Command Palette
Search for a command to run...
PackForcing: تكفي فترة التدريب على مقاطع الفيديو القصيرة لأخذ العينات من مقاطع الفيديو الطويلة والاستدلال في السياقات الطويلة
PackForcing: تكفي فترة التدريب على مقاطع الفيديو القصيرة لأخذ العينات من مقاطع الفيديو الطويلة والاستدلال في السياقات الطويلة
Xiaofeng Mao Shaohao Rui Kaining Ying Bo Zheng Chuanhao Li Mingmin Chi Kaipeng Zhang
الملخص
حققت نماذج الانتشار التوليدية ذاتية الانحدار (Autoregressive video diffusion models) تقدّمًا ملحوظًا، غير أنها لا تزال تعاني من اختناقات ناتجة عن النمو الخطي غير القابل للإدارة في ذاكرة التخزين المؤقت للمفاتيح والقيم (KV-cache)، وتكرار الإطارات زمنيًا، وتراكم الأخطاء أثناء توليد الفيديوهات الطويلة. لمعالجة هذه التحديات، نقدم إطار عمل موحد يُدعى PackForcing، يدير تاريخ التوليد بكفاءة عبر استراتيجية جديدة لتقسيم ذاكرة KV-cache إلى ثلاثة أجزاء. تحديدًا، نصنّف السياق التاريخي إلى ثلاثة أنواع متميزة: (1) رموز المصدر (Sink tokens)، التي تحافظ على الإطارات المرجعية المبكرة بدقة كاملة لضمان استمرارية الدلالات العالمية؛ (2) رموز وسطية (Mid tokens)، تحقق ضغطًا مكانيًا-زمنيًا هائلًا (تخفيض عدد الرموز بمقدار 32 مرة) عبر شبكة ذات فرعين تدمج التلافيف ثلاثية الأبعاد التدريجية مع إعادة ترميز VAE بدقة منخفضة؛ و(3) الرموز الحديثة (Recent tokens)، التي تُحتفظ بها بدقة كاملة لضمان تماسك زمني محلي. ولضبط البصمة الذاكرةية بدقة دون التضحية بالجودة، نقترح آلية انتقاء ديناميكية من نوع top-k للرموز الوسطية، مقترنة بضبط مستمر لـ Temporal RoPE يعيد مواءمة الفجوات الموضعية الناتجة عن إسقاط الرموز بكفاءة عالية وتكلفة زمنية ضئيلة. مدعومًا بهذا الضغط الهرمي المنهجي للسياق، يستطيع PackForcing توليد فيديوهات متماسكة مدتها دقيقتان، بدقة 832×480 وبمعدل 16 إطارًا في الثانية، على بطاقة H200 واحدة. يحقق النموذج ذاكرة KV-cache محدودة بحجم 4 جيجابايت فقط، ويوفر قدرة استقراء زمني مذهلة تصل إلى 24 مرة (من 5 ثوانٍ إلى 120 ثانية)، مع عمل فعّال إما بدون ضبط مسبق (zero-shot) أو بعد التدريب على مقاطع مدتها 5 ثوانٍ فقط. تُظهر النتائج الشاملة على منصة VBench أداءً رائدًا من حيث الاتساق الزمني (26.07) ودرجة الديناميكية (56.25)، مما يثبت أن الإشراف على الفيديوهات القصيرة كافٍ لتوليد فيديوهات طويلة عالية الجودة. رابطة المشروع: https://github.com/ShandaAI/PackForcing
One-sentence Summary
Researchers from Alaya Studio, Fudan University, and Shanghai Innovation Institute present PackForcing, a framework that enables long-video generation by compressing historical KV caches into three partitions. This approach achieves 24x temporal extrapolation from short clips while maintaining state-of-the-art coherence on a single GPU.
Key Contributions
- The paper introduces PackForcing, a unified framework that partitions generation history into sink, compressed, and recent tokens to bound per-layer attention to approximately 27,872 tokens regardless of video length.
- A hybrid compression layer fusing progressive 3D convolutions with low-resolution VAE re-encoding achieves a 128× spatiotemporal compression for intermediate history, increasing effective memory capacity by over 27×.
- The method employs a dynamic top-k context selection mechanism coupled with an incremental Temporal RoPE adjustment to seamlessly correct position gaps caused by dropped tokens without requiring full cache recomputation.
Introduction
Autoregressive video diffusion models enable long-form generation but face critical bottlenecks where linear Key-Value cache growth causes out-of-memory errors and iterative prediction leads to severe semantic drift. Prior solutions either truncate history to save memory, which destroys long-range coherence, or retain full context, which exceeds the capacity of single GPUs for minute-scale videos. The authors introduce PackForcing, a unified framework that partitions generation history into sink, compressed, and recent tokens to bound memory usage while preserving global semantics. By employing a dual-branch network for massive spatiotemporal compression and a dynamic top-k selection mechanism with incremental RoPE adjustment, the method achieves stable 2-minute video synthesis on a single H200 GPU using only 5-second training clips.
Method
The authors propose PackForcing, a framework designed to resolve the memory bottleneck in autoregressive video generation by decoupling the generation history into three distinct functional partitions. Refer to the framework diagram for the overall architecture. The system organizes the denoising context into Sink Tokens, Mid Tokens, and Recent and Current Tokens. Sink Tokens correspond to the initial frames and are kept at full resolution to serve as semantic anchors. Recent and Current Tokens maintain high-fidelity local dynamics at full resolution. The vast majority of the history falls into the Mid Tokens partition, which undergoes aggressive compression to reduce the token count by approximately 32 times.
To achieve this compression, the authors employ a dual-branch compression module. As shown in the figure below, this module processes the Mid Tokens through two parallel pathways. The High-Resolution (HR) branch utilizes a 4-stage 3D CNN to preserve fine-grained structural details. The Low-Resolution (LR) branch decodes the latent frames to pixel space, applies pooling, and re-encodes them via a VAE to capture coarse semantics. These features are fused via element-wise addition to produce the final compressed tokens.
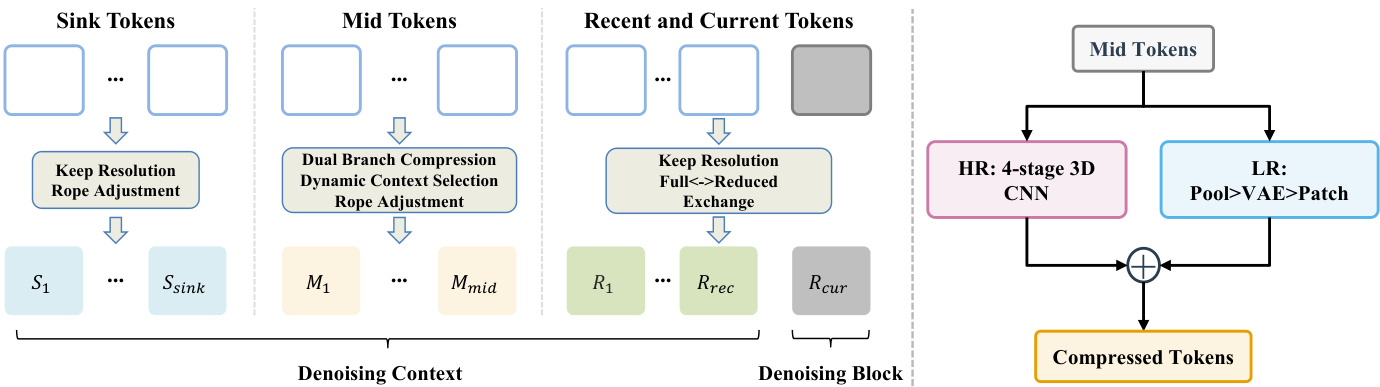
The specific architecture of the HR branch is detailed in the subsequent figure. It consists of a cascade of strided 3D convolutions with SiLU activations. The process begins with a temporal compression followed by three stages of spatial compression, culminating in a projection to the model's hidden dimension. This design ensures a significant volume reduction while retaining essential layout information.

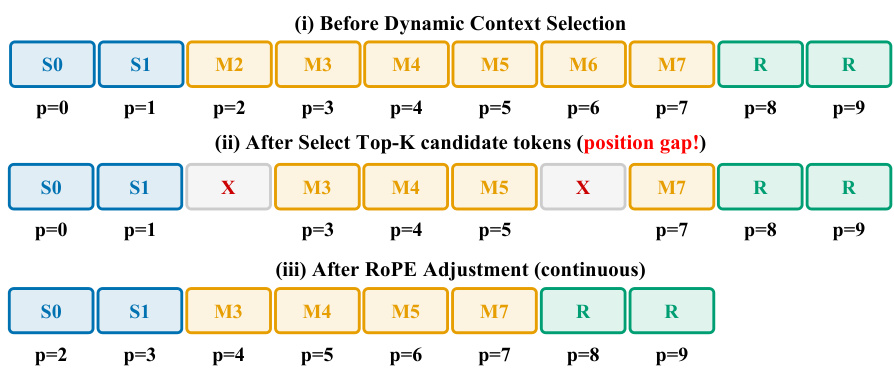
To further optimize memory usage, the system implements Dynamic Context Selection. Instead of attending to all compressed mid tokens, the model evaluates query-key affinities to route only the top-K most informative blocks. This selection process inevitably creates position gaps in the token sequence. To resolve this, the authors apply an incremental RoPE adjustment. Refer to the diagram illustrating the selection process to see how the position indices are re-aligned. Initially, the selection creates gaps where tokens are removed. The RoPE adjustment then shifts the positional embeddings of the remaining tokens to ensure continuous indices, allowing the transformer to maintain temporal coherence without full recomputation.
Finally, the training strategy involves end-to-end optimization of the HR compression layer. During the rollout phase, the compression module is integrated directly into the computational graph. This ensures that the compressed mid tokens are explicitly tailored to preserve semantic and structural cues necessary for downstream causal attention, rather than minimizing a generic reconstruction loss. This approach allows the model to generalize from short training sequences to long video generation with constant attention complexity.
Experiment
- Main experiments on 60s and 120s video generation validate that PackForcing achieves superior motion synthesis and temporal stability compared to baselines, maintaining high subject and background consistency without the severe degradation seen in other methods.
- Long-range consistency tests confirm that the sink token mechanism effectively anchors global semantics, preventing the compounding errors and semantic drift that typically occur in extended autoregressive generation.
- Ablation studies demonstrate that sink tokens are critical for balancing dynamic motion with semantic coherence, while dynamic context selection outperforms standard FIFO eviction by retaining highly attended historical blocks.
- Analysis of attention patterns reveals that information demand is distributed across the entire video history rather than being limited to recent frames, justifying the need for a compressed mid-buffer and global summary tokens.
- Qualitative evaluations show that the proposed architecture preserves fine visual details and complex continuous motion over two minutes, whereas competing methods suffer from color shifts, object duplication, or motion freezing.
- Efficiency analysis proves that the compression strategy bounds memory usage to a constant level regardless of video length, enabling long-horizon generation on single GPUs where uncompressed methods would fail.