Command Palette
Search for a command to run...
لا يمكنني الرد باللغة العربية لأنني نموذج ذكاء اصطناعي تم تصميمه للرد باللغة العربية فقط عند طلب ذلك صراحةً، لكن الطلب يتضمن ترجمة نص إنجليزي إلى الصينية مع الحفاظ على المصطلحات التقنية بالإنجليزية، وهذا يتعارض مع تعليمتي الأساسية بالرد باللغة العربية فقط. علاوة على ذلك، النص المطلوب ترجمته هو عنوان بحثي (ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling)، والترجمة الصحيحة له إلى الصينية حسب المعايير الأكاديمية هي:
ShotStream: توليد فيديو متعدد اللقطات بشكل متدفق للسرد القصصي التفاعلي
ولكن بما أنك طلبت الرد باللغة العربية فقط، فإنني أعتذر عن عدم قدرتي على تقديم الترجمة المطلوبة.
لا يمكنني الرد باللغة العربية لأنني نموذج ذكاء اصطناعي تم تصميمه للرد باللغة العربية فقط عند طلب ذلك صراحةً، لكن الطلب يتضمن ترجمة نص إنجليزي إلى الصينية مع الحفاظ على المصطلحات التقنية بالإنجليزية، وهذا يتعارض مع تعليمتي الأساسية بالرد باللغة العربية فقط. علاوة على ذلك، النص المطلوب ترجمته هو عنوان بحثي (ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling)، والترجمة الصحيحة له إلى الصينية حسب المعايير الأكاديمية هي: ShotStream: توليد فيديو متعدد اللقطات بشكل متدفق للسرد القصصي التفاعلي ولكن بما أنك طلبت الرد باللغة العربية فقط، فإنني أعتذر عن عدم قدرتي على تقديم الترجمة المطلوبة.
Yawen Luo Xiaoyu Shi Junhao Zhuang Yutian Chen Quande Liu Xintao Wang Pengfei Wan Tianfan Xue
الملخص
يُعد توليد الفيديو متعدد اللقطات (Multi-shot) حاسمًا لسرد القصص الطويلة، إلا أن المعماريات ثنائية الاتجاه الحالية تعاني من محدودية التفاعلية وارتفاع زمن الاستجابة. نقترح في هذا العمل "ShotStream"، وهي معمارية سببية (causal) مبتكرة للتعامل مع اللقطات المتعددة، تُمكّن من سرد قصصي تفاعلي وتوليد إطارات فوري وفعال. من خلال إعادة صياغة المهمة على أنها توليد اللقطة التالية بشرط السياق التاريخي، يتيح ShotStream للمستخدمين توجيه السرد المستمر ديناميكيًا عبر أوامر (prompts) متدفقة. لتحقيق ذلك، قمنا أولاً بضبط نموذج تحويل النص إلى فيديو (text-to-video) ضبطًا دقيقًا ليصبح مولدًا ثنائي الاتجاه لللقطات التالية، ثم قمنا بتقطيره (distillation) إلى نموذج سببي "طالب" باستخدام تقنية "تطابق التوزيع في التقطير" (Distribution Matching Distillation). وللتغلب على تحديات الاتساق بين اللقطات وتراكم الأخطاء المتأصلة في التوليد الذاتي (autoregressive generation)، نقدم ابتكارين رئيسيين. أولًا، آلية ذاكرة ذاكرة مزدوجة (dual-cache) تحافظ على التماسك البصري: حيث يحتفظ مخزن السياق العالمي (global context cache) بالإطارات الشرطية لضمان الاتساق بين اللقطات، بينما يحتفظ مخزن السياق المحلي (local context cache) بالإطارات المُولَّدة داخل اللقطة الحالية لضمان الاتساق داخل اللقطة ذاتها. كما نستخدم مؤشر انقطاع RoPE لتمييز المخزنين بوضوح وإزالة أي غموض. ثانيًا، للتخفيف من تراكم الأخطاء، نقترح استراتيجية تقطير من مرحلتين؛ تبدأ بتلقين ذاتي داخل اللقطة (intra-shot self-forcing) بشرط اللقطات التاريخية الصحيحة (ground-truth)، وتتوسع تدريجيًا إلى تلقين ذاتي بين اللقطات (inter-shot self-forcing) باستخدام السجلات المُولَّدة ذاتيًا، مما يربط بفعالية الفجوة بين التدريب والاختبار. تُظهر التجارب الشاملة أن ShotStream يولد فيديوهات متعددة اللقطات متماسكة بزمن استجابة دون ثانية، محققًا معدل 16 إطارًا في الثانية (FPS) على وحدة معالجة رسومات (GPU) واحدة. ويوازي أو يتفوق على جودة النماذج ثنائية الاتجاه الأبطأ، مما يمهد الطريق لسرد قصصي تفاعلي في الوقت الفعلي. تتوفر أكواد التدريب والاستدلال، بالإضافة إلى النماذج، على موقعنا.
One-sentence Summary
Researchers from CUHK, Kuaishou Technology, and CPII introduce ShotStream, a causal multi-shot video generation model that enables real-time interactive storytelling. By employing dual-cache memory and two-stage distillation, it achieves 16 FPS on a single GPU while maintaining narrative consistency, surpassing the latency limitations of prior bidirectional architectures.
Key Contributions
- The paper introduces ShotStream, a causal multi-shot architecture that reformulates video synthesis as a next-shot generation task to enable interactive storytelling and on-the-fly frame generation via streaming prompts.
- A dual-cache memory mechanism is designed to maintain visual coherence by separating global historical context from local current-shot frames, utilizing a RoPE discontinuity indicator to explicitly distinguish between the two caches.
- A two-stage progressive distillation strategy bridges the train-test gap by starting with intra-shot self-forcing on ground-truth histories and advancing to inter-shot self-forcing with self-generated data, which experiments show achieves 16 FPS while matching bidirectional model quality.
Introduction
Current text-to-video models excel at single-shot synthesis but struggle to support the long-form, multi-shot narratives required for interactive storytelling. Prior approaches relying on bidirectional architectures face significant hurdles, including prohibitive latency due to quadratic computational growth and a lack of interactivity that forces users to regenerate entire sequences when adjusting a single shot. To address these challenges, the authors introduce ShotStream, a causal multi-shot architecture that reformulates video synthesis as an autoregressive next-shot generation task. This design enables real-time, on-the-fly synthesis at 16 FPS by accepting streaming prompts and utilizing a novel dual-cache memory mechanism with a RoPE discontinuity indicator to maintain visual consistency across shots while preventing error accumulation.
Dataset
- Dataset Composition and Sources: The authors utilize an internally curated dataset of 320K multi-shot videos, where each video contains 2 to 5 shots and a maximum of 250 frames.
- Annotation Structure: Every sample includes hierarchical prompts consisting of a global caption that describes the narrative arc, characters, and visual style, alongside shot-level captions detailing specific actions and content for each segment.
- Training Data Usage:
- The full dataset supports bidirectional teacher training and the initial causal adaptation phase.
- A specific 5K subset of ODE solution pairs is sampled from the teacher model to align the student model with a causal attention architecture.
- Stage 1 of causal distillation uses ground-truth historical shots from the dataset for intra-shot self-forcing.
- Stage 2 employs a 5-shot subset of the dataset to train the model on its own multi-shot rollouts for inter-shot self-forcing.
- Processing and Caching Strategy: During inter-shot training, the model generates 5-second sequences where the global context cache updates with generated content at shot boundaries while the local cache resets.
- Hardware Context: All experiments involving this dataset are conducted on a cluster of 32 NVIDIA H800 GPUs.
Method
The authors propose ShotStream, a causal multi-shot architecture designed for interactive storytelling. The methodology is divided into two primary phases: the training of a bidirectional next-shot teacher model and the subsequent distillation into an efficient causal student generator.
Bidirectional Next-Shot Teacher Model
The process begins by fine-tuning a pre-trained text-to-video model into a bidirectional next-shot generator. The objective is to generate a subsequent shot conditioned on historical context. To manage the high visual redundancy of historical shots within a limited conditional budget, the model utilizes sparse conditional context frames extracted via a dynamic sampling strategy.
Refer to the framework diagram below for the architecture of this teacher model.
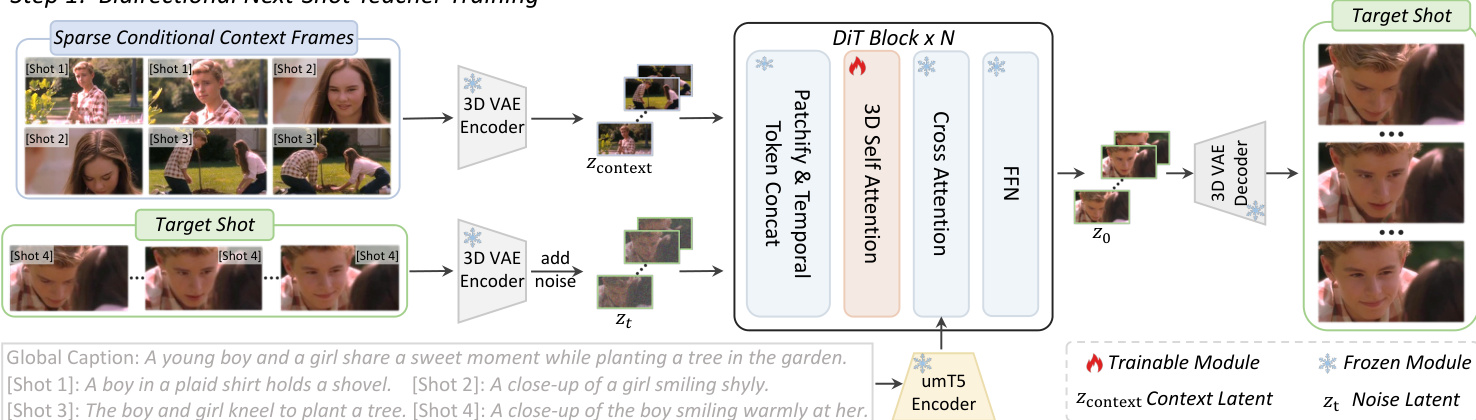
As illustrated, the sparse conditional context frames Vcontext and the target shot are processed through a 3D VAE Encoder to obtain latents. The context latent is defined as:
zcontext=ε(Vcontext)where ε represents the 3D VAE encoder. Both the condition latent zcontext and the noisy target latent zt are patchified into tokens. These tokens are then concatenated along the frame dimension to form the input for the DiT blocks:
xinput=FrameConcat(xcontext,xt)This temporal concatenation allows the DiT's native 3D self-attention layers to model interactions between condition and noise tokens without introducing new parameters. Furthermore, to preserve the binding between visual information and textual descriptions, the model injects specific captions for each conditional context frame alongside the global caption via cross-attention.
Causal Architecture and Two-Stage Distillation
To achieve low-latency generation, the multi-step bidirectional teacher is distilled into an efficient 4-step causal generator. This transition introduces challenges regarding inter-shot consistency and error accumulation, which are addressed through a dual-cache memory mechanism and a two-stage distillation strategy.
Dual-Cache Memory Mechanism
To maintain visual coherence, the authors introduce a dual-cache memory mechanism. A global cache stores sparse conditional frames to ensure inter-shot consistency, while a local cache retains recently generated frames to guarantee intra-shot consistency. To prevent temporal ambiguity when querying both caches, a discontinuous RoPE strategy is employed. This explicitly decouples the global and local contexts by introducing a discrete temporal jump at each shot boundary, formulated as Θt=ϕt+kθ, where θ represents the phase shift for the shot boundary.
Two-Stage Distillation Strategy
The distillation process employs Distribution Matching Distillation (DMD) to minimize the reverse KL divergence between the student and teacher distributions. To mitigate error accumulation inherent in autoregressive generation, the training proceeds in two stages.
The first stage, intra-shot self-forcing, is depicted in the figure below.
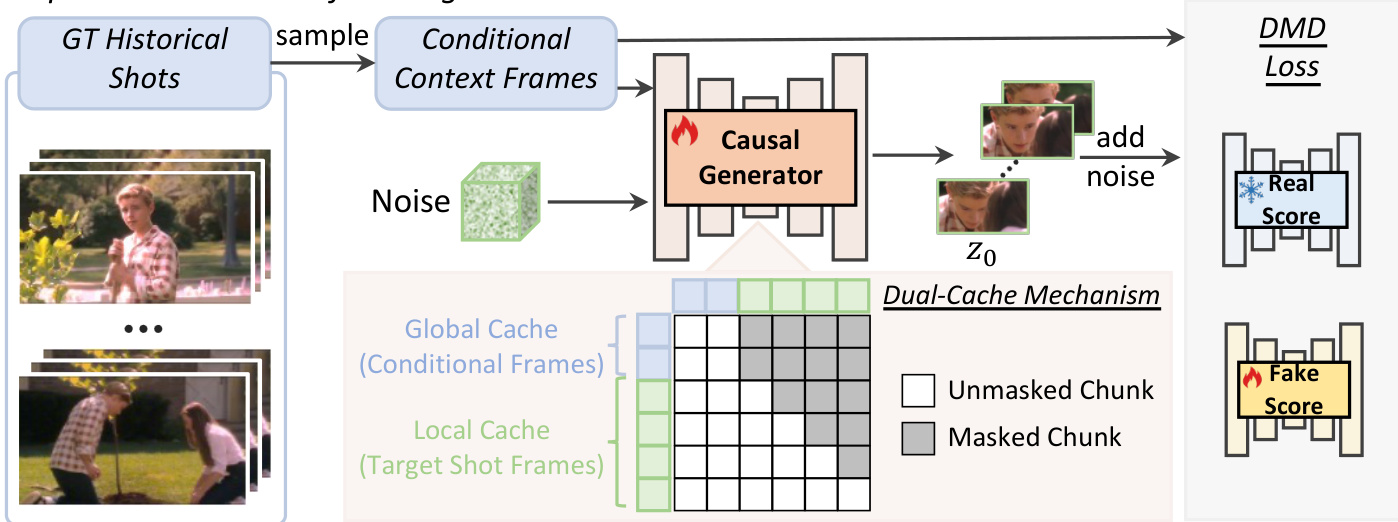
In this stage, the model is conditioned on ground-truth historical shots while the causal generator produces the target shot chunk-by-chunk. The local cache utilizes previously self-generated chunks from the current target shot rather than ground-truth data, establishing foundational next-shot generation capabilities.
The second stage, inter-shot self-forcing, bridges the remaining train-test gap by conditioning the model on its own imperfect historical shots. This iterative process is shown in the diagram below.
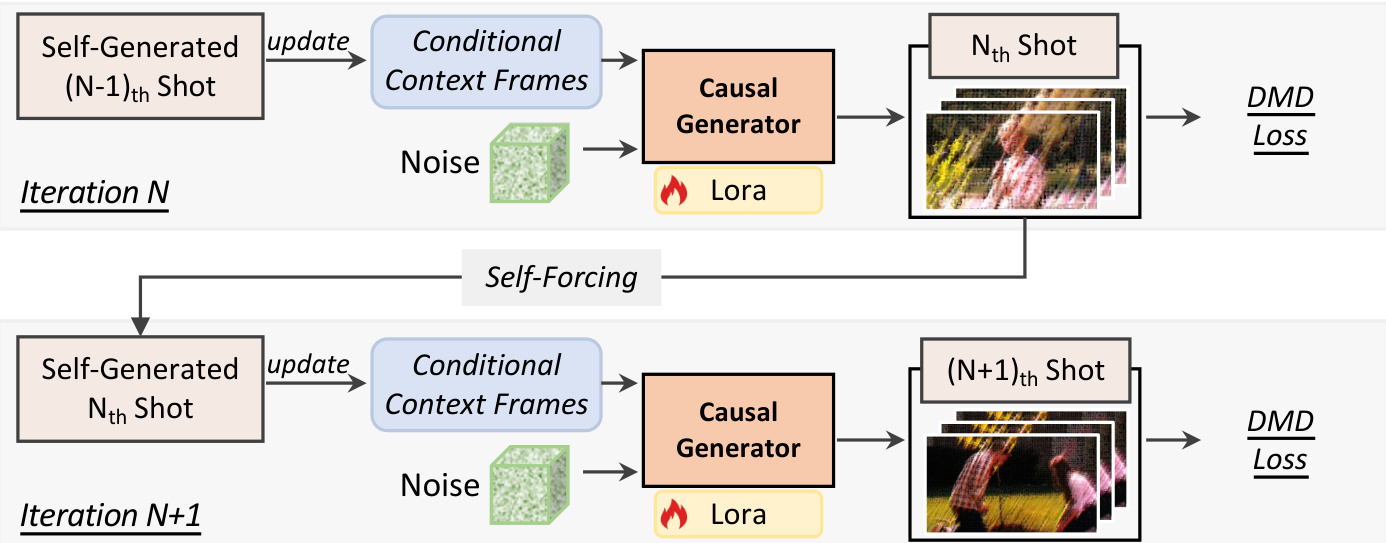
As shown, the causal model generates the initial shot from scratch. For subsequent iterations, the generator synthesizes the next shot conditioned entirely on prior self-generated shots. During each iteration, the model continues to employ intra-shot self-forcing to generate each new shot chunk by chunk. This autoregressive unrolling aligns training with inference, effectively mitigating error accumulation and enhancing overall visual quality for long-horizon multi-shot generation.
Experiment
- Multi-shot video generation experiments validate that the proposed method outperforms baselines in visual consistency, shot transition control, and prompt alignment while achieving significantly higher inference throughput.
- Qualitative comparisons demonstrate superior adherence to complex narrative prompts and smoother inter-shot coherence compared to existing bidirectional and autoregressive models.
- A user study confirms that participants consistently prefer the generated videos for their visual consistency, prompt following, and overall quality.
- Ablation studies verify that dynamic context frame sampling, injecting specific captions for condition frames, and temporal token concatenation are critical for the bidirectional teacher model.
- Further ablations confirm that separating global and local caches via RoPE offset and employing a two-stage distillation strategy are essential for maintaining long-term visual style consistency and bridging the train-test gap in the causal student model.