Command Palette
Search for a command to run...
مُركِّب Y لـ LLMs: حلّ تعفُّن السياق الطويل باستخدام λ-Calculus
مُركِّب Y لـ LLMs: حلّ تعفُّن السياق الطويل باستخدام λ-Calculus
Amartya Roy Rasul Tutunov Xiaotong Ji Matthieu Zimmer Haitham Bou-Ammar
الملخص
تُستخدم نماذج اللغة الكبيرة (LLMs) بشكل متزايد كمُستنتجات عامة الأغراض، غير أن المدخلات الطويلة لا تزال تعاني من اختناق بسبب نافذة السياق الثابتة. تعالج النماذج اللغوية العودية (RLMs) هذه المشكلة من خلال تفويض الـ prompt وحل المشكلات الفرعية بشكل عودي. ومع ذلك، فإن نماذج RLM الحالية تعتمد على حلقة قراءة-تقييم-طباعة مفتوحة النهاية (REPL)، حيث يولد النموذج أكواد تحكم تعسفية، مما يجعل تنفيذها صعب التحقق منه والتنبؤ به وتحليله. في هذا البحث، نقدم إطار عمل λ-RLM، المخصص للاستدلال في سياق طويل، والذي يستبدل توليد الكود العودي الحر بنظام تشغيل دالي منضبط النوع (typed functional runtime) مستند إلى حساب لامدا (λ-calculus). يعمل هذا الإطار على تنفيذ مكتبة مدمجة من المكوّنات (combinators) المُتحقَّق منها مسبقاً، ويستخدم الاستدلال العصبي فقط على المشكلات الفرعية الطرفية المحدودة، محوّلًا الاستدلال العودي إلى برنامج دالي هيكلي ذي تدفق تحكم صريح. نُظهر أن إطار عمل λ-RLM يتيح ضمانات رسمية غير متوفرة في نماذج RLM القياسية، تشمل: ضمان الإنهاء (termination)، وحدود تكلفة بصيغة مغلقة (closed-form cost bounds)، وتدرج مُتحكَّم به في الدقة مع عمق العودية، وقاعدة تقسيم مثلى ضمن نموذج تكلفة بسيط. من الناحية التجريبية، وفي إطار أربع مهام استدلال بسياق طويل وتسعة نماذج أساسية، تفوق إطار عمل λ-RLM على نماذج RLM القياسية في 29 من أصل 36 مقارنة بين النماذج والمهام، كما حسّن متوسط الدقة بنسبة تصل إلى +21.9 نقطة عبر مستويات النماذج المختلفة، وقلّل زمن الاستجابة (latency) بنسبة تصل إلى 4.1 ضعفًا. تُظهر هذه النتائج أن التحكم الرمزي المنضبط النوع يُوفّر أساسًا أكثر موثوقية وكفاءة للاستدلال في سياق طويل مقارنة بتوليد الكود العودي المفتوح النهاية. ويُتاح التنفيذ الكامل لإطار عمل λ-RLM للمجتمع العلمي كمصدر مفتوح عبر الرابط التالي: https://github.com/lambda-calculus-LLM/lambda-RLM.
One-sentence Summary
Researchers from IIT Delhi, Huawei Noah's Ark Lab, and UCL introduce λ-RLM, a framework that replaces open-ended recursive code with a typed functional runtime grounded in λ-calculus. This approach provides formal guarantees like termination and significantly improves accuracy and latency for long-context reasoning compared to standard Recursive Language Models.
Key Contributions
- The paper introduces λ-RLM, a framework that replaces free-form recursive code generation with a typed functional runtime grounded in λ-calculus to execute a library of pre-verified combinators. This approach turns recursive reasoning into a structured functional program with explicit control flow, using neural inference only on bounded leaf subproblems.
- Formal guarantees absent from standard Recursive Language Models are established, including termination, closed-form cost bounds, controlled accuracy scaling with recursion depth, and an optimal partition rule under a simple cost model. These properties are achieved by encoding recursion as a fixed-point over a deterministic operator library and enforcing predictable execution through a symbolic planner.
- Empirical evaluation across four long-context reasoning tasks and nine base models demonstrates that the method outperforms standard RLMs in 29 of 36 comparisons while improving average accuracy by up to 21.9 points. The results also show a latency reduction of up to 4.1 times, validating that typed symbolic control provides a more reliable and efficient foundation for long-context reasoning.
Introduction
Large language models face a critical bottleneck when processing inputs that exceed their fixed context windows, often forcing reliance on truncation or sliding windows that discard essential information. While Recursive Language Models (RLMs) attempt to solve this by treating the prompt as an external environment for recursive decomposition, they suffer from significant reliability issues because they require the model to generate arbitrary control code in an open-ended loop. This approach leads to unpredictable execution, potential non-termination, and difficult-to-audit failure modes that are orthogonal to the actual reasoning task.
The authors introduce λ-RLM, a framework that replaces free-form code generation with a typed functional runtime grounded in λ-calculus to enforce structured control flow. By executing a compact library of pre-verified combinators and restricting neural inference to bounded leaf subproblems, the system separates semantic reasoning from structural orchestration. This design provides formal guarantees on termination and cost while empirically outperforming standard RLMs in accuracy and reducing latency by up to 4.1 times across various long-context tasks.
Method
The λ-RLM framework fundamentally restructures long-context reasoning by separating control flow from semantic inference. Instead of relying on an LLM to generate arbitrary code for task decomposition, the system employs a typed functional runtime where recursion is expressed through a fixed library of pre-verified combinators. This design ensures that the execution trace is deterministic, auditable, and guaranteed to terminate, while the base language model is reserved exclusively for solving bounded leaf subproblems. The overall architecture is organized into three distinct layers, as illustrated in the framework diagram below.
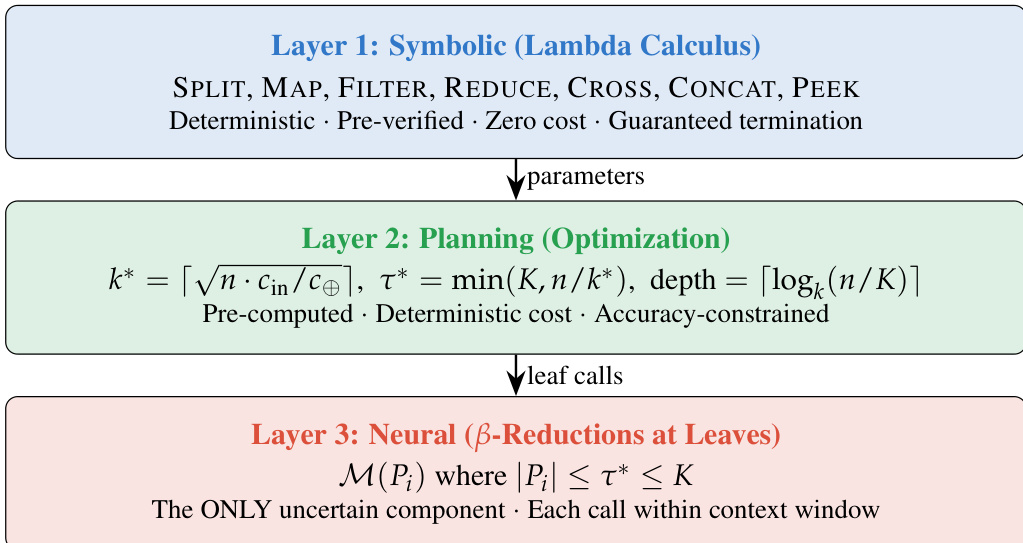
The first layer operates on the principles of Symbolic Lambda Calculus. This layer defines a compact combinator library L consisting of deterministic operators such as SPLIT, MAP, FILTER, REDUCE, CROSS, CONCAT, and PEEK. These operators handle the structural manipulation of the prompt and the orchestration of recursive calls without invoking the neural model. By restricting the control interface to this small set of trusted combinators, the system eliminates the open-ended failure modes associated with free-form code generation. The execution logic is formalized as a fixed-point lambda term, where the recursive solver f is defined in terms of itself, allowing for structured decomposition without external naming mechanisms.
The second layer is responsible for Planning and Optimization. Before execution begins, a deterministic planner computes the optimal parameters for the recursive strategy based on the input size n, the model's context window K, and the cost function. Specifically, the planner determines the partition size k∗, the leaf threshold τ∗, and the recursion depth. These values are derived to minimize the total computational cost while satisfying accuracy constraints. The optimal partition size k∗ is calculated as k∗=⌈n⋅cin/c⊕⌉, balancing the cost of leaf invocations against the overhead of composition. The depth is bounded by ⌈logk∗(n/K)⌉, ensuring that the number of recursive steps remains predictable and finite.
The third layer handles Neural β-Reductions at the leaves. This is the only component of the system that introduces uncertainty. When the recursive decomposition reaches a sub-prompt Pi with length ∣Pi∣≤τ∗, the system invokes the base language model M to solve the subproblem directly. The model acts as a bounded oracle, operating within its native context window to ensure high accuracy. The results from these leaf calls are then aggregated back up the recursion tree using the symbolic composition operators defined in the first layer. This separation ensures that the neural model is only used where semantic inference is genuinely required, while the surrounding control flow remains symbolic and efficient.
Experiment
- Comparison of λ-RLM against Direct LLM inference and Normal RLM validates that a restricted, typed functional runtime offers superior reliability and efficiency for long-context reasoning compared to stochastic or single-pass methods.
- Experiments confirm the Scale-Substitution Hypothesis, demonstrating that formal control structures allow weaker models (e.g., 8B) to match or exceed the accuracy of much larger models (e.g., 70B+) that lack structured orchestration.
- The Efficiency and Predictability Hypothesis is supported by findings that replacing multi-turn, stochastic REPL loops with a single deterministic combinator chain reduces latency by 3 to 6 times and significantly lowers execution variance.
- Qualitative analysis shows that the structured approach is most effective for complex tasks requiring quadratic cross-referencing, where it prevents the exponential accuracy decay known as context rot that plagues direct inference.
- Ablation studies reveal that the pre-built combinator library is the primary driver of performance gains, while symbolic operations for merging results further reduce latency by eliminating unnecessary LLM calls during recursion.
- While the fixed combinator library generally outperforms open-ended code generation, the latter retains an advantage in specific scenarios requiring creative, task-specific strategies such as adaptive code generation for repository navigation.