Command Palette
Search for a command to run...
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
الملخص
مع تقدم تقنيات توليد الفيديو التفاعلي، أظهرت نماذج Diffusion إمكانات متزايدة كـ world models. ومع ذلك، لا تزال النهج الحالية تواجه صعوبة في تحقيق الاتساق الزمني طويل المدى المدعوم بالذاكرة (memory-enabled long-term temporal consistency) مع التوليد في الوقت الفعلي (real-time generation) عالي الدقة في آن واحد، مما يحد من قابليتها للتطبيق في السيناريوهات الواقعية. ولمعالجة هذه المشكلة، نقدم Matrix-Game 3.0، وهو interactive world model معزز بالذاكرة مصمم لتوليد فيديوهات طويلة في الوقت الفعلي بدقة 720p. وبالاعتماد على Matrix-Game 2.0، قمنا بإدخال تحسينات منهجية تشمل البيانات، والنموذج، وعملية الـ inference.أولاً، قمنا بتطوير محرك بيانات لا نهائي (infinite data engine) مطور بمقياس صناعي، يدمج البيانات الاصطناعية المستندة إلى Unreal Engine، والجمع الآلي واسع النطاق من ألعاب AAA، وتعزيز الفيديوهات الواقعية لإنتاج بيانات من نوع quadruplet (Video-Pose-Action-Prompt) عالية الجودة وبكميات ضخمة. ثانياً، اقترحنا إطار عمل training لتحقيق الاتساق طويل المدى (long-horizon consistency)؛ فمن خلال نمذجة متبقيات التنبؤ (prediction residuals) وإعادة حقن الإطارات المولدة غير المثالية أثناء الـ training، يتعلم النموذج الأساسي التصحيح الذاتي (self-correction)؛ وفي الوقت نفسه، تتيح عملية استرجاع وحقن الذاكرة المدركة لحركة الكاميرا (camera-aware memory retrieval and injection) للنموذج الأساسي تحقيق اتساق مكاني وزماني طويل المدى. ثالثاً، صممنا استراتيجية تقطير (distillation) ذاتية الانحدار متعددة الأجزاء تعتمد على Distribution Matching Distillation (DMD)، مدمجة مع تقنيات model quantization و VAE decoder pruning، لتحقيق inference فعال في الوقت الفعلي.تظهر النتائج التجريبية أن Matrix-Game 3.0 يحقق توليداً في الوقت الفعلي بسرعة تصل إلى 40 FPS بدقة 720p باستخدام نموذج بحجم 5B، مع الحفاظ على اتساق مستقر للذاكرة عبر تسلسلات تمتد لعدة دقائق. كما يؤدي التوسع إلى نموذج 2x14B إلى تحسين جودة التوليد، والديناميكيات، والقدرة على التعميم (generalization). يوفر نهجنا مساراً عملياً نحو world models قابلة للنشر على نطاق صناعي.
One-sentence Summary
The authors propose Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time long-form video generation that utilizes an industrial-scale infinite data engine and a training framework incorporating prediction residual modeling and camera-aware memory retrieval to achieve long-horizon spatiotemporal consistency.
Key Contributions
- The paper introduces Matrix-Game 3.0, a memory-augmented interactive world model capable of generating 720p high-resolution video in real time.
- An upgraded industrial-scale infinite data engine is developed to produce high-quality Video-Pose-Action-Prompt quadruplets by integrating Unreal Engine synthetic data, automated AAA game collections, and real-world video augmentation.
- A novel training framework for long-horizon consistency is proposed that utilizes prediction residual modeling and re-injected generated frames for self-correction alongside camera-aware memory retrieval and injection to maintain spatiotemporal consistency.
Introduction
Interactive world models are essential for simulating complex environments in robotics, gaming, and extended reality by predicting future observations based on user actions. While diffusion models have advanced video synthesis, existing approaches struggle to balance long-term spatiotemporal consistency with the high-resolution, real-time performance required for practical deployment. Current methods often face a trade-off where increasing memory or context length leads to prohibitive latency or a loss of geometric stability.
The authors leverage a co-designed framework across data, modeling, and deployment to introduce Matrix-Game 3.0. They develop an industrial-scale data engine using Unreal Engine 5 and AAA game captures to provide high-quality video-pose-action-prompt quadruplets. To ensure stability, the authors implement a camera-aware memory retrieval mechanism and an error-aware training framework that enables the model to learn self-correction. Finally, they utilize a multi-segment autoregressive distillation strategy combined with model quantization and VAE pruning to achieve 720p generation at up to 40 FPS.
Dataset
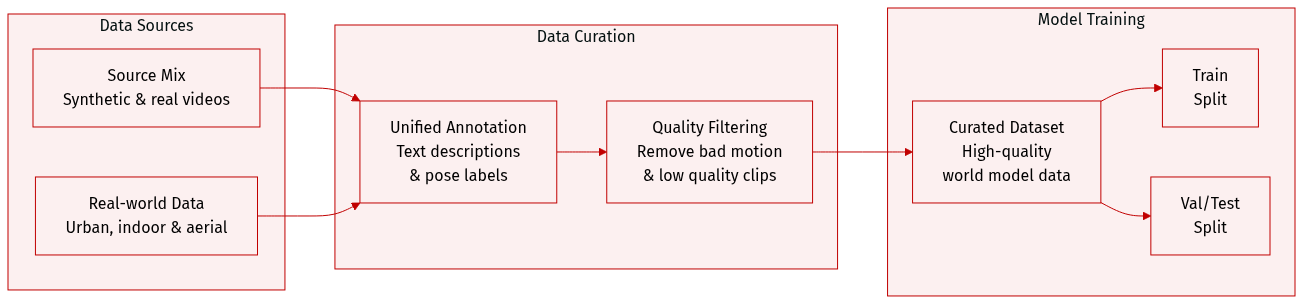
The authors developed a robust data system designed for large-scale world model training by integrating synthetic and real-world data through a unified pipeline.
-
Dataset Composition and Sources The dataset combines synthetic data from Unreal Engine-based first-person generation and AAA game recordings with four primary real-world video sources:
- DL3DV-10K: Over 10,000 4K video sequences across 65 point-of-interest categories.
- RealEstate10K: Indoor real-estate walkthroughs featuring static scenes and clean camera trajectories.
- OmniWorld-CityWalk: First-person urban walking footage from YouTube captured under various weather and lighting conditions.
- SpatialVid-HD: The largest subset, covering high-definition pedestrian, driving, and drone-aerial scenarios to improve long-tail viewpoint coverage.
-
Data Processing and Metadata Construction
- Uniform Re-annotation: To ensure consistency in coordinate conventions and pose representations, the authors re-annotate all real-world data using ViPE rather than relying on bundled annotations.
- Hierarchical Textual Annotation: Using InternVL3.5-8B, the authors generate structured descriptions for every clip based on a four-tier schema: narrative captions for holistic summaries, static scene captions for appearance modeling, dense temporal captions for event and motion labels, and perceptual quality scores.
- Perceptual Quality Scoring: Each clip is rated from 0 to 10 across five dimensions: motion smoothness, background dynamics, scene complexity, physics plausibility, and overall quality.
-
Filtering and Curation The authors implement a multi-stage filtering process to remove 20% of the raw data and ensure high quality:
- Trajectory and Speed Filtering: Three criteria are used to eliminate abnormal motion: local geometric consistency (via depth reprojection error), global motion anomaly (via max-to-median displacement ratio), and camera speed filtering (based on median velocity).
- Quality Filtering: Clips are further vetted using the perceptual quality scores to ensure the final training set is highly curated.
Method
The Matrix-Game 3.0 framework is designed to address the challenges of long-horizon generation and real-time inference in interactive world models. The system integrates four key components: an error-aware interactive base model, a camera-aware long-horizon memory mechanism, a training-inference aligned few-step distillation pipeline, and a real-time inference acceleration module. These components are coordinated to enable stable, high-resolution, and real-time generation with large models.
The core of the framework is the error-aware interactive base model, which is built upon a bidirectional diffusion Transformer. This architecture ensures that the model can maintain consistency during long-term, autoregressive generation while supporting precise action control. The model processes a sequence of video latents, partitioned into past frames that serve as history conditions and current frames to be predicted. Gaussian noise is added to the current frames before they are concatenated with the past frames and fed into the Transformer. The training objective is a flow-matching loss applied only to the current frames. To enable robust action control, discrete keyboard actions are incorporated via a dedicated Cross-Attention module, while continuous mouse-control signals are injected through Self-Attention. The model is also trained with imperfect historical contexts to ensure consistency with the subsequent distillation stage. A critical aspect of this design is the self-correcting formulation, which uses an error buffer to collect and inject residuals, simulating exposure errors during training.
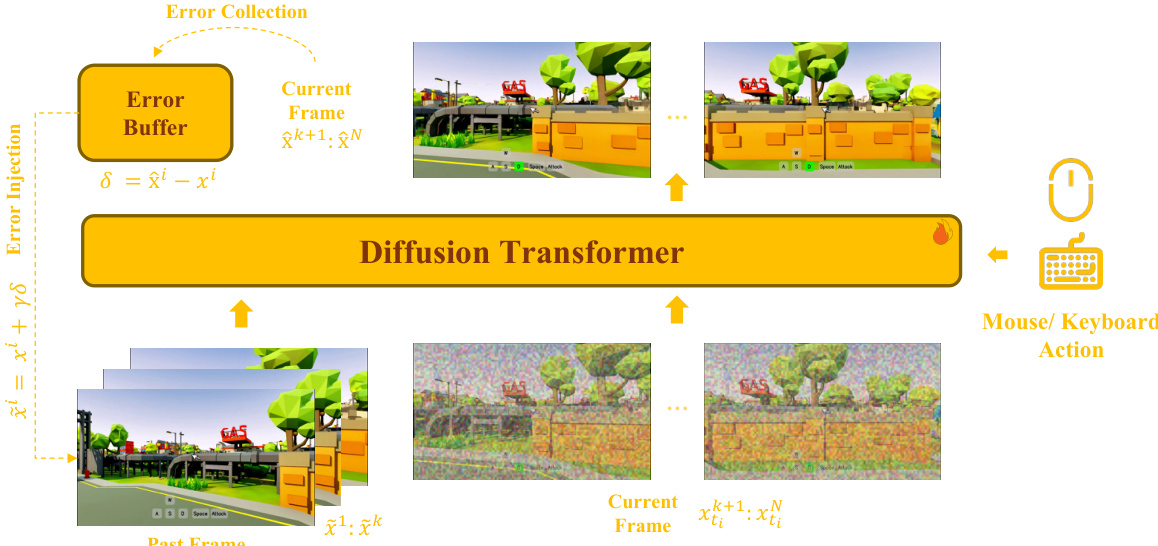
To enhance long-horizon generation, the framework incorporates a camera-aware long-horizon memory mechanism. This mechanism is built upon the base model and uses a unified Diffusion Transformer (DiT) to jointly model long-term memory, short-term history, and the current prediction target. Instead of treating memory as a separate branch, retrieved memory latents, past frame latents, and current prediction latents are placed in the same attention space, allowing for direct information exchange. This joint modeling is more compatible with streaming generation than a separate memory pathway. The memory selection is camera-aware, retrieving frames based on camera pose and field-of-view overlap to ensure only view-relevant content is used. The relative geometry between the current target and the selected memory is encoded using Plücker-style cues to help the model reason about scene alignment across different viewpoints. To reduce the train-inference mismatch, the memory pathway also uses error collection and injection on both the retrieved memory and past frames. Additionally, the model's temporal awareness is strengthened by injecting the original frame index into the rotary positional encoding and by introducing a head-wise perturbed RoPE base to mitigate positional aliasing and discourage over-reliance on distant memory.

The training-inference aligned few-step distillation pipeline ensures that the distilled model can perform stable few-step long-horizon generation. This is achieved by training the bidirectional student model to mimic the actual inference process. The student performs multi-segment rollouts, where each segment starts from random noise, and the past frames are taken from the tail of the previous segment. This multi-segment scheme creates a training environment that closely matches the inference behavior, thereby reducing exposure bias. The distillation objective is based on Distribution Matching Distillation (DMD), which minimizes the reverse KL divergence between the student's generated distribution and the data distribution at sampled timesteps. The gradient of this objective is approximated by the difference between the score functions of the data and the generated samples.
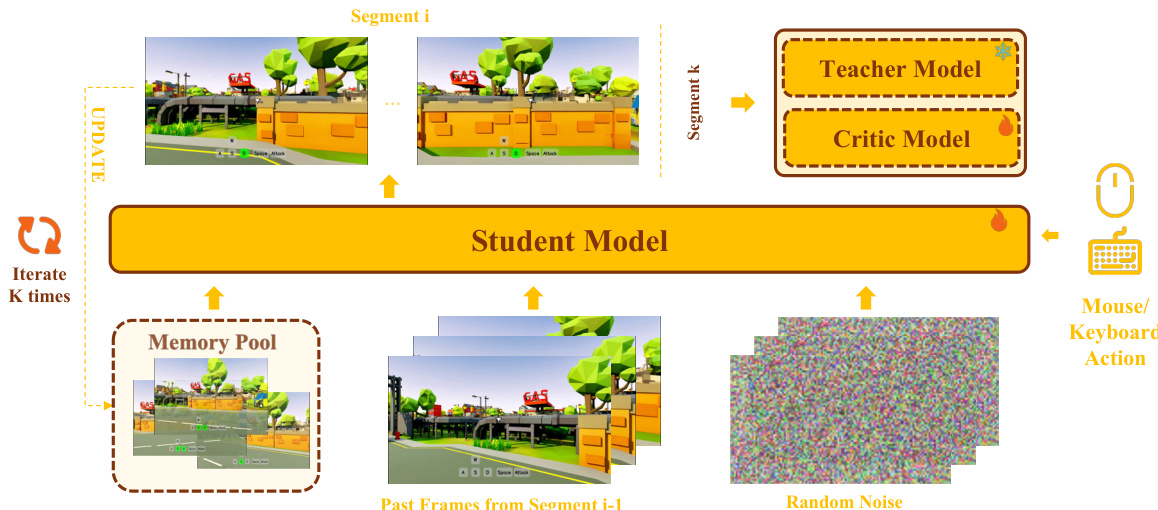
Finally, the real-time inference acceleration module ensures that the distilled model achieves high-speed inference. This is accomplished through several strategies: INT8 quantization of the DiT model's attention projection layers to reduce computation, VAE pruning to accelerate decoding, and GPU-based memory retrieval. The VAE is pruned to a lightweight version, MG-LightVAE, which achieves significant decoding speedups. The retrieval process is accelerated by using a GPU-based, sampling-based approximation for camera-aware memory retrieval, which is more efficient than the exact CPU-based method for long iterative generation. These optimizations enable the full pipeline to achieve up to 40 FPS inference with a 5B model at 720p resolution.
Experiment
The evaluation assesses the interactive base model, its distilled version, and various acceleration strategies to validate long-range scene consistency and inference efficiency. Results show that the memory-augmented base model and its distilled counterpart effectively reconstruct previously visited viewpoints and maintain stable scene layouts during long-horizon generation. Furthermore, combining INT8 quantization, VAE pruning, and GPU-based memory retrieval significantly enhances throughput, with pruned VAE variants successfully balancing reconstruction quality and real-time performance.
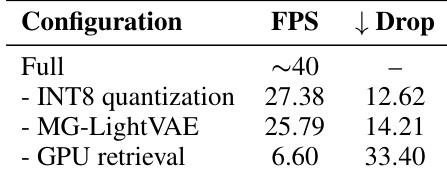
The study evaluates the impact of different acceleration components on inference speed. Results show that removing individual components reduces frames per second, with GPU retrieval having the most significant effect on performance. Removing GPU retrieval causes the largest drop in frames per second. INT8 quantization and MG-LightVAE both contribute to improved inference efficiency. The full configuration achieves the highest throughput, indicating synergistic benefits from combined optimizations.
The authors compare the reconstruction quality and efficiency of pruned variants of MG-LightVAE against the original Wan2.2 VAE. Results show that pruning reduces inference time while maintaining acceptable reconstruction fidelity, with higher pruning ratios leading to greater speedup at the cost of some quality. Pruning reduces inference time for both full and decoder-only reconstruction Higher pruning ratios lead to greater speedup but larger quality degradation The 50% pruned variant maintains strong reconstruction quality with significant efficiency gains

The study evaluates the impact of various acceleration components and pruning ratios on inference speed and reconstruction quality. Ablation experiments demonstrate that combining GPU retrieval, INT8 quantization, and MG-LightVAE creates a synergistic effect that maximizes throughput. Additionally, pruning the VAE offers a way to significantly reduce inference time, with moderate pruning levels successfully balancing efficiency gains against reconstruction fidelity.