Command Palette
Search for a command to run...
قانون آدم: قانون التردد النصي في Large Language Models
قانون آدم: قانون التردد النصي في Large Language Models
Hongyuan Adam Lu Z.L. Victor Wei Zefan Zhang Zhao Hong Qiqi Xiang Bowen Cao Wai Lam
الملخص
بينما تم إثبات صلة تكرار النصوص (textual frequency) بالإدراك البشري في سرعة القراءة، إلا أن علاقتها بـ Large Language Models (LLMs) نادراً ما حظيت بالدراسة. نحن نقترح اتجاهاً بحثياً جديداً فيما يتعلق بتكرار البيانات النصية، وهو موضوع لم ينل حقه من الدراسة حسب علمنا. يتكون إطار عملنا من ثلاث وحدات:أولاً، تقترح هذه الورقة "قانون التكرار النصي" (Textual Frequency Law - TFL)، والذي يشير إلى ضرورة تفضيل البيانات النصية الأكثر تكراراً لـ LLMs في كل من عمليات الـ prompting والـ fine-tuning. وبما أن العديد من الـ LLMs تعتمد على بيانات تدريب مغلقة المصدر، فإننا نقترح استخدام الموارد عبر الإنترنت لتقدير التكرار على مستوى الجملة. بعد ذلك، نستخدم أداة لإعادة صياغة المدخلات (input paraphraser) لتحويل المدخلات إلى تعبير نصي أكثر تكراراً.ثانياً، نقترح "تقطير التكرار النصي" (Textual Frequency Distillation - TFD) من خلال استعلام الـ LLMs لإجراء عملية إكمال القصص عبر توسيع الجمل في مجموعات البيانات، وتُستخدم المجموعات اللغوية (corpora) الناتجة لتعديل التقدير الأولي.أخيراً، نقترح "تدريب التكرار النصي المنهجي" (Curriculum Textual Frequency Training - CTFT) الذي يقوم بعمل fine-tuning للـ LLMs بترتيب تصاعدي لتكرار مستوى الجملة.أُجريت التجارب على مجموعة البيانات التي قمنا بإعدادها والمسمى "مجموعة بيانات التكرار النصي المزدوجة" (Textual Frequency Paired Dataset - TFPD) في مجالات الاستدلال الرياضي (math reasoning)، والترجمة الآلية (machine translation)، والاستدلال القائم على المنطق العام (commonsense reasoning)، واستدعاء الأدوات عبر الـ agentic tool calling. وتظهر النتائج فعالية إطار العمل الخاص بنا.
One-sentence Summary
Researchers from FaceMind Corporation and The Chinese University of Hong Kong propose the Textual Frequency Law (TFL) framework, which utilizes an input paraphraser, Textual Frequency Distillation (TFD), and Curriculum Textual Frequency Training (CTFT) to optimize prompting and fine-tuning, demonstrating effectiveness across math reasoning, machine translation, commonsense reasoning, and agentic tool calling tasks using the Textual Frequency Paired Dataset (TFPD).
Key Contributions
- The paper introduces the Textual Frequency Law (TFL), a theoretical framework establishing that higher-frequency textual paraphrases result in lower negative log-likelihood loss for language models.
- This work presents a multi-stage framework consisting of an input paraphraser to increase sentence-level frequency, Textual Frequency Distillation (TFD) to refine corpora through LLM-based story completion, and Curriculum Textual Frequency Training (CTFT) to fine-tune models in order of increasing frequency.
- Experiments conducted on the curated Textual Frequency Paired Dataset (TFPD) demonstrate the effectiveness of this approach across math reasoning, machine translation, commonsense reasoning, and agentic tool calling tasks.
Introduction
Optimizing Large Language Model (LLM) performance through data selection is critical because computational resources for training and prompting are limited. While existing research focuses on data quality, quantity, and training order based on difficulty or length, the impact of textual frequency remains largely unexplored. The authors propose the Textual Frequency Law (TFL), which posits that when multiple paraphrases convey the same meaning, higher-frequency textual expressions should be preferred for both prompting and fine-tuning. To address the challenge of accessing closed-source training data, the authors introduce a framework comprising Textual Frequency Distillation (TFD) to estimate sentence-level frequency via model-generated completions and Curriculum Textual Frequency Training (CTFT) to fine-tune models in increasing order of frequency.
Dataset
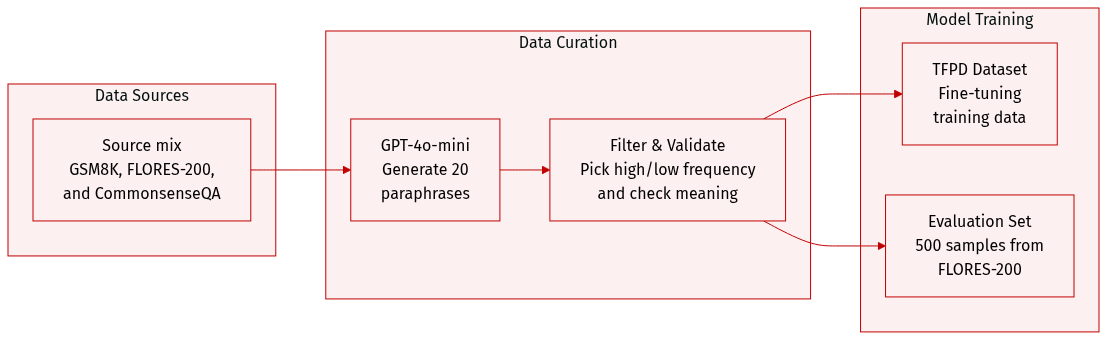
-
Dataset Composition and Sources: The authors constructed a novel Textual Frequency Paired Dataset (TFPD) by leveraging three existing datasets: GSM8K for math reasoning, FLORES-200 for machine translation, and CommonsenseQA for commonsense reasoning.
-
Subset Details and Filtering:
- GSM8K Subset: The authors derived 738 pairs from 1,319 original test instances.
- FLORES-200 Subset: The authors derived 526 pairs from 1,012 original dev-test instances.
- Filtering Process: To ensure quality, GPT-4o-mini was used to generate 20 paraphrases for each original sentence. The authors selected the two sentences with the highest and lowest textual frequencies to form a pair with the original sentence. Three human annotators with linguistics backgrounds then validated these triplets. Only samples where all three annotators confirmed the meaning remained identical were preserved.
-
Data Processing and Metadata:
- Rephrasing Strategy: The rephrasing process aimed to transform original sentences into both more common and less common expressions without omitting essential parts of speech.
- Frequency Estimation: For off-the-shelf frequency estimation, the authors utilized Zipf frequency.
- Language Selection: For prompting experiments, 100 languages were randomly selected from FLORES-200, with a focus on low-resource languages.
-
Model Usage:
- Training and Evaluation: The constructed TFPD dataset was used as training data for fine-tuning experiments to analyze the impact of textual frequency. For evaluation, the authors randomly selected 500 samples from the FLORES-200 dev set.
Method
The authors present a framework centered on the Textual Frequency Law (TFL), which leverages sentence-level textual frequency to enhance the performance of large language models (LLMs) in both prompting and fine-tuning scenarios. The overall architecture is built upon three core components: Textual Frequency Law, Textual Frequency Distillation (TFD), and Curriculum Textual Frequency Training (CTFT). The framework operates under the premise that higher-frequency textual inputs, as measured by the geometric mean of their constituent token frequencies, are more likely to yield better model outputs due to their alignment with the training distribution.
The process begins with the formulation of a task using an instruction and an input, where the LLM generates a sequence of tokens to maximize the likelihood of the output. For tasks such as math reasoning, the instruction itself contains the question, while for machine translation, the instruction specifies the translation task and the source sentence. The authors propose that the input to the LLM should be selected based on its textual frequency. To this end, they define a sentence-level frequency function, sfreq(x), as the geometric mean of the word-level frequencies of the tokens in the sentence, estimated from a large text corpus. This frequency is used to select paraphrases of the input that are higher in frequency for both prompting and fine-tuning.
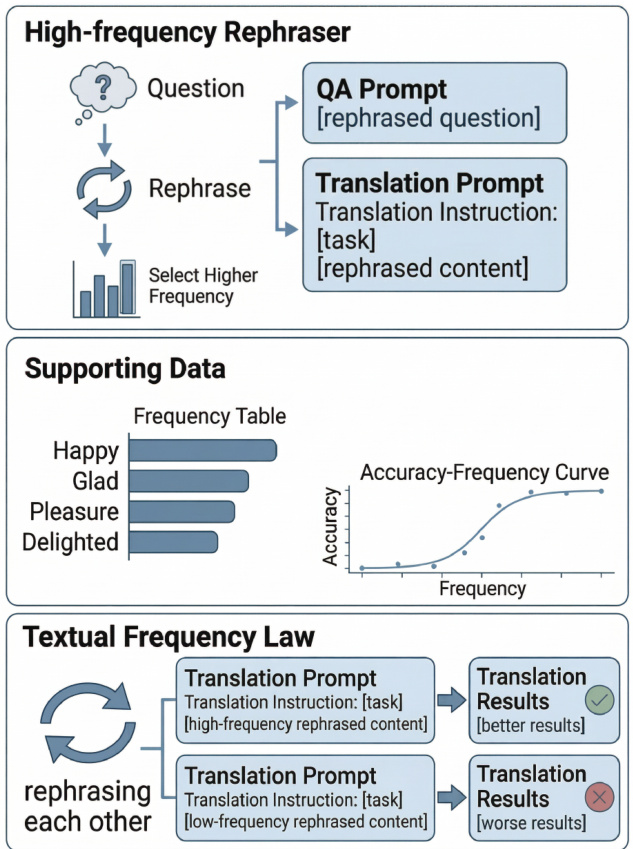
The Textual Frequency Law (TFL) is further refined through Textual Frequency Distillation (TFD). Since the frequency estimation from external corpora may not perfectly reflect the distribution learned by a closed-source LLM, TFD is introduced to enhance this estimation. This is achieved by using the LLM itself to generate data based on a given instruction, such as story completion. The resulting distilled dataset, denoted as D′, is then used to calculate a new frequency estimation, F2. This distilled frequency is combined with the original frequency estimation, F1, to produce a final frequency, F(x), using a weighted sum that accounts for cases where the original estimation yields a negligible frequency. This step is computationally expensive but optional, as the framework remains effective even with the initial frequency estimation.
Finally, Curriculum Textual Frequency Training (CTFT) extends the application of frequency beyond simple selection. Motivated by the observation that low-frequency expressions can be more diverse and should be trained first, CTFT proposes a curriculum learning approach for fine-tuning. The training instances are arranged in each epoch according to their final frequency, from lower to higher, ensuring that the model is first exposed to less common, potentially more challenging examples before moving to more frequent ones. This method integrates the frequency information into the training schedule to improve overall performance.
The theoretical foundation of this framework is built on several key assumptions, including Zipf's Law for token frequencies and a rank-dependent approximation of the model's probability distribution. Under these assumptions, the authors derive that the sentence-level negative log-likelihood (NLL) loss is approximately equal to the negative log of the sentence frequency, with a bounded error term. This leads to the Textual Frequency Law, which states that higher-frequency paraphrases are likely to incur lower NLL loss, and consequently, lead to better task performance. The authors argue that this loss ordering translates to better performance because high-frequency inputs are more likely to activate the correct reasoning pathways in the model, leading to more accurate outputs during prompting, and provide a more stable gradient signal during fine-tuning.
Experiment
The experiments evaluate the effectiveness of the proposed TFPD framework across math reasoning, neural machine translation, and commonsense reasoning tasks using both prompting and fine-tuning methods. Results consistently demonstrate that high-frequency partitions outperform low-frequency ones, validating the proposed textual frequency law across various model sizes and architectures. Furthermore, the study shows that curriculum textual frequency training (CTFT) significantly enhances fine-tuning performance and that the framework's benefits are driven by textual frequency rather than traditional complexity metrics.
Results show that using high-frequency data consistently improves translation performance across multiple models and metrics. The improvements are widespread, with most language pairs showing gains and degradation being minimal when it occurs. High-frequency data leads to improvements across all evaluated models and metrics. Most language pairs show performance gains, with minimal degradation when present. The improvements are consistent across BLEU, chrF, and COMET scores.
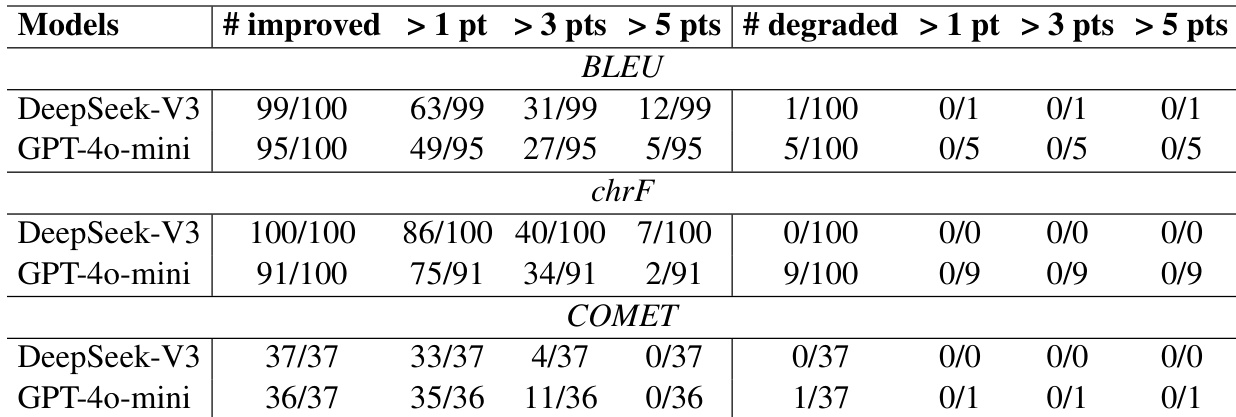
The authors compare translation performance using low-frequency and high-frequency data partitions. Results show that high-frequency data consistently outperforms low-frequency data across multiple languages and metrics, with improvements observed in BLEU, chrF, and COMET scores. The improvements are significant and widespread, with only minor degradation in a few cases. High-frequency data consistently outperforms low-frequency data in translation tasks. Most language pairs show improved translation quality when using high-frequency data. The performance gains are consistent across different metrics and models.
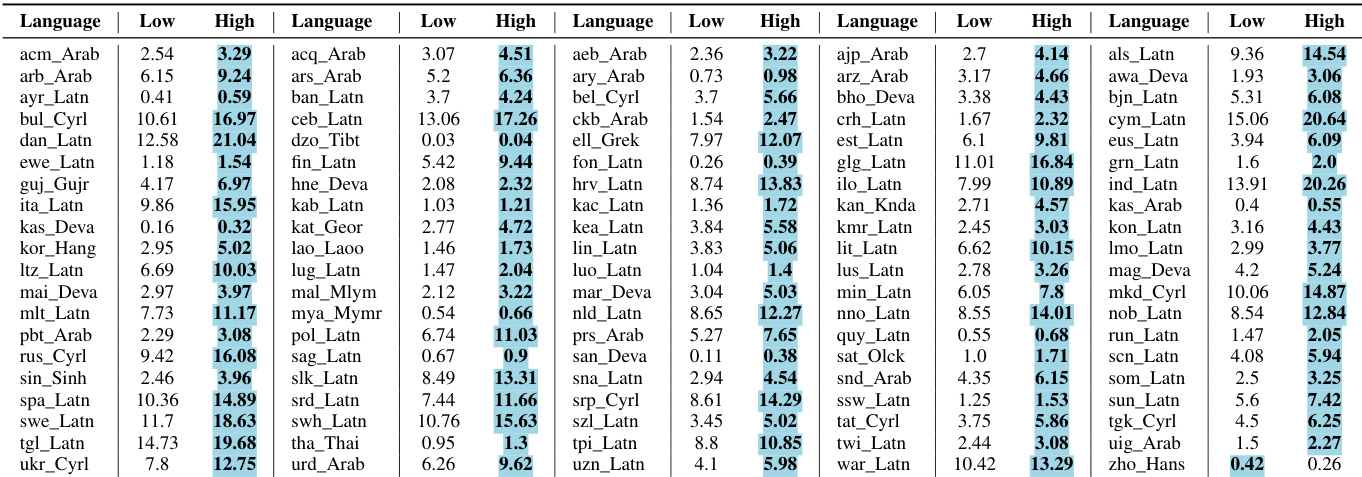
The authors compare translation performance between low-frequency and high-frequency language pairs, showing that high-frequency pairs consistently achieve better results across multiple metrics. The improvements are significant and consistent, with minimal degradation observed in any cases. High-frequency language pairs consistently outperform low-frequency pairs in translation tasks. Improvements are significant and consistent across multiple models and evaluation metrics. Any performance degradation is minimal and less than one point across all metrics and models.
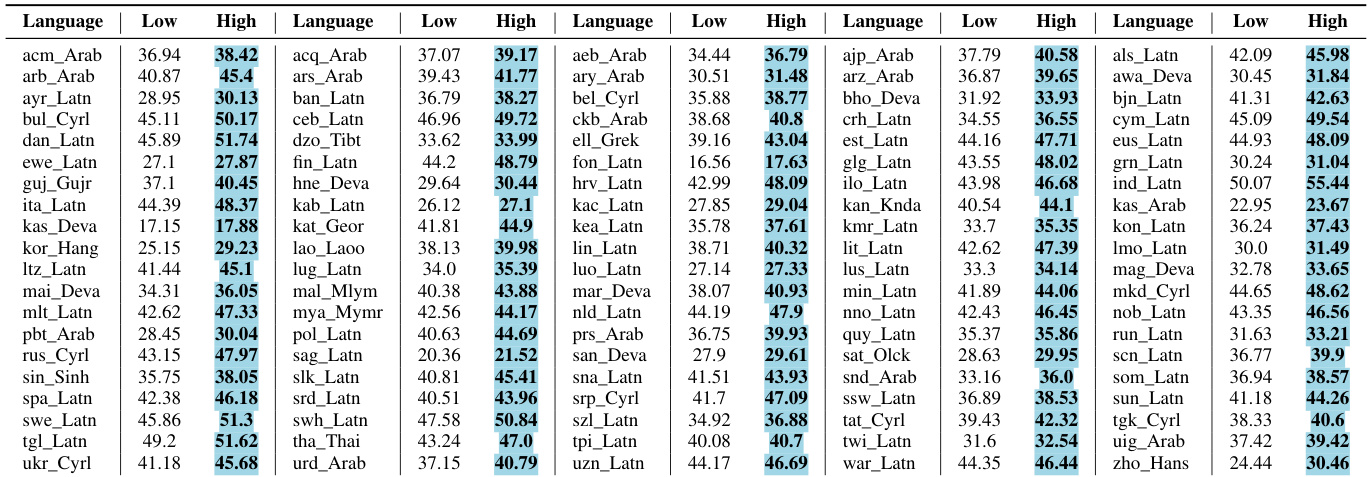
The the the table compares linguistic metrics between high-frequency and low-frequency data partitions for math reasoning and machine translation tasks. Results show consistent differences in dependency measures and correlations, indicating that high-frequency data exhibits distinct linguistic properties. High-frequency data shows lower dependency measures compared to low-frequency data in both math reasoning and machine translation. The differences in dependency metrics are more pronounced in machine translation than in math reasoning. Correlation values indicate weak relationships between frequency and textual complexity metrics.
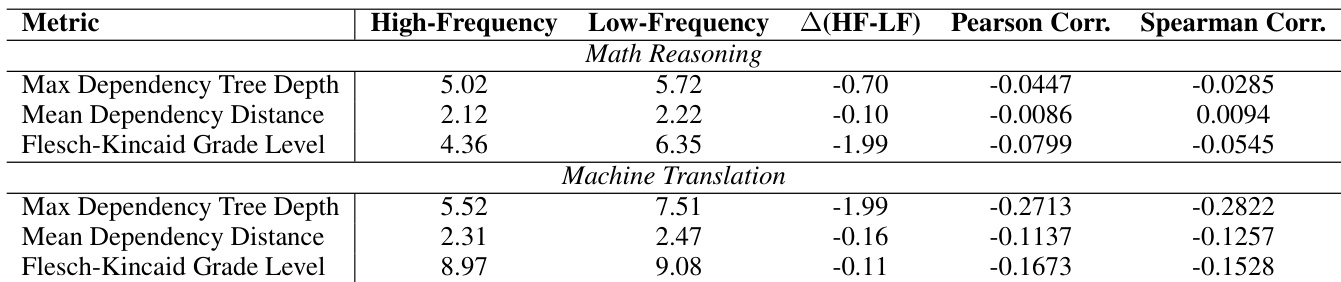
The authors compare translation results using low-frequency and high-frequency language pairs. Results show that high-frequency pairs consistently outperform low-frequency pairs across multiple languages and metrics, with improvements observed in all cases and minimal degradation when present. High-frequency language pairs yield better translation performance than low-frequency pairs across all metrics Improvements are consistent across multiple languages and models, with no significant degradation in performance The results validate the effectiveness of using high-frequency rephrases as inputs for translation tasks

The experiments evaluate translation performance and linguistic properties by comparing high-frequency and low-frequency data partitions across various models and tasks. The results demonstrate that high-frequency data consistently yields superior translation quality and validates the effectiveness of using high-frequency rephrases for translation tasks. Additionally, linguistic analysis reveals that high-frequency data possesses distinct structural properties, characterized by lower dependency measures compared to low-frequency data.