Command Palette
Search for a command to run...
خارج نطاق الرؤية ولكن ليس خارج نطاق العقل: ذاكرة هجينة لنماذج عالم الفيديو الديناميكية
خارج نطاق الرؤية ولكن ليس خارج نطاق العقل: ذاكرة هجينة لنماذج عالم الفيديو الديناميكية
Kaijin Chen Dingkang Liang Xin Zhou Yikang Ding Xiaoqiang Liu Pengfei Wan Xiang Bai
الملخص
لقد أظهرت نماذج العالم المرئي (Video world models) إمكانات هائلة في محاكاة العالم الفيزيائي، إلا أن آليات الذاكرة الحالية تعامل البيئات في الغالب كأقمشة ثابتة. وعندما تختفي الكيانات الديناميكية خارج نطاق الرؤية ثم تظهر مجددًا، غالبًا ما تواجه الأساليب الحالية صعوبة، مما يؤدي إلى تجمد الكيانات أو تشوهها أو اختفائها. ولمعالجة هذه المشكلة، نقدم "الذاكرة الهجينة" (Hybrid Memory)، وهي نموذج جديد يتطلب من النماذج أن تعمل في آن واحد كحافظين دقيقين للخلفيات الثابتة، وتتبعين يقظين للكيانات الديناميكية، لضمان استمرارية الحركة خلال الفترات التي تكون فيها الكيانات خارج نطاق الرؤية.لتسهيل البحث في هذا الاتجاه، قمنا ببناء مجموعة بيانات "إتش إم-وورلد" (HM-World)، وهي أول مجموعة بيانات فيديو واسعة النطاق مخصصة للذاكرة الهجينة. تتسم هذه المجموعة بـ 59 ألف مقطع عالي الدقة مع مسارات منفصلة للكاميرا وللكيانات، وتضم 17 مشهدًا متنوعًا و49 كيانًا مميزًا، بالإضافة إلى أحداث خروج ودخول مصممة بدقة لتقييم التماسك الهجين بدقة. وعلاوة على ذلك، نقترح معمارية "هايدرا" (HyDRA) المتخصصة في الذاكرة، والتي تقوم بضغط الذاكرة إلى وحدات Token، وتستخدم آلية استرجاع مدفوعة بالارتباط الزماني-المكاني. ومن خلال الانتقاء الانتباهي للإشارات الحركية ذات الصلة، تحافظ "هايدرا" بفعالية على هوية الكيانات المخفية وحركتها. وتُظهر التجارب الواسعة على مجموعة بيانات HM-World أن طريقتنا تتفوق بشكل كبير على أحدث الأساليب المتاحة (state-of-the-art) من حيث اتساق الكيانات الديناميكية وجودة التوليد الشاملة.
One-sentence Summary
Researchers from Huazhong University of Science and Technology and Kling Team propose Hybrid Memory, a paradigm for video world models that maintains static backgrounds while tracking dynamic subjects. Their HyDRA architecture uses spatiotemporal retrieval to preserve motion consistency during out-of-view intervals, validated on the new HM-World dataset.
Key Contributions
- The paper introduces Hybrid Memory, a novel paradigm that requires models to simultaneously maintain spatial consistency for static backgrounds and motion continuity for dynamic subjects during out-of-view intervals.
- This work presents HM-World, the first large-scale video dataset dedicated to hybrid memory research, featuring 59K high-fidelity clips with decoupled camera and subject trajectories to rigorously evaluate spatiotemporal coherence.
- A specialized memory architecture named HyDRA is proposed, which compresses memory into tokens and employs a spatiotemporal relevance-driven retrieval mechanism to effectively rediscover hidden subjects and preserve their identity and motion.
Introduction
Video world models are critical for applications like autonomous driving and embodied intelligence, yet current memory mechanisms treat environments as static canvases that fail when dynamic subjects move out of view. Existing approaches often cause hidden characters to vanish, freeze, or distort upon re-emergence because they lack the ability to track independent motion logic during occlusion. The authors introduce Hybrid Memory, a new paradigm that requires models to simultaneously archive static backgrounds and predict the unseen trajectories of dynamic subjects. To support this, they release HM-World, the first large-scale dataset featuring decoupled camera and subject movements, and propose HyDRA, a specialized architecture that uses spatiotemporal relevance-driven retrieval to preserve identity and motion continuity for hidden entities.
Dataset
-
Dataset Composition and Sources: The authors introduce HM-World, a large-scale synthetic dataset built to address the scarcity of natural videos featuring exit-entry events. It is generated entirely within Unreal Engine 5 by procedurally combining four core dimensions: 17 diverse 3D scenes, 49 distinct subjects (humans and animals), 10 predefined subject trajectories, and 28 designed camera trajectories.
-
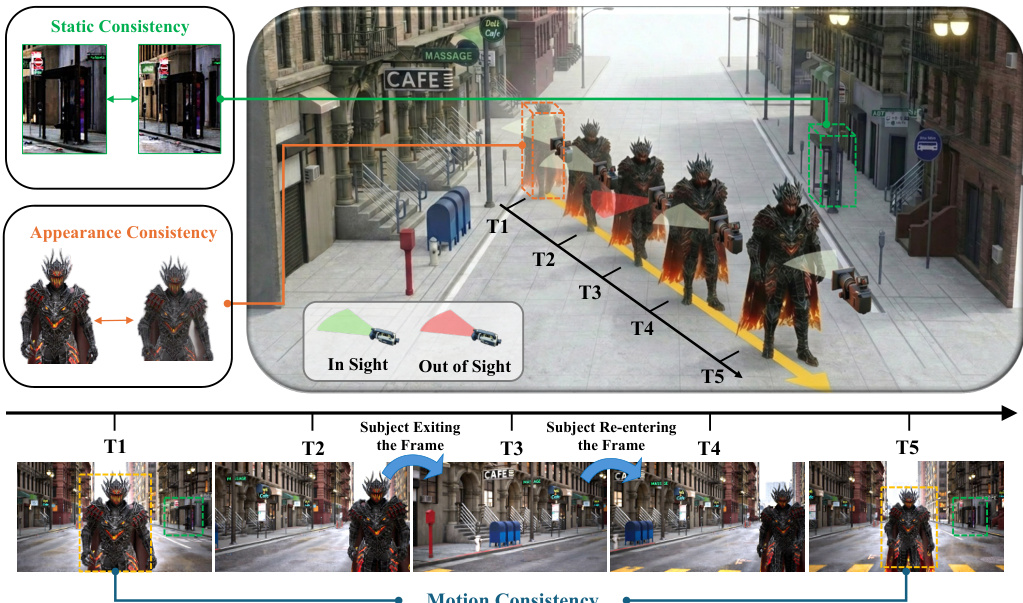
Key Details for Each Subset: The final collection consists of 59,225 high-fidelity video clips. Each clip features 1 to 3 subjects moving along random paths while the camera executes deliberate back-and-forth motions to force subjects to leave and re-enter the frame. The dataset is unique in its inclusion of specific in-and-out-of-frame dynamics, unlike existing datasets that either lack dynamic subjects, keep subjects always visible, or use static cameras.
-
Usage in the Model: This dataset serves as a dedicated testing ground and training resource for Hybrid Memory in Video World Models. It enables the model to learn spatiotemporal decoupling by simultaneously anchoring static backgrounds and tracking dynamic subjects that disappear and reappear, a capability essential for maintaining visual identity and consistent motion states during out-of-view extrapolation.
-
Processing and Metadata Construction: The rendering pipeline filters out any clips that fail to produce exit-entry events. Every retained sample is comprehensively annotated with the rendered video, a descriptive caption generated by MiniCPM-V, precise camera poses, per-frame 3D positions for all subjects, and exact timestamps marking when each subject exits and enters the frame.
Method
The authors address the challenge of generating consistent video sequences where dynamic subjects frequently exit and re-enter the camera's field of view. As illustrated in the conceptual diagram, maintaining static, appearance, and motion consistency across time steps (T1 to T5) is critical when subjects are occluded or out of sight. To achieve high-fidelity future frame prediction, the model must preserve the static background while actively seeking moving subjects to maintain their appearance and motion consistency.
The overall framework is built upon a full-sequence video diffusion model. Refer to the framework diagram for the complete pipeline structure. The architecture comprises a causal 3D VAE for spatiotemporal compression and a Diffusion Transformer (DiT) for generation. The model follows Flow Matching, where the diffusion timestep is encoded via an MLP to modulate the DiT blocks. During training, the model learns to predict the ground-truth velocity vt=z0−z1 at timestep t∈[0,1], minimizing the loss function:
Lθ=Ez0,z1,t∣∣u(zt,t;θ)−vt∣∣2To enable precise spatial control, camera trajectories are injected as an explicit condition. The camera pose sequence is flattened and encoded via a camera encoder, then added element-wise to the latent features fed into the DiT blocks.
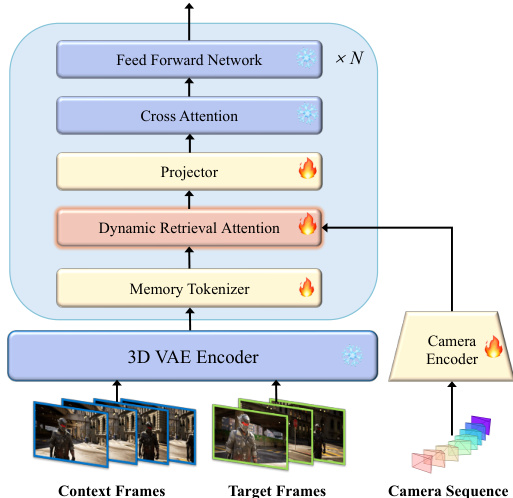
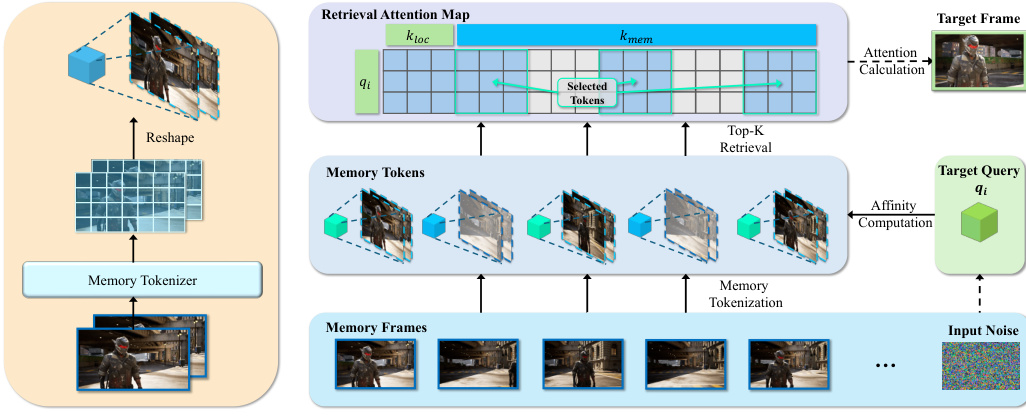
To handle dynamic subjects efficiently without flooding the model with irrelevant noise, the authors introduce HyDRA (Hybrid Dynamic Retrieval Attention). This module replaces standard self-attention layers and consists of two key components: Memory Tokenization and Dynamic Retrieval Attention.
First, a Memory Tokenizer processes the encoded memory latents Zmem. Instead of using raw latents, a 3D-convolution-based tokenizer expands the spatiotemporal receptive field to capture long-duration motion information, producing compact memory tokens M. This transformation is defined as M=Tmem(Zmem).
Second, the Dynamic Retrieval Attention mechanism computes a spatiotemporal affinity metric between the target query and the memory tokens. As shown in the detailed module breakdown, the system performs a Top-K selection to retrieve the most relevant memory tokens based on affinity scores Si,j. To preserve local denoising stability, the retrieved memory features are concatenated with keys and values from a local temporal window. The final attention is computed using the standard formulation:
Attention(qi,Ki′,Vi′)=Softmax(dqi(Ki′)T)Vi′By iterating this process, the model selectively attends to pertinent motion and appearance cues of out-of-sight subjects, ensuring spatiotemporal consistency while reducing computational burden.
Experiment
- Main experiments compare the proposed HyDRA method against baselines and state-of-the-art models, validating its superior ability to maintain subject identity and motion coherence during complex exit-and-re-entry events.
- Qualitative results demonstrate that while competing methods suffer from subject distortion, vanishing, or stuttering, HyDRA successfully preserves hybrid consistency by effectively anchoring static backgrounds and tracking dynamic subjects.
- Ablation studies confirm that temporal interaction within the memory tokenizer is critical for capturing long-term dynamics, as removing it causes significant consistency failures.
- Experiments on token retrieval show that dynamic affinity-based selection outperforms static Field of View filtering by adaptively retrieving keyframes with rich subject details rather than relying on fixed geometric overlap.
- Analysis of retrieved token counts indicates that a moderate number of tokens is sufficient to provide necessary spatiotemporal context, whereas overly restricted counts lead to information loss and generation artifacts.
- Open-domain evaluations verify that the model generalizes well to unseen scenes and camera movements, maintaining robust memory capabilities without specific fine-tuning.