Command Palette
Search for a command to run...
WorldCam: عوالم ألعاب ثلاثية الأبعاد تفاعلية ذاتية الانحدار باستخدام وضعية الكاميرا كتمثيل هندسي موحد
WorldCam: عوالم ألعاب ثلاثية الأبعاد تفاعلية ذاتية الانحدار باستخدام وضعية الكاميرا كتمثيل هندسي موحد
الملخص
أحدثت التطورات الحديثة في محولات الانتشار الفيديوي (Video Diffusion Transformers) نقلة نوعية في نماذج عوالم الألعاب التفاعلية، مما مكّن المستخدمين من استكشاف البيئات المُولَّدة على مدى زمني ممتد. غير أن المنهجيات الحالية تواجه تحديات كبيرة في تحقيق تحكم دقيق في الأفعال والحفاظ على اتساق ثلاثي الأبعاد (3D) على المدى الطويل. فمعظم الأعمال السابقة تعامل أفعال المستخدم كإشارات تكييف مجردة، متجاهلةً الاقتران الهندسي الجوهري بين الأفعال والعالم ثلاثي الأبعاد، حيث تُسبب الأفعال حركات نسبية للكاميرا تتراكم لتُشكّل وضعية كاميرا عالمية ضمن فضاء ثلاثي الأبعاد. في هذه الورقة، نحدد وضعية الكاميرا (Camera Pose) كثيم هندسي موحد لترسيخ كل من التحكم الفوري في الأفعال والاتساق ثلاثي الأبعاد طويل الأمد بشكل متزامن. أولاً، نعرّف فضاء أفعال مستمر قائم على الفيزياء، ونُمثّل مدخلات المستخدم في جبر لي (Lie algebra) لاستنتاج وضعيات كاميرا دقيقة ذات 6 درجات حرية (6-DoF)، تُحقَن بعد ذلك في النموذج التوليدي عبر مُضمّن للكاميرا (Camera Embedder) لضمان محاذاة دقيقة للأفعال. ثانياً، نستخدم وضعيات الكاميرا العالمية كمؤشرات مكانية لاسترجاع الملاحظات السابقة ذات الصلة، مما يتيح إعادة زيارة المواقع بشكل متسق هندسياً أثناء التنقل على المدى الطويل. لدعم هذا البحث، نقدم مجموعة بيانات واسعة النطاق تضم 3000 دقيقة من لعب حقيقي من قبل البشر، ومُعلَّمة بمسارات الكاميرا والوصوف النصية. وتُظهر التجارب المكثفة أن منهجيتنا تتفوق بشكل ملحوظ على أحدث نماذج عوالم الألعاب التفاعلية من حيث قابلية التحكم في الأفعال، والجودة البصرية على المدى الطويل، والاتساق المكاني ثلاثي الأبعاد.
One-sentence Summary
Researchers from KAIST, Adobe Research, and MAUM AI introduce WorldCam, a foundation model that unifies precise action control and long-horizon 3D consistency by mapping user inputs to Lie algebra-based camera poses, outperforming prior methods in interactive gaming scenarios through a novel pose-indexed memory retrieval system.
Key Contributions
- The paper introduces a physics-based continuous action space that translates user inputs into precise 6-DoF camera poses using Lie algebra, which are then injected into a video diffusion transformer via a camera embedder to ensure accurate action alignment.
- A retrieval mechanism is presented that uses global camera poses as spatial indices to fetch relevant past observations, enabling geometrically consistent revisiting of locations during long-horizon navigation.
- The authors release a large-scale dataset containing 3,000 minutes of authentic human gameplay annotated with camera trajectories and textual descriptions to support the training and evaluation of interactive gaming world models.
Introduction
Interactive gaming world models built on video diffusion transformers aim to generate playable environments, yet they struggle with precise action control and maintaining 3D consistency over long horizons. Prior approaches often treat user inputs as abstract signals or rely on simplified linear approximations, which fail to capture the complex geometric coupling between actions and camera motion in a 3D space. The authors introduce WorldCam, a framework that establishes camera pose as a unifying geometric representation to simultaneously ground immediate action control and long-term spatial consistency. They achieve this by translating user inputs into precise 6-DoF poses using Lie algebra and leveraging these poses to retrieve past observations for geometrically coherent revisiting of locations. Additionally, the team addresses data scarcity by releasing WorldCam-50h, a large-scale dataset of authentic human gameplay annotated with camera trajectories and text descriptions.
Dataset
-
Dataset Composition and Sources: The authors introduce WorldCam-50h, a large-scale dataset of human gameplay videos designed to capture authentic action dynamics. Data is sourced from three games: Counter-Strike (closed-licensed), and Xonotic and Unvanquished (open-licensed under CC BY-SA 2.5 and GPL v3). The collection focuses on single-player exploration within static environments to ensure reproducibility and visual diversity.
-
Key Details for Each Subset: The dataset comprises over 100 videos per game, with each video averaging 8 minutes to yield approximately 17 hours of footage per title. Participants were instructed to perform diverse behaviors such as navigation, rapid camera movements, and revisiting locations. The total collection amounts to roughly 50 hours of gameplay.
-
Model Usage and Training Strategy: The authors utilize the entire dataset for training foundational gaming world models. Unlike prior works that discard textual guidance, this approach leverages detailed captions to maintain frame quality and scene style during the training process.
-
Processing and Metadata Construction:
- Captioning: Each training video chunk is annotated with detailed textual descriptions generated by Qwen2.5-VL-7B. These prompts focus on global layout, visual themes, and ambient environmental conditions.
- Camera Annotation: Global camera pose information, including intrinsics and extrinsics, is extracted for every one-minute segment using ViPE.
- Filtering: To ensure data quality, the authors apply a filtering step that removes camera pose estimates with unrealistically large translation magnitudes.
Method
The authors propose WorldCam, an interactive 3D world model designed to autoregressively generate video sequences that accurately follow user actions while maintaining long-term spatial consistency. The system takes an initial RGB observation, a text prompt, and a sequence of user actions as input to generate future frames.
Refer to the framework diagram below for an overview of the system architecture, which integrates action-to-camera mapping, camera-controlled generation, and a pose-anchored memory mechanism.
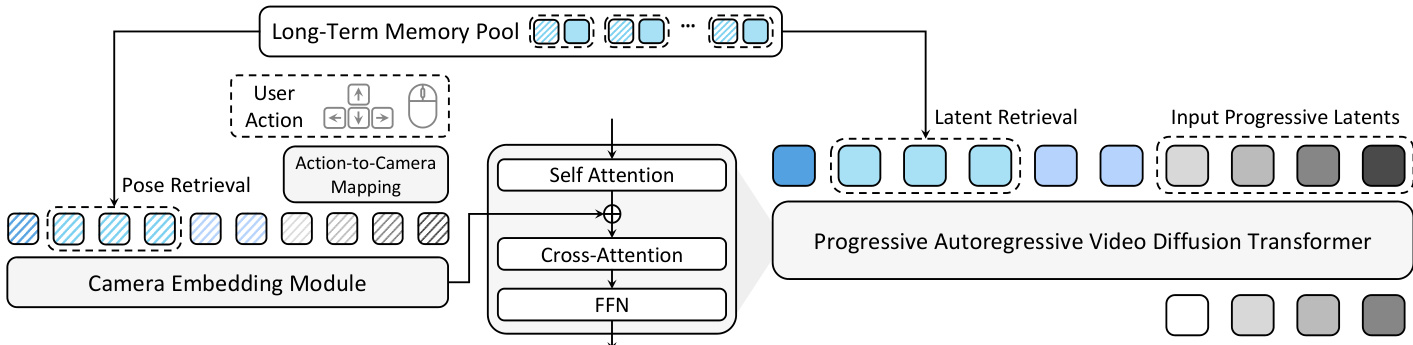
The core generative backbone is a pretrained Video Diffusion Transformer (DiT), specifically Wan-2.1-T2V. Given an input video V, a VAE encoder maps it to a latent sequence z0. The DiT learns to predict the velocity field that transports noisy latents zt toward the clean latents z0 using a flow matching objective:
LFM=Ez0,ctext,t[vθ(zt,ctext,t)−1−tz0−zt22].To ensure precise control over camera motion, the authors define the action space in the Lie algebra se(3). User actions are represented as twist vectors Ai=[vi;ωi]∈R6, containing linear and angular velocities. These are converted into relative camera poses ΔPi∈SE(3) via the matrix exponential map:
ΔPi=exp(A^i)=[ΔRi0⊤Δti1],where A^i is the 4×4 matrix representation of the twist. This formulation jointly integrates linear and angular velocities on the SE(3) manifold, avoiding the geometric inconsistencies found in decoupled linear approximations.
The derived camera poses are then used to condition the generative model. The poses are converted into Plücker embeddings P^∈RF×6 to provide explicit view-dependent geometric information. A lightweight camera embedding module cϕ consisting of two MLP layers processes these embeddings. To align with the temporally compressed latent sequence, r consecutive Plücker embeddings are concatenated for each latent frame. The resulting camera embeddings are added to the DiT features d after each self-attention layer:
d←d+cϕ(p^).To maintain 3D consistency over long horizons, the system employs a pose-anchored long-term memory pool M. This pool stores previously generated latents along with their global camera poses. The global pose Piglobal is computed by accumulating relative poses. During generation, a hierarchical retrieval strategy is used to find relevant context. First, the system selects the top-K candidates based on translation distance to the current position. From these, it further selects L entries whose viewing directions are most aligned with the current orientation, measured by the trace of the relative rotation matrix. These retrieved latents are concatenated with the current input sequence, and their associated poses are realigned and injected into the DiT to enforce spatial coherence.
Finally, the model utilizes a progressive autoregressive inference strategy. A progressive per-frame noise schedule assigns monotonically increasing noise levels to latent frames within each denoising window. This provides a low-noise anchor in early frames while keeping future frames at higher noise levels for correction. During inference, the latent sequence is shifted forward after completing all denoising stages, with the earliest frame evicted and a new pure-noise latent appended. An attention sink mechanism is also incorporated to stabilize attention and preserve frame fidelity during long rollouts.
Experiment
- Comparison with state-of-the-art interactive gaming and camera-controlled models validates that the proposed method achieves superior action controllability, visual quality, and 3D consistency over long-horizon sequences, whereas baselines suffer from visual drift, coarse control, or inability to maintain geometric coherence.
- Qualitative analysis confirms the model faithfully follows complex user inputs and preserves consistent 3D scene structures even when revisiting previously seen locations, while prior methods often fail to maintain geometry beyond short generation windows.
- Ablation studies demonstrate that Lie algebra-based action-to-camera mapping provides more accurate motion control than linear approximations, and that increasing long-term memory latents alongside attention sinks significantly enhances 3D consistency and reduces long-horizon error drift.
- Human evaluation and quantitative metrics collectively verify that the approach outperforms existing baselines across all key aspects, establishing it as a robust solution for interactive 3D world modeling.