Command Palette
Search for a command to run...
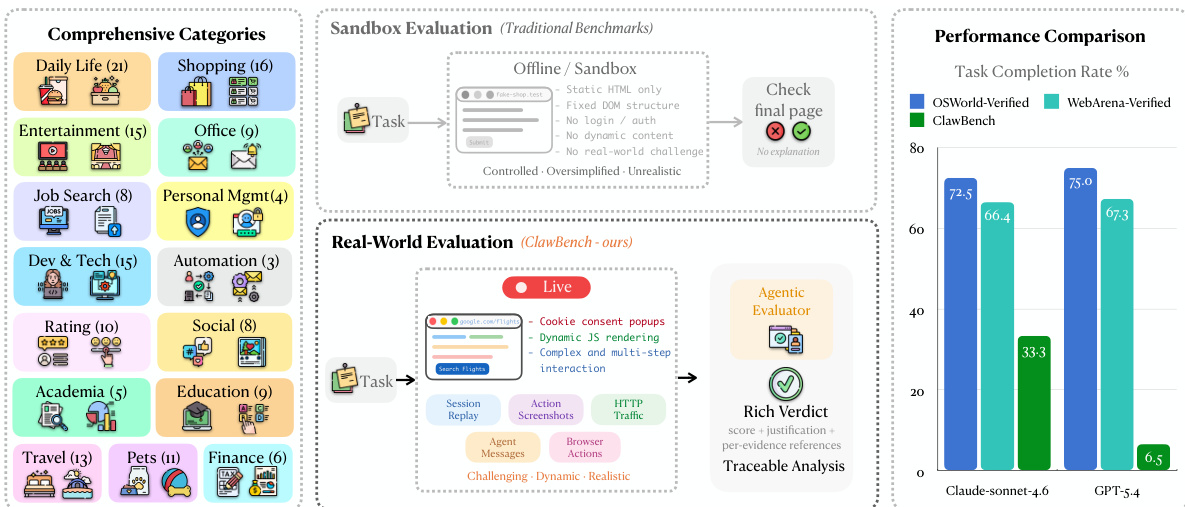
ClawBench: هل تستطيع AI Agents إكمال المهام اليومية عبر الإنترنت؟
ClawBench: هل تستطيع AI Agents إكمال المهام اليومية عبر الإنترنت؟
الملخص
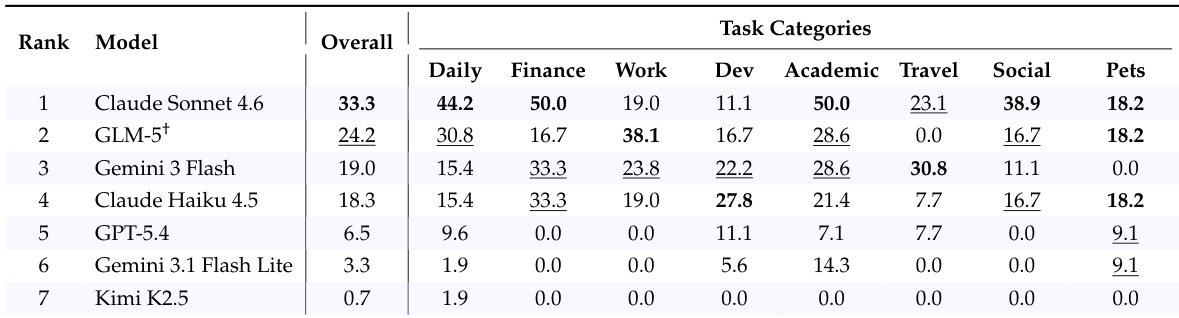
قد تتمكن AI agents من أتمتة بريدك الوارد، ولكن هل يمكنها أتمتة الجوانب الروتينية الأخرى من حياتك؟ توفر المهام اليومية عبر الإنترنت بيئة اختبار واقعية ولكنها غير محلولة لتقييم الجيل القادم من AI agents. وتحقيقاً لهذه الغاية، نقدم ClawBench، وهو إطار تقييم يتكون من 153 مهمة بسيطة يحتاج الأشخاص إلى إنجازها بانتظام في حياتهم وعملهم، وتغطي 144 منصة حية عبر 15 فئة، بدءاً من إتمام عمليات الشراء وحجز المواعيد وصولاً إلى تقديم طلبات التوظيف.تتطلب هذه المهام قدرات متقدمة تتجاوز ما تقدمه الـ benchmarks الحالية، مثل استخراج المعلومات ذات الصلة من المستندات التي يقدمها المستخدم، والتنقل عبر workflows متعددة الخطوات عبر منصات متنوعة، والعمليات التي تعتمد بشكل مكثف على الكتابة مثل ملء العديد من النماذج التفصيلية بشكل صحيح. وبخلاف الـ benchmarks الحالية التي تقيم الـ agents في بيئات sandbox غير متصلة بالإنترنت (offline) ذات صفحات ثابتة، يعمل ClawBench على مواقع إنتاج حقيقية (production websites)، مما يحافظ على التعقيد الكامل والطبيعة الديناميكية والتحديات التي تفرضها التفاعلات الواقعية عبر الويب.تستخدم المنصة طبقة اعتراض (interception layer) خفيفة الوزن تقوم بالتقاط وحظر طلب الإرسال النهائي فقط، مما يضمن تقييماً آمناً دون آثار جانبية في العالم الحقيقي. وتظهر تقييماتنا لـ 7 نماذج رائدة (frontier models) أن كلاً من النماذج المملوكة (proprietary) ومفتوحة المصدر (open-source) لا يمكنها إكمال سوى جزء صغير فقط من هذه المهام؛ فعلى سبيل المثال، حقق نموذج Claude Sonnet 4.6 نسبة 33.3% فقط. إن التقدم في ClawBench يقربنا أكثر من الوصول إلى AI agents يمكنها العمل كمساعدين عامين موثوقين.
One-sentence Summary
To evaluate the ability of AI agents to automate routine life and work activities, the researchers introduce ClawBench, an evaluation framework comprising 153 tasks across 144 live platforms that utilizes a lightweight interception layer on production websites to preserve real-world complexity, revealing that frontier models struggle with these dynamic workflows and achieve low success rates, such as 33.3% for Claude Sonnet 4.6.
Key Contributions
- This work introduces CLAWBENCH, an evaluation framework consisting of 153 routine tasks across 144 live platforms that require complex capabilities like navigating multi-step workflows and performing write-heavy operations.
- The framework utilizes a lightweight interception layer to capture and block final submission requests, allowing for safe evaluation on production websites without causing real-world side effects.
- The researchers implement an agentic evaluator that performs step-level alignment between agent trajectories and human reference trajectories to provide binary success verdicts and structured justifications.
Introduction
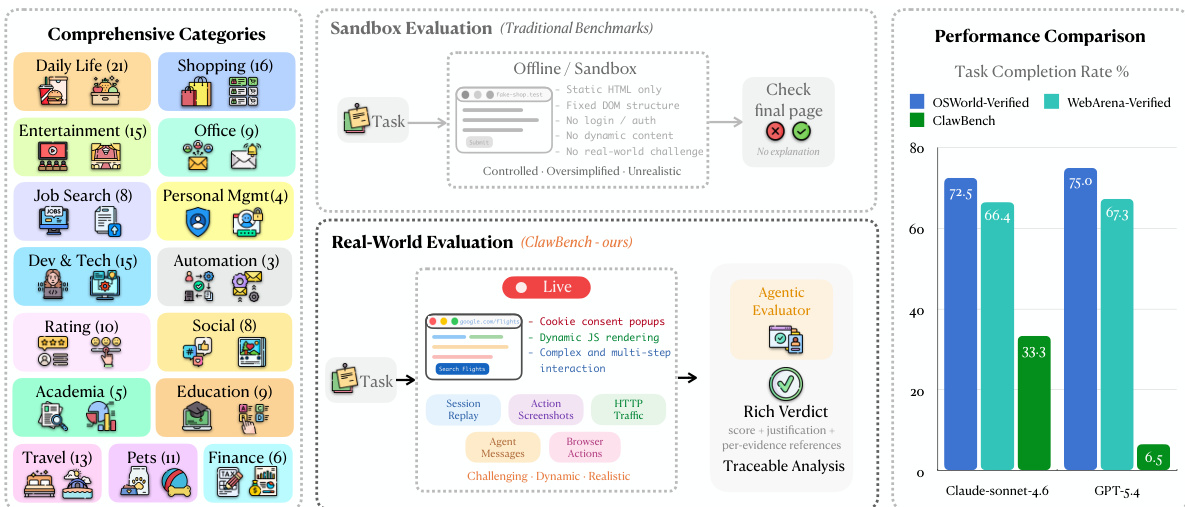
As AI agents move toward automating routine life and work tasks, they must navigate the complexities of real-world web environments. Existing benchmarks often rely on simplified, synthetic sandboxes or read-only tasks that fail to capture the difficulty of state-changing, write-heavy operations like filling out detailed forms or booking appointments. The authors introduce CLAWBENCH, an evaluation framework consisting of 153 everyday tasks across 144 live production platforms. To ensure safety while maintaining ecological validity, the authors leverage a specialized interception layer that blocks final submission requests, allowing agents to interact with real websites without unintended real-world consequences. This framework provides a scalable, traceable method for evaluating how well frontier models handle the multi-step workflows and dynamic nature of the actual web.
Dataset

-
Dataset Composition and Sources: The authors introduce CLAWBENCH, a benchmark consisting of 153 real-world web tasks distributed across 144 live production platforms. The tasks are organized into 8 high-level category groups and focus on write-heavy operations, such as making reservations, purchases, or applications, which require modifying server-side states.
-
Task Details and Filtering: Each task is defined by a natural language instruction, a starting URL, and a specific terminal submission target at the HTTP request level. To ensure quality and usability, the authors applied a multi-stage filtering pipeline to remove tasks involving paid subscriptions, geographically restricted services, or websites that are no longer active. Human annotators were used to instantiate realistic goals and verify that every task remains completable and reproducible.
-
Data Processing and Interception: A key technical feature is the manual annotation of interception signals. Human experts inspect browser network traffic during ground-truth execution to identify the exact HTTP endpoint, method, and payload schema for the irreversible submission. This allows the framework to intercept the terminal request, ensuring the agent can complete the workflow without causing real-world side effects like actual financial transactions.
-
Multi-Layer Recording and Evaluation: The authors use a synchronized five-layer recording infrastructure to capture both human ground-truth trajectories and agent execution traces. These layers include:
- Session recordings via video.
- Per-step action screenshots.
- Full HTTP traffic logs, including request bodies and payloads.
- Structured JSON logs of agent messages, including reasoning chains and tool calls.
- Low-level browser actions such as mouse coordinates and keystrokes.
-
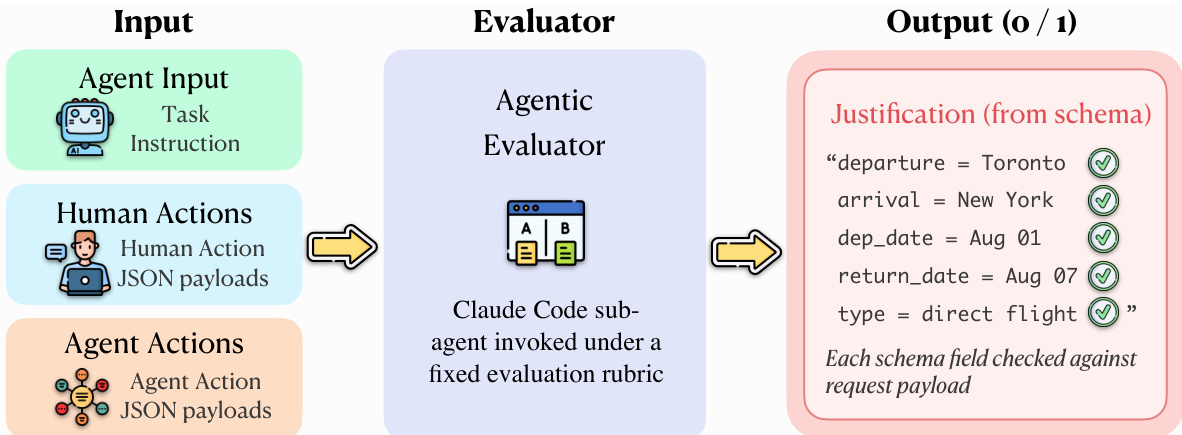
Usage in Evaluation: The dataset is used to evaluate AI agents by comparing their full behavioral trajectories against human ground-truth references. An Agentic Evaluator performs step-level alignment across the five multimodal layers to determine success, enabling deep diagnostic traceability to identify exactly where an agent's reasoning or actions diverged from the human reference.
Method
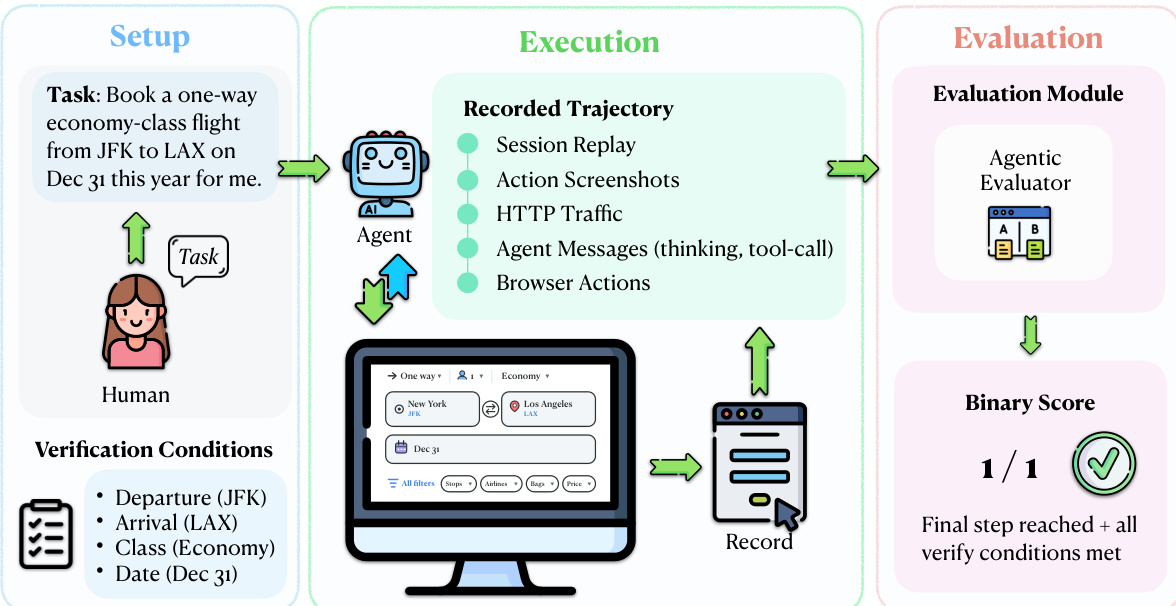
The authors leverage a real-world evaluation framework centered on a multi-layered trajectory comparison between agent and human executions. The core of this approach is the interception mechanism, which enables safe and ecologically valid evaluation by capturing only the final request of a task without allowing it to reach the server. Refer to the framework diagram, which illustrates the overall process from task setup to evaluation. This mechanism is implemented via a lightweight Chrome extension and a Chrome DevTools Protocol (CDP) server that monitors outgoing HTTP requests. When an agent action triggers a request matching a human-annotated URL pattern and HTTP method, the system captures the full request payload—including form fields, headers, and query parameters—blocks the request from reaching the server, and logs it locally with a timestamp and tab URL. All other requests, such as page loads and dynamic content fetches, pass through unmodified, preserving the agent's interaction experience.
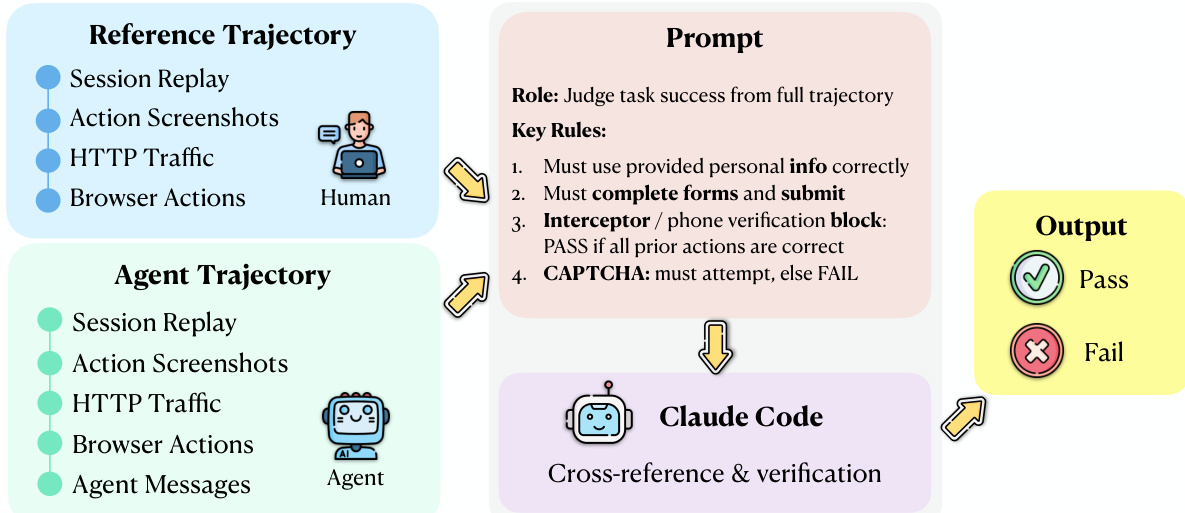
The evaluation protocol operates on five synchronized evidence streams derived from both the agent and a human reference trajectory: session replay, screenshots, HTTP traffic, browser actions, and agent messages. As shown in the figure below, the evaluation module uses an Agentic Evaluator, implemented as a Claude Code sub-agent, to perform an explicit alignment between the agent and human trajectories. This evaluator receives the task instruction, the agent trajectory, and the human reference trajectory as input and applies a fixed evaluation rubric to determine task success. The evaluation process involves identifying corresponding steps, detecting divergences, verifying that required fields and actions are correct, and confirming that the agent reaches a terminal state equivalent to the human reference.
The Agentic Evaluator produces a binary verdict for each task, indicating success or failure. For a task t, let q(t) denote the task instruction, Ta(t) the agent trajectory, and Th(t) the human reference trajectory. The evaluator A maps these inputs to a binary task-level verdict: Score(t)=A(q(t),Ta(t),Th(t)), where Score(t)∈{0,1}, with 1 indicating successful task completion. The overall success rate over a task set T is then defined as SR=∣T∣1∑t∈TScore(t), where ∣T∣ is the number of evaluated tasks. This comparative evaluation design leverages the full multi-layer recordings and grounds success determination in a concrete human demonstration, avoiding reliance on potentially ambiguous task instructions alone.
The Agentic Evaluator operates by invoking a Claude Code sub-agent under a fixed evaluation rubric. The input to the evaluator includes the task instruction, human action payloads, and agent action payloads. The evaluator compares the agent's execution against the human reference trajectory, which consists of session replay, action screenshots, HTTP traffic, and browser actions. The evaluation process involves cross-referencing the agent's trajectory with the human reference and verifying specific conditions, such as correct form completion and submission. The output is a binary score with a structured justification, indicating whether the final step was reached and all verification conditions were met.
The evaluation module also includes a verification component that checks the agent's actions against the human reference trajectory. The evaluation process involves identifying corresponding steps, detecting divergences, and verifying that required fields and actions are correct. The Agentic Evaluator produces a binary verdict for each task, indicating success or failure. The overall success rate over a task set T is then defined as SR=∣T∣1∑t∈TScore(t), where ∣T∣ is the number of evaluated tasks. This comparative evaluation design leverages the full multi-layer recordings and grounds success determination in a concrete human demonstration, avoiding reliance on potentially ambiguous task instructions alone.
Experiment
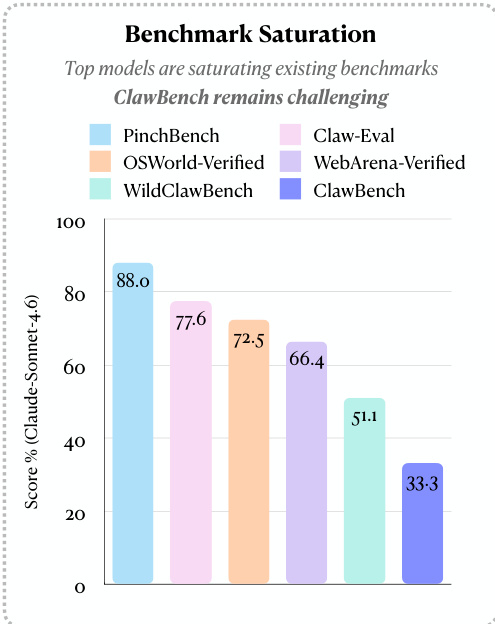
The CLAWBENCH benchmark evaluates the ability of frontier AI models to complete everyday online tasks by allowing them to operate on live, production websites rather than static sandboxes. By comparing agent trajectories against human ground-truth references through an agentic evaluator, the study validates how well models handle real-world complexities like dynamic content and multi-step workflows. The findings reveal that even the strongest models struggle significantly with these live environments, showing highly inconsistent performance across different life categories and failing to match their success rates on traditional, controlled benchmarks.
The authors evaluate several frontier AI models on CLAWBENCH, a benchmark that assesses task completion on live websites with real-world complexity. Results show that models perform significantly worse on CLAWBENCH compared to traditional sandboxed benchmarks, indicating the increased difficulty of real-world web tasks. Models achieve substantially lower success rates on CLAWBENCH compared to traditional benchmarks Performance varies significantly across different task categories, with no single model excelling uniformly The strongest model completes only a minority of tasks on CLAWBENCH, highlighting the challenge of real-world web interaction
The authors present CLAWBENCH, a benchmark that evaluates AI agents on real-world web tasks using a live environment and a multi-layered data recording system. Results show that even the strongest models achieve low success rates, indicating significant challenges in handling everyday online workflows. CLAWBENCH evaluates agents on live websites with real-world complexity, unlike existing benchmarks that use offline sandboxes. The benchmark uses a multi-layer data recording system to capture detailed agent behavior and enable traceable evaluation. Even the top-performing model achieves a low success rate, highlighting the difficulty of real-world web tasks compared to traditional benchmarks.
The authors evaluate seven frontier AI models on CLAWBENCH, a benchmark of real-world web tasks, and report overall and category-specific success rates. Results show that the strongest model achieves only moderate success overall, with significant variation across task categories, indicating persistent challenges in real-world web interaction. The top model achieves a 33.3% overall success rate on real-world web tasks Performance varies widely across task categories, with no model excelling uniformly Even the best-performing model shows substantial room for improvement in most domains
The authors compare model performance across different benchmarks, showing that top models achieve high scores on established benchmarks but significantly lower scores on CLAWBENCH. This indicates that CLAWBENCH remains challenging despite model improvements on other platforms. Top models achieve high success rates on established benchmarks but much lower rates on CLAWBENCH CLAWBENCH presents a more difficult evaluation due to real-world web complexity Performance varies across benchmarks, with CLAWBENCH showing the lowest scores for the same models
The authors evaluate seven frontier models on the CLAWBENCH benchmark, which assesses AI agents on real-world web tasks. Results show that the top-performing model achieves a success rate of 33.3%, with significant variation across models and task categories. Claude Sonnet 4.6 achieves the highest success rate among the evaluated models. Performance varies widely across models, with the top model outperforming others by a substantial margin. Model strengths differ by task category, indicating uneven competence across domains.
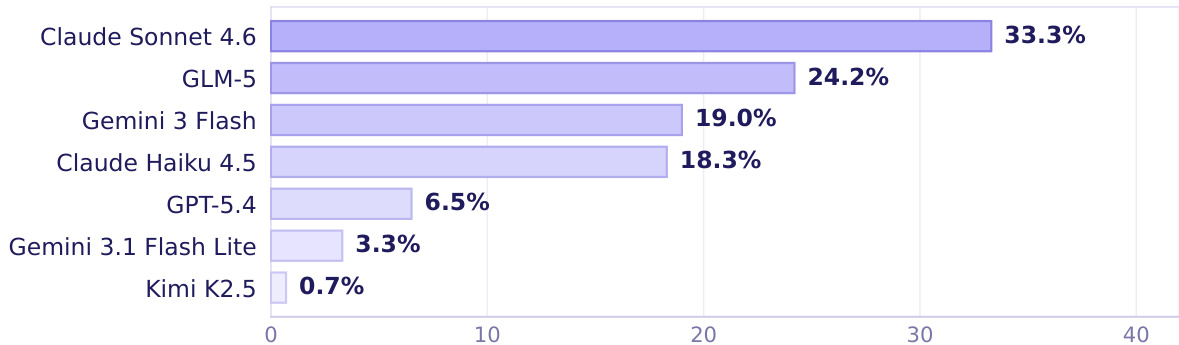
The authors evaluate several frontier AI models using CLAWBENCH, a benchmark designed to assess task completion within complex, live web environments rather than traditional sandboxed settings. The results demonstrate that current models struggle significantly with real-world web interactions, performing much worse on this benchmark than on established offline platforms. Even the strongest models show inconsistent success across different task categories, highlighting a substantial gap in the ability of AI agents to handle everyday online workflows.