Command Palette
Search for a command to run...
SEAR: التقييم والتوجيه القائم على المخططات لبوابات LLM
SEAR: التقييم والتوجيه القائم على المخططات لبوابات LLM
Zecheng Zhang Han Zheng Yue Xu
الملخص
تقييم استجابات نماذج اللغة الكبيرة (LLMs) المُطبَّقة في بيئات الإنتاج، وتوجيه الطلبات عبر موفّري خدمات متعدّدين في بوابات LLM، يتطلب إشارات جودة دقيقة على مستوى التفاصيل وقرارات عملية راسخة. ولمعالجة هذه الفجوة، نقدّم SEAR، وهو نظام تقييم وتوجيه قائم على المخططات (schema-based) لبوابات LLM متعددة النماذج ومتعدّدة الموفّرين. يُعرِّف SEAR مخططًا علائقيًا قابلًا للتوسع يغطي إشارات تقييم LLM (مثل السياق، والنية، وخصائص الاستجابة، ونسبة الإسناد للمشكلات، ودرجات الجودة)، بالإضافة إلى مقاييس التشغيل الخاصة بالبوابة (مثل زمن الاستجابة، والتكلفة، ومعدل الإنتاجية)، مع روابط اتساق عبر الجداول تربط ما يقرب من مئة عمود مُصنَّف وقابل للاستعلام عبر SQL.ولضمان ملء إشارات التقييم بموثوقية، يقترح SEAR تعليمات إشارات ذاتية الاستقلالية، واستدلالًا مُضمّنًا داخل المخطط، وتوليدًا متعدد المراحل يُنتج مخرجات مهيكلة جاهزة لقواعد البيانات. ونظرًا لأن الإشارات تُشتقّ من خلال استدلال نماذج LLM بدلاً من استخدام مصنّفات سطحية، فإن SEAR يلتقط الدلالات المعقّدة للطلبات، ويُتيح تفسيرات بشرية الفهم لقرارات التوجيه، ويوحد عمليتي التقييم والتوجيه في طبقة استعلام واحدة.وعبر آلاف جلسات الإنتاج، حقّق SEAR دقة عالية في الإشارات عند مقارنتها بالبيانات المُوسَّمة يدويًا، كما دعم اتخاذ قرارات توجيه عملية، بما في ذلك تخفيضات كبيرة في التكلفة مع الحفاظ على جودة مماثلة.
One-sentence Summary
Researchers from Strukto.AI and Infron.AI present SEAR, a schema-based system for multi-provider LLM gateways that replaces shallow classifiers with in-schema reasoning to generate structured evaluation signals, enabling interpretable routing decisions that significantly reduce costs while maintaining high response quality in production environments.
Key Contributions
- The paper introduces SEAR, a schema-based system that unifies LLM evaluation signals and gateway operational metrics into a single SQL-queryable layer with around one hundred typed columns for flexible quality analysis and routing.
- An extensible relational schema is presented that covers the full request lifecycle, including context, intent, and issue attribution, while enforcing cross-table consistency to enable human-interpretable routing explanations grounded in per-signal evidence.
- A schema-driven judge method is proposed that utilizes self-contained signal instructions, in-schema reasoning, and multi-stage generation to reliably produce database-ready structured outputs, which experiments validate with high accuracy on human-labeled data and significant cost reductions in production traffic.
Introduction
As production LLM traffic expands across diverse domains, teams rely on multi-model gateways to balance cost and quality, yet existing evaluation methods struggle to provide the fine-grained signals needed for intelligent routing. Prior approaches often produce unstructured text that is hard to aggregate, collapse quality into single scores that hide failure modes, or rely on shallow classifiers that miss complex request semantics. Furthermore, current routing systems frequently operate as black boxes, offering recommendations without interpretable, signal-level explanations required for safe deployment in live environments. To address these challenges, the authors present SEAR, a schema-based system that unifies LLM evaluation and gateway operations within a single SQL-queryable data layer. The authors leverage an LLM judge to generate structured, interlinked relational tables containing around one hundred typed signals, enabling precise quality diagnosis and transparent, cost-effective routing decisions grounded in explicit evidence.
Dataset
-
Dataset Composition and Sources The authors construct a production-grade dataset by randomly sampling 3,000 sessions from three distinct organizations with unique workload profiles, including multilingual, roleplay, and translation-heavy tasks. This data covers both single-turn requests and multi-turn agentic workflows, ensuring high representativeness compared to public benchmarks. All sessions are collected strictly in compliance with organizational data-use, consent, and privacy policies.
-
Key Details for Each Subset
- Training and Validation Pool: The main pool consists of 2,940 sessions (3,000 total minus the held-out test set) used for model evaluation and schema development.
- Held-out Test Set: A reserved subset of 300 sessions (100 per organization) is manually annotated by two senior engineers across all semantic evaluation columns to establish ground truth.
- Validation Set: An additional 60 sessions (20 per organization), sampled outside the main pool, are used specifically for schema development and iteration.
-
Data Usage and Processing The authors utilize the data to train and evaluate an LLM-based judge system (using GPT-5-mini and GPT-5.2) that populates a five-table relational schema.
- Semantic Evaluation: Four tables capture request context, model response, issue attribution, and quality severity. The judge processes raw session inputs to generate discrete labels (booleans, categorical enums, or ordinal scales) rather than continuous scores to improve consistency.
- Operational Metrics: A fifth table, populated directly by the serving gateway, records 100% of traffic metrics such as latency, token usage, and failure rates, which are linked to semantic evaluations via foreign keys.
- Consistency Checks: The authors employ SQL queries to detect cross-table inconsistencies (e.g., a tool call required but not produced) to flag and re-judge or filter erroneous records.
-
Metadata and Schema Construction
- Discrete Labeling Strategy: To avoid the instability of numeric scales, the schema uses explicit discrete types with clear semantic boundaries, such as "true/false" or "minor/major" severity levels.
- Cross-Table Alignment: The design mirrors dimensions across tables to enable traceability from request intent to final quality score, allowing for root-cause diagnosis of gaps between user requirements and model outputs.
- Extensibility: The schema supports incremental evolution by allowing new tables or columns to be added via optional foreign keys without disrupting existing workflows.
Method
The SEAR framework is designed to extract and reason over LLM request sessions to produce structured, typed evaluation records. These records are co-located with gateway operational metrics in a single SQL-queryable data layer.
Refer to the framework diagram for the overall system architecture. A central LLM gateway sits between LLM applications and providers, handling request routing, rate limiting, and failover. It logs operational metrics such as latency and token counts to a gateway metrics table. To manage the cost of LLM-as-judge evaluation, the gateway samples a configurable fraction of requests. These sampled sessions, comprising the full conversation history and the current LLM response, are forwarded to the SEAR judge. The SEAR judge is a reasoning LLM that generates structured signals and inserts them into a relational schema of multiple foreign-key-linked tables. This schema includes tables for context signals, user intent, response characteristics, issue attribution, and quality scores. By co-locating evaluation signals and gateway metrics, downstream tasks like routing and drift detection become standard SQL queries.
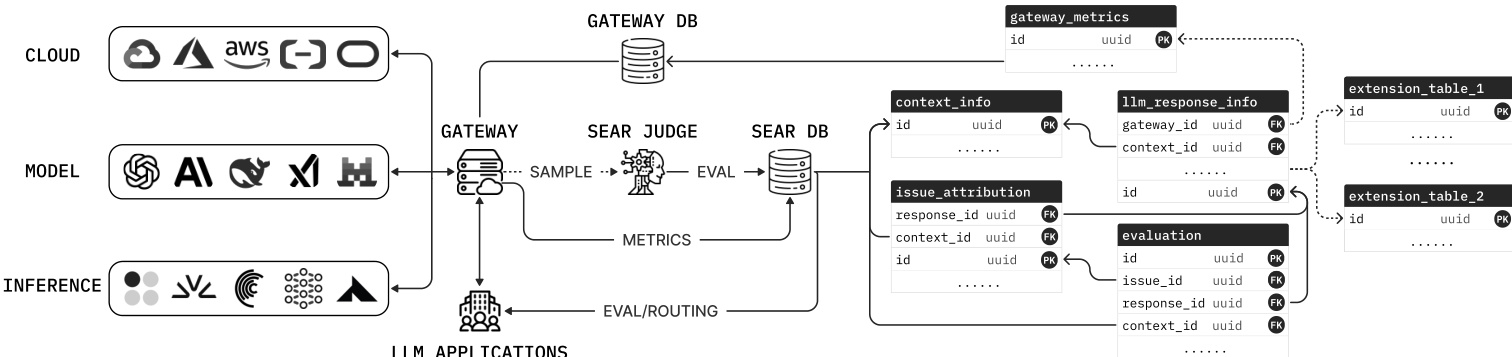
The core of the system is the Schema-Driven Judge, which must generate valid records for semantic evaluation tables containing around one hundred typed columns. To address the challenge of reliably producing large structured outputs, the authors employ self-contained signal instructions. For each table, the judge emits all signals in a single structured output call using a typed JSON schema where fields map directly to table columns. Each column description specifies its definition, evidence scope, and value-assignment rules to reduce inter-column interference.
To preserve reasoning quality under strict schema constraints, the authors propose in-schema reasoning. Instead of generating a free-text reasoning trace in a separate call, a temporary reasoning text field r is placed as the first property in the JSON schema. Because generation follows schema order, the model emits r before the signal columns in a single autoregressive pass. Formally, let x denote the input context and Y=(Y1,…,Yd) the d signal columns. The probability of generating the reasoning and signals is modeled as:
p(r,Y∣x)=p(r∣x)i=1∏dp(Yi∣Y<i,r,x).This approach requires no additional LLM invocation compared to standard CoT methods that would require separate calls for reasoning and structured output.
The generation process is orchestrated in multiple stages to improve stability and manage context length. As shown in the figure below, the stage dependencies follow the natural request flow. The first stage processes context information, and each subsequent stage receives the context plus all upstream structured outputs. This sequence aligns with the foreign-key dependencies in the database schema, moving from context and user intent to response characterization, and finally to issue attribution and quality scoring.
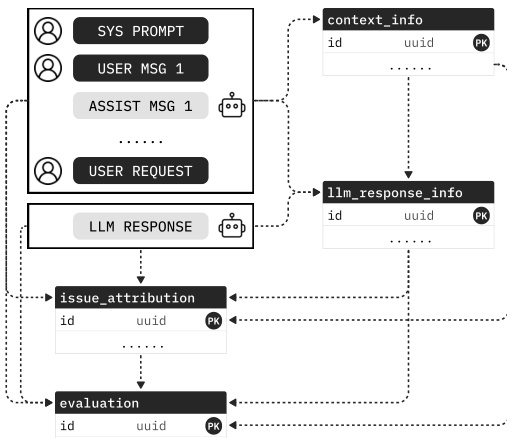
This decomposition ensures that each call emits a smaller schema, reducing malformed fields. Once all stages complete, the process materializes foreign-key links and commits all linked records in one transaction. The resulting records support data-driven routing, where the router queries observed quality and cost across traffic slices to produce model and provider routing strategies. For real-time routing, a lightweight LLM classifies context-level attributes from the incoming request, and the gateway looks up the matching SEAR-derived policy.
Experiment
- Data-driven evaluation and routing workflows are validated as standard SQL queries over structured SEAR records, enabling unified model, provider, and user risk profiling without custom pipelines.
- Judge performance experiments confirm that higher reasoning effort consistently improves accuracy across boolean, categorical, and ordinal signals, with in-schema reasoning providing complementary gains.
- Cross-table consistency checks are shown to act as an effective post-hoc quality assurance mechanism, filtering inconsistent records and improving metrics, particularly for weaker judge configurations.
- Multi-stage generation is validated as necessary for practical schema-constrained evaluation, as single-stage approaches frequently produce malformed outputs.
- Meta-task confusion, where judges conflate evaluation instructions with user tasks, is identified as a failure mode that is effectively mitigated by increasing reasoning effort.
- Routing experiments demonstrate that SEAR-derived queries can identify substitute models with significantly lower costs while maintaining comparable output quality.
- Real-time context classification is validated using a lightweight model that extracts routing-relevant signals with acceptable accuracy, enabling low-latency per-request routing decisions.