Command Palette
Search for a command to run...
كاليبري: تعزيز محولات الانتشار عبر المعايرة الفعالة من حيث المعاملات
كاليبري: تعزيز محولات الانتشار عبر المعايرة الفعالة من حيث المعاملات
Danil Tokhchukov Aysel Mirzoeva Andrey Kuznetsov Konstantin Sobolev
الملخص
في هذه الورقة، نكشف عن الإمكانات الكامنة في محولات الانتشار (Diffusion Transformers أو DiTs) لتعزيز المهام التوليدية بشكل ملحوظ. من خلال تحليل معمق لعملية إزالة الضوضاء، نثبت أن إدخال معلمة قياس واحدة مُتعلمة يمكن أن يحسّن أداء كتل DiT بشكل كبير. وبناءً على هذه الرؤى، نقترح منهجية Calibri، وهي نهج كفؤ في استخدام المعلمات يقوم بمعايرة مكونات DiT بشكل أمثل لرفع جودة التوليد. تعامل منهجية Calibri معايرة DiT على أنها مشكلة تحسين مكافأة من الصندوق الأسود (black-box reward optimization)، ويتم حلها بكفاءة باستخدام خوارزمية تطورية مع تعديل ما يقرب من 100 معلمة فقط. وتُظهر النتائج التجريبية أنه رغم تصميمها الخفيف الوزن، فإن Calibri تحسّن الأداء بشكل متسق عبر نماذج مختلفة من النص إلى الصورة. ومن الجدير بالذكر أن Calibri تُقلل أيضًا من خطوات الاستدلال (inference steps) المطلوبة لتوليد الصور، مع الحفاظ في الوقت نفسه على مخرجات عالية الجودة.
One-sentence Summary
Authors from MSU and FusionBrain Lab introduce Calibri, a parameter-efficient method that aligns Diffusion Transformers by optimizing only approximately one hundred parameters. Unlike prior approaches requiring extensive fine-tuning, Calibri significantly enhances generation quality for detailed image synthesis while maintaining computational efficiency.
Key Contributions
- The paper introduces Calibri, a parameter-efficient method that frames Diffusion Transformer calibration as a black-box reward optimization problem solved via an evolutionary algorithm to adjust only approximately 100 scaling parameters.
- This work demonstrates that applying learned scalar weights to individual DiT block outputs significantly enhances generative quality and reduces the number of inference steps required for image synthesis.
- Experimental results validate that the Calibri Ensemble approach, which integrates multiple calibrated models, consistently improves performance across various text-to-image baselines without introducing computational overhead.
Introduction
Modern visual generation has shifted toward Diffusion Transformers (DiT) combined with flow matching, establishing a new standard for tasks ranging from text-to-image synthesis to video generation. However, recent analysis reveals that these models suffer from sub-optimal weighting across their uniform blocks, where some layers introduce artifacts while others contribute unevenly to the final output. The authors leverage this insight to propose Calibri, a parameter-efficient method that frames block calibration as a black-box reward optimization problem solved via an evolutionary algorithm. By tuning only approximately 100 scaling parameters, Calibri significantly enhances generation quality and reduces the number of inference steps required without the computational overhead of full fine-tuning.
Method
The Diffusion Transformer (DiT) architecture comprises sequential DiT blocks that transform input tokens into output tokens. The standard DiT block consists of Multi-Head Self-Attention (MHSA) layers and feed-forward layers. Both layers apply LayerNorm to the incoming data and are modulated by a time embedding. This modulation is achieved using vectors α,β,γ, which are generated by a distinct Multi-Layer Perceptron (MLP). For multimodal processing, the authors utilize the Multimodal Diffusion Transformer (MM-DiT). This block builds upon the standard structure by combining textual and visual tokens via concatenation and processing them in parallel. Inter-modal communication is restricted to the MultiModal Attention Layer, enabling effective interaction between the two modalities. Separate modulation vectors are employed for each modality, denoted as αv,βv,γv for visual tokens and αt,βt,γt for textual tokens. As shown in the figure below, the block schemes illustrate the structural differences between the standard DiT and the MM-DiT architectures.
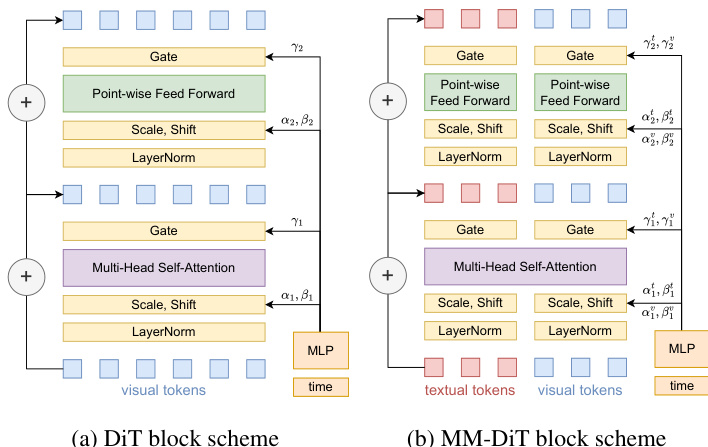
The output of the standard DiT layers can be described by the following formula:
xl=xl−1+γ1MHSA(α1LN(xl−1)+β1),xl+1=xl+γ2FF(α2LN(xl)+β2),where xl−1 denotes the input token sequence, and xl and xl+1 represent the intermediate and final outputs. The forward pass for the MM-DiT block is expressed as:
xlv=xl−1v+γ1vMHSA(α1vLN(xl−1)+β1v),xlt=xl−1t+γ1tMHSA(α1tLN(xl−1)+β1t),xl+1v=xlv+γ2vFF(α2LN(xlv)+β2v),xl+1t=xlt+γ2tFF(α2LN(xlv)+β2t),where xlv and xlt correspond to the transformed tokens for the visual and textual modalities, respectively.
To enhance the generative capabilities of these transformers, the authors introduce Calibri, a method aimed at calibrating a minimal subset of the model's parameters. The calibration process is formulated as an optimization problem where the goal is to find the optimal parameter configuration c∗ that maximizes the reward function:
c∗=argcmaxR(c),where R(∗) is a scalar-valued function measuring the performance of the diffusion transformer on the given task. The search space for calibrating the model is determined by specific locations within the diffusion transformer where adjustments are applied. The authors introduce three levels of granularity for internal-layer calibration parameters: Block Scaling, which uniformly adjusts outputs of Attention and MLP layers; Layer Scaling, which adjusts individual layers within a block; and Gate Scaling, which is particularly important for architectures with multimodal interactions like MM-DiT.
To identify optimal calibration coefficients, the method employs the Covariance Matrix Adaptation Evolution Strategy (CMA-ES), a powerful gradient-free optimization approach. CMA-ES optimizes an objective function by iteratively refining a sampling distribution based on a multivariate Gaussian, N(μ,σ2C). The method scheme is depicted in the figure below.
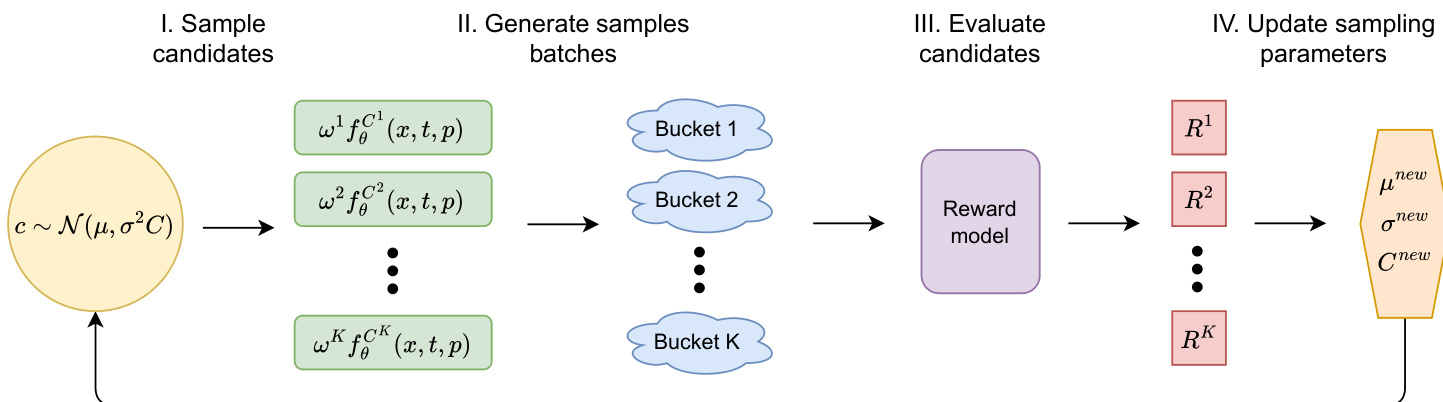
At each iteration, candidate solutions are drawn from this Gaussian distribution and evaluated using the objective function. The process involves sampling candidates, generating sample batches, evaluating candidates via a reward model, and finally updating the sampling parameters. CMA-ES updates the mean vector by moving toward higher-performing candidates while adapting the covariance matrix to reflect successful directions in the search space. This iterative refinement allows efficient exploration and exploitation, optimizing calibration coefficients for improved model performance over successive iterations.
Experiment
- Motivation experiments reveal that DiT block contributions are uneven, and removing specific layers can unexpectedly improve image quality, leading to the discovery that applying optimal scaling factors to individual blocks enhances overall model performance.
- Design decision studies demonstrate that layer scaling offers the most consistent improvements across multiple reward functions compared to block or gate scaling, while Calibri Ensemble effectively aggregates calibrated models to boost rewards and reduce the optimal number of inference steps from 30–50 to 10–15.
- Evaluations across diverse backbones confirm that Calibri consistently improves generation quality and text alignment while significantly reducing inference steps, with human evaluations validating these gains as genuine perceptual improvements rather than reward artifacts.
- Integration tests show that Calibri can be combined with existing alignment methods like Flow-GRPO to further boost performance on various targets, achieving comparable results to large-scale fine-tuning while updating a negligible number of parameters.
- Diversity analysis indicates that Calibri preserves generation diversity comparable to baseline models despite using fewer inference steps, whereas other optimization methods often degrade diversity without offering speed advantages.
- Comparative studies establish that CMA-ES is substantially more efficient than gradient-based approaches like Flow-GRPO for optimizing calibration coefficients, with training dynamics showing clear convergence that allows for early termination to save computational resources.