Command Palette
Search for a command to run...
TAPS: توزيعات اقتراح واعية بالمهام لأخذ العينات التخمينية
TAPS: توزيعات اقتراح واعية بالمهام لأخذ العينات التخمينية
Mohamad Zbib Mohamad Bazzi Ammar Mohanna Hasan Abed Al Kader Hammoud Bernard Ghanem
الملخص
تُسرع تقنية الترميز التخميني (Speculative Decoding) عملية التوليد التلقائي (autoregressive generation) من خلال السماح بنموذج مسودة خفيف الوزن باقتراح رموز (tokens) مستقبلية، يتحقق منها بعد ذلك نموذج هدف أكبر بشكل متوازٍ. ومع ذلك، في الممارسة العملية، تُدرَّب نماذج المسودة عادةً على مجموعات بيانات عامة واسعة النطاق، مما يترك غامضًا مدى اعتماد جودة الترميز التخميني على توزيع تدريب نموذج المسودة. ندرس هذا السؤال باستخدام نماذج مسودة خفيفة الوزن من نوع HASS و EAGLE-2، مُدرَّبة على مجموعات بيانات MathInstruct و ShareGPT ومتغيرات البيانات المختلطة، مع التقييم على مقاييس MT-Bench و GSM8K و MATH-500 و SVAMP. وعند القياس بناءً على طول القبول (acceptance length)، يُظهر التدريب المخصص للمهام تخصصًا واضحًا: حيث تتفوق نماذج المسودة المُدرَّبة على MathInstruct في مقاييس الاستدلال، بينما تتفوق تلك المُدرَّبة على ShareGPT في MT-Bench. كما يُحسّن التدريب على بيانات مختلطة من المتانة، لكن الخلطات الأكبر لا تهيمن عبر درجات حرارة الترميز (decoding temperatures) المختلفة.كما ندرس كيفية دمج نماذج المسودة المتخصصة أثناء الاستدلال (inference). فمتوسط نقاط التفتيش (checkpoint averaging) البسيط يؤدي أداءً ضعيفًا، في حين أن التوجيه القائم على الثقة (confidence-based routing) يُحسّن الأداء مقارنة بنماذج المسودة أحادية النطاق، ويؤدي التحقق من الشجرة المدمجة (merged-tree verification) إلى تحقيق أعلى طول قبول بشكل عام لكلا الهيكلين الأساسيين (backbones). وأخيرًا، تُعدّ الثقة إشارة توجيه أكثر فائدة من الانتروبيا (entropy): فمع أن الرموز المرفوضة تميل إلى امتلاك انتروبيا أعلى، فإن الثقة تُنتج قرارات توجيه على مستوى المقاييس أكثر وضوحًا. تُظهر هذه النتائج أن جودة الترميز التخميني لا تعتمد فقط على بنية نموذج المسودة، بل أيضًا على مدى التوافق بين بيانات تدريب المسودة وعبء العمل اللاحق (downstream workload)، وأن نماذج المسودة المتخصصة يُدمجها بشكل أفضل أثناء الاستدلال بدلاً من فضاء الأوزان (weight space).
One-sentence Summary
Researchers from KAUST and the American University of Beirut propose TAPS, demonstrating that task-specific training of HASS and EAGLE-2 drafters significantly boosts speculative decoding acceptance on matched workloads. Their work reveals that combining specialized models via confidence-based routing or merged-tree verification at inference time outperforms naive weight averaging, optimizing LLM throughput for diverse domains like math and conversation.
Key Contributions
- The paper introduces an empirical analysis showing that task-specific training of draft models yields clear specialization, where MathInstruct-trained drafters excel on reasoning benchmarks while ShareGPT-trained drafters perform best on MT-Bench.
- This work demonstrates that combining specialized drafters at inference time via confidence-based routing and merged-tree verification significantly outperforms naive weight-space averaging, achieving the highest acceptance length across both HASS and EAGLE-2 backbones.
- Results indicate that confidence serves as a more effective routing signal than entropy for making benchmark-level decisions, as rejected tokens exhibit higher entropy but confidence provides clearer distinctions for selecting the optimal drafter.
Introduction
Autoregressive generation in LLMs faces a significant inference bottleneck that speculative decoding addresses by using a lightweight drafter to propose tokens for parallel verification by a larger target model. While prior work focuses on improving draft architectures or verification procedures, most draft models are trained on broad generic corpora, leaving the impact of training data distribution on acceptance quality under-explored. The authors leverage task-specific training on datasets like MathInstruct and ShareGPT to demonstrate that specialized drafters significantly outperform generic ones on matched benchmarks. They further show that combining these specialists at inference time through confidence-based routing and merged-tree verification yields superior results compared to naive weight averaging or mixed-data training.
Method
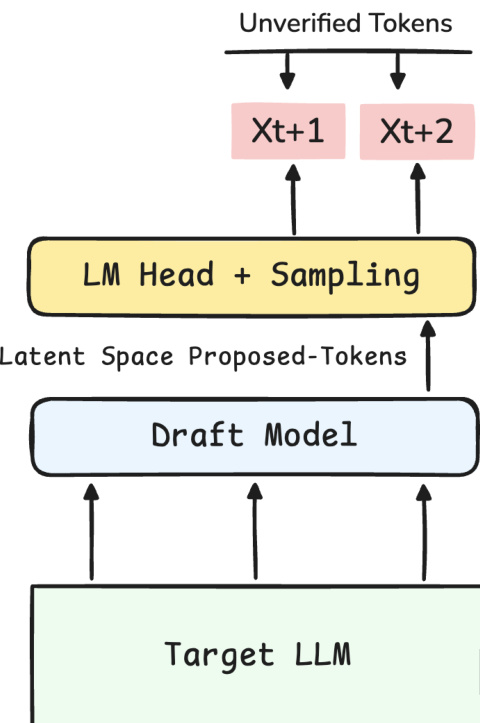
The authors leverage a speculative decoding framework where a lightweight draft model proposes future tokens for verification by a larger target LLM. As shown in the framework diagram, the process begins with the Target LLM providing context to the Draft Model. The draft model operates in latent space to propose tokens, which are then passed through an LM Head and sampling layer to generate unverified tokens like Xt+1 and Xt+2.
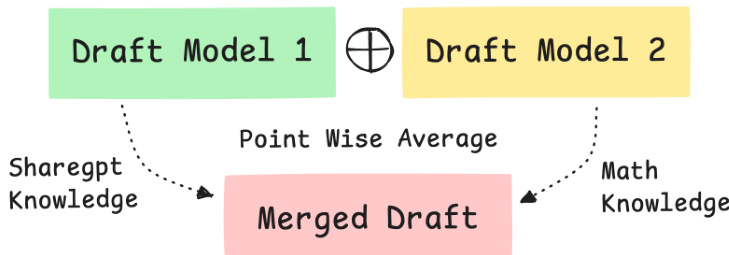
To enhance the quality of these drafts, the authors explore composition strategies for specialized models. One baseline approach is checkpoint averaging. As illustrated in the figure below, parameters from distinct draft models, such as one trained on ShareGPT data and another on Math data, are combined via point-wise averaging to create a single merged draft model.
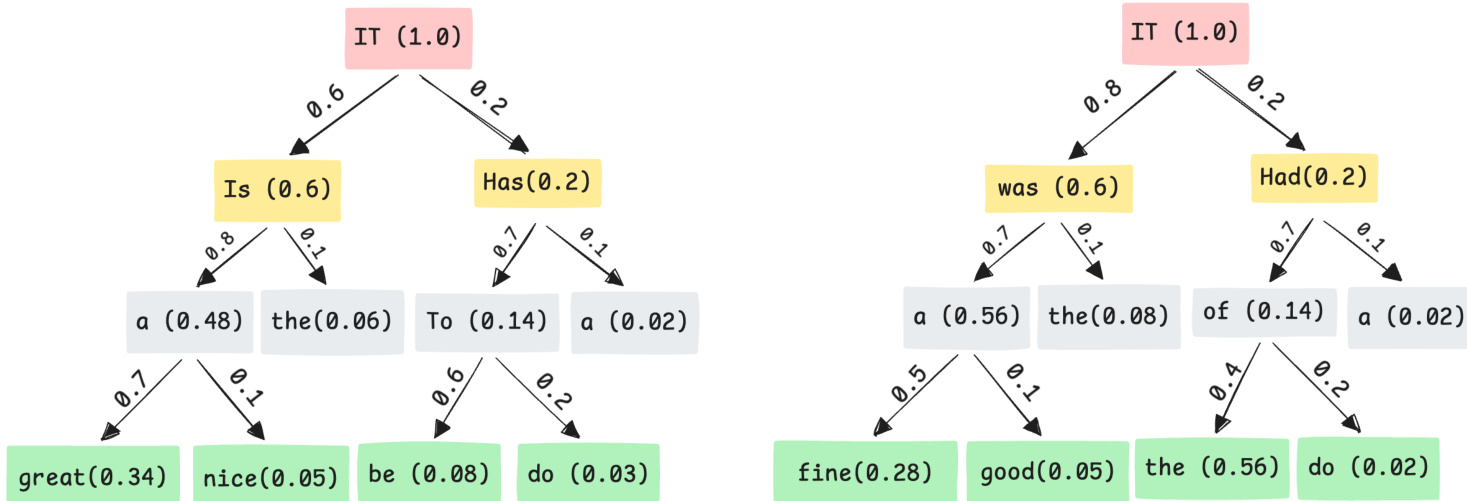
Alternatively, the authors investigate inference-time composition strategies that maintain separate specialized checkpoints. In this setting, specialized models generate distinct candidate continuations with associated confidence scores, as depicted in the tree diagrams showing separate branches for different experts.
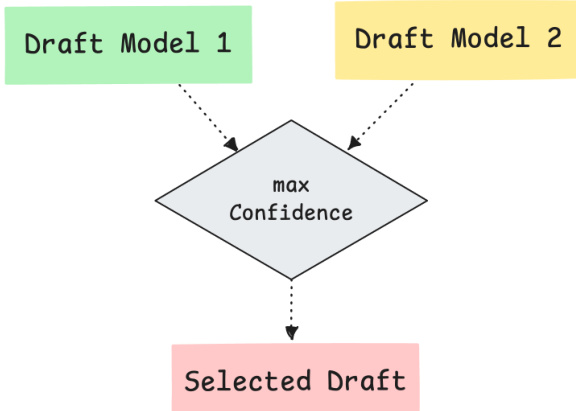
For inference-time selection, the authors propose confidence routing. This method generates separate draft trees from different checkpoints and selects the tree with the higher mean node confidence before verification, as shown in the routing diagram where the max confidence path is chosen.
A more comprehensive strategy is merged-tree verification. Instead of selecting a single tree, the method packs multiple draft trees under a shared root. This allows the verifier to evaluate candidates from all specialists in a single parallel pass. The flattened merged-tree input preserves ancestry through tree attention masks and depth-based position ids, enabling the verifier to process both specialized subtrees without cross-subtree attention.
Experiment
- Single-domain training validates that drafters achieve significantly higher acceptance lengths when their training distribution matches the target workload, with mathematical models excelling on reasoning tasks and conversational models on dialogue benchmarks.
- Mixed-data training demonstrates that combining domains improves cross-domain robustness, though the optimal mixture ratio depends on the decoding temperature and does not guarantee uniform generalization.
- Inference-time composition strategies, specifically confidence-based routing and merged-tree verification, substantially outperform weight-space averaging, proving that keeping specialized models separate and combining them at runtime is more effective than merging parameters.
- Analysis of confidence, entropy, and speculative depth reveals that confidence is the superior signal for routing between specialists, while deeper speculative steps increasingly favor task-matched experts over broad-coverage models.
- The overall conclusion establishes that proposal quality in speculative decoding is a function of both architecture and training distribution, necessitating task-aware drafting and dynamic composition rather than static, averaged checkpoints.