Command Palette
Search for a command to run...
تكامل بيانات النص
تكامل بيانات النص
Md Ataur Rahman Dimitris Sacharidis Oscar Romero Sergi Nadal
الملخص
تتخذ البيانات أشكالًا متعددة. ومن منظور سطحي، يمكن تصنيفها إلى بيانات مهيكلة (مثل العلاقات أو أزواج المفاتيح والقيم) أو بيانات غير مهيكلة (مثل النصوص والصور). حتى الآن، أظهرت الآلات كفاءة كبيرة في معالجة البيانات المهيكلة والاستدلال عليها، شريطة أن تتبع مخططًا دقيقًا. غير أن تنوع البيانات يشكل تحديًا جوهريًا فيما يتعلق بكيفية تخزين أنواع البيانات المتنوعة ومعالجتها بطريقة ذات مغزى. وتُعد تكامل البيانات، الذي يُعد ركيزة أساسية في خط أنابيب هندسة البيانات، الحل الأمثل لهذه الإشكالية من خلال دمج مصادر بيانات متباينة وتوفير وصول موحد إليها للمستخدمين النهائيين. ومع ذلك، اعتمدت معظم أنظمة تكامل البيانات حتى الآن على دمج مصادر البيانات المهيكلة فحسب. غير أن البيانات غير المهيكلة (المعروفة أيضًا بالنصوص الحرة) تحتوي على ثروة هائلة من المعرفة بانتظار الاستغلال. وعليه، نبدأ في هذا الفصل بتبرير أهمية دمج البيانات النصية، لننتقل بعد ذلك إلى استعراض التحديات التي تواجه هذا الدمج، وأحدث التطورات في هذا المجال، والمشكلات المفتوحة التي لم تُحل بعد.
One-sentence Summary
The authors propose a comprehensive framework for integrating textual data with structured sources using Knowledge Graphs and LLMs to overcome heterogeneity, enabling data discovery, sparsity mitigation, and augmentation across diverse enterprise scenarios.
Key Contributions
- The chapter presents a case for integrating textual data with structured sources to address data heterogeneity, leveraging Knowledge Graphs as a unified representation model that captures semantic relationships and contextual information.
- The work outlines three specific benefits of this integration approach, demonstrating how textual data can mitigate data sparsity, enable data discovery, and enhance integration through data augmentation with concrete motivating examples.
- The text identifies the need for a scalable and automated framework that combines techniques from Natural Language Processing, Machine Learning, and the Semantic Web to overcome the limitations of current systems that rely on manual extraction of structured information from text.
Introduction
Data integration is essential for unifying disparate sources, yet traditional systems struggle to incorporate the vast amounts of unstructured text that hold critical contextual knowledge. Prior approaches often rely on fixed schemas or require extensive manual annotation, making them ill-suited for handling the semantic ambiguity, heterogeneity, and dynamic nature of real-world textual data. The authors address these gaps by advocating for a framework that leverages Knowledge Graphs and advanced NLP techniques, including LLMs and RAG, to automatically conceptualize text and enrich structured datasets. This approach aims to mitigate data sparsity, enable discovery of implicit relationships, and support scalable schema evolution without the heavy resource costs of retraining models for every new integration scenario.
Dataset
- The dataset integrates disjoint structured medical records with unstructured clinical text to bridge schema gaps and discover new relationships.
- Structured sources include a Disease Dataset containing diagnoses and surgeries, a Complication Dataset tracking adverse events and drugs, a Patients Table with demographics, and a Medications Table listing prescriptions.
- Unstructured data consists of clinical book excerpts and patient notes that provide context for linking entities like anatomy, organs, and specific medical conditions.
- The authors use textual data to perform data augmentation by extracting inferred concepts and join-paths, such as connecting diseases to complications via anatomical entities.
- Processing involves identifying relationships in text to create new associative tables, such as a Prescription Table that links patients to medications without shared primary keys.
- This approach enables schema evolution and instance enrichment, allowing the system to adapt to previously unknown information and produce a unified view for complex queries.
Method
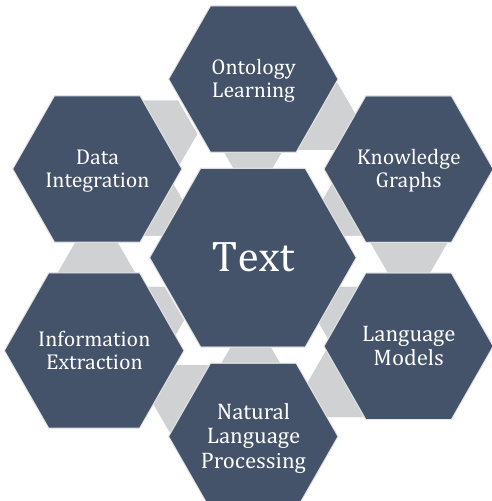
The authors propose a comprehensive framework for text data integration, positioning Ontology Learning (OL) as the central mechanism to transform unstructured text into structured Knowledge Graphs (KGs). As illustrated in the central framework diagram, this approach integrates various NLP components, including Information Extraction, Language Models, and Data Integration, to facilitate robust reasoning and data management.
The construction of the ontology follows a hierarchical progression, moving from basic linguistic units to complex logical rules. Refer to the hierarchical structure diagram which outlines these levels, starting from Terms and Synonyms, advancing to Concepts and Concept Hierarchies, then Relations, and finally culminating in Concept and Relation Representation and Axioms.
The initial phase involves concept extraction, where entities are identified from text using techniques such as Named Entity Recognition (NER), co-reference resolution, or syntactic parsing. More recent practices utilize neural Language Models (LMs) based on transformer architectures, such as BERT or T5, to extract concepts in a supervised manner. These concepts are then organized into taxonomic relationships (hypernym/hyponym) using lexico-syntactic patterns or distributional semantics.
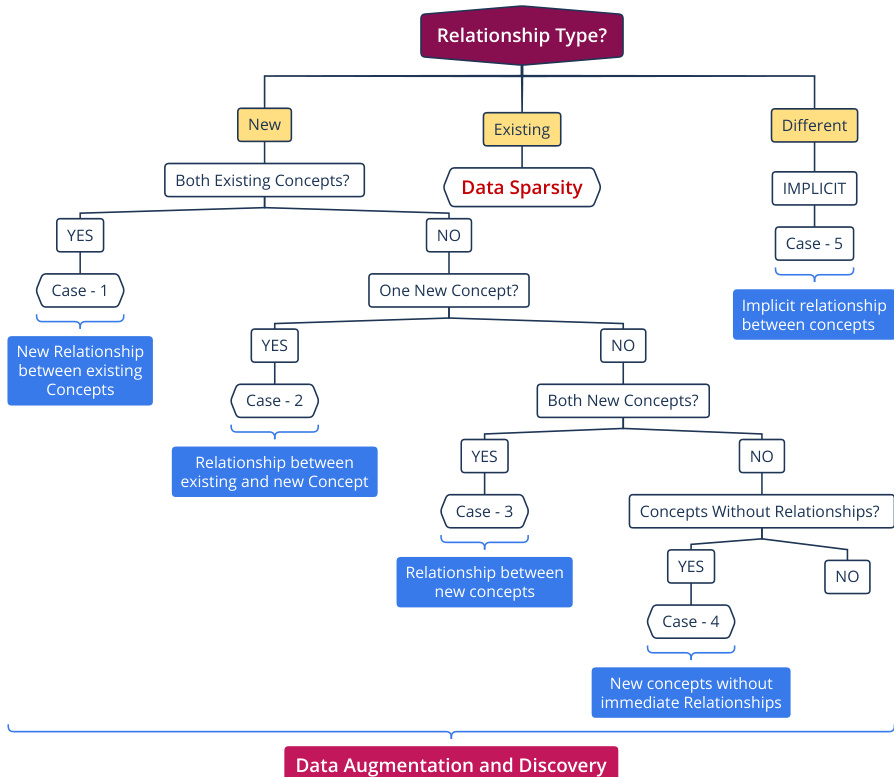
Following concept identification, the method focuses on extracting non-taxonomic relations, such as attributes, thematic roles, meronymy, and causality. The system categorizes relationship types based on the status of the underlying concepts (existing vs. new) to handle data sparsity and facilitate discovery. The decision process for relationship types is detailed in the flowchart, which branches into cases for new relationships between existing concepts, relationships involving new concepts, and implicit relationships.
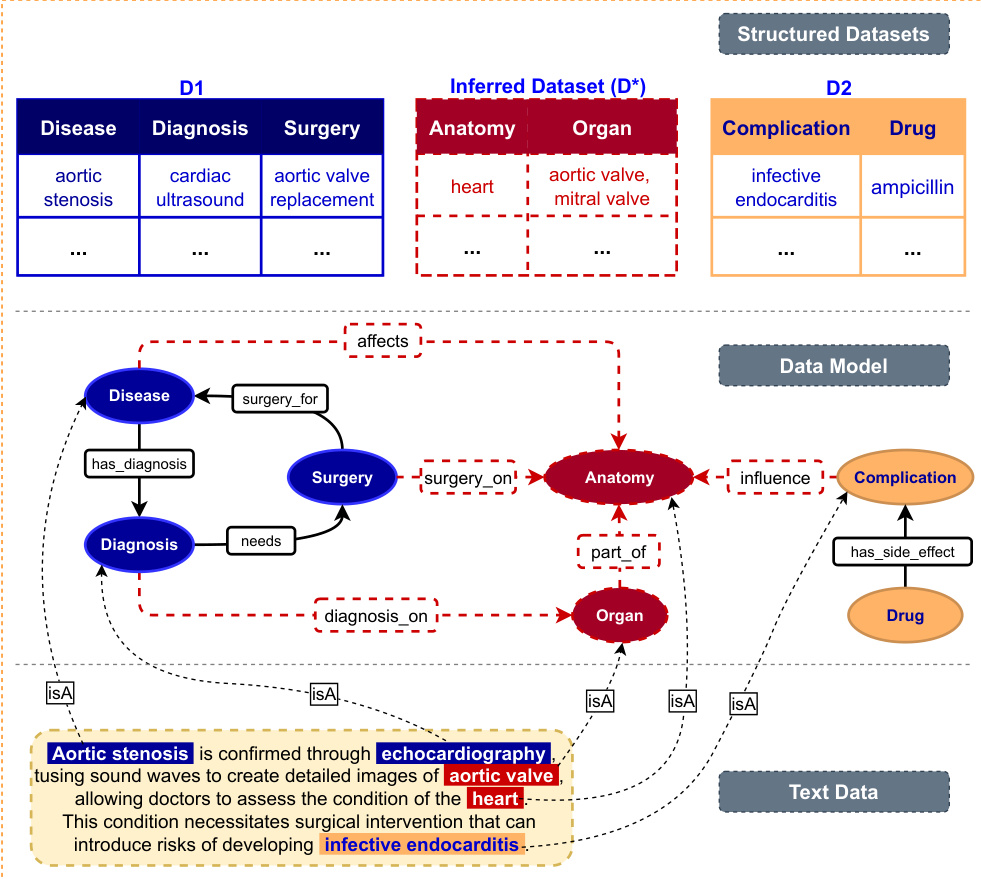
To represent this data, the authors advocate for modeling the information as a Knowledge Graph with a dynamic schema, utilizing representation languages like RDF, RDFS, and OWL. This allows for high-level abstraction and reasoning capabilities that simple data graphs lack. The final Data Model integrates structured datasets with inferred data derived from text, linking entities such as Disease, Surgery, and Anatomy through defined relationships like surgery_for or affects.
The process concludes with the definition of Axioms, which are rules and constraints that govern the interaction between concepts and relations. These axioms, often expressed in first-order logic or description logics, add expressivity to the ontology and are crucial for automatic reasoning and knowledge discovery within the domain.