Command Palette
Search for a command to run...
السرعة عبر البساطة: بنية أحادية التدفق لنموذج أساسي توليدي سريع للصوت والفيديو
السرعة عبر البساطة: بنية أحادية التدفق لنموذج أساسي توليدي سريع للصوت والفيديو
الملخص
نقدم نموذج daVinci-MagiHuman، وهو نموذج تأسيسي مفتوح المصدر لتوليد الفيديو والصوت الموجه نحو المحتوى البشري. يولد daVinci-MagiHuman الفيديو والصوت المتزامنين بشكل مشترك باستخدام محول (Transformer) أحادي التيار يعالج النص والفيديو والصوت ضمن تسلسل رموز (token sequence) موحد، مع الاعتماد حصريًا على الانتباه الذاتي (self-attention). يتجنب هذا التصميم أحادي التيار تعقيد معماريات متعددات التيارات أو آليات الانتباه المتقاطع (cross-attention)، مع بقائه سهل التحسين باستخدام بنية تحتية قياسية للتدريب والاستدلال (inference). يتفوق النموذج بشكل خاص في السيناريوهات الموجهة نحو البشر، حيث ينتج تعبيرات وجهية معبّرة، وتنسيقًا طبيعيًا بين الكلام والتعبير، وحركة جسم واقعية، ومزامنة دقيقة بين الصوت والفيديو. ويدعم النموذج التوليد الشفهي متعدد اللغات عبر الصينية (الماندارين والكانتونية)، والإنجليزية، واليابانية، والكورية، والألمانية، والفرنسية. ولتحقيق استدلال كفء، نقترن العمود الفقري أحادي التيار بتقنية تقطير النموذج (model distillation)، فائقة الدقة في فضاء الكمون (latent-space super-resolution)، ومفكك (decoder) VAE من نوع Turbo، مما يتيح توليد فيديو بدقة 256p لمدة 5 ثوانٍ خلال ثانيتين فقط على بطاقة H100 GPU واحدة. وفي التقييم الآلي، يحقق daVinci-MagiHuman أعلى جودة بصرية وأعلى توافق مع النص بين النماذج المفتوحة الرائدة، مع أقل معدل خطأ في الكلمات (14.60%) فيما يتعلق بوضوح الكلام. أما في التقييم البشري الزوجي، فقد حقق معدلات فوز بلغت 80.0% مقابل Ovi 1.1 و60.9% مقابل LTX 2.3 عبر أكثر من 2000 مقارنة. وقد قمنا بنشر كامل مكدس النموذج (model stack) مفتوح المصدر، بما في ذلك النموذج الأساسي، والنموذج المقطر، ونموذج فائقة الدقة، بالإضافة إلى قاعدة كود الاستدلال.
One-sentence Summary
SII-GAIR and Sand.ai introduce daVinci-MagiHuman, an open-source audio-video foundation model that uses a single-stream Transformer to generate synchronized human-centric content without complex cross-attention. This approach enables efficient multilingual speech and motion synthesis, achieving superior visual quality and speech intelligibility compared to leading open models.
Key Contributions
- The paper introduces daVinci-MagiHuman, an open-source audio-video generative foundation model that utilizes a single-stream Transformer to process text, video, and audio within a unified token sequence via self-attention only, avoiding the complexity of multi-stream or cross-attention architectures.
- This work demonstrates strong human-centric generation capabilities, including expressive facial performance and precise audio-video synchronization, while supporting multilingual spoken generation across six major languages and achieving a 14.60% word error rate in automatic evaluations.
- The authors present an efficient inference pipeline combining model distillation, latent-space super-resolution, and a Turbo VAE decoder to generate a 5-second 256p video in 2 seconds on a single H100 GPU, alongside a fully open-source release of the complete model stack and codebase.
Introduction
Video generation is rapidly evolving toward synchronized audio-video synthesis, yet open-source solutions struggle to balance high-quality output, multilingual support, and inference efficiency within a scalable architecture. Existing open models often rely on complex multi-stream designs that are difficult to optimize jointly with training and inference infrastructure. The authors introduce daVinci-MagiHuman, an open-source model that leverages a single-stream Transformer to unify text, video, and audio processing within a shared-weight backbone. This simplified approach enables fast inference through latent-space super-resolution while delivering strong human-centric generation quality and broad multilingual capabilities across languages like English, Chinese, and Japanese.
Method
The authors propose daVinci-MagiHuman, which centers on a single-stream Transformer architecture designed to jointly generate synchronized video and audio. Unlike dual-stream approaches that process modalities separately, this model represents text, video, and audio tokens within a unified sequence processed via self-attention only. This design avoids the complexity of cross-attention modules while remaining easy to optimize with standard infrastructure.
As shown in the figure below:
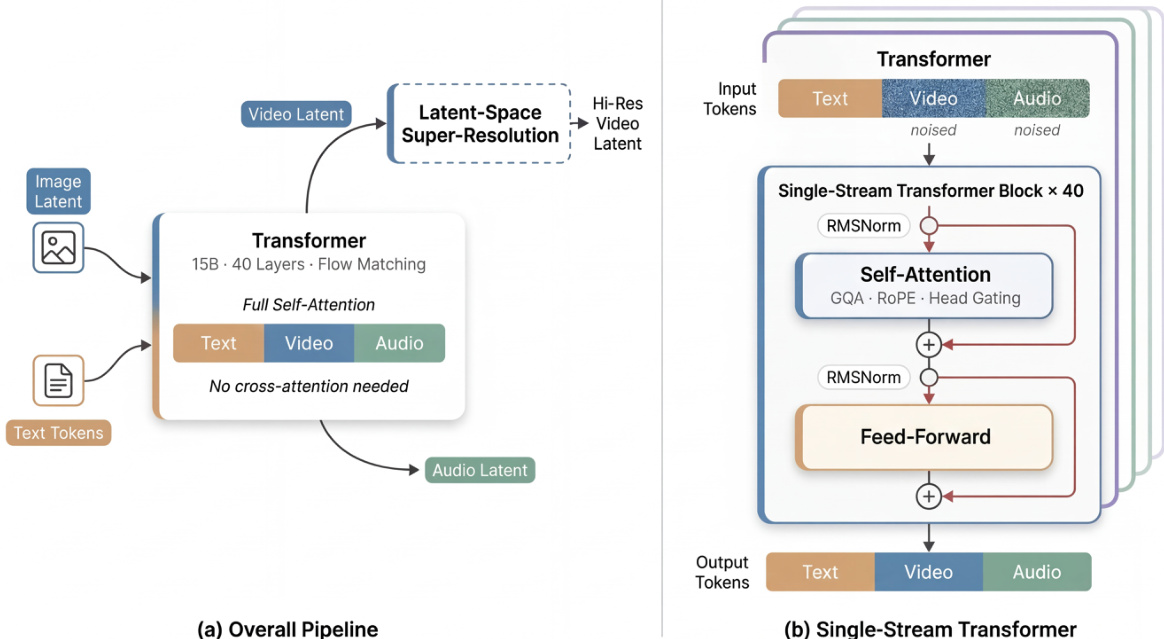
The base generator accepts text tokens, a reference image latent, and noisy video and audio tokens. It jointly denoises the video and audio tokens using a 15B-parameter, 40-layer Transformer. A latent-space super-resolution stage can subsequently refine the generated video at higher resolutions. The internal architecture adopts a sandwich structure where the first and last 4 layers utilize modality-specific projections and normalization parameters, while the middle 32 layers share parameters across all modalities. This design preserves modality sensitivity at the boundaries while enabling deep multimodal fusion in the shared representation space.
Several key mechanisms enhance the model's performance and stability. The system employs timestep-free denoising, inferring the denoising state directly from the noisy inputs rather than using explicit timestep embeddings. Additionally, the model incorporates per-head gating within the attention blocks. For each attention head h, a learned scalar gate modulates the output oh via a sigmoid function σ, resulting in a gated output:
o~h=σ(qh)ohThis improves numerical stability and representability with minimal overhead.
To ensure efficient inference, the authors integrate several complementary techniques. Latent-space super-resolution allows the base model to generate at a lower resolution before refining in latent space, avoiding expensive pixel-space operations. A Turbo VAE decoder replaces the standard decoder to reduce overhead on the critical path. Furthermore, full-graph compilation via MagiCompiler fuses operators across layer boundaries, and model distillation using DMD-2 reduces the required denoising steps to 8 without classifier-free guidance.
Experiment
- Quantitative benchmarks on VerseBench and TalkVid-Bench validate that daVinci-MagiHuman achieves superior visual quality, text alignment, and speech intelligibility compared to Ovi 1.1 and LTX 2.3, while maintaining competitive physical consistency.
- Pairwise human evaluations confirm a strong preference for daVinci-MagiHuman over both baselines, with raters favoring its overall audio-video quality, synchronization, and naturalness in the majority of comparisons.
- Inference efficiency tests demonstrate that the pipeline generates high-resolution 1080p videos in under 40 seconds on a single H100 GPU, utilizing a distilled base stage and Turbo VAE decoder to balance speed and output quality.