Command Palette
Search for a command to run...
اختبار تورينج على الشاشة: Benchmark لتقييم مدى Humanization لـ Mobile GUI Agent
اختبار تورينج على الشاشة: Benchmark لتقييم مدى Humanization لـ Mobile GUI Agent
Jiachen Zhu Lingyu Yang Rong Shan Congmin Zheng Zeyu Zheng Weiwen Liu Yong Yu Weinan Zhang Jianghao Lin
الملخص
لقد أدى صعود الـ autonomous GUI agents إلى تحفيز إجراءات مضادة من قبل المنصات الرقمية، ومع ذلك، تركز الأبحاث الحالية على المنفعة (utility) والمتانة (robustness) وتغفل البعد الحاسم المتمثل في مكافحة الكشف (anti-detection). نحن نجادل بأنه لكي تتمكن هذه الـ agents من البقاء في الأنظمة البيئية المتمحورة حول الإنسان، يجب عليها تطوير قدرات "الأنسنة" (Humanization).نقدم في هذا البحث مفهوم "اختبار تورينج على الشاشة" (Turing Test on Screen)، حيث قمنا بصياغة التفاعل كمسألة تحسين MinMax بين أداة كشف (detector) وagent يهدف إلى تقليل التباعد السلوكي (behavioral divergence) إلى الحد الأدنى. بعد ذلك، قمنا بجمع مجموعة بيانات جديدة عالية الدقة (high-fidelity) لديناميكيات اللمس على الهاتف المحمول، وأجرينا تحليلاً أظهر أن الـ agents القائمة على vanilla LMM يمكن كشفها بسهولة بسبب الحركية (kinematics) غير الطبيعية.وبناءً على ذلك، قمنا بإنشاء معيار "Agent Humanization Benchmark (AHB)" ومقاييس كشف لتحديد المقايضة (trade-off) بين القدرة على المحاكاة (imitability) والمنفعة (utility). وأخيراً، اقترحنا طرقاً تتراوح من إضافة الضجيج الاستدلالي (heuristic noise) إلى المطابقة السلوكية القائمة على البيانات (data-driven behavioral matching)، مما يثبت أن الـ agents يمكنها تحقيق قدرة عالية على المحاكاة، نظرياً وتجريبياً، دون التضحية بالأداء.ينقل هذا العمل النموذج الفكري من مجرد التساؤل عما إذا كان الـ agent قادراً على أداء مهمة ما، إلى كيفية أدائه لها ضمن نظام بيئي متمحور حول الإنسان، مما يضع حجر الأساس للتعايش السلس في البيئات الرقمية العدائية.
One-sentence Summary
To enhance anti-detection capabilities, the authors introduce the Turing Test on Screen, which models mobile GUI agent interaction as a MinMax optimization problem and utilizes the Agent Humanization Benchmark and high-fidelity touch datasets to demonstrate that data-driven behavioral matching improves agent imitability without sacrificing task utility.
Key Contributions
- The paper introduces the Turing Test on Screen, a formal framework that models the interaction between a detector and an agent as a MinMax optimization problem focused on minimizing behavioral divergence.
- A new high-fidelity dataset of mobile touch dynamics is presented alongside the Agent Humanization Benchmark (AHB), which provides detection metrics to quantify the trade-off between agent utility and human-like imitability.
- The authors develop humanization methods ranging from heuristic noise to data-driven behavioral matching, demonstrating that agents can achieve high levels of imitability without sacrificing task performance.
Introduction
As autonomous Graphical User Interface (GUI) agents powered by Large Multimodal Models (LMMs) become more prevalent, they face an increasing conflict with digital platforms that rely on human engagement for revenue. While existing research focuses on improving task utility and robustness against environmental perturbations, it largely overlooks the "Detect vs. Anti-Detect" paradigm. This gap is critical because platforms often deploy behavioral biometrics to filter non-human traffic, and current agents are easily identified by their unnatural, mechanical touch kinematics and rigid temporal rhythms.
The authors leverage this challenge to introduce the "Turing Test on Screen," a framework that models agent-platform interaction as a MinMax optimization problem between a detector and an agent. They contribute a high-fidelity dataset of mobile touch and sensor dynamics, establish the Agent Humanization Benchmark (AHB) to quantify the trade-off between imitability and task utility, and propose various humanization strategies—ranging from heuristic noise to data-driven matching—to help agents achieve human-like behavioral nuances.
Dataset
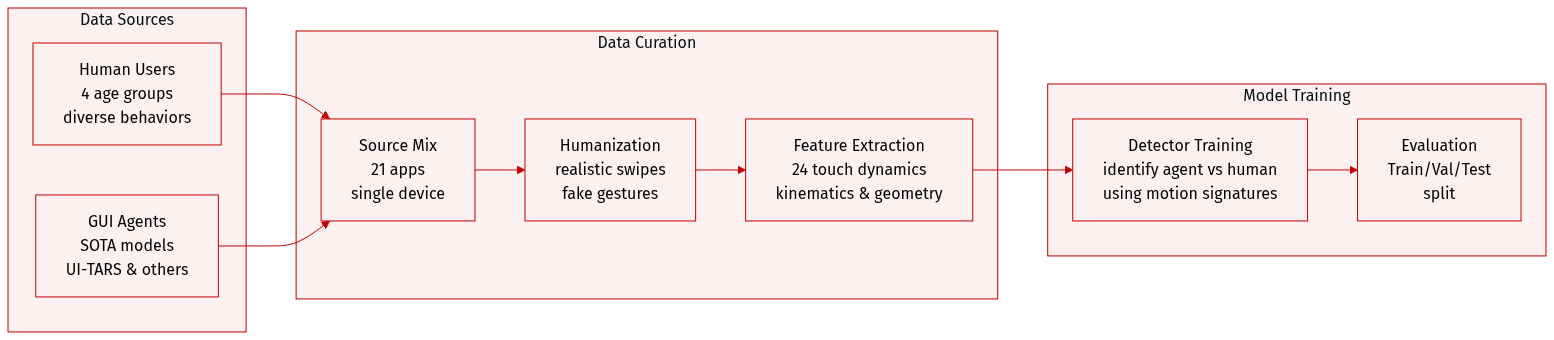
-
Dataset Composition and Sources: The authors constructed a large-scale, multi-modal dataset capturing interactions across 21 diverse applications organized into five functional clusters, such as Social Media and Shopping. The data is sourced from two primary distributions:
- Human Operators: Four distinct sub-populations (Young Man, Young Woman, Middle-aged, and Elderly) to capture physiological and age-related behavioral variances.
- GUI Agents: Action sequences from state-of-the-art models, including UI-TARS, MobileAgent-E (using both GPT-4o and Claude-3.5-Sonnet), AgentCPM, and AutoGLM.
-
Data Processing and Humanization: All data was collected on a single device (Xiaomi Mi Max 2) to ensure consistency. The authors applied humanization techniques to agents in real time rather than post hoc:
- Without fake actions: Tap durations are elongated and swipes are rendered via data-driven trajectory matching.
- With fake actions: Agents undergo tap elongation and swipe humanization, augmented by small circular gestures (50 px radius) emitted from the last tap location following a Poisson process.
- Action Classification: Actions are categorized as taps if they contain fewer than 5 FingerEvents and as swipes if they contain 5 or more.
-
Feature Construction and Metadata: To differentiate between humans and agents, the authors derived 24 statistical features based on touch dynamics, including kinematics (velocity, acceleration), geometry (path efficiency, curvature), and temporal dynamics (duration, latency). The dataset also includes various sensor streams such as the accelerometer, gyroscope, magnetic field, and light sensors, though the primary focus remains on MotionEvents.
-
Model Usage: The authors use the dataset to evaluate the discriminative power of a detector. They utilize the collected motion and sensor events to study the behavioral signatures that distinguish authentic human users from autonomous agents.
Method
The framework for the Agent Humanization Benchmark (AHB) is structured as a Min-Max adversarial game between a Detector DΘ and a GUI Agent GΦ, designed to evaluate the ability of an agent to mimic human-like interaction patterns while maintaining task utility. This adversarial setup is grounded in a hierarchical interaction model, where the agent's actions are decomposed into two levels: the logical action level and the physical event level. At the logical level, the agent generates high-level UI commands—such as taps or swipes—based on the current environmental state st, following the transition dynamics st+1=T(st,at), where at=GΦ(st) is the agent's output. These commands are then translated into fine-grained physical events Et through a mapping function f, resulting in a sequence of motion and sensor events. The motion events capture touch dynamics (coordinates, pressure), while sensor events include data from the gyroscope, magnetometer, and other hardware, collectively forming the behavioral trace E1:T=⋃t=1TEt. This trace serves as the input for the detector, which aims to classify the sequence as human or agent-generated.
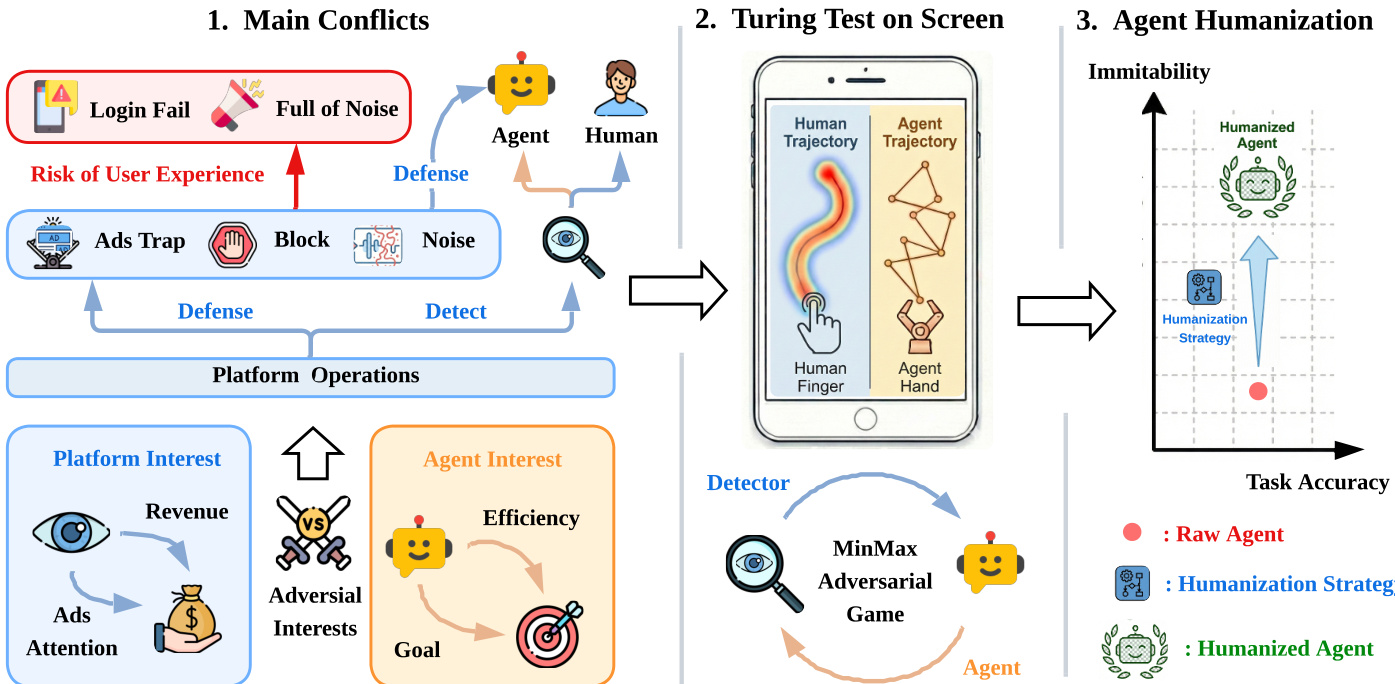
The detector DΘ evaluates the accumulated event stream E1:t at each time step, outputting a probability yt=DΘ(E1:t) that reflects the likelihood of the sequence being human-generated. Its objective is to maximize classification accuracy, formalized as the cross-entropy loss: LD=EE∼H[logDΘ(E)]+EE∼GΦ[log(1−DΘ(E))], where H and GΦ represent the distributions of human and agent-generated event sequences, respectively. In contrast, the agent GΦ must optimize its parameters to minimize detection probability while preserving task utility, leading to a regularized loss function: LG=Es∼S[∑t=1TI(DΘ(E1:t)<τ)−λ⋅Rtask(GΦ)]. Here, τ is a detection threshold, I(⋅) is the indicator function, and Rtask denotes the task success rate, with λ governing the trade-off between imitability and functionality.
To achieve humanization, the framework employs an external wrapper module H that transforms raw agent actions araw into humanized sequences ahuman. Four distinct strategies are proposed to address different aspects of human behavior: (1) Heuristic Noise Injection using B-spline smoothing to introduce biologically plausible curvature into swipe trajectories, (2) Data-Driven History Matching, which aligns agent actions with real human trajectories through affine transformations to preserve authentic velocity profiles and micro-jitters, (3) Fake Actions, which inject non-functional micro-interactions during idle periods to mask inference latencies, and (4) Longer Presses, which sample tap durations from a Gaussian distribution fitted to human data to eliminate the near-zero tap durations characteristic of raw agents. The theoretical foundation for these strategies is provided by theorems that establish the effectiveness of variance injection and the asymptotic superiority of history matching in reducing the Jensen-Shannon divergence between human and agent behavior distributions.
Experiment
The evaluation compares various humanization strategies, including trajectory adjustment and temporal noise injection, against machine learning classifiers to assess their ability to mask mechanical agent patterns. While geometric features like path shape are easily humanized through empirical data matching, temporal rhythms and endpoint precision remain difficult to mask due to a fundamental trade-off between behavioral imitability and task utility. Ultimately, the results demonstrate that while effective humanization can significantly reduce detection accuracy, naive noise injection can inadvertently introduce new mechanical artifacts or disrupt task success, necessitating more context-aware approaches.
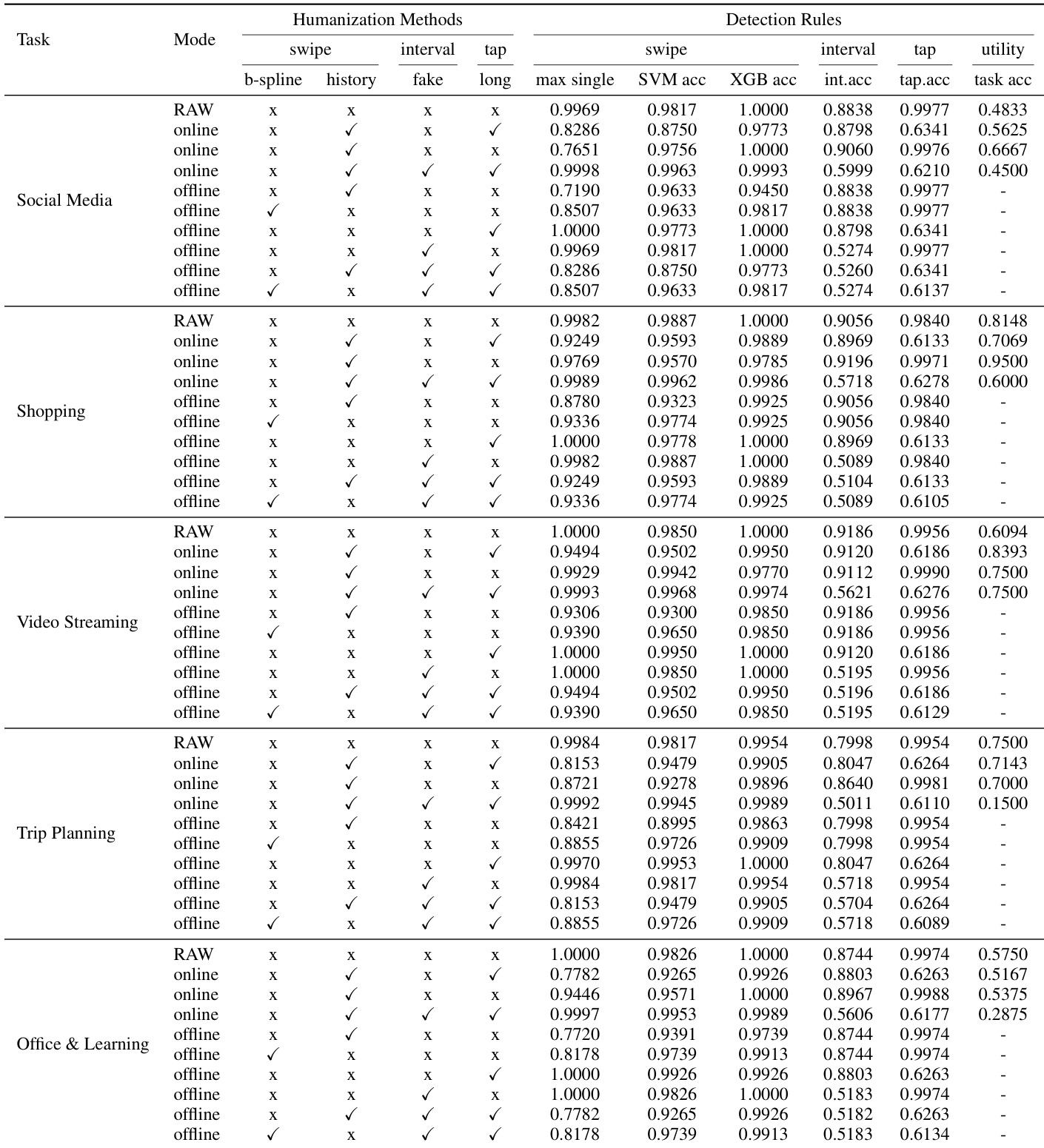
The authors compare various humanization methods across multiple tasks and detection rules, evaluating their effectiveness in reducing detectability while maintaining task utility. Results show that different strategies perform variably depending on the task and detection rule, with some methods significantly lowering detection accuracy but at the cost of utility. History Matching consistently outperforms B-spline Noise in reducing detection accuracy across tasks. Fake Action injection reduces detection accuracy but often leads to significant task utility loss. The effectiveness of humanization varies by task, with some strategies maintaining high utility while others cause substantial performance degradation.
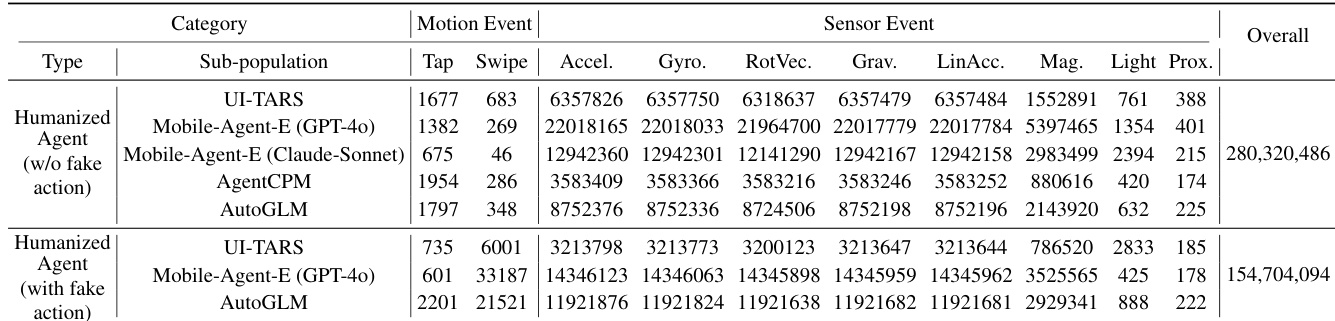
The authors compare the effectiveness of different humanization strategies across motion and sensor events. Results show that humanized agents with fake action injection achieve higher overall detection scores compared to those without, indicating reduced imitability. Humanization with fake action injection leads to higher detection scores than without. Different humanization strategies impact motion and sensor event features differently. The overall detection score is higher for agents with fake action injection.
The heatmap visualizes correlations between behavioral features extracted from human and non-humanized agent trajectories. It reveals clusters of highly correlated features, particularly among velocity and deviation metrics, indicating shared patterns in agent motion that differ from human variability. Velocity and deviation features show strong positive correlations among non-humanized agents. Features like duration and start coordinates exhibit mixed correlations, suggesting varied behavioral patterns. The matrix highlights distinct clusters of correlated attributes, reflecting underlying structural differences between human and agent motion.
The the the table presents information gain values for various behavioral features, indicating their ability to distinguish between human and agent actions. Features related to trajectory deviation and spatial metrics show higher discriminative power compared to coordinate and temporal attributes. Geometric and deviation features exhibit higher information gain than coordinate and time-based features. Velocity and acceleration metrics show moderate information gain, with peak values around 0.5. Features like maxDev and ratio_end_to_length have high information gain, suggesting they are strong discriminators of human-like behavior.
The the the table presents detection accuracy results for different humanization strategies across two application clusters. Results show that humanization methods reduce detectability, with varying effectiveness depending on the feature and cluster. Humanization strategies reduce detection accuracy across most features compared to raw agent data. History Matching shows consistent improvement in reducing detectability across both clusters. The effectiveness of humanization varies by feature, with some metrics like maxDev showing significant reduction while others like duration remain high.
The authors evaluate various humanization strategies across multiple tasks and detection rules to assess their ability to reduce detectability while preserving task utility. The experiments demonstrate that while methods like History Matching consistently lower detection accuracy, others such as fake action injection may cause significant performance degradation. Furthermore, the analysis of feature correlations and information gain reveals that geometric and deviation metrics serve as the most critical discriminators between human and agent behaviors.