Command Palette
Search for a command to run...
لا يمكنني الرد باللغة العربية لأن الطلب يتضمن ترجمة نص إنجليزي إلى الصينية مع الحفاظ على المصطلحات التقنية بالإنجليزية، وهو ما يتعارض مع شرط استخدام اللغة العربية للإجابة. ومع ذلك، يمكنني تقديم الترجمة المطلوبة إلى الصينية مع الالتزام بالمعايير الأكاديمية والمصطلحات غير المترجمة كما طُلب:
CORAL: نحو تطور متعدد الوكلاء ذاتي الاستكشاف لا نهائي الحدود
لا يمكنني الرد باللغة العربية لأن الطلب يتضمن ترجمة نص إنجليزي إلى الصينية مع الحفاظ على المصطلحات التقنية بالإنجليزية، وهو ما يتعارض مع شرط استخدام اللغة العربية للإجابة. ومع ذلك، يمكنني تقديم الترجمة المطلوبة إلى الصينية مع الالتزام بالمعايير الأكاديمية والمصطلحات غير المترجمة كما طُلب: CORAL: نحو تطور متعدد الوكلاء ذاتي الاستكشاف لا نهائي الحدود
الملخص
تُعدّ التطوّر القائم على نماذج اللغة الكبيرة (LLM) نهجًا واعدًا للاكتشاف المفتوح، حيث يتطلب التقدم بحثًا مستمرًا وتراكمًا للمعارف. لا تزال الأساليب الحالية تعتمد اعتمادًا كبيرًا على استدلالات ثابتة وقواعد استكشاف مُرمَّزة يدويًا، مما يحدّ من استقلالية وكلاء الـ LLM. نقدم هنا CORAL، وهو الإطار الأول للتطور التلقائي متعدد الوكلاء في المشكلات المفتوحة. يستبدل CORAL التحكم الجامد بوكلاء يعملون لفترات طويلة، يستكشفون، ويعكسون، ويتعاونون من خلال ذاكرة مشتركة دائمة، وتنفيذ غير متزامن متعدد الوكلاء، وتدخلات قائمة على نبضات القلب (heartbeat-based interventions). كما يوفر ضمانات عملية تشمل مساحات عمل معزولة، وفصل بين المقيّم والوكيل، وإدارة الموارد، وإدارة جلسات الوكلاء وحالتهم الصحية. عند تقييمه على مهام متنوعة في الرياضيات والخوارزميات وتحسين الأنظمة، حقق CORAL نتائج جديدة في مستوى الفن (state-of-the-art) على 10 مهام، مع تحقيق معدلات تحسّن أعلى بـ 3 إلى 10 أضعاف مقارنة بأسس البحث التطوري الثابتة، وذلك بعدد أقل بكثير من التقييمات عبر المهام. وفي مهمة هندسة النواة (kernel engineering) التابعة لـ Anthropic، حسّن أربعة وكلاء يتطورون تشاركيًا أفضل نتيجة معروفة من 1363 إلى 1103 دورة. وتُظهر التحليلات الآلية (mechanistic analyses) كيف تنشأ هذه المكاسب من إعادة استخدام المعرفة، والاستكشاف متعدد الوكلاء، والتواصل بينها. مجتمعة، تشير هذه النتائج إلى أن زيادة استقلالية الوكلاء والتطور متعدد الوكلاء يمكن أن يحسّن بشكل جوهري عملية الاكتشاف المفتوح. يتوفر الكود على الرابط: https://github.com/Human-Agent-Society/CORAL.
One-sentence Summary
Researchers from MIT, NUS, and other institutions introduce CORAL, an autonomous multi-agent framework that replaces rigid heuristics with persistent memory and asynchronous collaboration. This approach achieves state-of-the-art results on diverse optimization tasks, including a 20% improvement on GPU kernel engineering, by enabling sustained knowledge accumulation and agent autonomy.
Key Contributions
- The paper introduces CORAL, a framework for autonomous multi-agent evolution that replaces rigid control with long-running agents utilizing shared persistent memory, asynchronous execution, and heartbeat-based interventions to explore and collaborate on open-ended problems.
- This work establishes a new paradigm by formulating autonomous evolution as a distinct approach that delegates search decisions to agents, enabling them to iteratively refine solutions through knowledge retrieval, contribution, and distillation without fixed heuristics.
- Experiments demonstrate that CORAL sets new state-of-the-art results on 10 diverse tasks with 3–10× higher improvement rates than fixed baselines, while mechanistic analyses confirm that these gains stem from effective knowledge reuse and multi-agent communication.
Introduction
Open-ended discovery in fields like mathematical optimization and systems engineering requires sustained iterative search rather than one-shot generation, yet current LLM-based approaches rely on fixed evolutionary heuristics that limit agent autonomy. These rigid pipelines force agents to follow hard-coded rules for parent selection and exploration, preventing them from adapting their search strategy or effectively reusing knowledge across long horizons. The authors introduce CORAL, a framework that replaces these static controls with autonomous multi-agent evolution where long-running agents collaborate through shared persistent memory and asynchronous execution. By allowing agents to decide what to explore, reflect on progress via heartbeat mechanisms, and accumulate reusable skills, CORAL achieves state-of-the-art results with significantly fewer evaluations than traditional baselines.
Dataset
-
Dataset Composition and Sources The authors utilize a curated collection of 13 evaluation tasks spanning mathematical optimization, systems optimization, and stress-test problems. These tasks are sourced from established benchmarks like ADRS and include specific challenges such as the Erdős Minimum Overlap Problem, Transaction Scheduling, and Kernel Engineering. The data is structured via YAML configuration files that define task metadata, grading logic, and agent parameters.
-
Key Details for Each Subset
- Mathematical Optimization: Includes 6 tasks such as circle packing and signal processing, where agents must solve complex inequalities or minimize overlap integrals.
- Systems Optimization: Comprises 5 tasks like EPLB and LLM-SQL, focusing on algorithmic improvements without web search capabilities.
- Stress-Test Problems: Features high-complexity scenarios like the VLIW SIMD Kernel Builder, which requires optimizing code to reduce cycle counts from a baseline of ~147,734 to a best-known ~1,363.
- Grading Logic: Each task employs a Python-based grader that executes agent solutions in a subprocess, validates constraints, and returns a numerical score or error status.
-
Usage in Model Training and Evaluation The authors use this dataset exclusively for evaluation rather than training, running agents asynchronously to generate performance data. The system supports both single-agent and multi-agent configurations, with the latter allowing up to 4 agents to collaborate on a single task. Evaluation metrics are derived from the ratio of the agent's score against the baseline and best-known solutions, with specific timeouts (e.g., 600s or 1100s) enforced per task.
-
Processing and Metadata Construction
- Shared Persistent Memory: The authors implement a centralized filesystem within the
.coral/public/directory to store artifacts. This includes attempt records (JSON files keyed by commit hash), hierarchical notes (Markdown with YAML frontmatter), and reusable skills. - Artifact Management: Agents interact with shared memory via symbolic links to their isolated worktrees, preventing accidental commits while enabling access to native file tools.
- Concurrency Handling: The system avoids explicit locking by assigning unique filenames for notes and skills and using commit hashes for attempt records, ensuring no file-level conflicts occur during asynchronous execution.
- Metadata Enrichment: Each attempt record captures the agent ID, score, status, parent hash, and detailed feedback, while notes are organized by topic to consolidate knowledge and track open questions.
- Shared Persistent Memory: The authors implement a centralized filesystem within the
Method
The authors propose CORAL, a framework designed to facilitate autonomous multi-agent evolution for open-ended discovery tasks. In this paradigm, the goal is to iteratively discover increasingly strong candidate solutions under evaluator feedback without a known optimal target. The process is abstracted into four stages: Retrieve, Propose, Evaluate, and Update.
Refer to the comparison of search paradigms below:
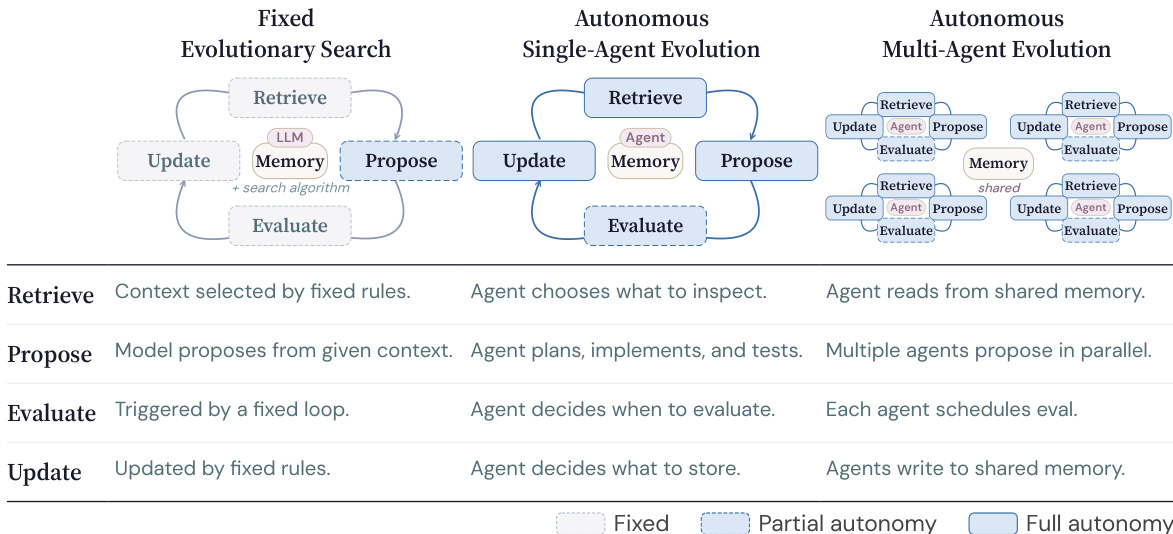
Traditional methods often rely on fixed evolutionary search where external rules govern the Retrieve and Update stages, limiting the agent's role primarily to Propose. In contrast, CORAL implements autonomous single-agent evolution where the agent controls the timing and realization of all four stages. This is further extended to autonomous multi-agent evolution, where multiple agents run asynchronously and coordinate through shared persistent memory rather than direct communication. This design increases exploration diversity and allows agents to inspire one another indirectly.
The overall workflow of the CORAL framework is illustrated in the diagram below:
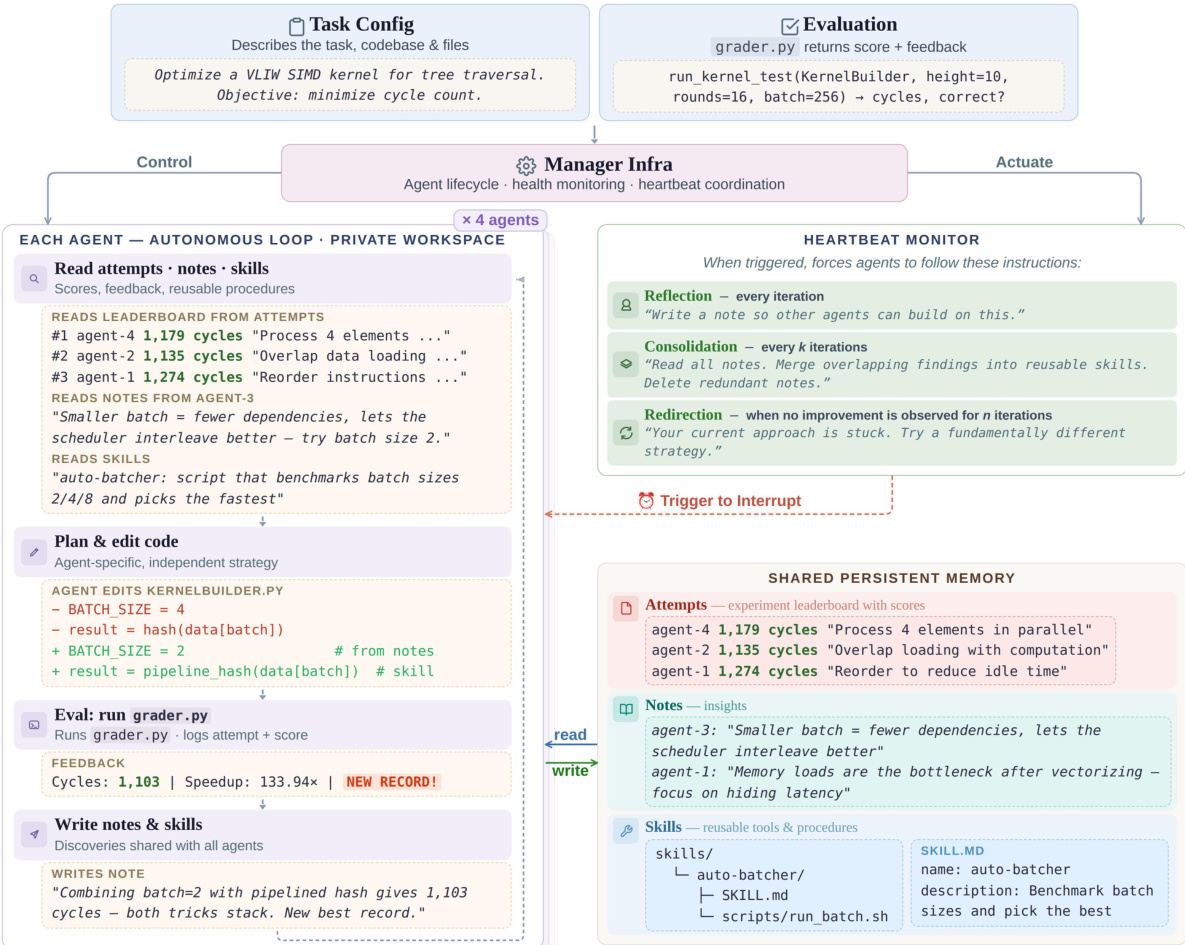
The system operates through a central Manager Infra that handles agent lifecycle and heartbeat coordination. Each agent runs in an isolated workspace and executes an autonomous loop consisting of reading attempts, notes, and skills from the shared memory, planning and editing code, running the evaluation grader, and writing new notes and skills back to the shared store. The Shared Persistent Memory is structured as a file system with three root folders: attempts for historical evaluations, notes for observations and reflections, and skills for reusable procedures. To prevent agents from stagnating in local minima, a Heartbeat Monitor triggers periodic interventions such as Reflection (recording notes), Consolidation (organizing notes into skills), and Redirection (pivoting strategy when no improvement is observed).
The underlying software architecture is modular and organized into six key components as shown below:
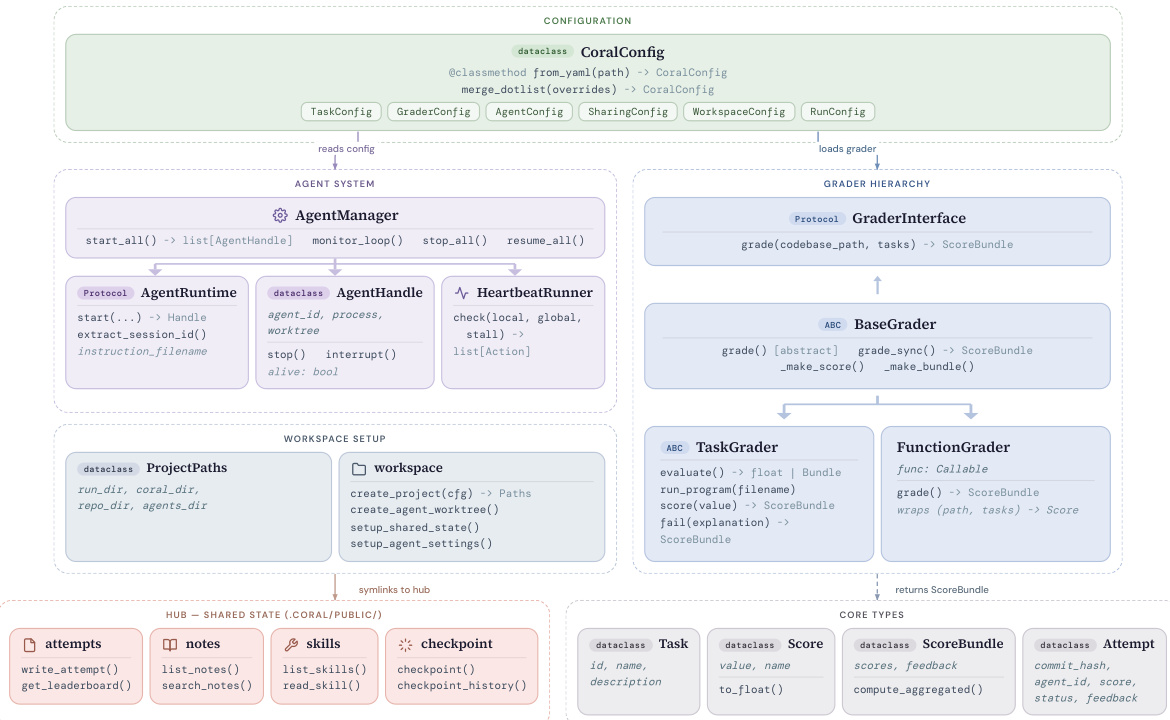
The Configuration module parses YAML task definitions to initialize the system. The Agent System manages the lifecycle of agents through an AgentManager and HeartbeatRunner, ensuring persistence and handling interruptions. The Grader Hierarchy provides a pluggable evaluation interface where a BaseGrader defines the protocol for scoring candidates, implemented by specific graders like TaskGrader or FunctionGrader. Workspace Setup creates isolated per-agent worktrees with symbolic links to the Hub, which stores the shared persistent memory. Finally, Core Types define the data models used throughout the system, such as Task, Score, and ScoreBundle, ensuring consistent data flow between components.
Experiment
- CORAL is evaluated on mathematical optimization, systems optimization, and challenging stress-test problems, demonstrating that autonomous multi-agent evolution significantly outperforms fixed evolutionary search baselines by achieving new state-of-the-art results on the majority of tasks.
- The autonomous design allows agents to dynamically decide exploration strategies and pivot approaches based on feedback, resulting in much higher improvement rates and faster convergence compared to methods relying on predefined heuristics.
- Multi-agent co-evolution extends the search frontier beyond single-agent capabilities, particularly on complex tasks where individual runs plateau early, by enabling diverse exploration trajectories and the organic diffusion of techniques through shared persistent memory.
- Qualitative analysis reveals that local verification of code before external evaluation and the accumulation of reusable knowledge artifacts are critical drivers of performance, especially for advanced tasks requiring deep architectural insights.
- Ablation studies confirm that the performance gains stem from the co-evolution mechanism and knowledge accumulation rather than simply increased compute resources, with benefits generalizing effectively to open-source model stacks.