Command Palette
Search for a command to run...
وكيل ذكاء الذاكرة (Memory Intelligence Agent)
وكيل ذكاء الذاكرة (Memory Intelligence Agent)
Jingyang Qiao Weicheng Meng Yu Cheng Zhihang Lin Zhizhong Zhang Xin Tan Jingyu Gong Kun Shao Yuan Xie
الملخص
إليك الترجمة الاحترافية للنص إلى اللغة العربية، مع مراعاة المعايير التقنية والأكاديمية المذكورة:تدمج وكلاء البحث العميق (Deep Research Agents - DRAs) بين قدرات الاستدلال الخاصة بـ LLM والأدوات الخارجية. وتتيح أنظمة الذاكرة لهذه الوكلاء الاستفادة من الخبرات التاريخية، وهو أمر ضروري لعمليات الاستدلال الفعالة والتطور الذاتي المستقل. تعتمد المنهجيات الحالية على استرجاع مسارات (trajectories) مماثلة من الذاكرة للمساعدة في الاستدلال، إلا أنها تعاني من قيود جوهرية تتمثل في عدم فعالية تطور الذاكرة، وارتفاع تكاليف التخزين والاسترجاع.ولمعالجة هذه المشكلات، نقترح إطار عمل مبتكر يُسمى وكيل الذكاء الذاكري (Memory Intelligence Agent - MIA)، والذي يتكون من بنية تعتمد على "المدير-المخطط-المنفذ" (Manager-Planner-Executor). يعمل "مدير الذاكرة" (Memory Manager) كنظام ذاكرة غير معلمي (non-parametric memory system) يمكنه تخزين مسارات البحث التاريخية المضغوطة. أما "المخطط" (Planner) فهو وكيل ذاكرة معلمي (parametric memory agent) قادر على وضع خطط بحث للأسئلة المطروحة. بينما يمثل "المنفذ" (Executor) وكيلاً آخر يمكنه البحث في المعلومات وتحليلها مسترشداً بخطة البحث.لبناء إطار عمل MIA، اعتمدنا أولاً نموذج تعلم تعزيزي متبادل (alternating reinforcement learning paradigm) لتعزيز التعاون بين الـ Planner والـ Executor. علاوة على ذلك، مكنّا الـ Planner من التطور المستمر أثناء عملية التعلم في وقت الاختبار (test-time learning)، حيث يتم إجراء التحديثات بشكل فوري (on-the-fly) بالتزامن مع عملية الاستدلال (inference) دون مقاطعة عملية الاستدلال نفسها. بالإضافة إلى ذلك، أنشأنا حلقة تحويل ثنائية الاتجاه بين الذاكرة المعلمية (parametric memory) وغير المعلمية (non-parametric memory) لتحقيق تطور فعال للذاكرة. وأخيراً، دمجنا آليات للتفكير (reflection) والتقييم غير الخاضع للإشراف (unsupervised judgment) لتعزيز قدرات الاستدلال والتطور الذاتي في العالم المفتوح.أظهرت التجارب المكثفة عبر أحد عشر benchmark تفوق إطار MIA؛ فأولاً، يعزز MIA بشكل كبير أداء نماذج LLM الحالية (SOTA) في مهام البحث العميق. فعلى سبيل المثال، ساهم MIA في رفع أداء GPT-5.4 بنسبة تصل إلى 9% و6% في LiveVQA وHotpotQA على التوالي. علاوة على ذلك، وباستخدام Executor خفيف الوزن مثل Qwen2.5-VL-7B، استطاع MIA تحقيق تحسن متوسط بنسبة 31% عبر مجموعات البيانات التي تم تقييمها، متفوقاً على نموذج Qwen2.5-VL-32B الأكبر حجماً بفارق 18%، مما يسلط الضوء على أدائه الاستثنائي.بالإضافة إلى ذلك، كشف تحليل التدريب أن التعلم التعزيزي يمكن الـ Planner والـ Executor من تحسين استراتيجياتهما بشكل تآزري، مما يسمح بالتقاط الخصائص النوعية لمجموعات البيانات بفعالية وتعزيز قدرات الاستدلال والذاكرة عبر المجالات المختلفة (cross-domain). كما أظهر تحليل الأدوات أن طرق الذاكرة ذات السياق الطويل (long-context memory) تواجه صعوبات في التفاعل متعدد الجولات مع الأدوات، في حين تفوق MIA المقترح بشكل كبير على المنهجيات السابقة. وفي ظل الإعدادات غير الخاضعة للإشراف، حقق MIA أداءً مماثلاً لنظيره الخاضع للإشراف، مع إظهار أداء تطور ذاتي تدريجي عبر دورات تدريبية متعددة.
One-sentence Summary
The Memory Intelligence Agent (MIA) framework employs a Manager-Planner-Executor architecture to unify parametric and non-parametric memories via bidirectional conversion and alternating reinforcement learning, enabling continuous test-time evolution that achieves up to 9% and 6% performance gains for GPT-5.4 on LiveVQA and HotpotQA respectively while allowing a lightweight Qwen2.5-VL-7B Executor to achieve a 31% average improvement across eleven benchmarks and outperform the Qwen2.5-VL-32B by 18%.
Key Contributions
- The paper introduces the Memory Intelligence Agent (MIA) framework, which employs a Manager-Planner-Executor architecture to store compressed historical search trajectories and generate search plans. This design facilitates a bidirectional conversion loop between parametric and non-parametric memories to achieve efficient memory evolution during inference.
- An alternating reinforcement learning paradigm is adopted to enhance cooperation between the Planner and the Executor, allowing the Planner to continuously evolve during test-time learning without interrupting reasoning. Training analysis indicates this approach enables synergistic optimization of strategies, effectively capturing dataset-specific characteristics and enhancing cross-domain reasoning capabilities.
- Extensive experiments across eleven benchmarks demonstrate the superiority of MIA, showing significant performance enhancements for current SOTA LLMs in deep research tasks. The method boosts GPT-5.4 performance by up to 9% on LiveVQA and enables a lightweight Executor to outperform larger models by an 18% margin while achieving comparable performance in unsupervised settings.
Introduction
Deep research agents combine large language models with external tools to handle complex tasks, relying heavily on memory systems to accumulate experience and refine strategies over time. However, existing methods often depend on long-context memory that stores raw search trajectories, leading to bloated storage, retrieval inefficiencies, and attention dilution. Furthermore, prior planners lack task-specific training, while memory systems focus on factual data rather than the process-oriented strategies needed for effective search planning. To address these issues, the authors introduce the Memory Intelligence Agent (MIA) framework, featuring a Manager-Planner-Executor architecture. They utilize a non-parametric system for compressed historical storage and a parametric agent for dynamic planning. Through alternating reinforcement learning and bidirectional memory conversion, MIA enables continuous test-time evolution. This approach significantly enhances reasoning performance and allows smaller models to outperform larger counterparts on deep research benchmarks.
Dataset
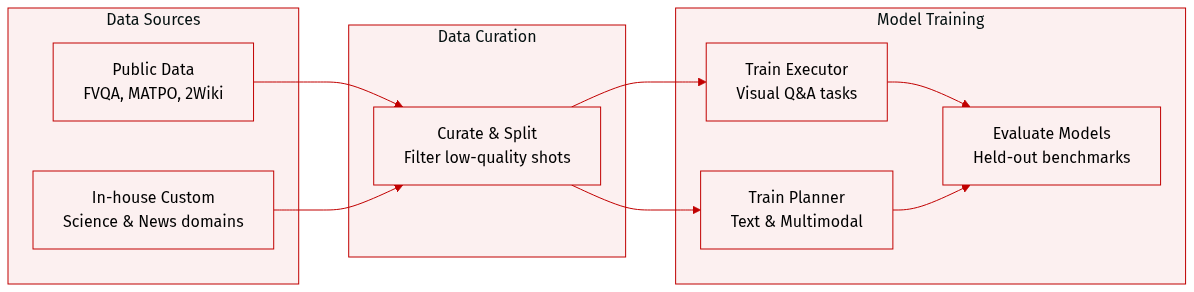
The authors evaluate their framework on both multimodal and text-only datasets to assess performance across different modalities.
Multimodal Data Composition and Usage
- Training: The authors adopt FVQA-train, which contains 4,856 image-question-answer examples from the MMSearch-R1 setting, to train both the Executor and the Planner.
- Public Evaluation Sets: They utilize FVQA-test (1,800 examples), InfoSeek (2,000 examples), SimpleVQA (1,013 examples), and MMSearch (171 examples) as held-out benchmarks. For LiveVQA, they use the accessible public version with 2,384 examples instead of the deprecated 3,602-example version.
- In-house Multimodal Sets: Two custom subsets were constructed to address specific domains. In-house 1 includes 295 examples in scientific fields like Physics and Chemistry, created by crawling text, synthesizing QA pairs, and retrieving matched images. In-house 2 consists of 505 examples from dynamic domains such as Sports and Entertainment, generated from news corpora where Qwen2.5-VL-72B-Instruct anchors visual entities to build complex multi-hop questions.
Text-Only Data Composition and Usage
- Training: The authors incorporate 6,175 examples from MATPO into the Planner training data to enhance planning abilities in textual environments.
- Evaluation: The text-only evaluation suite comprises 2Wiki (12,576 samples), HotpotQA (7,405 samples), SimpleQA (4,327 samples), and GAIA-Text (103 examples). These datasets test multi-hop reasoning, factual knowledge retrieval, and general problem-solving skills.
Method
The proposed MIA framework introduces a Manager-Planner-Executor architecture designed to address storage bottlenecks and reasoning inefficiencies in deep research agents. This architecture decouples historic memory, parametric planning, and dynamic execution. The core components include the Planner, which acts as a cognitive hub to generate search plans; the Executor, which serves as an operational terminal to implement plans via tool usage; and the Memory Manager, which handles memory compression and retrieval.
Refer to the framework diagram below for a visual representation of the overall architecture and reasoning process.
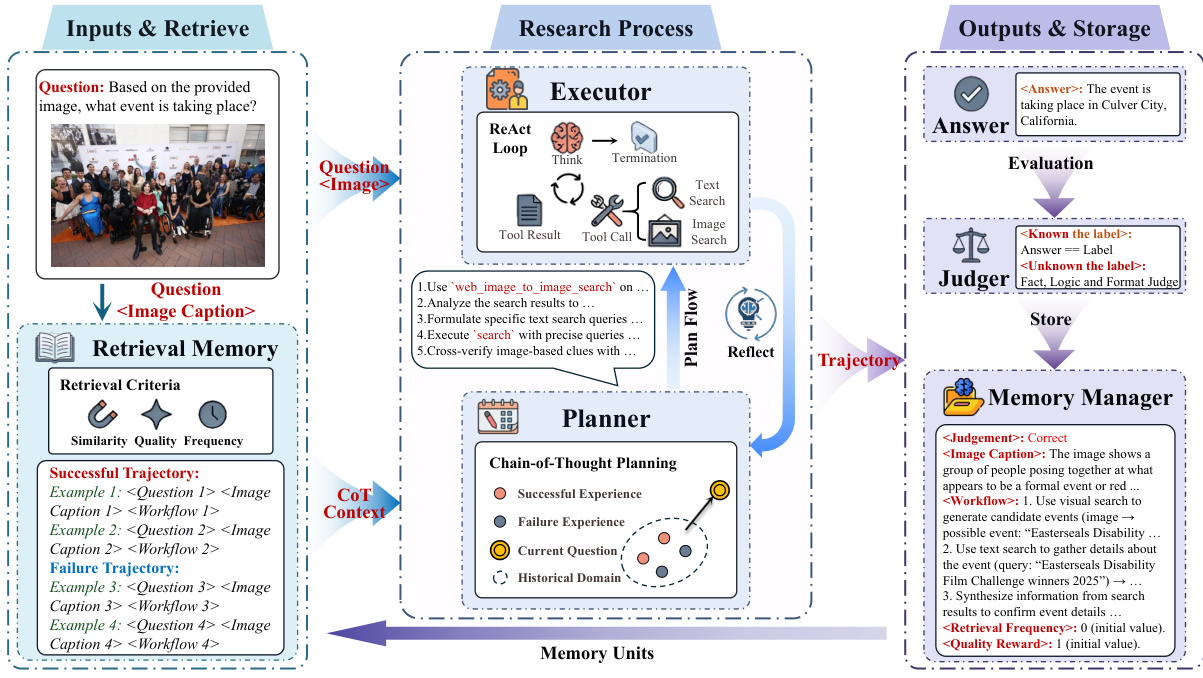
The reasoning process operates through a planning-execution-memory loop comprising three stages: memory retrieval, collaborative reasoning, and experience consolidation. Initially, the Memory Manager retrieves relevant historical trajectories based on semantic similarity, value reward, and frequency reward to provide contextual support. The Planner then decomposes complex tasks into executable sub-goals using a few-shot Chain-of-Thought strategy. The Executor interacts with the environment via a ReAct loop, performing task reasoning and tool usage. A dynamic feedback loop connects the two agents; if the Executor encounters an impasse, the Planner triggers a Reflect-Replan mechanism to adjust the search plan.
To ensure efficient memory storage, the system compresses verbose trajectories into structured workflow summaries. This process involves converting visual inputs into textual captions and abstracting action patterns. The prompts used for this memory compression are detailed in the figure below.

To optimize the collaboration between the Planner and Executor, the authors propose a two-stage alternating Reinforcement Learning (RL) training strategy based on Group Relative Policy Optimization (GRPO). In the first stage, the Planner is frozen while the Executor is trained to understand and follow plans. In the second stage, the Executor is frozen, and the Planner is optimized using memory contexts to enhance plan generation and reflection capabilities. The training pipeline, including the forward rollout and backward reward calculation, is illustrated below.
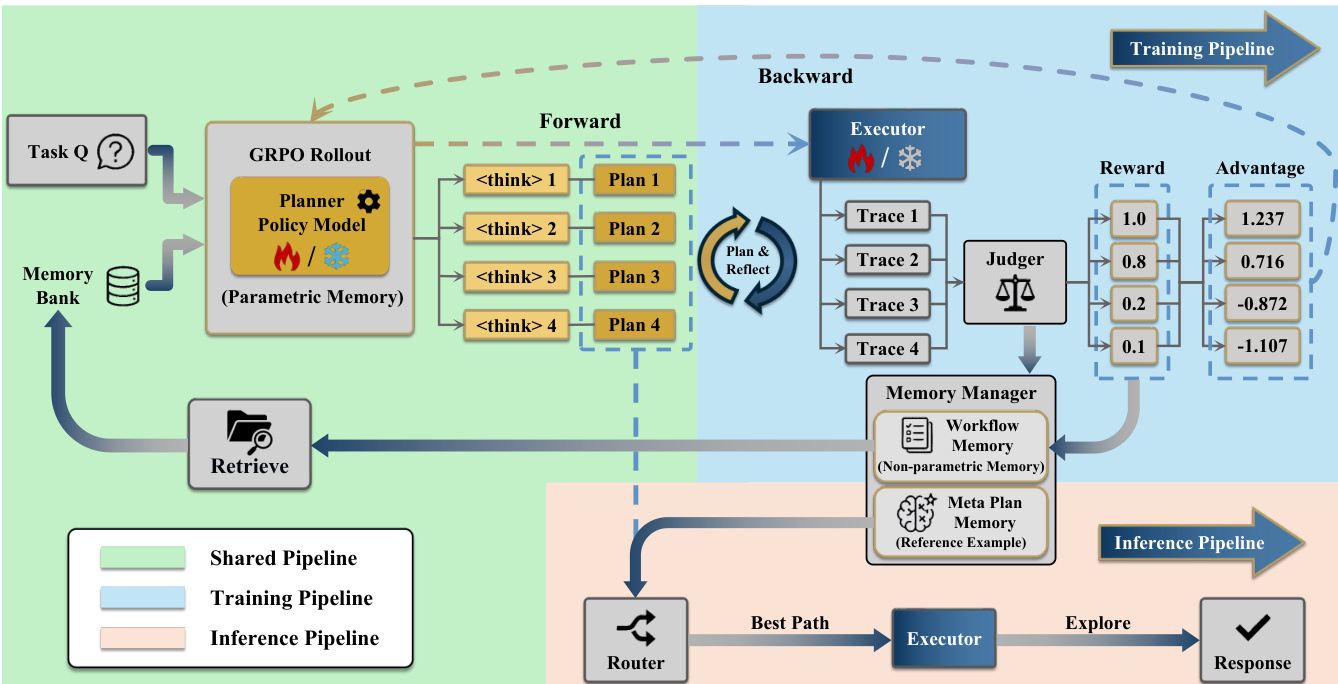
During Test-Time Learning (TTL), MIA adopts an online learning paradigm that performs exploration, storage, and learning simultaneously. This mechanism allows the agent to update its parametric memory (Planner parameters) and non-parametric memory (Workflow Memory) without interrupting the reasoning workflow. In unsupervised environments where ground-truth answers are unavailable, the framework employs a novel evaluation mechanism that mimics the peer-review process. This involves specialized reviewers for reasoning, information sourcing, and result validity, overseen by an Area Chair agent to ensure robust self-evolution. This unsupervised evaluation framework is depicted below.
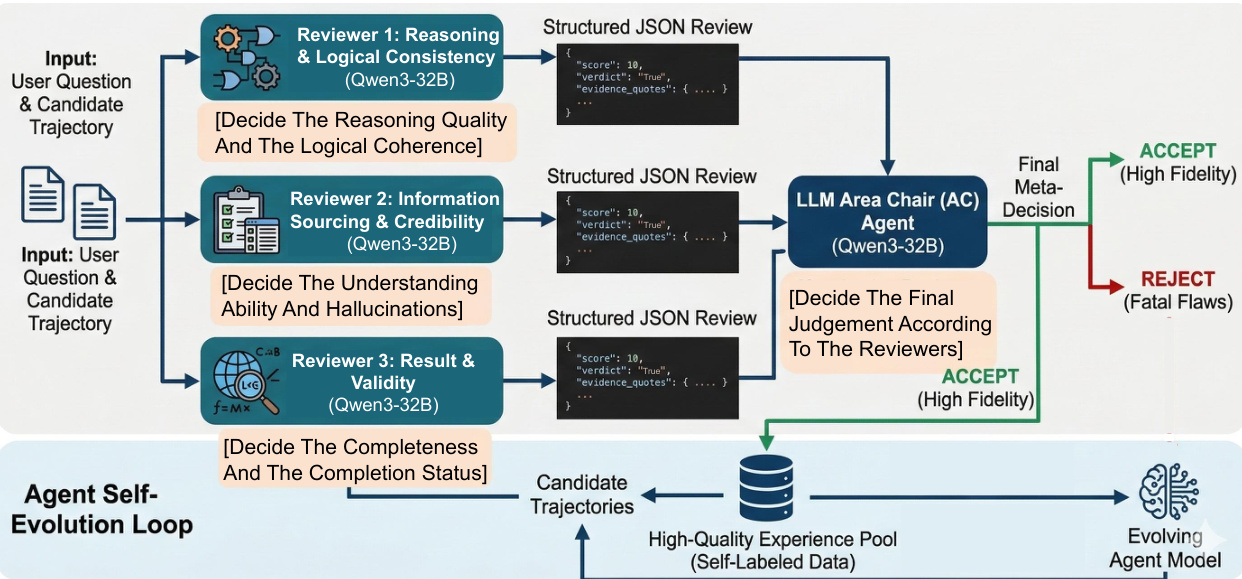
Experiment
MIA is evaluated on diverse multimodal and text-only benchmarks against closed-source models and memory-based agents. Results indicate that MIA's dual-memory mechanism and online updating mitigate noise found in traditional contextual methods, surpassing many closed-source models and agents. Ablation and generalization analyses further validate that guiding planning with memory rather than direct execution, combined with test-time learning, ensures robust reasoning across modalities and executor types.
The authors evaluate their proposed MIA framework against direct answer models, search agents, and memory-based agents across multiple multimodal datasets. The results indicate that MIA achieves superior performance compared to most baselines, effectively bridging the gap in internalizing historical experiences better than contextual memory approaches. The proposed MIA model achieves top performance among open-source models and rivals the capabilities of leading closed-source systems like Gemini-3-Flash across various benchmarks. Contextual memory methods such as RAG and Mem0 generally underperform the No Memory baseline, suggesting that long memory contexts can introduce noise. The unsupervised variant of MIA demonstrates strong capabilities, achieving competitive results that approach the performance of the fully supervised version.
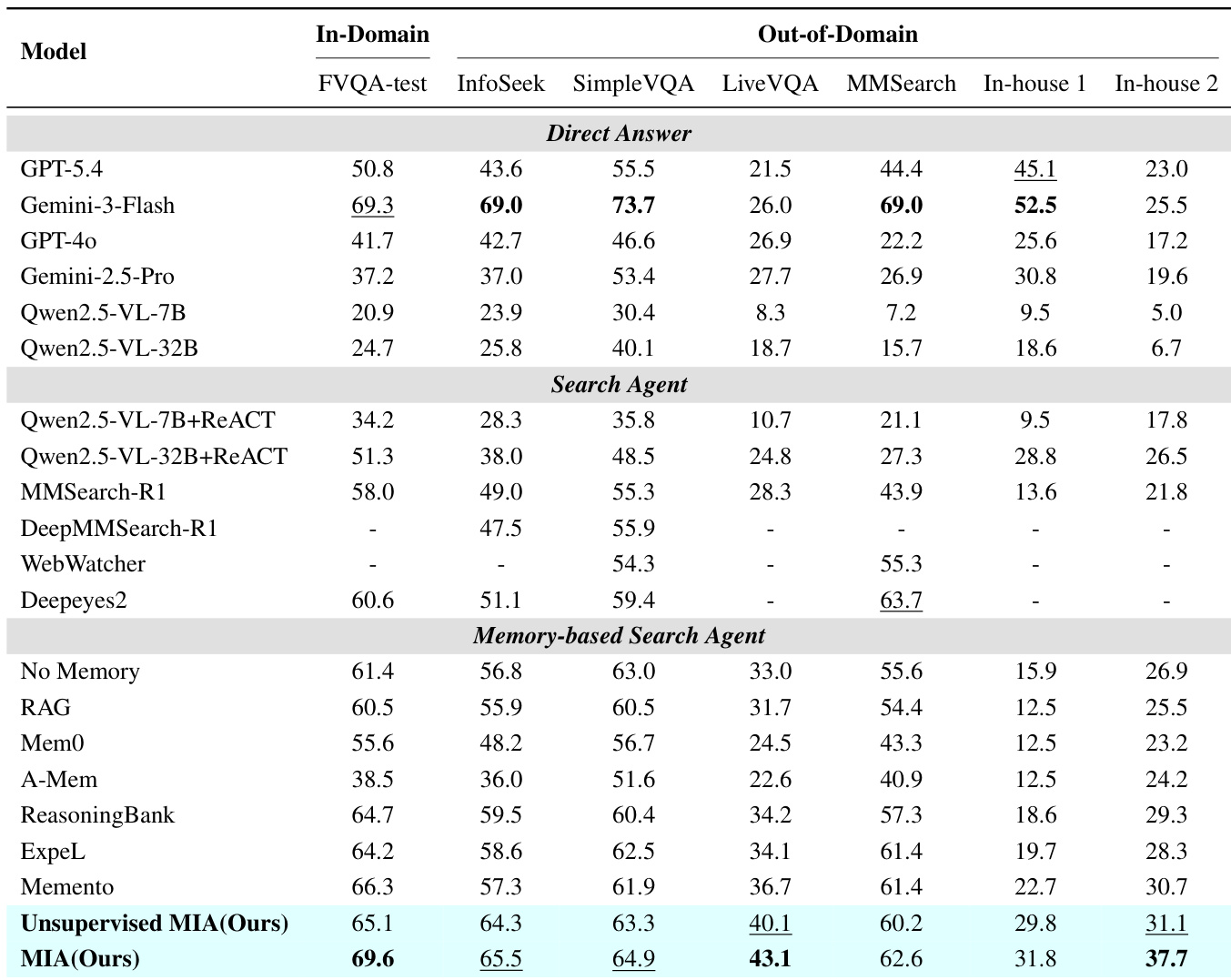
The authors conduct an ablation study to evaluate the contribution of individual components within their proposed framework on multimodal datasets. Results indicate that incrementally introducing modules such as memory-guided planning and test-time learning consistently enhances performance over the baseline. The complete system achieves the highest accuracy across all in-domain and out-of-domain benchmarks compared to intermediate variations. Integrating memory specifically to guide the planning process yields significant performance gains compared to using memory alone or a baseline without it. Training the planner component through alternating reinforcement learning provides substantial improvements over using a standard pre-trained planner. The full framework incorporating test-time learning outperforms all ablated versions across every evaluated dataset, demonstrating the effectiveness of the complete architecture.
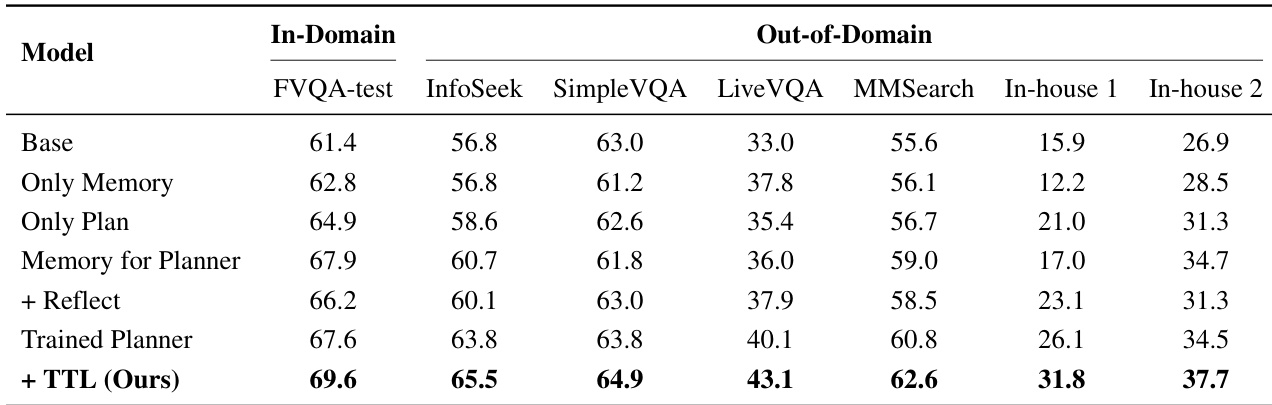
The the the table presents an evaluation of the Unsupervised MIA model across multimodal and text-only benchmarks, comparing its performance against Base and Plan and Reflect baselines. It specifically tracks the model's progress over three epochs of unsupervised self-evolution to demonstrate the effectiveness of the proposed method. The results indicate that the model consistently outperforms the baselines and shows steady improvements in accuracy as it undergoes more epochs of training. Unsupervised MIA achieves higher accuracy than the Base and Plan and Reflect models across all evaluated datasets. Performance demonstrates a consistent upward trend from epoch-1 to epoch-3, validating the effectiveness of the self-evolution mechanism. The model exhibits significant improvements on text-only reasoning tasks compared to the baseline configurations.
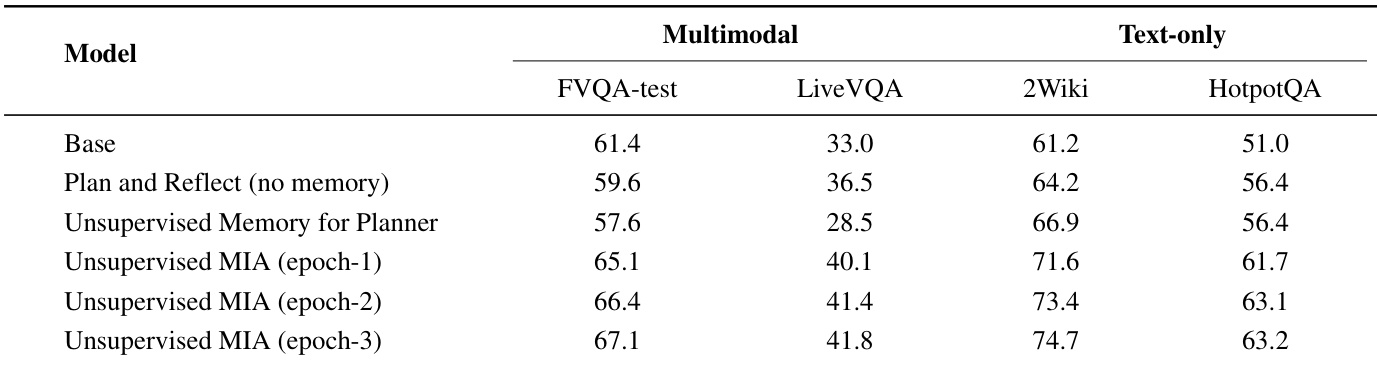
The the the table presents an ablation study evaluating the impact of specific architectural components on text-only out-of-domain reasoning tasks. Results show a consistent performance increase as the model integrates memory-guided planning, reflection, and test-time learning mechanisms. The complete framework outperforms all intermediate variants and the baseline across every dataset column. Guiding the planner with memory yields significantly better results than using memory or planning in isolation. Training the planner model through reinforcement learning leads to substantial performance gains over a standard pre-trained planner. The introduction of online test-time learning provides the final substantial improvement, securing the highest accuracy across all benchmarks.
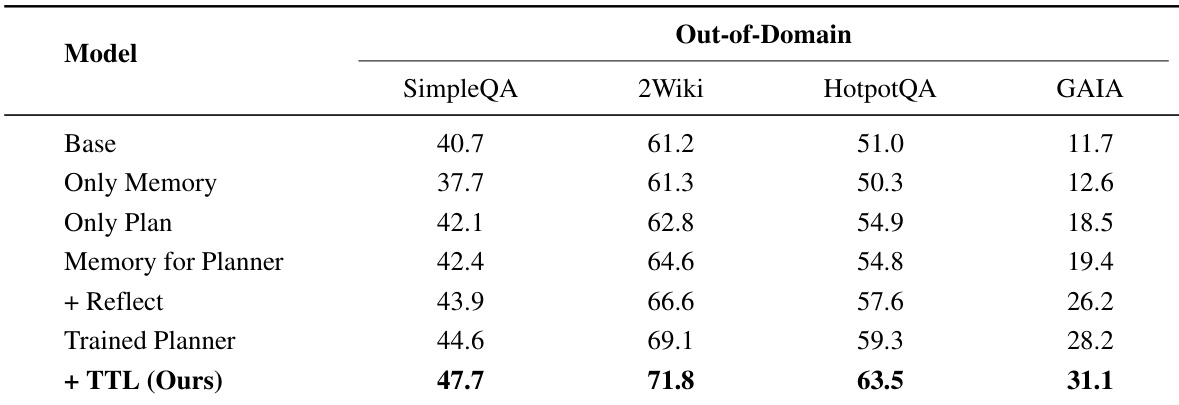
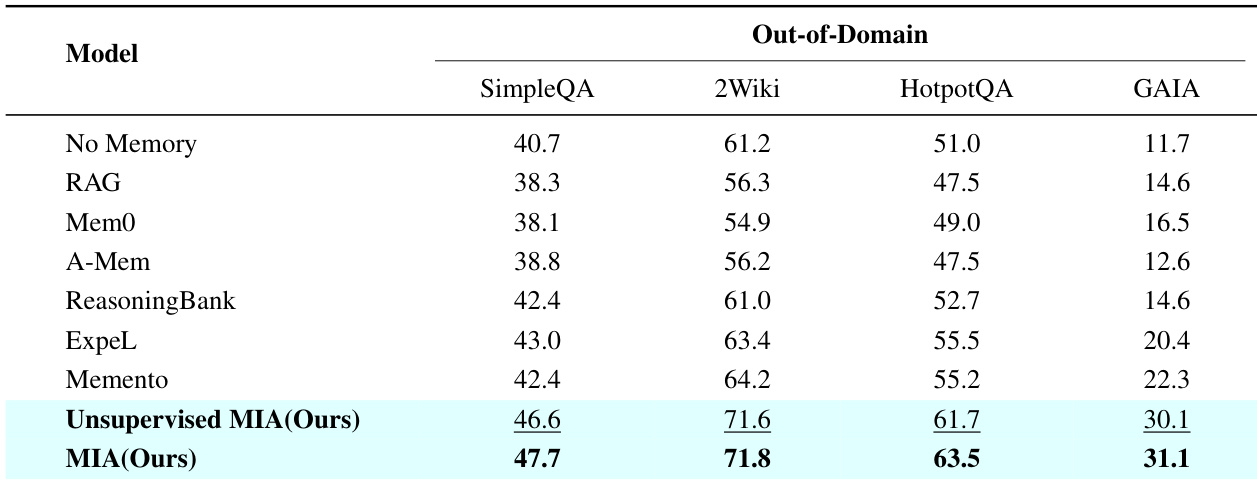
The the the table compares the proposed MIA model against various baselines on text-only out-of-domain datasets including SimpleQA, 2Wiki, HotpotQA, and GAIA. MIA demonstrates superior performance across all metrics, while traditional contextual memory methods often lag behind the no-memory baseline. The results validate the effectiveness of MIA's architecture in handling complex reasoning tasks without degrading performance. MIA consistently outperforms all baseline models including Memento and ExpeL across SimpleQA, 2Wiki, HotpotQA, and GAIA. Contextual memory methods such as RAG and Mem0 generally underperform the no-memory baseline, indicating potential noise introduction. The unsupervised variant of MIA achieves competitive results, closely approaching the performance of the supervised version.
The authors evaluate the proposed MIA framework against diverse baselines across multimodal and text-only out-of-domain datasets, demonstrating superior performance that rivals leading closed-source systems. Ablation studies confirm that integrating memory-guided planning, reinforcement learning, and test-time learning significantly enhances accuracy compared to isolated components or standard pre-trained planners. Notably, traditional contextual memory methods often underperform due to noise, whereas the unsupervised variant achieves competitive results through effective self-evolution.