Command Palette
Search for a command to run...
أسرع: إعادة التفكير في نماذج اللغة البصرية-الحركية (VLAs) ذات التدفق في الوقت الفعلي
أسرع: إعادة التفكير في نماذج اللغة البصرية-الحركية (VLAs) ذات التدفق في الوقت الفعلي
Yuxiang Lu Zhe Liu Xianzhe Fan Zhenya Yang Jinghua Hou Junyi Li Kaixin Ding Hengshuang Zhao
الملخص
يُعد التنفيذ في الوقت الفعلي عاملاً حاسمًا لنشر نماذج الرؤية-اللغة-الإجراء (VLA) في العالم المادي. تركز طرق الاستدلال غير المتزامن الحالية في المقام الأول على تحسين سلاسة المسارات، لكنها تتجاهل زمن التأخير الحرج في الاستجابة للتغيرات البيئية. من خلال إعادة تفكير مفهوم "الاستجابة" في سياسات تجزئة إجراءات (action chunking)، يقدم هذا العمل تحليلًا منهجيًا للعوامل المتحكمة في زمن الاستجابة. نبيّن أن زمن الاستجابة يتبع توزيعًا منتظمًا يُحدَّد بشكل مشترك بواسطة "الزمن حتى الإجراء الأول" (TTFA) وأفق التنفيذ. علاوة على ذلك، نكشف أن الممارسة القياسية المتمثلة في تطبيق جدولة زمنية ثابتة في نماذج VLA القائمة على التدفق (flow-based VLAs) قد تكون غير فعالة، حيث تجبر النظام على إكمال جميع خطوات أخذ العينات قبل بدء أي حركة، مما يُشكّل عنق زجاجة في زمن تأخير الاستجابة. للتغلب على هذه المشكلة، نقترح طريقة "أخذ العينات السريع للإجراء من أجل استجابة فورية" (FASTER). ومن خلال إدخال "جدولة واعية بالأفق" (Horizon-Aware Schedule)، تعطي FASTER أولوية تكيفية للإجراءات قصيرة الأجل أثناء أخذ العينات في نماذج التدفق، مما يقلل من عملية إزالة الضوضاء (denoising) اللازمة للاستجابة الفورية بعامل عشرة (مثلًا في نماذج π_{0.5} و X-VLA) إلى خطوة واحدة، مع الحفاظ على جودة المسار طويل الأجل. وبدمجها مع خط أنابيب (pipeline) من نوع "عميل-خادم" تداخلي (streaming)، تقلل FASTER بشكل كبير من زمن تأخير الاستجابة الفعلي على الروبوتات الحقيقية، خاصة عند النشر على وحدات معالجة رسومية (GPUs) من الفئة الاستهلاكية. وتُثبت التجارب في العالم الحقيقي، بما في ذلك مهمة تنس طاولة ديناميكية للغاية، أن FASTER تتيح استجابة في الوقت الفعلي غير مسبوقة للسياسات العامة (generalist policies)، مما يمكّن من توليد مسارات دقيقة وسلسة بسرعة فائقة.
One-sentence Summary
Researchers from The University of Hong Kong and ACE Robotics propose FASTER, a plug-and-play method for flow-based VLAs that employs a Horizon-Aware Schedule to compress immediate action sampling into a single step. This innovation overcomes the latency bottlenecks of constant timestep policies, enabling real-time responsiveness in dynamic tasks like table tennis without architectural changes.
Key Contributions
- The paper presents a systematic analysis of reaction attributes in action chunking VLA policies, revealing that reaction time follows a uniform distribution and identifying how constant timestep schedules create latency bottlenecks.
- This work introduces FASTER, a method utilizing a Horizon-Aware Schedule to adaptively prioritize near-term actions during flow matching, which compresses the Time to First Action to a single sampling step while preserving long-horizon trajectory quality.
- The authors design a streaming client-server interface with early stopping that enables immediate dispatch of initial actions, substantially reducing effective reaction latency and increasing inference-execution cycle frequency on real robots.
Introduction
Deploying Vision-Language-Action (VLA) models in dynamic physical environments requires real-time responsiveness, yet current flow-based policies suffer from high reaction latency due to rigid constant timestep schedules that force the system to complete all sampling steps before executing any movement. While prior asynchronous methods successfully eliminate inter-chunk pauses to improve motion smoothness, they fail to address the critical delay in reacting to sudden environmental changes because they still require full denoising cycles for immediate actions. The authors introduce FASTER, a plug-and-play solution that employs a Horizon-Aware Schedule to adaptively prioritize near-term actions, compressing the sampling of the immediate reaction into a single step while preserving long-horizon trajectory quality. By combining this algorithmic acceleration with a streaming client-server pipeline, FASTER reduces the Time to First Action by tenfold and enables robust real-time control on consumer-grade GPUs without requiring architectural modifications or additional training.
Dataset
-
Dataset Composition and Sources The authors utilize two primary simulation benchmarks: LIBERO and CALVIN. LIBERO targets distinct embodied capabilities through four task suites (Spatial, Object, Goal, and Long), while CALVIN focuses on diverse manipulation skills with unconstrained language instructions.
-
Key Details for Each Subset
- LIBERO: Contains four suites with 10 tasks each, evaluated over 50 trials per task. The authors use the OpenVLA dataset converted to LeRobot format for training π0.5 and the HDF5-format dataset from X-VLA authors for training X-VLA to align with the EE6D action space.
- CALVIN: Comprises 34 tasks evaluated under the ABC→D setting using a LeRobot-format dataset. Evaluation involves 1,000 unique instruction chains where each chain consists of five consecutive tasks.
-
Model Usage and Training Strategy Following prior work, the authors train a single policy across all four LIBERO suites. Performance on CALVIN is measured by the average number of successfully completed tasks per chain.
-
Processing and Evaluation Metrics Data conversion scripts from openpi are used to standardize formats. The Table Tennis task included in the study defines specific scoring criteria based on reaction latency and hit power, ranging from 0 points for a miss to 1 point for a powerful return.
Method
The authors propose FASTER, a framework designed to enhance reaction capability in action chunking policies for Vision-Language-Action (VLA) models. The core challenge addressed is the latency inherent in generating action chunks, which delays the robot's response to dynamic events.
Inference Pipeline and Reaction Analysis The system operates on a client-server architecture where the policy server handles model inference and the robot client manages motor control. The authors analyze two interaction paradigms: synchronous and asynchronous inference. In the synchronous setting, the robot pauses execution while waiting for the next action chunk to be generated, leading to non-smooth trajectories if inference latency exceeds the control period. Conversely, asynchronous inference initiates the next inference cycle before the current action chunk is fully executed, allowing for seamless execution.
Refer to the framework diagram illustrating the temporal pipelines of synchronous and asynchronous inference.
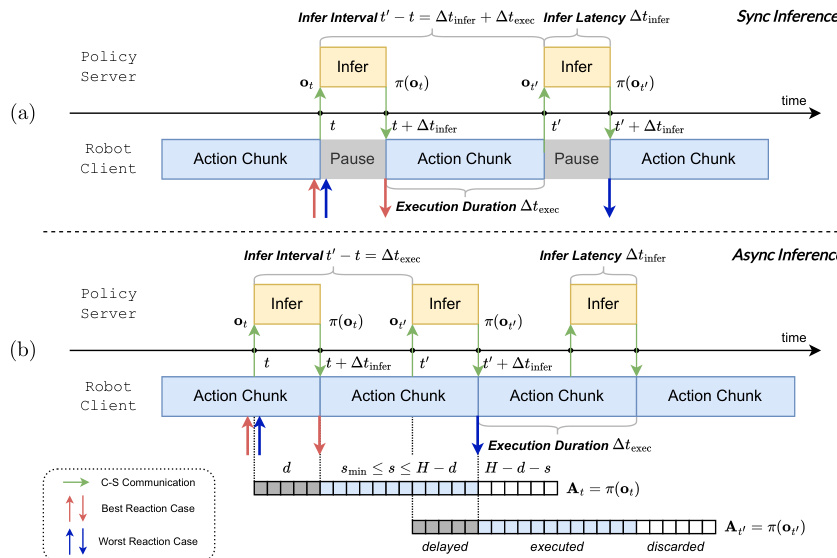
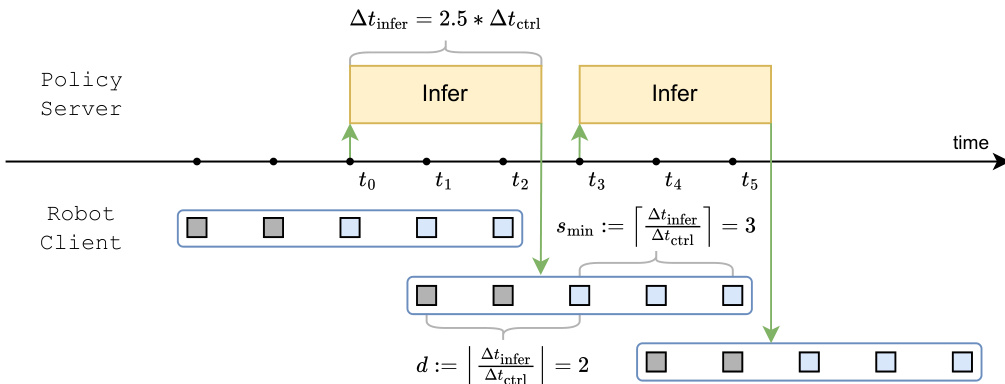
However, asynchronous execution introduces a perception-execution gap, where the observation used for inference may become stale by the time the new actions are ready. To quantify responsiveness, the authors introduce Time to First Action (TTFA), defined as the earliest moment the robot can initiate movement. They note that reducing the execution horizon s increases inference frequency but is bounded by the inference latency Δtinfer. The minimum feasible execution horizon is determined by smin:=⌈Δtinfer/Δtctrl⌉.
Refer to the timeline diagram detailing the asynchronous inference pipeline and discretized inference delay.
Model Architecture and Training The underlying policy utilizes a flow-based VLA structure consisting of a VLM backbone and an Action Expert (AE) module. The model learns a velocity field that transports a noise sample to the target action chunk using conditional flow matching. The training objective minimizes the difference between the predicted velocity field and the ground-truth velocity along a linear interpolation path between Gaussian noise and the target actions:
L(θ)=Eτ∼U(0,1)vθ(ot,Atτ,τ)−(ϵ−A^t)2.During inference, actions are generated by integrating the learned velocity field from τ=1 to τ=0.
Horizon-Aware Schedule (HAS) To minimize TTFA, the authors propose a Horizon-Aware Schedule (HAS) that prioritizes the sampling of near-term actions. Unlike conventional methods that apply a constant time schedule across the entire action chunk, HAS allocates more denoising steps to future actions while accelerating the generation of immediate actions.
Refer to the visualization comparing constant and horizon-aware schedules.
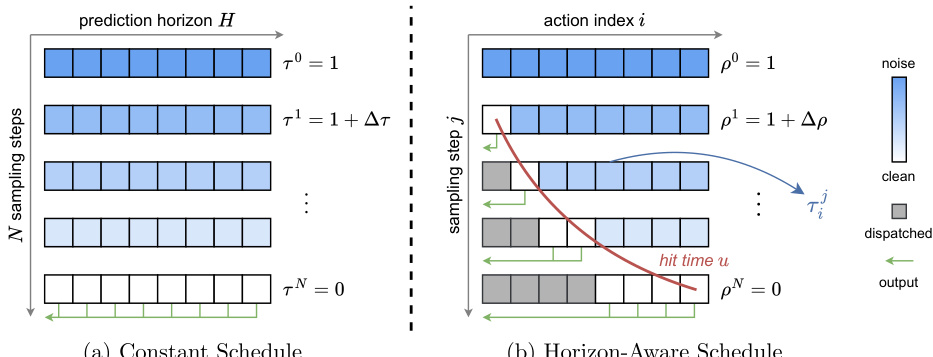
In this scheme, the flow matching timestep is made index-dependent. Each action i has a specific hit time ui determined by its index, ensuring that the first action is fully denoised after a single sampling step. This allows the system to dispatch the first action immediately, significantly reducing latency.
Streaming Interface and Early Stopping The framework implements a streaming client-server interface to exploit the progressive generation of actions. On the server side, finalized actions are dispatched immediately, while the model continues generating the remaining actions. On the client side, the controller appends received actions to the buffer without waiting for the full chunk.
Refer to the comparison of action sampling speeds.
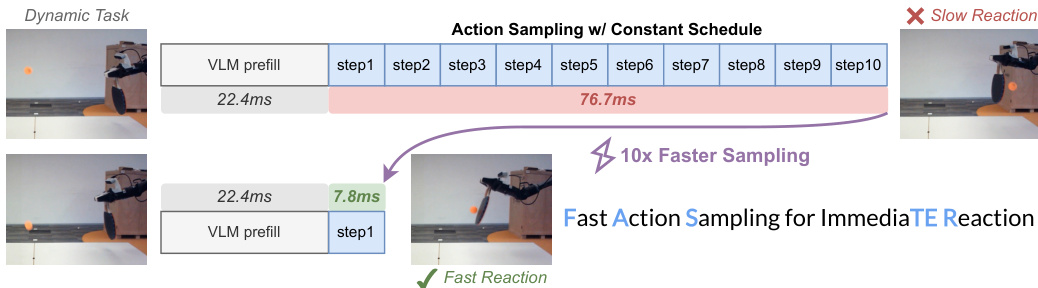
Furthermore, the authors introduce an early-stopping strategy. Once all actions within the execution horizon s are finalized, the remaining sampling steps are skipped. This reduces the overall inference latency for the required actions, allowing for a smaller feasible smin and tighter bounds on reaction time. To ensure robustness during fine-tuning, a mixed scheduling strategy is employed, where the model learns under both the horizon-aware schedule and the original constant schedule.
Experiment
- A pilot study on action chunk sampling validates that early actions in a sequence exhibit lower straightness and faster convergence than future actions, confirming that short-term predictions are easier and more certain due to stronger causal constraints.
- Reaction speed experiments demonstrate that the proposed Horizon-Aware Schedule significantly reduces inference latency and improves probabilistic reaction times compared to synchronous and asynchronous baselines, with deterministic superiority observed on resource-constrained hardware.
- Real-world robotic tasks, including table tennis and manipulation, show that faster reaction capabilities enable earlier motion initiation and better contact quality, proving that balancing responsiveness with accuracy yields superior task completion scores and efficiency.
- Simulation benchmarks on LIBERO, CALVIN, and Kinetix confirm that the adaptive sampling strategy maintains competitive performance with only marginal degradation, while ablation studies verify the robustness of the mixed training schedule and the trade-offs in scheduling parameters.
- A streaming client-server interface analysis reveals that progressive action transmission effectively masks network latency for subsequent actions, ensuring continuous execution without pipeline stalls during real-time operation.