Command Palette
Search for a command to run...
MDPBench: مقياس مرجعي لتحليل المستندات متعدد اللغات في سيناريوهات العالم الحقيقي
MDPBench: مقياس مرجعي لتحليل المستندات متعدد اللغات في سيناريوهات العالم الحقيقي
Zhang Li Zhibo Lin Qiang Liu Ziyang Zhang Shuo Zhang Zidun Guo Jiajun Song Jiarui Zhang Xiang Bai Yuliang Liu
الملخص
نقدم لكم Multilingual Document Parsing Benchmark، وهو أول benchmark مخصص لعمليات تحليل وفهم المستندات الرقمية والمصورة متعددة اللغات. لقد حقق تحليل المستندات (Document parsing) قفزات نوعية ملحوظة، إلا أن هذه التطورات اقتصرت بشكل شبه حصري على الصفحات الرقمية النظيفة وذات التنسيق الجيد في عدد محدود من اللغات السائدة. وحتى الآن، لا يوجد benchmark منهجي لتقييم أداء النماذج على المستندات الرقمية والمصورة عبر مختلف النصوص واللغات ذات الموارد المنخفضة (low-resource languages).يتكون MDPBench من 3,400 صورة مستند تغطي 17 لغة، وأنظمة كتابة متنوعة، وظروف تصوير متفاوتة، مع توفير annotations عالية الجودة تم إنتاجها عبر pipeline صارم يتضمن تصنيف النماذج من قبل خبراء، والتصحيح اليدوي، والتحقق البشري. ولضمان المقارنة العادلة ومنع تسرب البيانات (data leakage)، قمنا بفصل مجموعات التقييم إلى أقسام عامة (public) وخاصة (private).وقد كشف تقييمنا الشامل لكل من النماذج مفتوحة المصدر (open-source) والنماذج مغلقة المصدر (closed-source) عن نتيجة صادمة: فبينما أثبتت النماذج مغلقة المصدر (لا سيما Gemini3-Pro) متانة نسبية، عانت البدائل مفتوحة المصدر من انهيار حاد في الأداء، خاصة عند التعامل مع النصوص غير اللاتينية والمستندات المصورة في بيئات واقعية؛ حيث سجلت متوسط انخفاض بنسبة 17.8% في المستندات المصورة و14.0% في النصوص غير اللاتينية. وتكشف هذه النتائج عن اختلالات كبيرة في الأداء عبر اللغات والظروف المختلفة، كما تشير إلى توجهات محددة لبناء أنظمة تحليل أكثر شمولاً وجاهزية للنشر الفعلي.
One-sentence Summary
The researchers introduce MDPBench, the first benchmark for multilingual digital and photographed document parsing, which utilizes a dataset of 3,400 images across 17 languages to reveal that while closed-source models like Gemini3-Pro remain relatively robust, open-source models suffer significant performance collapses on non-Latin scripts and photographed documents.
Key Contributions
- The paper introduces MDPBench, the first benchmark designed to evaluate multilingual document parsing across both digital and photographed documents.
- This work provides a dataset of 3,400 high-quality images spanning 17 languages and diverse scripts, which were annotated through a rigorous pipeline involving expert model labeling, manual correction, and human verification.
- Extensive evaluations of open-source and closed-source models reveal significant performance gaps, specifically showing that open-source models experience an average performance drop of 17.8% on photographed documents and 14.0% on non-Latin scripts.
Introduction
Efficient document parsing is essential for digitizing information, yet current research focuses almost exclusively on clean, digitally born documents in a few dominant languages. Existing benchmarks fail to account for the complexities of real-world scenarios, such as diverse scripts, low-resource languages, and the visual distortions found in photographed documents. To address these gaps, the authors introduce MDPBench, the first comprehensive benchmark for multilingual digital and photographed document parsing. The dataset consists of 3,400 high-quality images spanning 17 languages and various photographic conditions, providing a rigorous framework to evaluate how models handle non-Latin scripts and imperfect real-world captures.
Dataset
-
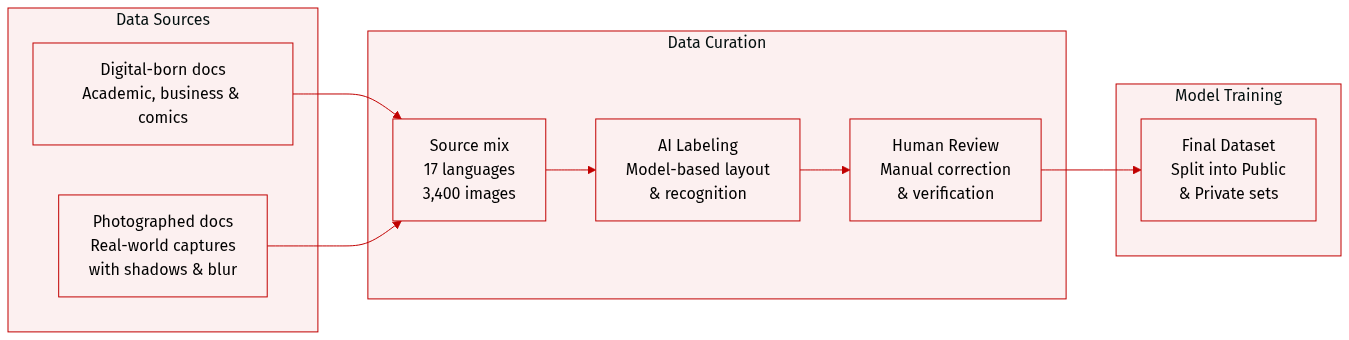
Dataset Composition and Sources: The authors introduce MDPBench, a benchmark consisting of 3,400 document images across 17 languages. The dataset includes digital-born documents sourced from academic papers, business reports, educational materials, handwritten notes, historical archives, newspapers, and complex text-image documents like comics. It also incorporates challenging Chinese and English documents from OmniDocBench.
-
Subset Details:
- Digital-born Subset: Contains 850 curated images spanning 17 languages. These were selected for diversity in layout complexity and visual elements such as formulas, tables, and charts, following a manual review to filter out low-quality or trivial samples.
- Photographed Subset: Created by transforming digital documents into real-world images through printing or screen capture. This subset includes indoor and outdoor captures with various degradations, such as physical deformations (bending and wrinkling), diverse camera angles (oblique and inverted), moiré patterns, reflections, shadows, and uneven illumination.
- Public and Private Splits: To prevent benchmark overfitting, the authors divide the data into a public subset for community download and a private subset for secure evaluation via an official website.
-
Data Processing and Annotation:
- Multi-stage Annotation Pipeline: The authors employ a rigorous "annotation-correction-verification" workflow.
- Expert Model Labeling: Layout detection is performed using dots.ocr and PaddleOCR-VL. Text, table, and formula blocks are cropped based on bounding boxes. Recognition is then performed by three models (PaddleOCR-VL, dots.ocr, and Qwen3VL). The final initial annotation is selected based on the highest average similarity (using NED for text/formulas and TEDS for tables) among the models. If similarity falls below 0.7, Gemini-3-pro is used to ensure reliability.
- Manual Correction and Verification: Annotators manually correct layout coordinates, element types, and reading order. An independent reviewer then verifies the corrected documents, returning any errors to the original annotator for iterative revision.
-
Evaluation Strategy: The authors use a page-level aggregation strategy to prevent imbalanced element distributions (like formulas or tables) from disproportionately affecting multilingual scores. Metrics are calculated per page and then averaged. Evaluation ignores page components such as headers, footers, and page numbers. Specific metrics include Normalized Edit Distance (NED) for text, CDM for formulas, and Tree-Edit-Distance-based Similarity (TEDS) for tables.
Experiment
The MDPBench evaluates a diverse range of document parsing models, including general vision-language models and specialized pipeline systems, across 17 languages and various document formats. The experiments validate model robustness against real-world challenges such as photographed documents, complex layouts, and non-Latin scripts. Findings reveal that while proprietary models generally outperform open-source alternatives, all methods suffer significant performance drops when handling photographed images or low-resource languages. Furthermore, models frequently struggle with language-specific nuances, including incorrect reading orders for right-to-left scripts, visual confusion in Cyrillic characters, and hallucinations in unspaced text.
The authors evaluate multiple document parsing models on a multilingual benchmark, comparing their performance across different languages and document types. Results show significant differences between proprietary and open-source models, with notable challenges in parsing photographed documents and non-Latin scripts. Proprietary models outperform open-source models across all evaluation metrics. Performance degrades significantly on photographed documents compared to digital-born ones. Models exhibit lower accuracy on non-Latin-script languages and struggle with language-specific reading orders.

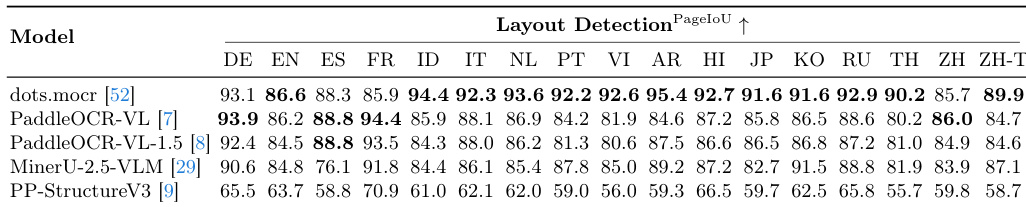
The authors evaluate multiple models on layout detection using MDPBench, focusing on performance across various languages. Results show that dots.mocr achieves the highest overall accuracy, with strong performance in many languages, while other models exhibit varying degrees of effectiveness depending on language and image type. dots.mocr achieves the highest overall layout detection accuracy across multiple languages Performance varies significantly across languages, with some models showing strong results in certain scripts and weaker ones in others Models exhibit differences in handling different languages, indicating language-specific biases in training data
The the the table compares several document parsing benchmarks, highlighting differences in language coverage, image types, and photograph conditions. MDPBench stands out with broader language support and a focus on photographed documents under diverse real-world conditions. MDPBench includes more languages and a wider range of photograph conditions compared to other benchmarks. Most existing benchmarks focus on digital-born documents, while MDPBench emphasizes photographed and real-world scenarios. MDPBench features a larger number of document images and includes diverse photographic challenges such as background variation and camera orientation.

The authors evaluate various document parsing models on a multilingual benchmark that includes both digital and photographed documents. Results show significant performance gaps between proprietary and open-source models, with notable declines on photographed documents and non-Latin-script languages. Proprietary models outperform open-source models, particularly in photographed document scenarios. Performance drops substantially on photographed documents and non-Latin-script languages across all models. Models exhibit language-specific errors, including issues with reading order, hallucinations, and incorrect segmentation.
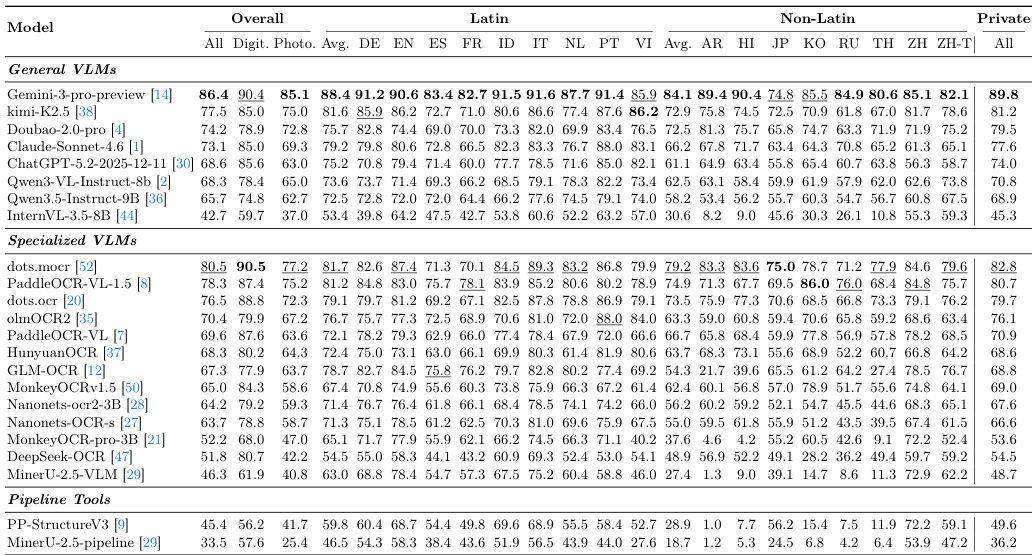
The authors evaluate various document parsing models using MDPBench, a multilingual benchmark designed to test performance across diverse image types and real-world photographic conditions. The experiments reveal that proprietary models generally outperform open-source alternatives, though all models struggle with non-Latin scripts and photographed documents compared to digital-born ones. Ultimately, the results highlight significant challenges in handling language-specific reading orders and complex photographic environments.