Command Palette
Search for a command to run...
SAMA: ترسيخ دلالي مُفكَّك ومحاذاة حركة لتحرير الفيديو الموجه بالأوامر
SAMA: ترسيخ دلالي مُفكَّك ومحاذاة حركة لتحرير الفيديو الموجه بالأوامر
الملخص
تواجه نماذج تحرير الفيديو الحالية الموجهة بالتعليمات صعوبة في الموازنة المتزامنة بين التعديلات الدلالية الدقيقة والحفاظ الأمثل على الحركة. ورغم أن المنهجيات القائمة تعتمد على حقن مسبقات خارجية صريحة (مثل ميزات نماذج اللغة البصرية VLM أو الشروط الهيكلية) للتخفيف من هذه المشكلات، فإن هذا الاعتماد يُعَدّ عنق زجاجة يُضعف بشكل حاد من متانة النموذج وقدرته على التعميم. للتغلب على هذا القيد، نقدم SAMA (المرساة الدلالية المفككة ومحاذاة الحركة)، إطار عمل يفكك عملية تحرير الفيديو إلى مكونين: المرساة الدلالية ونمذجة الحركة. أولاً، نقدم "المرساة الدلالية" (Semantic Anchoring)، التي تُؤسس مرساة بصرية موثوقة من خلال التنبؤ المشترك بالرموز الدلالية (semantic tokens) والتمثيلات الكامنة للفيديو (video latents) في إطارات المرساة المتناثرة، مما يتيح تخطيطاً هيكلياً واعياً بالتعليمات فقط. ثانياً، تقوم "محاذاة الحركة" (Motion Alignment) بتدريب العمود الفقري نفسه مسبقاً على مهام استعادة الفيديو المركزة على الحركة (مثل استكمال المكعبات، وتشويه السرعة، وتبديل الأنابيب)، مما يمكّن النموذج من استيعاب الديناميكيات الزمنية مباشرة من مقاطع الفيديو الخام. يتم تحسين SAMA باستخدام خط أنابيب ثنائي المراحل: مرحلة تدريب مسبق مفككة تتعلم تمثيلات دلالية-حركية متأصلة دون الحاجة إلى بيانات تحرير فيديو-تعليمات مقترنة، تليها مرحلة ضبط دقيق بإشراف (supervised fine-tuning) على بيانات تحرير مقترنة. ومن الجدير بالذكر أن مرحلة التدريب المسبق المفكك وحدها تُنتج بالفعل قدرة قوية على تحرير الفيديو في وضع الصفر (zero-shot)، مما يؤكد صحة عملية التفكيك المقترحة. حققت SAMA أداءً على مستوى أحدث ما توصلت إليه الأبحاث (state-of-the-art) بين النماذج مفتوحة المصدر، وهي تنافس الأنظمة التجارية الرائدة (مثل Kling-Omni). سيتم إصدار الكود البرمجي، والنماذج، ومجموعات البيانات.
One-sentence Summary
Researchers from Baidu, Tsinghua University, and other institutions present SAMA, a framework that factorizes video editing into semantic anchoring and motion alignment. By pre-training on motion-centric restoration tasks without paired data, SAMA achieves state-of-the-art zero-shot performance while avoiding the robustness bottlenecks of prior methods relying on external priors.
Key Contributions
- The paper introduces SAMA, a framework that factorizes video editing into semantic anchoring and motion modeling to reduce reliance on explicit external priors like VLM features or structural conditions.
- Semantic Anchoring establishes reliable visual anchors by jointly predicting semantic tokens and video latents at sparse frames, while Motion Alignment pre-trains the backbone on motion-centric restoration tasks to internalize temporal dynamics from raw videos.
- Experiments demonstrate that the proposed two-stage training pipeline yields strong zero-shot editing capabilities and achieves state-of-the-art performance among open-source models, competing with leading commercial systems.
Introduction
Instruction-guided video editing aims to apply fine-grained semantic changes while preserving the temporal coherence of motion, yet current models struggle to balance these competing demands. Prior approaches often rely on injecting explicit external priors like skeletons or depth maps, which constrains the diffusion backbone from learning inherent semantic-motion representations and leads to artifacts or diluted edits. The authors propose SAMA, a framework that factorizes semantic planning from motion modeling by introducing Semantic Anchoring for instruction-aware structural planning and Motion Alignment to internalize temporal dynamics through motion-centric pre-training. This two-stage strategy enables the model to achieve state-of-the-art performance among open-source systems without heavy reliance on brittle external signals.
Dataset
-
Dataset Composition and Sources: The authors curate a mixed dataset for image and video editing, drawing from NHR-Edit, GPT-image-edit, X2Edit, and Pico-Banana-400K for image editing tasks. For video editing, they utilize Ditto-1M, OpenVE-3M, and ReCo-Data, while incorporating Koala-36M and MotionBench specifically for pretext motion alignment in text-to-video generation.
-
Subset Filtering and Selection: All data undergoes a VLM-based coarse filtering stage using Qwen2.5-VL-72B to score samples on a 1–10 scale across metrics like Instruction Following, Visual Quality, Content Preservation, and Motion Consistency. The authors apply strict thresholds, retaining image samples with scores of 9 or higher for the first three metrics, and video samples with scores of 8 or higher for most metrics and above 8 for Motion Consistency. Specific subsets are selected, including only the Style category from Ditto-1M and the Local Change, Background, Style, and Subtitles categories from OpenVE-3M.
-
Training Strategy and Mixture Ratios: The model undergoes two-stage training on mixed image and video data at 480p resolution with support for multiple aspect ratios. For text-to-video data, the authors employ a sampling ratio of 1:2:3:4 for no-pretext tasks, Cube Inpainting, Speed Perturbation, and Tube Shuffle respectively. Cube Inpainting uses a 30% masking ratio, Speed Perturbation applies 2x temporal acceleration, and Tube Shuffle divides videos into 2x2x2 spatiotemporal tubes for random shuffling.
-
Processing and Configuration Details: During training, the authors uniformly sample N sparse anchor frames for Semantic Anchoring, setting N to 1 for efficiency, and fix the number of local semantic tokens per anchor frame at 64. They maintain an exponential moving average of model parameters with a decay of 0.9998 and set the loss weight lambda to 0.1. Evaluation is conducted on VIE-Bench, OpenVE-Bench, and ReCo-Bench using different VLM judges such as GPT-4o and Gemini-2.5-Pro for scoring.
Method
The authors propose SAMA, a framework built upon the Wan2.1-T2V-14B video diffusion transformer. The core philosophy involves factorizing video editing into semantic anchoring and motion modeling to balance precise semantic modifications with faithful motion preservation. The overall architecture and training pipeline are illustrated in the framework diagram below.
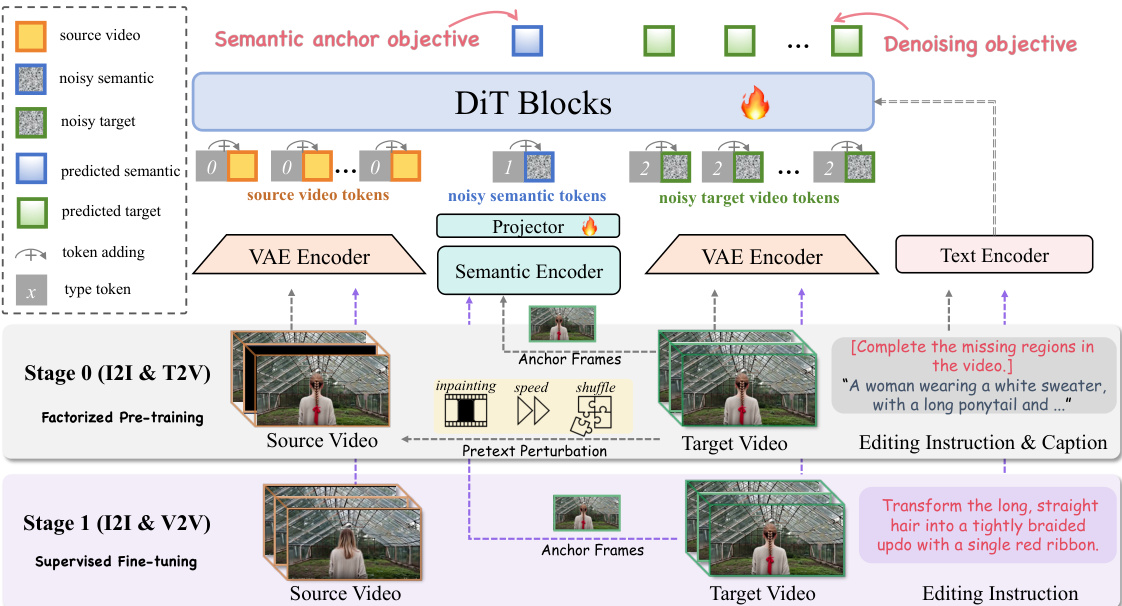
The method encodes source and target videos into VAE latents, denoted as zs and zt. These are concatenated to form an in-context V2V input z=[zs;zt]. To distinguish token roles, learned type embeddings are added: type id 0 for source-video latents, type id 2 for target-video latents, and type id 1 for semantic tokens. This approach is observed to yield faster convergence compared to shifted RoPE schemes.
Semantic Anchoring (SA) establishes reliable visual anchors. For video samples, N frames are uniformly sampled as anchor frames. A SigLIP image encoder extracts patch-level semantic features, which are pooled into local and global tokens. These are projected into the VAE latent space via a lightweight MLP. The projected semantic tokens s^ are prepended to the target latent sequence. Both semantic tokens and target latents undergo the forward noising process. The model predicts the semantic tokens s via a head attached to the final DiT layer. The objective minimizes the ℓ1 loss: Lsem=∥s^−s∥1 The total loss combines flow matching and semantic anchoring: L=LFM+λ⋅Lsem.
Motion Alignment (MA) aligns the edited video with source motion dynamics. It applies motion-centric transformations T only to the source video Vs to create a perturbed version V~s, while keeping the target video unchanged. This forces the model to learn motion recovery. The specific pretext perturbations are detailed in the figure below.

The three transformations include Cube Inpainting (masking temporal blocks), Speed Perturbation (accelerating playback), and Tube Shuffle (permuting spatio-temporal tubes). Task tokens are prepended to instructions to unify the formulation (e.g., "[Complete the missing regions in the video.]").
SAMA utilizes a two-stage pipeline. Stage 0 is Factorized Pre-training, where the model learns inherent semantic-motion representations without paired editing data. SA is applied to both image and video samples, while MA is applied to the video stream. Stage 1 is Supervised Fine-tuning (SFT) on paired video editing datasets. In this stage, the model aligns generation with paired supervision while keeping SA enabled to maintain stable semantic anchoring.
Experiment
- Comparisons with state-of-the-art methods validate that SAMA achieves superior overall performance on Swap, Change, and Remove tasks, demonstrating stronger instruction adherence, better handling of fine-grained spatial and attribute constraints, and improved temporal consistency compared to existing models.
- Zero-shot evaluation confirms the model can perform diverse editing tasks without specific training data, though it exhibits limitations such as temporal color inconsistency, blurriness in added objects, and residual ghosting in removal edits.
- Ablation studies reveal that Semantic Anchoring accelerates model convergence and stabilizes training, while Motion Alignment significantly enhances temporal coherence and reduces motion blur during fast camera movements, with both components proving complementary.
- Visualization of motion-centric pretext tasks indicates that the model successfully internalizes motion cues and temporal reasoning, which directly supports high-quality instruction-guided video editing.