Command Palette
Search for a command to run...
TC-AE: إطلاق قدرة الـ Token لـ Deep Compression Autoencoders
TC-AE: إطلاق قدرة الـ Token لـ Deep Compression Autoencoders
Teng Li Ziyuan Huang Cong Chen Yangfu Li Yuanhuiyi Lyu Dandan Zheng Chunhua Shen Jun Zhang
الملخص
نحن نقترح TC-AE، وهي بنية هندسية تعتمد على ViT مخصصة للمشفّرات التلقائية (autoencoders) ذات الضغط العميق. تهدف الأساليب الحالية عادةً إلى زيادة عدد القنوات في التمثيلات الكامنة (latent representations) للحفاظ على جودة إعادة البناء في ظل نسب الضغط العالية. ومع ذلك، تؤدي هذه الاستراتيجية غالبًا إلى انهيار التمثيل الكامن (latent representation collapse)، مما يؤدي إلى تدهور الأداء التوليدي. وبدلاً من الاعتماد على بنيات هندسية تزداد تعقيدًا أو مخططات تدريب متعددة المراحل، يعالج TC-AE هذا التحدي من منظور مساحة الـ token، والتي تعد الجسر الأساسي بين البكسلات والتمثيلات الكامنة للصور، وذلك من خلال ابتكارين متكاملين:أولاً، قمنا بدراسة توسيع عدد الـ tokens عن طريق تعديل حجم الرقعة (patch size) في ViT ضمن ميزانية كامنة ثابتة، وحددنا أن الضغط الشديد من الـ token إلى التمثيل الكامن هو العامل الرئيسي الذي يحد من التوسع الفعال. ولمعالجة هذه المشكلة، قمنا بتفكيك عملية الضغط من الـ token إلى التمثيل الكامن إلى مرحلتين، مما يقلل من فقدان المعلومات الهيكلية ويسمح بتوسيع فعال لعدد الـ tokens لأغراض التوليد.ثانيًا، وللتخفيف بشكل أكبر من انهيار التمثيل الكامن، قمنا بتعزيز البنية الدلالية لـ image tokens عبر التدريب المشترك ذاتي الإشراف (joint self-supervised training)، مما يؤدي إلى تمثيلات كامنة أكثر ملاءمة للعمليات التوليدية.بفضل هذه التصميمات، يحقق TC-AE تحسنًا جوهريًا في أداء إعادة البناء والأداء التوليدي تحت ظروف الضغط العميق. ونأمل أن يساهم بحثنا في تطوير أدوات الترميز (tokenizer) القائمة على ViT المخصصة للتوليد البصري.
One-sentence Summary
TC-AE is a Vision Transformer-based architecture for deep compression autoencoders that addresses latent representation collapse by decomposing token-to-latent compression into two stages and employing joint self-supervised training to enhance semantic structure, thereby enabling effective token scaling and achieving superior reconstruction and generative performance.
Key Contributions
- The paper introduces TC-AE, a Vision Transformer-based architecture designed for deep compression autoencoders that optimizes the token space to prevent latent representation collapse.
- This work proposes a staged token compression strategy that redistributes the compression process across encoder stages to mitigate information loss and enable effective scaling of token numbers.
- The method incorporates a self-supervised joint training mechanism to enhance the semantic structure of image tokens, which results in improved reconstruction and generative performance on ImageNet.
Introduction
Latent diffusion models rely on tokenizers to compress images into efficient latent representations for generative modeling. While recent research pushes for deeper compression by reducing spatial resolution, existing methods often compensate by increasing channel numbers, which frequently leads to latent representation collapse and degraded generative performance. The authors leverage the token space as a critical bridge between pixels and latents to address these limitations. They introduce TC-AE, a ViT-based architecture that utilizes staged token compression to prevent structural information loss and incorporates a joint self-supervised training objective to enhance semantic structure. This approach enables effective token number scaling, significantly improving both reconstruction and generative quality under high compression ratios.
Method
The authors leverage a Vision Transformer (ViT)-based framework for image autoencoding, where an encoder E compresses an input image X∈RH×W×3 into a latent representation z∈Rh×w×c, which is subsequently reconstructed by a decoder D. The process begins with a patch embedding layer ϕp(⋅) that partitions the image into non-overlapping p×p patches, projects each patch into a d-dimensional vector, and flattens the grid into a sequence of N=HW/p2 tokens, T∈RN×d. These tokens are processed by a stack of Transformer layers TF(⋅) and then compressed by a bottleneck layer B(⋅) to produce the final latent representation. The spatial compression ratio from pixels to latent space decomposes into two stages: pixel-to-token compression fpix→tok=p2 and token-to-latent compression ftok→lat=N/(h⋅w), with the image tokens serving as an information bridge between the input and latent domains.
To enhance the semantic structure of the token space and improve generative performance, the authors introduce a joint self-supervised learning (SSL) objective using iBOT. This framework employs a student–teacher distillation paradigm, where the teacher is an exponential moving average (EMA) of the student. The student processes the input image through two augmentation pipelines: Augstu(⋅) generates global crops with random patch masking and additional local crops, while Augtea(⋅) produces two global crops. For masked global crops, the student is trained to predict the teacher's patch-token outputs, forming a masked image modeling objective LMIM. For local crops, the student's class-token predictions are aligned with the teacher's to enforce semantic consistency, yielding the class-token distillation loss L[CLS]. The combined self-supervised objective is LiBOT=LMIM+L[CLS], which encourages both local and global semantic structure in the token representation.
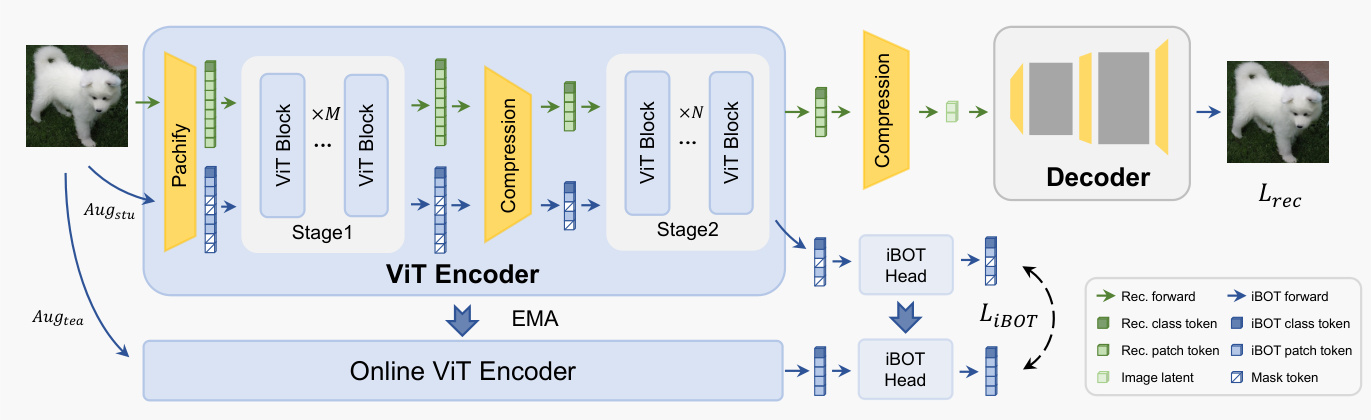
As shown in the figure below, the proposed TC-AE architecture consists of a ViT encoder, a latent bottleneck, and a structurally symmetric decoder. The encoder design incorporates staged token compression to mitigate structural information loss at the bottleneck. It begins with a patch embedding layer using a small patch size p to generate high-resolution image tokens, reducing information loss at the initial pixel-to-token stage. These fine-grained tokens are processed by the first M ViT blocks to capture rich visual details and semantic structure. An intermediate bottleneck then compresses the token sequence to one-fourth its length, producing a compact and structured intermediate representation. This compressed sequence is further processed by the remaining N ViT blocks, after which a second bottleneck yields the final latent representation for downstream generative modeling.
The training scheme of TC-AE jointly optimizes the tokenizer with the self-supervised objective, enabling the ViT encoder to learn latent representations with stronger semantic regularization without requiring external large-scale pretraining. This lightweight training approach contrasts with methods like VTP, making TC-AE practical under limited computational resources. The overall training objective combines the standard reconstruction loss with the self-supervised objective: LTC-AE=αLrec+LiBOT. The reconstruction loss Lrec is defined as Lpix+λpLp+λqLq, where Lpix is a pixel-level ℓ1 loss, Lp is a perceptual loss for high-level semantic discrepancies, and Lq is an adversarial loss to enhance the realism of reconstructed images. The combination of staged token compression and joint self-supervised training accelerates diffusion model convergence.
Experiment
The experiments evaluate how scaling token numbers and compression strategies affect the reconstruction and generative performance of deep compression autoencoders. While increasing image tokens improves reconstruction quality, it fails to enhance generative performance due to severe semantic information loss at the compression bottleneck. To resolve this, the authors propose staged token compression and self-supervised learning, which effectively preserve semantic structure and enable generative quality to scale with token density. These methods work synergistically to improve training efficiency and achieve superior generative results compared to existing tokenizers at a lower computational cost.
The authors analyze the impact of increasing image token numbers on reconstruction and generation quality under a fixed latent budget. Results show that while reconstruction improves with more tokens, generative performance does not, due to severe semantic information loss during bottleneck compression. Introducing staged token compression mitigates this loss, enabling better generative quality and scaling with token number. Increasing token numbers improves reconstruction but not generation due to semantic loss at the bottleneck. Staged token compression reduces structural information loss and enables generative performance to scale with token count. The proposed method achieves strong generative quality with fewer tokens and lower computational cost compared to existing approaches.
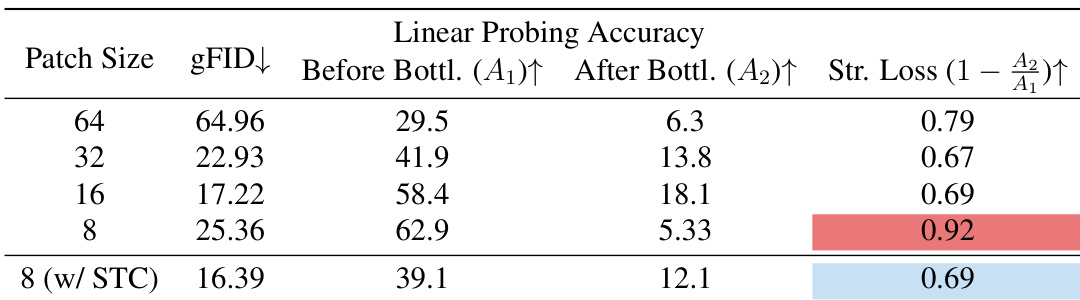
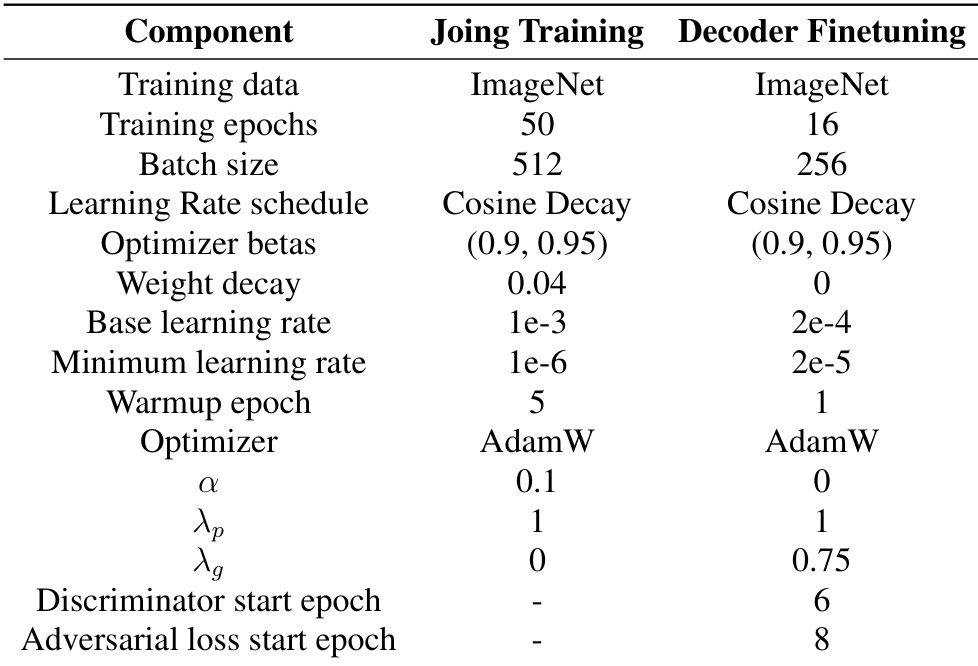
The the the table outlines the training settings for joint training and decoder finetuning in TC-AE. It specifies differences in epochs, batch size, learning rates, optimizers, and other hyperparameters between the two phases. Joint training uses more epochs and a larger batch size compared to decoder finetuning. The base learning rate is higher for joint training than for decoder finetuning. Different optimizers are used for joint training and decoder finetuning, with AdamW used in both cases.
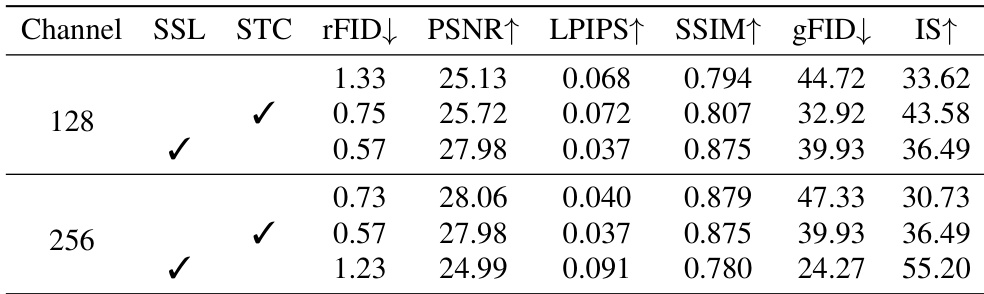
The authors compare the impact of latent channel dimensions on model performance, finding that increasing the channel size from 128 to 256 leads to mixed results. While some reconstruction metrics improve, generative performance degrades, suggesting that a higher channel dimension may exacerbate representation collapse. Increasing the latent channel dimension from 128 to 256 improves reconstruction quality but reduces generative performance. The trade-off between reconstruction fidelity and generatability is evident, with 128 channels providing better generative outcomes. Staged token compression and self-supervision improve performance across both channel sizes, but the benefits are more pronounced at 128 channels.
The authors compare TC-AE and DC-AE under identical settings, showing that TC-AE achieves better generative performance with significantly lower computational cost. Both models have the same latent shape, but TC-AE demonstrates superior results in both reconstruction and generation metrics. TC-AE achieves better generative performance than DC-AE with lower computational cost. Both models use the same latent shape, indicating a fair comparison. TC-AE shows improvements in both reconstruction and generation quality metrics compared to DC-AE.

The authors investigate the impact of increasing image token numbers on reconstruction and generative performance under a fixed latent budget. Results show that while reconstruction quality improves with more tokens, generative performance does not, due to severe semantic information loss during compression. Introducing staged token compression mitigates this loss and enables generative quality to scale with token count. Increasing token numbers improves reconstruction quality but not generative performance under a fixed latent budget. Staged token compression reduces semantic loss during compression, enabling generative performance to scale with token count. Self-supervision and staged token compression together enhance generative quality while maintaining reconstruction fidelity.
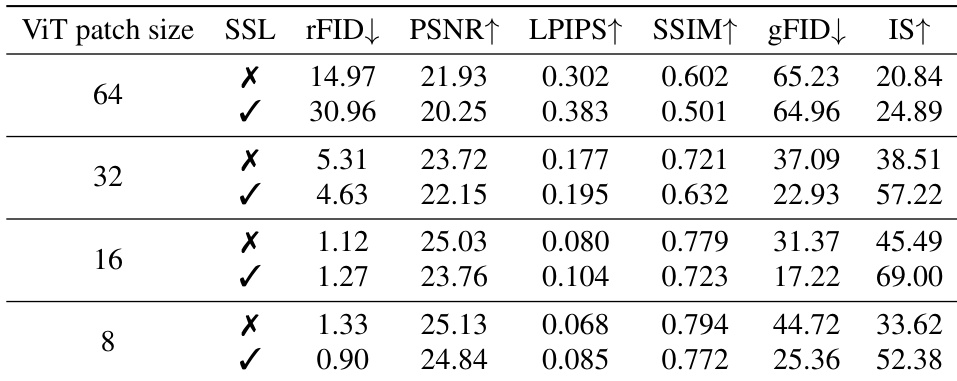
The authors evaluate the effects of token scaling, latent channel dimensions, and compression strategies on reconstruction and generative performance. While increasing token counts or channel dimensions can improve reconstruction, they often lead to semantic loss or representation collapse that degrades generative quality. By implementing staged token compression and self-supervision, the proposed TC-AE model effectively mitigates these issues, achieving superior generative performance and higher computational efficiency compared to DC-AE.