Command Palette
Search for a command to run...
FORGE: تقييم متعدد الوسائط دقيق لسيناريوهات التصنيع
FORGE: تقييم متعدد الوسائط دقيق لسيناريوهات التصنيع
الملخص
يتزايد اعتماد قطاع التصنيع على نماذج اللغات الكبيرة متعددة الوسائط (Multimodal Large Language Models - MLLMs) للتحول من مجرد الإدراك البسيط إلى التنفيذ الذاتي، ومع ذلك، فإن التقييمات الحالية لا تعكس المتطلبات الصارمة لبيئات التصنيع في العالم الحقيقي. ويتعثر التقدم نتيجة لندرة البيانات ونقص المعاني الدلالية الدقيقة للمجال (fine-grained domain semantics) في مجموعات البيانات الحالية.ولسد هذه الفجوة، نقدم FORGE. قمنا أولاً ببناء مجموعة بيانات متعددة الوسائط عالية الجودة تجمع بين الصور ثنائية الأبعاد (2D images) وسحب النقاط ثلاثية الأبعاد (3D point clouds) الواقعية، والموسومة بدلالات دقيقة للمجال (على سبيل المثال، أرقام الطرازات الدقيقة). بعد ذلك، قمنا بتقييم 18 من نماذج MLLMs الرائدة عبر ثلاث مهام تصنيعية، وهي: التحقق من قطع العمل (workpiece verification)، وفحص السطح الهيكلي (structural surface inspection)، والتحقق من التجميع (assembly verification)، مما كشف عن فجوات كبيرة في الأداء.وعلى عكس الفهم التقليدي، أظهر تحليل عنق الزجاجة (bottleneck analysis) أن التأسيس البصري (visual grounding) ليس هو العامل المحدِد الرئيسي؛ بل إن عدم كفاية المعرفة المتخصصة في هذا المجال هو عنق الزجاجة الأساسي، مما يحدد اتجاهاً واضحاً للأبحاث المستقبلية. وإلى جانب التقييم، نوضح أن التوسيمات الهيكلية (structured annotations) الخاصة بنا يمكن أن تعمل كمورد تدريب فعال: حيث أدى الضبط الدقيق الخاضع للإشراف (supervised fine-tuning) لنموذج مدمج بحجم 3B-parameter على بياناتنا إلى تحقيق تحسن نسبي في الدقة يصل إلى 90.8% في سيناريوهات التصنيع غير المدرجة في التدريب (held-out scenarios)، مما يوفر دليلاً أولياً على مسار عملي نحو تطوير نماذج MLLMs مكيّفة لمجال التصنيع.التعليمات البرمجية ومجموعات البيانات متاحة على الرابط التالي: https://ai4manufacturing.github.io/forge-web.
One-sentence Summary
To address the limitations of current evaluations in the manufacturing sector, the authors introduce FORGE, a fine-grained multimodal evaluation framework and dataset that integrates 2D images and 3D point clouds with domain-specific semantics to reveal that insufficient domain knowledge, rather than visual grounding, is the primary bottleneck for the 18 state-of-the-art MLLMs evaluated across workpiece verification, structural surface inspection, and assembly verification tasks.
Key Contributions
- The paper introduces FORGE, a high-quality multimodal dataset that integrates real-world 2D images with 3D point clouds and incorporates fine-grained domain semantics such as exact model numbers.
- This work presents a comprehensive evaluation of 18 state-of-the-art Multimodal Large Language Models (MLLMs) across three specific manufacturing tasks, including workpiece verification, structural surface inspection, and assembly verification.
- The research demonstrates that supervised fine-tuning of a compact 3B-parameter model using the structured annotations from the new dataset can achieve up to 90% accuracy.
Introduction
The manufacturing sector is transitioning from simple perception to autonomous decision-making through the use of Multimodal Large Language Models (MLLMs). While traditional computer vision models excel at localized tasks like anomaly detection, they lack the reasoning capabilities required for high-level planning and execution. Current research is hindered by a significant data scarcity gap and a lack of fine-grained domain semantics, as most existing benchmarks fail to account for the rigorous precision and specific model-level details required in real-world factory environments.
The authors leverage these challenges to introduce FORGE, a comprehensive multimodal benchmark specifically designed for manufacturing. They construct a high-quality dataset that integrates aligned 2D images and 3D point clouds annotated with fine-grained semantics, such as exact model numbers. Through an extensive evaluation of 18 state-of-the-art MLLMs across three core tasks—workpiece verification, structural surface inspection, and assembly verification—the authors identify that insufficient domain knowledge, rather than visual grounding, is the primary bottleneck for current models. Finally, they demonstrate that their structured annotations serve as an effective training resource, showing that supervised fine-tuning can significantly improve model accuracy in unseen manufacturing scenarios.
Dataset
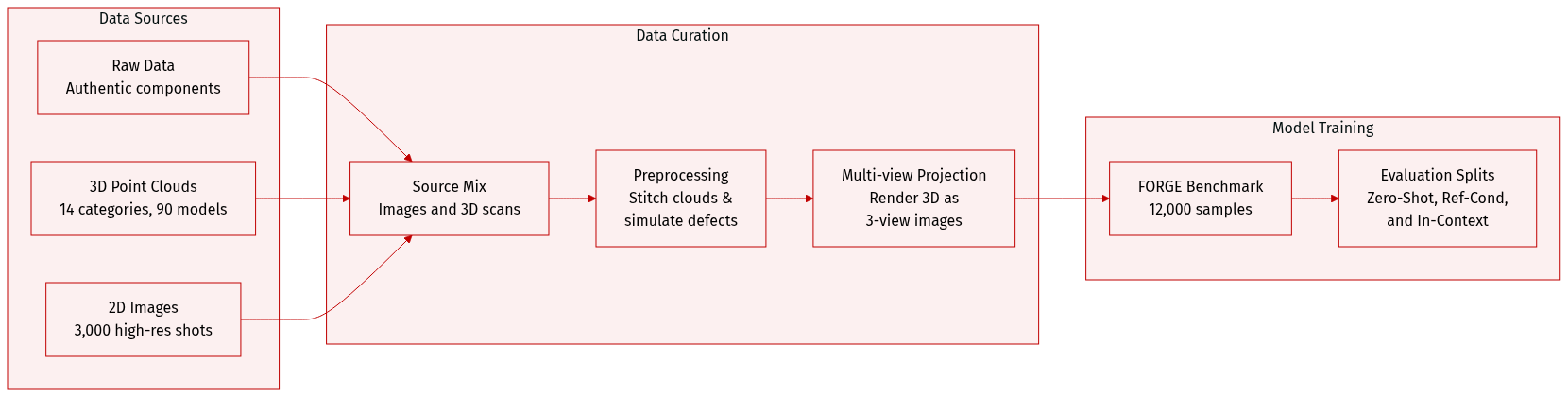
The authors developed FORGE, a comprehensive benchmark comprising approximately 12,000 samples designed to evaluate the reasoning and cognitive capabilities of Multimodal Large Language Models (MLLMs) in manufacturing contexts.
-
Dataset Composition and Sources
- The dataset is built from authentic manufacturing components collected via a precision rotary table and a custom fixture.
- 3D Point Cloud Subset: Contains high-fidelity geometric data covering 14 workpiece categories across 90 distinct models.
- Image Subset: Comprises approximately 3,000 high-resolution images (captured with a 50-megapixel sensor) covering four manufacturing scenarios, including both normal and abnormal samples.
-
Task-Specific Details
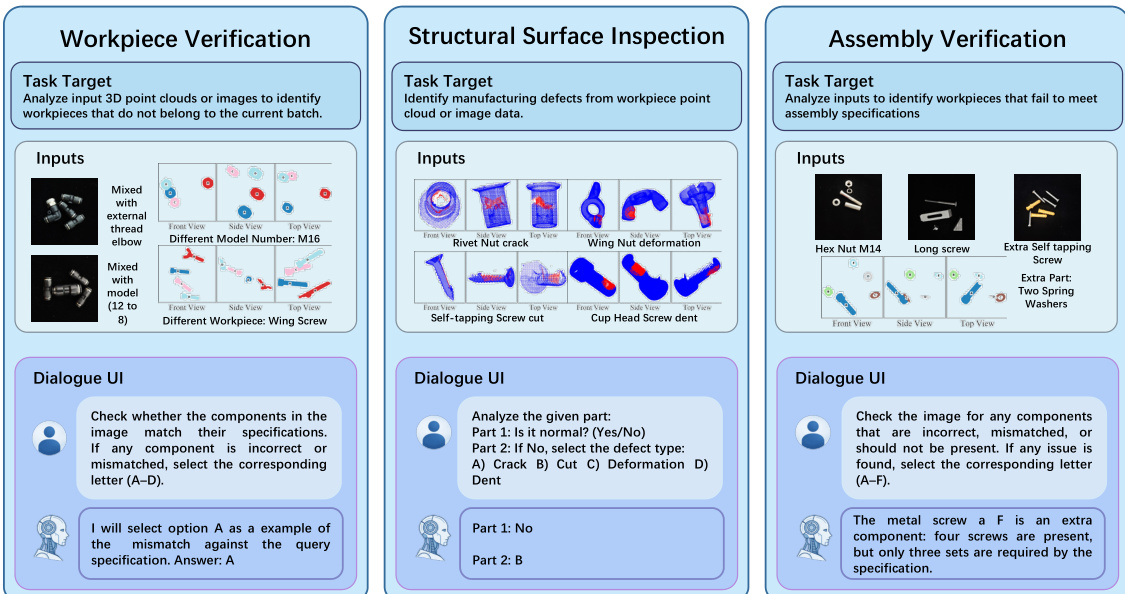
- Workpiece Verification (WORKVERI): Focuses on material sorting by identifying incorrect workpieces or model number mismatches. It includes scenarios for pneumatic connectors (images), cup head screws, and nuts (point clouds).
- Structural Surface Inspection (SURFINSPI): Targets defect detection and classification (e.g., Crack, Deformation, Dent, and Cut) across 14 workpiece types using point cloud data.
- Assembly Verification (ASSYVERI): Assesses understanding of assembly rules and compatibility. It covers four scenarios, including metal/plastic expansion screws and CNC fixtures (images), and screw/washer/nut compatibility (point clouds).
-
Data Processing and Synthesis
- 2D Image Processing: Ground-truth labels were established through automated contour and coordinate extraction followed by manual refinement.
- 3D Point Cloud Synthesis: For WORKVERI and ASSYVERI, the authors stitched 4 to 5 individual point clouds with random orientations to create batch samples. For SURFINSPI, manufacturing defects were simulated using morphology-based algorithms and non-rigid deformation, with defect density constrained between 5% and 15%.
- Data Augmentation: The SURFINSPI subset was augmented using 20 random rotations per sample.
-
Modality Bridging and Evaluation Strategy
- Multi-view Projection: To bridge the gap between 3D data and MLLMs lacking native 3D encoders, the authors render all 3D point clouds as three-view (3V) orthogonal projections (front, side, and top).
- Evaluation Settings: The benchmark utilizes three distinct settings: Zero-Shot, Reference-Conditioned (providing three correct normal cases), and In-Context Demonstration (providing a similar image, query, and correct answer).
- Error Categorization: Scenarios are classified into coarse-grained errors (different workpieces/missing components) and fine-grained errors (different model numbers).
Method
The authors leverage a multimodal framework designed to address industrial verification tasks through a structured pipeline that integrates diverse data modalities and task-specific architectures. The overall system begins with a multimodal data foundation, which processes real-world 2D images and 3D point clouds to generate fine-grained semantic annotations. These annotations serve as the basis for subsequent tasks within the FORGE benchmark, which is structured into three core components: Workpiece Verification, Structural Surface Inspection, and Assembly Verification. Each task is designed to analyze specific aspects of manufactured components, ranging from identifying non-conforming workpieces to detecting surface defects and validating assembly specifications.
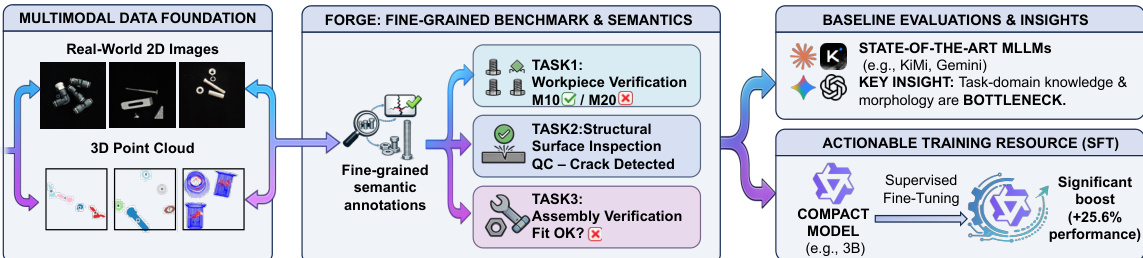
The framework is grounded in a unified annotation process that ensures semantic consistency across modalities. This foundation enables the generation of high-quality, fine-grained labels for various industrial scenarios. The resulting data is then used to train and evaluate models across multiple tasks. For instance, Workpiece Verification focuses on identifying components that deviate from expected specifications, such as those with incorrect model numbers or mismatched parts. Structural Surface Inspection targets the detection of manufacturing defects, including cracks, cuts, deformations, and dents, by analyzing surface features in 3D point clouds or images. Assembly Verification evaluates whether all required components are present and correctly specified, identifying missing parts or extraneous elements in an assembly.
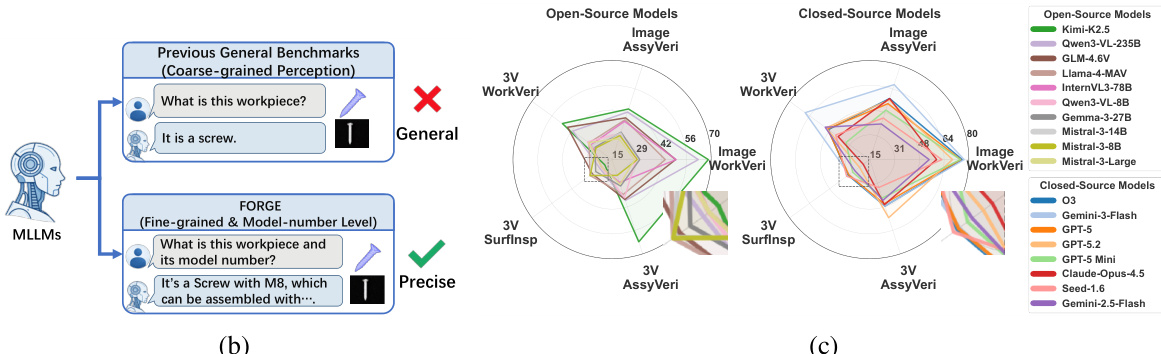
The model architecture is designed to handle both general perception tasks and fine-grained, model-level verification. While general-purpose models often fail to capture the nuanced requirements of industrial applications—such as distinguishing between a standard screw and a specific model number—the FORGE framework employs a precision-oriented approach. This is demonstrated by the shift from coarse-grained queries like "What is this workpiece?" to more precise inquiries such as "What is this workpiece and its model number?" which are better suited for detailed industrial inspection. The system further enhances its capabilities through a combination of supervised fine-tuning and compact model optimization, enabling significant performance gains.
To evaluate the effectiveness of the framework, the authors conduct baseline assessments using state-of-the-art multimodal large language models (MLLMs), highlighting key insights into the bottlenecks of current approaches. These evaluations reveal that domain-specific knowledge and geometric understanding are critical for accurate verification. The framework also incorporates actionable training resources, such as compact models, which achieve substantial performance improvements with minimal computational overhead. The system's modular design allows for scalability and adaptability across different industrial applications, ensuring robustness in real-world deployment.
Experiment
The evaluation assesses 18 multimodal large language models across three manufacturing tasks to determine their ability to perform assembly verification, surface defect classification, and component recognition. Results indicate that while models demonstrate strong semantic understanding and visual grounding, they struggle with microscopic surface morphology and fine-grained domain-specific reasoning. Bottleneck analyses reveal that failures in complex manufacturing scenarios stem primarily from a lack of deep domain knowledge and relational assembly logic rather than poor visual perception or localization capabilities.
The the the table compares several benchmarks for manufacturing tasks, highlighting differences in data modality, source, scenario, and granularity. FORGE is distinguished by its use of both image and point cloud data, real-world scenarios, and fine-grained model number and workpiece details, with the largest sample size among the listed benchmarks. FORGE includes both image and point cloud data modalities, unlike other benchmarks that use only one or none. FORGE is the only benchmark that evaluates both workpiece and model number granularity with real-world data. FORGE has the largest number of samples, indicating a more comprehensive evaluation dataset.

The the the table presents results from a visual grounding task, comparing the performance of four models across single-image and cross-image settings. The evaluation measures the ability to map between spatial coordinates and part labels, with the models achieving high accuracy in single-image tasks but lower performance in cross-image matching. Closed-source models achieve higher accuracy than open-source models in both single-image and cross-image settings. All models perform better on single-image tasks compared to cross-image tasks. The performance gap between single-image and cross-image tasks is more pronounced for open-source models.
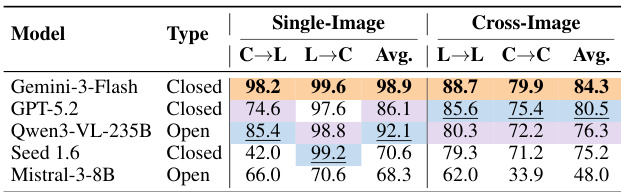
The authors evaluate multiple MLLMs on three manufacturing tasks, analyzing performance across different settings and modalities. Results show that current models struggle with fine-grained domain knowledge and spatial reasoning, particularly in tasks requiring detailed visual analysis and logical inference. MLLMs perform better on macroscopic part recognition than microscopic surface analysis Reference-based methods do not consistently improve performance, indicating a lack of deep domain understanding Three-view evaluations show performance degradation with additional examples, suggesting spatial confusion in models
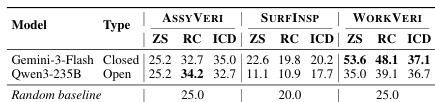
The experiments evaluate multimodal models on three manufacturing tasks, assessing performance across different scenarios and error types. Results show that models perform better on workpiece-level tasks than model-number-level tasks, and that visual grounding is not the primary bottleneck, suggesting domain knowledge limitations are more critical. Models perform better on workpiece-level tasks than on model-number-level tasks Visual grounding is not the main bottleneck, indicating domain knowledge limitations are more significant Performance degrades with additional examples in three-view modalities, suggesting spatial confusion

The experiment evaluates multiple MLLMs across manufacturing tasks, showing that closed-source models generally outperform open-source ones. Performance varies significantly across tasks and evaluation settings, with notable differences between zero-shot, reference-conditioned, and in-context demonstration methods. The results highlight that domain knowledge and reasoning capabilities are key bottlenecks, while visual grounding is not the primary limitation. Closed-source models achieve higher accuracy than open-source models across most tasks and settings. In-context demonstration methods generally improve performance over zero-shot and reference-conditioned settings. Performance varies significantly across tasks, with some tasks showing much lower accuracy than others, indicating task-specific challenges.
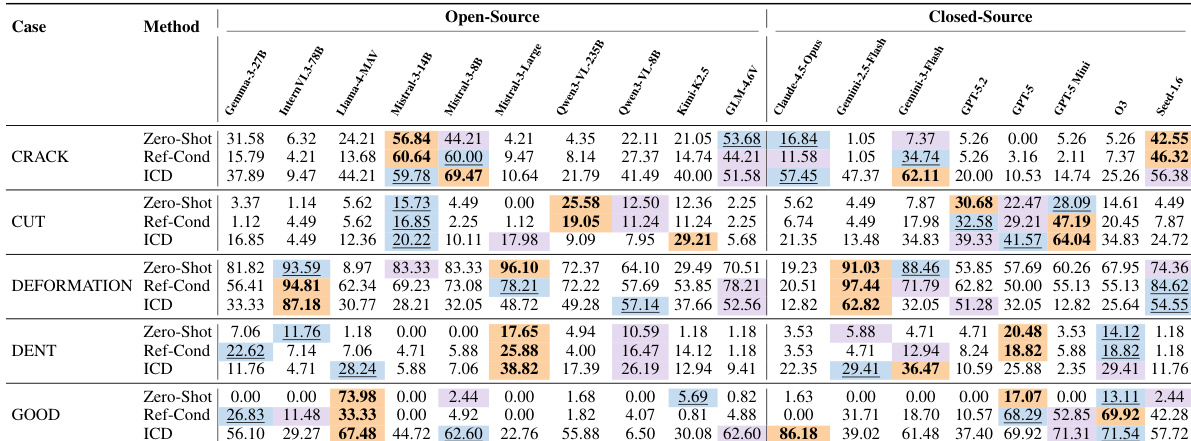
The evaluation compares various manufacturing benchmarks and the performance of multiple multimodal large language models across tasks involving visual grounding, part recognition, and spatial reasoning. While closed-source models generally outperform open-source ones, all models struggle with fine-grained domain knowledge and complex spatial reasoning, particularly when tasks require microscopic analysis or multiple views. The findings suggest that the primary limitations in these models are domain-specific understanding and logical inference rather than basic visual grounding capabilities.