Command Palette
Search for a command to run...
MinerU2.5-Pro: دفع حدود تحليل المستندات المرتكز على البيانات على نطاق واسع
MinerU2.5-Pro: دفع حدود تحليل المستندات المرتكز على البيانات على نطاق واسع
الملخص
تتنافس طرق تحليل المستندات الحالية بشكل أساسي على ابتكار بنية النماذج (model architecture)، بينما لا تزال الهندسة المنهجية لبيانات التدريب غير مستكشفة بشكل كافٍ. ومع ذلك، تظهر نماذج SOTA ذات البنيات وأحجام المعلمات (parameter scales) المختلفة أنماط فشل متسقة للغاية عند اختبارها على نفس مجموعة العينات الصعبة، مما يشير إلى أن عنق الزجاجة في الأداء ينبع من أوجه القصور المشتركة في بيانات التدريب وليس من البنية نفسها.بناءً على هذه النتيجة، نقدم minerupro، الذي يحقق تقدماً في حالة الفن (state of the art) من خلال هندسة البيانات وتحسين استراتيجية التدريب فقط، مع الإبقاء على بنية mineru ذات الـ 1.2B parameter ثابتة تماماً. يعتمد المشروع في جوهره على محرك بيانات (Data Engine) صُمم بشكل مشترك ليركز على الشمولية، والمعلوماتية، ودقة التوسيم (annotation accuracy):أخذ العينات المدرك للتنوع والصعوبة (Diversity-and-Difficulty-Aware Sampling): يعمل على توسيع بيانات التدريب من أقل من 10 ملايين إلى 65.5 مليون عينة، مع تصحيح انزياح التوزيع (distribution shift).التحقق من الاتساق عبر النماذج (Cross-Model Consistency Verification): يستفيد من توافق المخرجات بين النماذج غير المتجانسة لتقييم صعوبة العينات وتوليد annotations موثوقة.خط معالجة الـ Judge-and-Refine pipeline: يعمل على تحسين جودة الـ annotation للعينات الصعبة من خلال عملية تصحيح تكرارية تعتمد على "الصيرورة ثم التحقق" (render-then-verify).تتبع عملية التدريب استراتيجية تدريب تدريجية من ثلاث مراحل: التدريب المسبق واسع النطاق (large-scale pre-training)، والضبط الدقيق للعينات الصعبة (hard sample fine-tuning)، ومحاذاة GRPO (GRPO alignment)، حيث يتم استغلال هذه البيانات بالتتابع عبر مستويات جودة مختلفة.وعلى صعيد التقييم، قمنا بمعالجة انحيازات مطابقة العناصر (element-matching biases) في OmniDocBench v1.5، وقدمنا مجموعة فرعية صعبة (Hard subset)، مما أدى إلى تأسيس بروتوكول OmniDocBench v1.6 الأكثر قدرة على التمييز. وبدون أي تعديل في البنية، حقق minerupro نتيجة 95.69 على OmniDocBench v1.6، متفوقاً على النموذج المرجعي (baseline) ذو البنية نفسها بمقدار 2.71 نقطة، ومتجاوزاً جميع الطرق الحالية بما في ذلك النماذج التي تمتلك معلمات أكثر بـ 200 مرة.
One-sentence Summary
By utilizing a Data Engine comprising Diversity-and-Difficulty-Aware Sampling, Cross-Model Consistency Verification, and a Judge-and-Refine pipeline alongside a three-stage progressive training strategy, MinerU2.5-Pro advances the state of the art in document parsing by expanding training data from under 10M to 65.5M samples and achieving a score of 95.69 on the newly established OmniDocBench v1.6 benchmark, all while keeping the 1.2B-parameter architecture of MinerU2.5 completely fixed.
Key Contributions
- The paper introduces MinerU2.5-Pro, a document parsing model that achieves state-of-the-art performance by focusing on systematic data engineering and training strategy optimization rather than architectural changes. By keeping the 1.2B-parameter architecture fixed, the method improves the OmniDocBench v1.6 score to 95.69, surpassing existing models with significantly larger parameter counts.
- A specialized Data Engine is presented to expand training data from under 10M to 65.5M samples through diversity-aware sampling, cross-model consistency verification for reliable annotations, and a judge-and-refine pipeline for iterative error correction. This engine is paired with a three-stage progressive training strategy that sequentially utilizes large-scale pre-training, hard sample fine-tuning, and GRPO alignment to exploit different data quality tiers.
- The work establishes the OmniDocBench v1.6 evaluation protocol, which incorporates Multi-Granularity Adaptive Matching to eliminate element-matching biases and introduces a dedicated Hard subset to better differentiate model performance. This updated benchmark provides a more discriminative assessment of parsing capabilities compared to previous versions.
Introduction
Document parsing is a critical component for building LLM training pipelines and retrieval-augmented generation systems by converting unstructured PDFs into machine-readable formats like Markdown. While research has traditionally focused on architectural innovation and inference efficiency, the authors observe that state-of-the-art models across different scales exhibit consistent failure patterns on the same hard samples. This suggests that the primary performance bottleneck is not model architecture, but rather shared deficiencies in training data, specifically regarding insufficient coverage of long-tail scenarios and unreliable automatic annotations for complex structures.
The authors leverage a data-centric approach to develop MinerU2.5-Pro, achieving significant performance gains without modifying the underlying 1.2B-parameter architecture. They introduce a comprehensive Data Engine that utilizes diversity-and-difficulty-aware sampling and cross-model consistency verification to expand the training set from 10M to 65.5M samples. To resolve annotation noise in difficult cases, they implement a Judge-and-Refine pipeline that uses a render-then-verify mechanism to improve structural accuracy. Additionally, the authors contribute OmniDocBench v1.6, an upgraded evaluation protocol that corrects element-matching biases and introduces a dedicated hard subset to provide more discriminative benchmarking.
Dataset
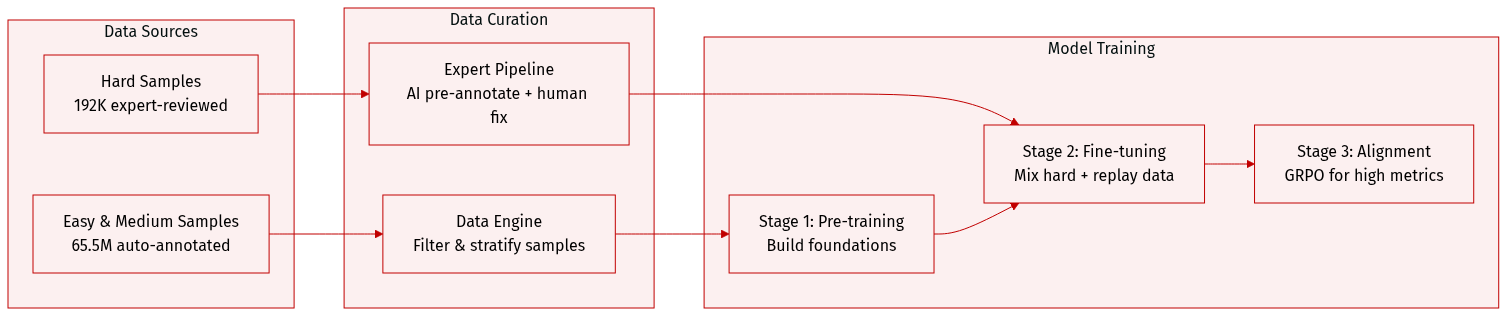
The authors utilize a multi-stage data engine to construct a stratified dataset designed for progressive model training. The dataset composition and usage are summarized below:
-
Dataset Composition and Sources
- Easy and Medium Samples: Approximately 65.5M samples generated via the Data Engine. These are automatically annotated using a CMCV (multi-model consensus) approach and include text recognition (21M), layout analysis (14M), formula recognition (13M), table recognition (11.5M), and image analysis (6M).
- Hard Samples: 192K high-quality samples that undergo a specialized expert annotation pipeline. This pipeline uses Gemini 3 Pro for AI pre-annotation followed by expert review and correction to ensure ground truth quality.
- Hard Evaluation Subset: A separate set of 296 pages covering complex scenarios like nested tables and dense formulas. This subset is strictly excluded from all training stages to ensure unbiased evaluation.
-
Data Processing and Filtering
- Difficulty Stratification: The authors use DDAS sampling and CMCV difficulty stratification to categorize samples.
- Refinement Workflow: A Judge-and-Refine process is used to correct annotations. For samples where automatic correction fails, expert human annotation is prioritized for high-confidence error locations and subtask categories where the model shows the most weakness.
- Quality Assurance: Automated QA tools and inter-annotator cross-validation are employed to maintain annotation consistency.
-
Training Strategy and Mixture Ratios
- Stage 1 (Pre-training): Uses the 65.5M Easy and Medium samples to build foundational capabilities.
- Stage 2 (Supervised Fine-Tuning): Focuses on hard scenarios by mixing the 192K expert-annotated Hard samples with Stage 1 replay data to prevent catastrophic forgetting. The mixing ratio (Hard to Replay) is customized per subtask: layout analysis (6:1), image analysis (1:4), table recognition (1:10), formula recognition (1:25), and text recognition (1:50).
- Stage 3 (Alignment): Utilizes the expert-annotated Hard samples for GRPO alignment to achieve metric-level performance.
Method
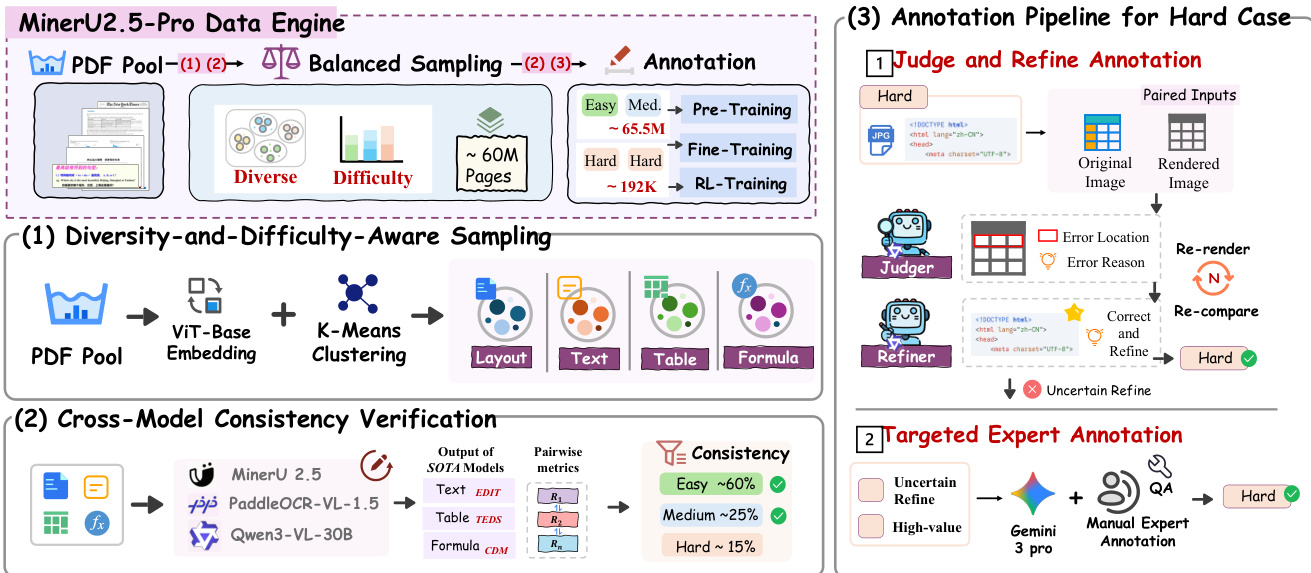
The authors leverage a co-designed Data Engine to systematically expand training data from under 10 million pages to 65.5 million while improving annotation quality through a closed-loop progression. The framework is built around three core dimensions: coverage, informativeness, and annotation accuracy, and comprises four synergistic components: Diversity-and-Difficulty-Aware Sampling (DDAS), Cross-Model Consistency Verification (CMCV), and a Judge-and-Refine annotation pipeline, with samples exceeding automatic correction capability routed to expert annotation. The overall pipeline is illustrated in the framework diagram.
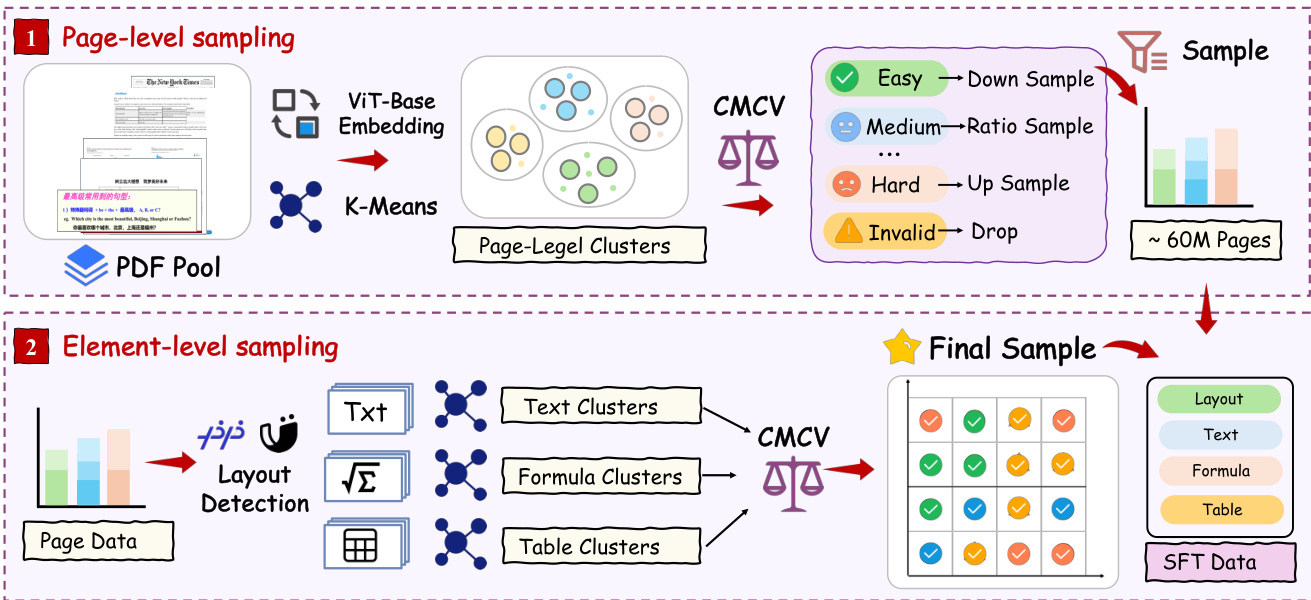
The first component, DDAS, operates at two granularity levels to balance diversity and difficulty. At the page level, visual features extracted via ViT-base are clustered using K-Means, and initial sampling is performed uniformly across cluster centers. The resulting candidate set undergoes page-level CMCV to obtain difficulty labels, which are then used to adjust sampling weights—clusters with diverse difficulty distributions are upweighted, while those dominated by easy or invalid content are downweighted or filtered. This yields a page-level candidate set with balanced difficulty coverage. At the element level, the selected pages are parsed into text, formula, and table blocks using layout detection models. For each element type, independent clustering is performed, and block-level CMCV is run to obtain difficulty labels. The final sampling combines these two levels by performing balanced sampling in the joint cluster-difficulty space across all four subtasks: layout, text, formula, and table. This process corrects long-tail distribution shifts and upweights medium and hard samples to enhance training signal informativeness. As shown in the figure below, the DDAS pipeline operates at both page-level and element-level granularity, with the two levels combined to produce the final training data for all subtasks.
The second component, CMCV, enables difficulty assessment on massive unlabeled data without human annotation by extending difficulty estimation from single-model introspection to multi-model cross-validation. The underlying assumption is that consistent outputs from multiple heterogeneous models indicate a correct result, while substantial disagreement signifies a genuinely difficult sample. The authors run K heterogeneous SOTA models—MinerU2.5, PaddleOCR-VL, and Qwen3-VL-30B—on candidate data from DDAS, computing task-specific pairwise consistency metrics: edit distance for text, TEDS for tables, and CDM for formulas. Samples are classified into three difficulty tiers based on consistency patterns: Easy (MinerU2.5's output is consistent with at least one external model), Medium (external models agree but MinerU2.5 differs), and Hard (all models disagree). This distinction is critical for annotation strategy design, as Easy data forms the foundation, Medium data pinpoints the model's capability gaps, and Hard data requires further refinement or expert annotation. The CMCV process is illustrated in the figure below, showing the flow from model outputs to consistency metrics and difficulty classification.

The third component, the Judge-and-Refine annotation pipeline, improves annotation accuracy for hard samples through a render-then-verify iterative correction process. For hard samples, the original image is rendered into a high-fidelity version, which is then compared with the model's output to identify errors. The model is then refined based on the identified error locations and reasons. If the refinement is successful, the sample is marked as correct and refined; otherwise, it is routed to targeted expert annotation. This process is illustrated in the figure below, showing the flow from paired inputs to the judge and refiner, and the iterative correction process.

The authors also introduce a three-stage progressive training strategy matched to the data quality tiers produced by the Data Engine. The model, initialized from MinerU2.5's Stage 0 checkpoint, undergoes large-scale pre-training on CMCV auto-annotated data to build foundational capabilities. This is followed by high-quality hard sample fine-tuning on expert-annotated data to strengthen performance on challenging scenarios. The final stage aligns output format and structural conventions through reinforcement learning with Group Relative Policy Optimization (GRPO). This stage directly optimizes task-level metrics—edit distance for text, CDM for formulas, TEDS for tables, and category IoU for layout detection—by sampling G groups of candidate outputs, computing rewards based on these metrics, and updating the policy using within-group relative advantages. The training data is generated from Stage 2 model rollouts and filtered to retain mid-reward samples, ensuring reliable policy gradients. The training configuration is summarized in Table 1. The authors also propose Multi-Granularity Adaptive Matching (MGAM) to eliminate matching bias in evaluation by adaptively adjusting segmentation granularity on the prediction side, ensuring fairer and more discriminative evaluation. The overall framework and key components are illustrated in the figure below.
Experiment
The experiments evaluate MinerU2.5-Pro against specialized document parsing models and general-purpose VLMs using the OmniDocBench v1.6 benchmark, which includes both standard and challenging subsets. Results demonstrate that the proposed data engine and progressive training strategy significantly enhance robustness in complex scenarios, particularly for the table, formula, and reading order recognition. The model achieves superior performance in end-to-end parsing and element-specific tasks, outperforming larger general-purpose models while maintaining high accuracy on difficult structural elements like rotated tables and multi-line formulas.
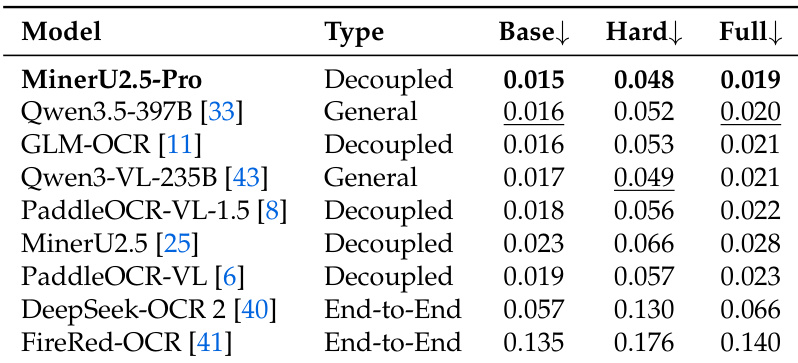
The authors compare text recognition performance across multiple models using edit distance metrics on the Base, Hard, and Full subsets of OmniDocBench v1.6. Results show that MinerU2.5-Pro achieves the best performance on the Base subset, while general-purpose models like Qwen3.5-397B perform competitively, and end-to-end models exhibit significantly lower performance. MinerU2.5-Pro achieves the best text recognition performance on the Base subset. General-purpose models show competitive performance, while end-to-end models perform substantially worse. Performance varies significantly across subsets, with higher error rates on the Hard and Full subsets compared to the Base subset.
The authors evaluate MinerU2.5-Pro against general-purpose VLMs and specialized document parsing models on OmniDocBench v1.6, using a three-tier evaluation protocol. Results show that MinerU2.5-Pro achieves top performance on the Full and Hard subsets, demonstrating significant improvements over its baseline and strong robustness in challenging scenarios. MinerU2.5-Pro leads on the Hard subset, showing superior robustness compared to other models. The model achieves the best scores in formula and the the table recognition, particularly on complex and hard scenarios. The performance gain over the baseline is attributed to data engineering and training strategy optimization, not model architecture changes.

The authors evaluate MinerU2.5-Pro and other models on OmniDocBench v1.6 across multiple subsets and benchmarks. Results show that MinerU2.5-Pro achieves top performance on several tasks, particularly in formula and the the table recognition, while also demonstrating strong robustness on hard scenarios compared to other models. MinerU2.5-Pro achieves the highest scores on multiple benchmarks, including CPE and SPC, indicating strong performance in formula recognition. MinerU2.5-Pro shows superior robustness on hard subsets, maintaining high performance compared to other models that exhibit significant drops. The model excels in the the table recognition, achieving top scores on both Base and Hard subsets, outperforming specialized and general-purpose models.
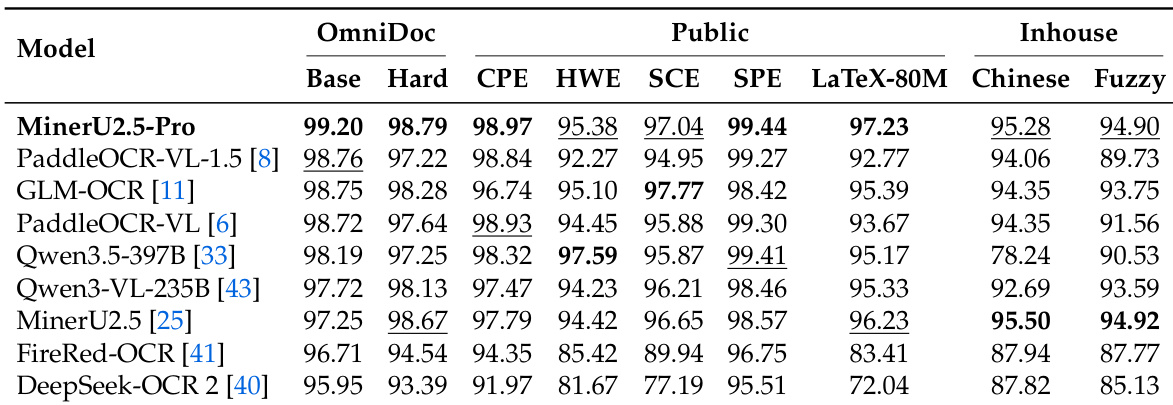
The authors evaluate MinerU2.5-Pro on OmniDocBench v1.6 using a three-tier protocol, comparing it against general-purpose VLMs and specialized document parsing models. Results show that MinerU2.5-Pro achieves top performance on the Full and Hard subsets, demonstrating strong robustness and competitive accuracy in formula and the the table recognition. The progressive training strategy contributes incrementally to performance, with each stage improving specific sub-metrics. MinerU2.5-Pro achieves top performance on the Full and Hard subsets, demonstrating strong robustness in challenging scenarios. The model excels in formula and the the table recognition, with significant improvements over the baseline in key sub-metrics. Each training stage contributes incrementally to performance, with the Data Engine and reinforcement learning playing key roles in enhancing accuracy.
The authors evaluate MinerU2.5-Pro against various document parsing models and general-purpose VLMs on OmniDocBench v1.6, using a three-tier protocol that includes Base, Hard, and Full subsets. Results show that MinerU2.5-Pro achieves the highest overall score and leads in multiple sub-metrics, particularly in formula and the the table recognition, demonstrating strong performance on both standard and challenging scenarios. MinerU2.5-Pro achieves the highest overall score and leads in formula and the the table recognition metrics. The model shows strong performance on the Hard subset, outperforming several specialized models. MinerU2.5-Pro demonstrates robustness, with a smaller performance drop from Base to Hard compared to other models.
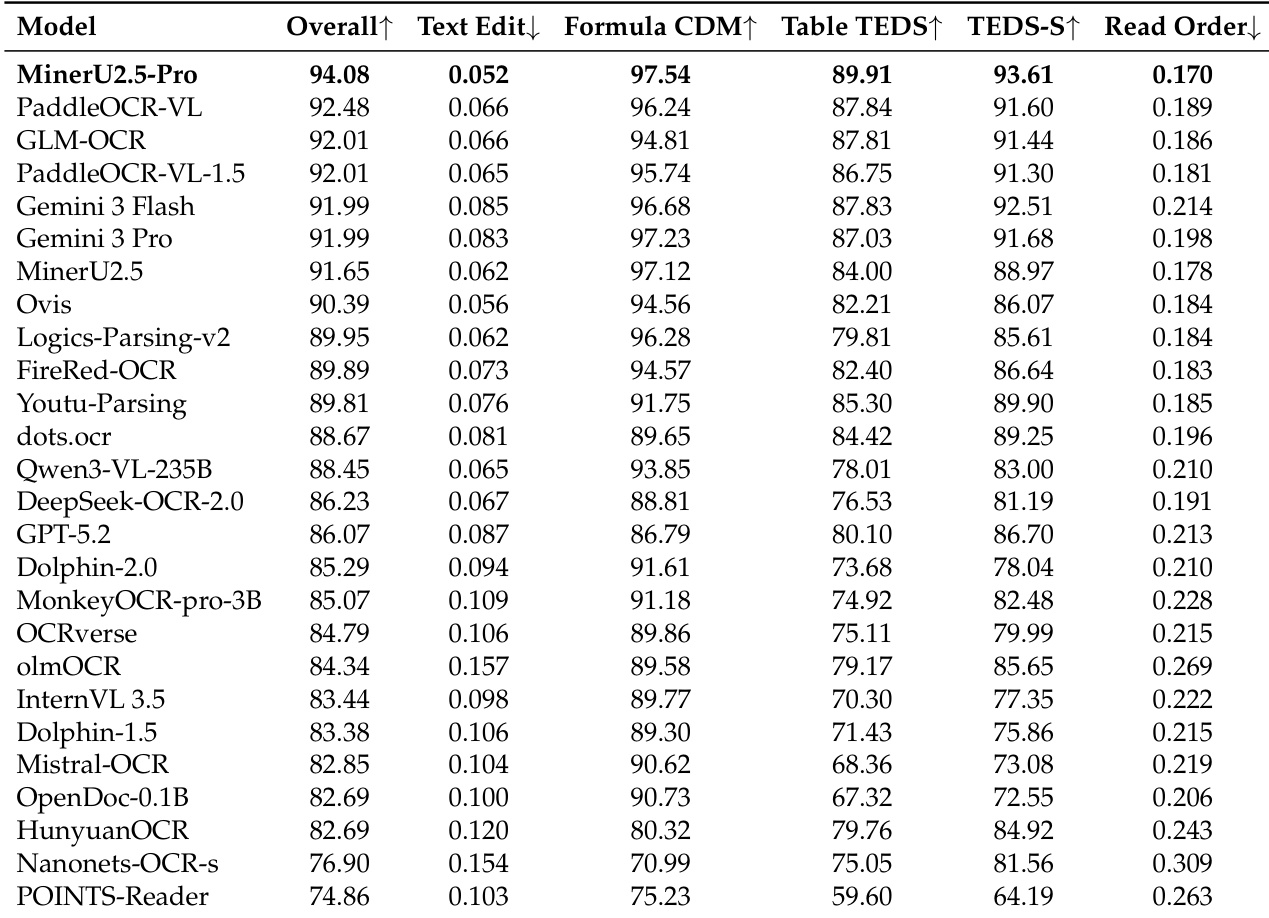
The authors evaluate MinerU2.5-Pro against general-purpose VLMs and specialized document parsing models using the multi-tiered OmniDocBench v1.6 benchmark. The experiments validate the model's text recognition, formula, and the table parsing capabilities across varying levels of difficulty. Results demonstrate that MinerU2.5-Pro achieves superior performance and maintains greater robustness in challenging scenarios compared to other models. These improvements are primarily attributed to optimized data engineering and progressive training strategies rather than changes in model architecture.