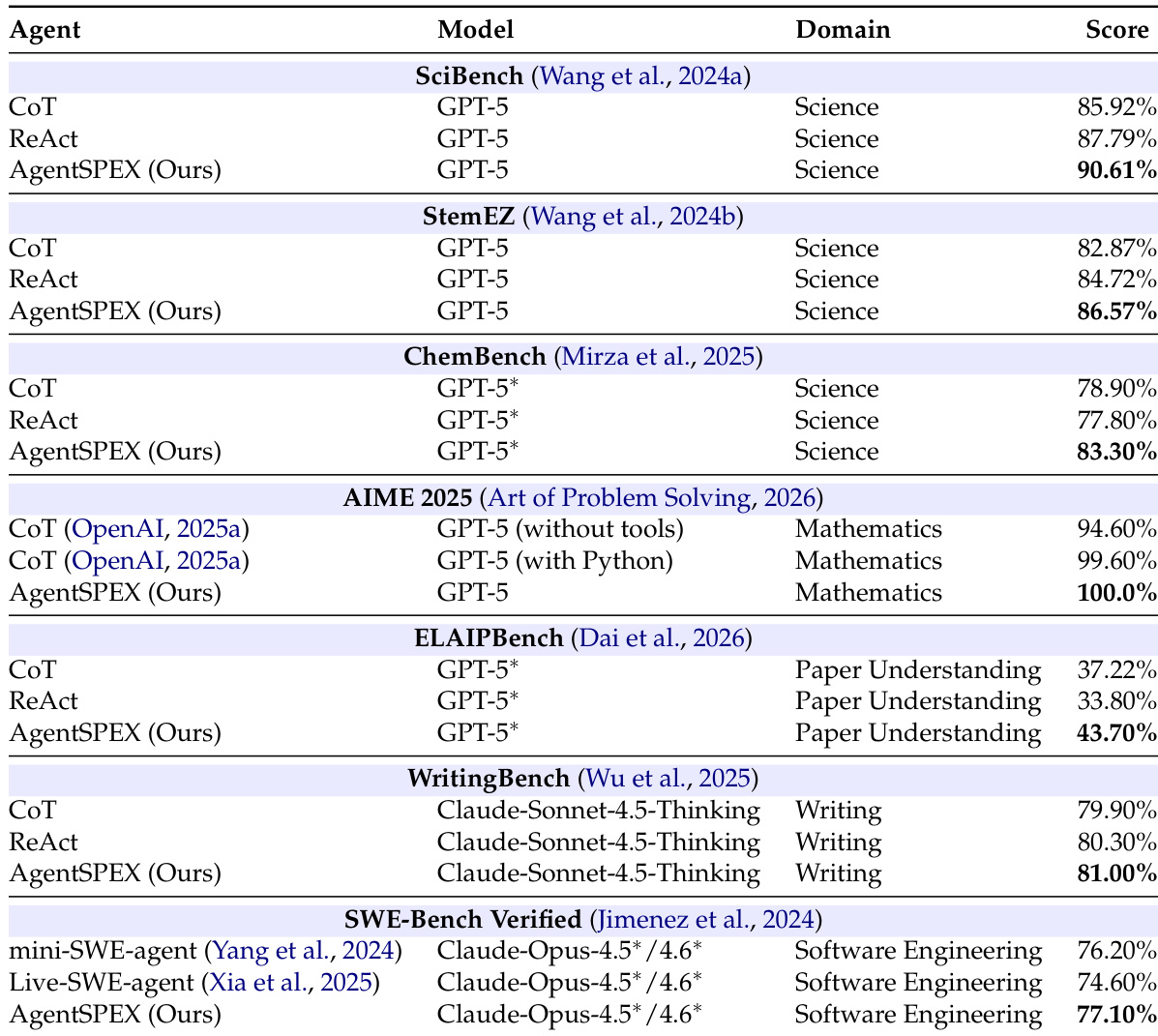
The authors evaluate AgentSPEX across seven benchmarks spanning science, mathematics, writing, paper understanding, and software engineering domains, comparing it against baselines such as chain-of-thought and ReAct. Results show that AgentSPEX outperforms all compared approaches on every benchmark, with particularly strong improvements on tasks requiring extended reasoning or complex input processing. AgentSPEX achieves the highest performance on all seven evaluated benchmarks across diverse domains. The framework shows significant improvements over baselines on benchmarks involving long-form reasoning and multi-step problem-solving. AgentSPEX outperforms both chain-of-thought and ReAct baselines, with larger gains observed on tasks requiring extensive context management.

The authors evaluate AgentSPEX through benchmark comparisons against existing frameworks and reasoning baselines, alongside a user study to assess usability. The results demonstrate that AgentSPEX offers superior stability across different model versions and provides a more comprehensive feature set by integrating natural language specification, explicit context management, and visual editing. Furthermore, the framework consistently outperforms standard reasoning approaches across diverse domains, particularly in tasks requiring complex, multi-step reasoning, while remaining highly interpretable and accessible to non-coders.