Command Palette
Search for a command to run...
RefineAnything: تحسين متعدد الوسائط خاص بالمناطق للحصول على تفاصيل محلية مثالية
RefineAnything: تحسين متعدد الوسائط خاص بالمناطق للحصول على تفاصيل محلية مثالية
Dewei Zhou You Li Zongxin Yang Yi Yang
الملخص
نقدم في هذا البحث "تحسين الصور الخاص بمنطقة محددة" (region-specific image refinement) كإطار عمل مخصص لمشكلة تقنية: حيث يكون الهدف، بناءً على صورة مدخلة ومنطقة يحددها المستخدم (مثل قناع خربشة scribble mask أو مربع إحاطة bounding box)، هو استعادة التفاصيل الدقيقة مع الحفاظ على جميع البكسلات غير المعدلة دون أي تغيير. وعلى الرغم من التقدم السريع في مجال توليد الصور، لا تزال النماذج الحديثة تعاني بشكل متكرر من "انهيار التفاصيل المحلية" (local detail collapse)، مثل تشوه النصوص، والشعارات، والهياكل الدقيقة. وتُركز نماذج التحرير الحالية القائمة على التعليمات (instruction-driven editing models) على التعديلات الدلالية خشنة الحبيبات (coarse-grained semantic edits)، وغالباً ما تتجاهل العيوب المحلية الدقيقة أو تغير الخلفية عن غير قصد، خاصة عندما تشغل المنطقة المستهدفة جزءاً صغيراً فقط من صورة مدخلة ذات دقة ثابتة.نقدم RefineAnything، وهو نموذج تحسين متعدد الوسائط يعتمد على الـ diffusion، ويدعم كلاً من التحسين القائم على المرجع (reference-based) والتحسين المستقل عن المرجع (reference-free). وبناءً على ملاحظة غير بديهية مفادها أن عملية "القص وإعادة التحجيم" (crop-and-resize) يمكن أن تحسن بشكل كبير إعادة البناء المحلي تحت دقة مدخلات ثابتة لـ VAE، نقترح استراتيجية Focus-and-Refine؛ وهي استراتيجية تركز على المنطقة عبر "التحسين ثم إعادة اللصق" (refinement-and-paste-back)، والتي تزيد من فعالية وكفاءة التحسين من خلال إعادة تخصيص ميزانية الدقة (resolution budget) للمنطقة المستهدفة، بينما تضمن عملية إعادة اللصق باستخدام "القناع الممزوج" (blended-mask) الحفاظ الصارم على الخلفية. علاوة على ذلك، نقدم "فقد الاتساق الحدودي" (Boundary Consistency Loss) المدرك للحدود لتقليل عيوب الفواصل (seam artifacts) وتحسين طبيعية عملية إعادة اللصق.ولدعم هذا الإطار الجديد، قمنا ببناء مجموعة بيانات Refine-30K (تتكون من 20 ألف عينة قائمة على المرجع و10 آلاف عينة مستقلة عن المرجع)، وقدمنا RefineEval، وهو benchmark يقيم كلاً من دقة المنطقة المعدلة واتساق الخلفية. وعلى اختبار RefineEval، حقق RefineAnything تحسينات قوية مقارنة بالنماذج المنافسة (baselines) مع الحفاظ شبه المثالي على الخلفية، مما يضع حلاً عملياً للتحسين المحلي عالي الدقة.صفحة المشروع: https://limuloo.github.io/RefineAnything/
One-sentence Summary
The authors propose RefineAnything, a multimodal diffusion-based model for high-precision, region-specific image refinement that utilizes a Focus-and-Refine strategy and a Boundary Consistency Loss to restore local details while ensuring strict background preservation, outperforming competitive baselines on the newly introduced RefineEval benchmark.
Key Contributions
- The paper presents RefineAnything, a multimodal diffusion-based refinement model designed for both reference-based and reference-free tasks to restore fine-grained local details.
- The authors introduce the Focus-and-Refine strategy, which reallocates resolution to a target region through a crop-and-resize approach and uses a blended-mask paste-back method to ensure strict background preservation.
- This work contributes a boundary-aware Boundary Consistency Loss to minimize seam artifacts and provides Refine-30K and RefineEval, a new benchmark for evaluating edited-region fidelity and background consistency.
Introduction
While modern diffusion models have achieved significant progress in high-fidelity image generation, they frequently suffer from local detail collapse, resulting in distorted text, logos, and thin structures. Existing instruction-driven editing models typically focus on coarse-grained semantic changes and often fail to address subtle local defects or inadvertently alter the background when editing small regions. To address these issues, the authors introduce RefineAnything, a multimodal diffusion-based framework designed for region-specific refinement. The authors leverage a Focus-and-Refine strategy that concentrates model capacity on user-specified areas to restore fine-grained details while ensuring strict background preservation through a specialized boundary-aware loss.
Dataset
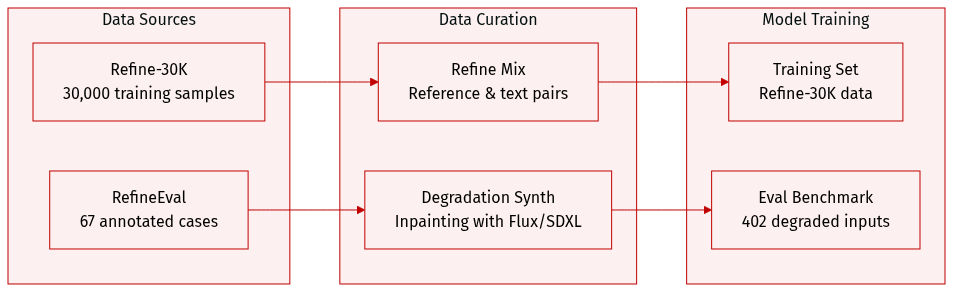
The authors introduce two distinct datasets to support the training and evaluation of the RefineAnything model:
-
Refine-30K (Training Dataset): This dataset contains 30,000 samples divided into two specific subsets:
- Reference-based refine pairs (20,000 samples): These samples provide the model with both a refinement instruction and a reference image to guide the visual style and appearance.
- Reference-free refine samples (10,000 samples): These instruction-only samples require the model to perform refinements based solely on text specifications.
-
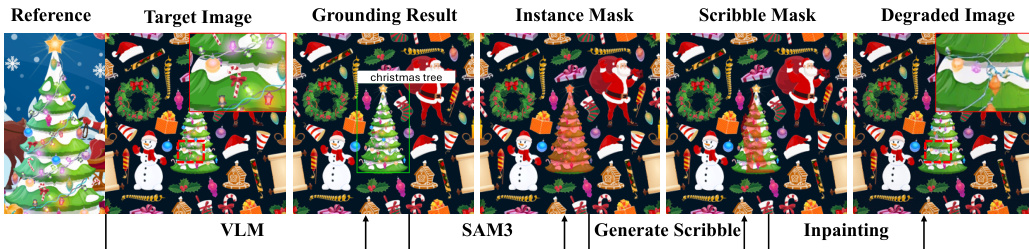
RefineEval (Evaluation Benchmark): A curated benchmark consisting of 402 degraded inputs derived from 67 manually annotated cases. The benchmark is structured as follows:
- Composition: It includes 31 reference-based cases focusing on identity-sensitive content like logos and person IDs, and 36 reference-free cases covering generic objects, faces, and human bodies.
- Data Synthesis: For each case, the authors use inpainting via Flux-fill, SDXL, and Qwen-Edit to create degraded inputs within localized edit regions.
- Processing Pipeline: To ensure variety, the authors generate candidates using five random scribble masks across three different seeds for each inpainting method. They then manually select two representative degraded images per method to form the final evaluation set.
Method
The authors leverage a multimodal diffusion framework for localized image refinement, built upon the Qwen-Image architecture. The overall system, as illustrated in the framework diagram, consists of three primary components: a frozen multimodal encoder, a variational autoencoder (VAE), and a trainable diffusion backbone. The framework accepts an input image I, an optional reference image Iref, a user-provided scribble mask M indicating the edit region, and a text instruction y. The first component is a frozen Qwen2.5-VL encoder, which processes the input image, reference image (if provided), the scribble mask, and the text instruction to generate high-level multimodal conditioning tokens c. These tokens, defined by the equation c=Eϕ(I,Iref,M,y), capture the semantic and instructional intent of the task and are used to guide the denoising process through joint-attention mechanisms.
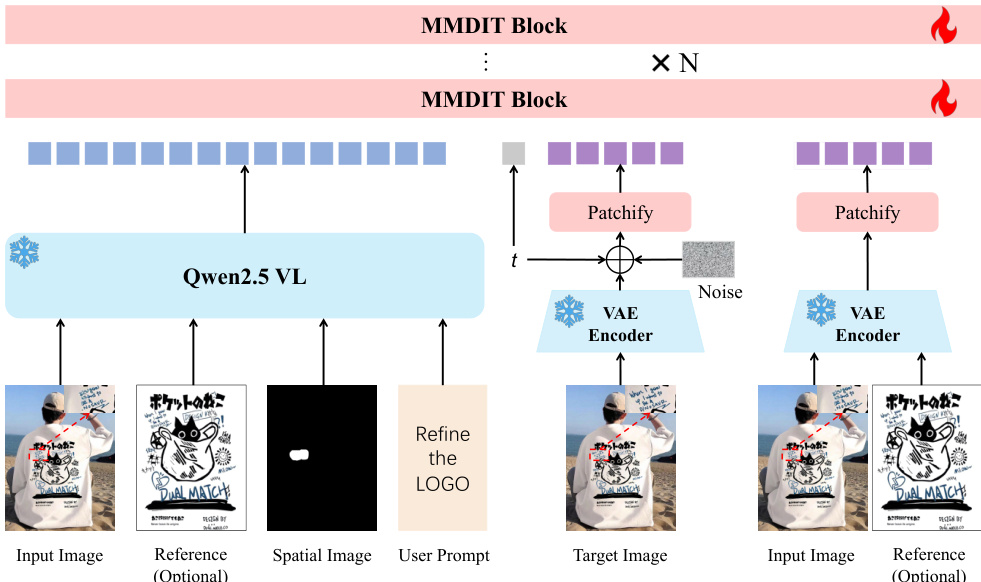
The second component is a VAE that encodes the input and optional reference images into latent representations zI and zref. These VAE latents provide low-level, fine-grained visual context, which is crucial for preserving the structural details of the image. During training, these latent representations are packed alongside the noisy target latent zt into patch token sequences and concatenated along the sequence dimension before being fed into the diffusion backbone.
The third component is the denoising backbone, which is built from MMDiT blocks, as shown in the framework diagram. This backbone iteratively removes noise from the target latent zt conditioned on both the multimodal tokens c and the VAE latent branches. At inference, the process begins with a noise latent zT, which is progressively denoised under a scheduler to produce z0. The final output image I is obtained by decoding z0 using the VAE decoder. The conditioning on the scribble mask M ensures that the refinement is localized to the specified region while the rest of the image is preserved.
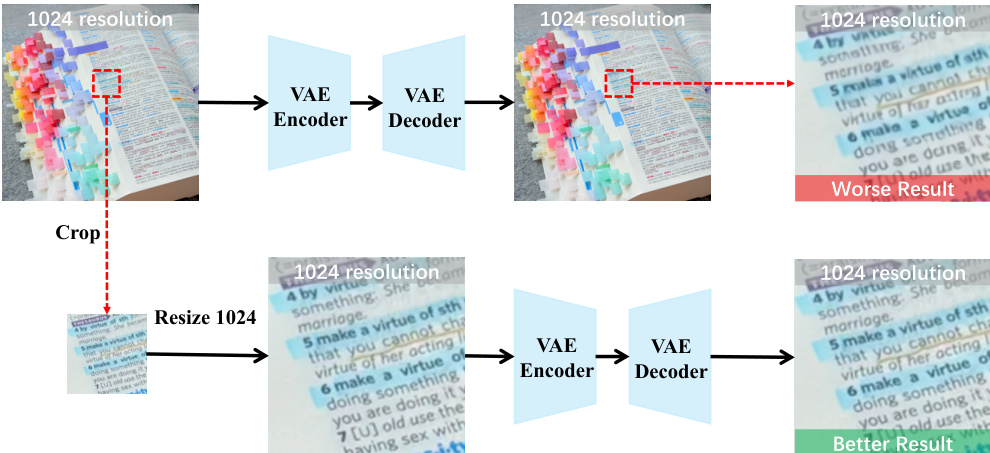
To address the challenge of limited resolution budget in local refinement, the authors introduce a Focus-and-Refine method. This method, illustrated in the overview diagram, consists of three stages. First, the region of interest is localized by computing a tight bounding box around the scribble mask and expanding it with a margin to create a focus crop. Second, the model performs focused generation on the cropped view, using the cropped scribble mask as a spatial cue and conditioning on the input, reference, and text instruction. This focused generation step is performed using the RefineAnything Model, which is the same architecture shown in the framework diagram. Third, to avoid visible seams, the refined crop is seamlessly pasted back into the original image using a blended mask. This blended mask is created by applying morphological dilation and Gaussian smoothing to the cropped mask, which is then used to composite the refined result with the original image.
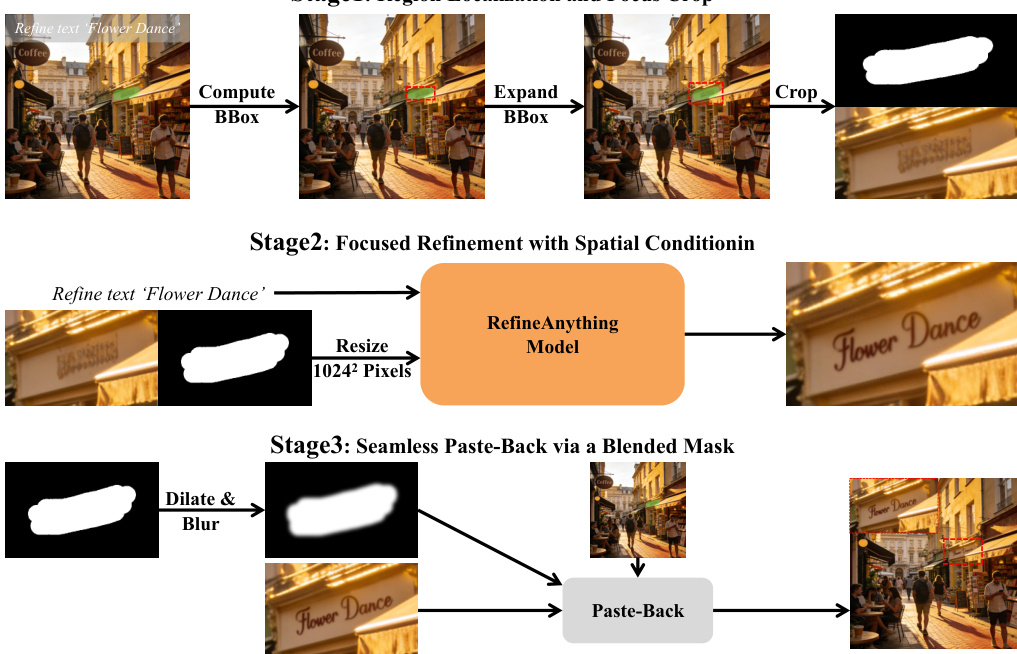
To further enhance the naturalness of the paste-back, the authors employ a boundary consistency loss during training. This loss upweights supervision near the edit boundary to ensure smooth transitions. A boundary band Bc is defined by dilating the cropped mask and eroding it, and this band is used to weight the base loss map, which is the mean squared error between the predicted and target velocities in the latent space. The overall training objective is the expected value of the boundary-weighted loss.
Experiment
The evaluation utilizes the RefineEval benchmark to assess both reference-based and reference-free image refinement across metrics for edited-region fidelity and background preservation. Experiments validate the effectiveness of the Focus-and-Refine strategy and the Boundary Consistency Loss through ablation studies and comparisons with competitive baselines. Results demonstrate that the proposed method significantly improves local detail recovery and semantic alignment while maintaining near-perfect background consistency and seamless boundaries.
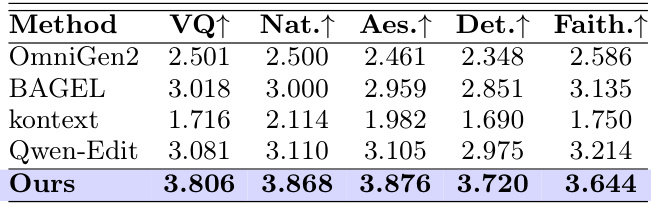
The authors evaluate their method against baselines on reference-free image refinement using a multi-dimensional scoring system. Results show that their approach achieves superior performance across all evaluation dimensions, outperforming existing models in visual quality, naturalness, aesthetics, detail fidelity, and instruction faithfulness. Our method outperforms all baselines on visual quality, naturalness, aesthetics, detail fidelity, and instruction faithfulness. The approach achieves the highest scores in all five evaluation dimensions compared to existing models. Results demonstrate strong performance in generating refined images that are both detailed and faithful to the input instructions.
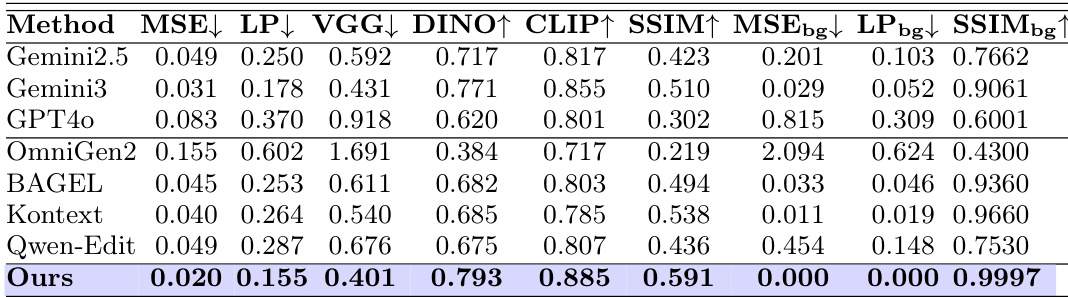
The authors evaluate their method against baselines on reference-based image refinement, focusing on region fidelity and background consistency. Results show that their approach achieves the best performance across multiple metrics, particularly in preserving the background and improving local detail accuracy. The proposed method outperforms baselines in both region fidelity and background preservation. It achieves near-perfect background consistency with minimal reconstruction errors. The method improves local detail recovery while maintaining strict background unchanged.

The authors evaluate their method against several baselines on reference-based image refinement, measuring both edited-region fidelity and background preservation. Results show that their approach achieves the best performance across multiple metrics, particularly in maintaining background consistency and improving local detail quality. Our method achieves the lowest error metrics for edited-region fidelity, including MSE and LPIPS. It maintains near-perfect background consistency, with minimal changes to non-target regions. The approach outperforms all baselines in both region fidelity and background preservation, demonstrating superior overall performance.
The authors evaluate their method through both reference-free and reference-based image refinement setups to assess visual quality and structural integrity. In reference-free scenarios, the approach demonstrates superior instruction faithfulness and aesthetic naturalness compared to existing baselines. For reference-based tasks, the method excels at recovering local details while maintaining near-perfect background consistency and region fidelity.