Command Palette
Search for a command to run...
OpenSeeker: تمكين وكلاء البحث المتقدمة من خلال جعل بيانات التدريب مفتوحة المصدر بالكامل
OpenSeeker: تمكين وكلاء البحث المتقدمة من خلال جعل بيانات التدريب مفتوحة المصدر بالكامل
Yuwen Du Rui Ye Shuo Tang Xinyu Zhu Yijun Lu Yuzhu Cai Siheng Chen
الملخص
أصبحت قدرات البحث العميق كفاءة لا غنى عنها لوكلاء نماذج اللغة الكبيرة (LLM) الرائدة؛ غير أن تطوير وكلاء بحث عالي الأداء لا يزال يهيمن عليه العمالقة الصناعيون، وذلك نتيجةً لنقص بيانات التدريب الشفافة وعالية الجودة. وقد عرقل هذا النقص الدائم في البيانات تقدم المجتمع البحثي الأوسع بشكل جذري في مجال التطوير والابتكار ضمن هذا الحقل. ولسد هذه الفجوة، نقدم OpenSeeker، وهو أول وكيل بحث مفتوح المصدر بالكامل (يشمل النموذج والبيانات)، يحقق مستوى أداء رائدًا من خلال ابتكارين تقنيين أساسيين: (1) توليد أسئلة وأجوبة (QA) قابل للتحكم وقابل للتوسع ومُرسَّس على الحقائق، الذي يعكس هندسة رسم الويب (web graph) عبر التوسع الطوبولوجي وإخفاء الكيانات لتوليد مهام استدلال معقدة متعددة الخطوات، مع إمكانية التحكم في نطاقها وتعقيدها. (2) توليد مسارات مُنقَّاة من الضوضاء، الذي يستعين بآلية تلخيص استرجاعي لتنقية المسار، مما يشجّع نماذج اللغة الكبيرة المعلمة (teacher LLMs) على توليد إجراءات عالية الجودة. وتُظهر النتائج التجريبية أن OpenSeeker، الذي تم تدريبه (في جولة تدريب واحدة) على 11.7 ألف عينة مُصنَّعة فقط، يحقق أداءً متفوقًا على أحدث ما توصلت إليه الأبحاث (state-of-the-art) عبر عدة معايير تقييم (benchmarks)، منها BrowseComp وBrowseComp-ZH وxbench-DeepSearch وWideSearch. ومن الجدير بالذكر أنه، عند تدريبه باستخدام ضبط دقيق بسيط (SFT)، يتفوق OpenSeeker بشكل ملحوظ على الوكيل المفتوح المصدر الثاني من حيث الانفتاح الكامل، DeepDive (على سبيل المثال، 29.5% مقابل 15.3% على BrowseComp)، بل ويتجاوز حتى المنافسين الصناعيين مثل Tongyi DeepResearch (الذي تم تدريبه عبر تدريب مسبق مستمر مكثف، وضبط دقيق SFT، وتعلم التعزيز RL) على معيار BrowseComp-ZH (48.4% مقابل 46.7%). وقد قمنا بنشر مجموعة بيانات التدريب الكاملة وأوزان النموذج بشكل مفتوح بالكامل، وذلك لتمكين أبحاث وكلاء البحث الرائدة وتعزيز نظام بيئي أكثر شفافية وتعاونًا.
One-sentence Summary
Researchers from Shanghai Jiao Tong University introduce OpenSeeker, a fully open-source search agent that leverages fact-grounded scalable QA synthesis and denoised trajectory techniques to achieve state-of-the-art performance on complex benchmarks using simple supervised fine-tuning.
Key Contributions
- The paper introduces a fact-grounded scalable controllable QA synthesis method that reverse-engineers the web graph through topological expansion and entity obfuscation to generate complex, multi-hop reasoning tasks with adjustable difficulty.
- A denoised trajectory synthesis technique is presented that employs retrospective summarization to clean historical context for teacher models, enabling the generation of high-quality action sequences while training the agent on raw, noisy data to improve robustness.
- The work releases the fully open-source OpenSeeker agent, including its complete training dataset and model weights, which achieves state-of-the-art performance on multiple benchmarks using only simple supervised fine-tuning on 11.7k synthesized samples.
Introduction
Deep search capabilities are now essential for Large Language Model agents to navigate the internet for accurate, real-time information, yet this field has been dominated by industrial giants due to a lack of transparent, high-quality training data. Prior open-source efforts have failed to bridge this gap because they either withhold their training datasets, release only partial data, or rely on low-fidelity samples that cannot support frontier-level performance. To address these limitations, the authors introduce OpenSeeker, the first fully open-source search agent that achieves state-of-the-art results by leveraging two key innovations: fact-grounded scalable controllable QA synthesis to generate complex multi-hop reasoning tasks and denoised trajectory synthesis to teach models how to extract signals from noisy web content.
Dataset
-
Dataset Composition and Sources: The authors construct a high-fidelity dataset D comprising complex queries, ground truth answers, and optimal tool-use trajectories by reverse-engineering the web graph. They leverage approximately 68GB of English and 9GB of Chinese web data to anchor every query in real-world topology, ensuring factual grounding and eliminating hallucination risks.
-
Key Details for Each Subset: The synthesis pipeline operates in two phases: Generative Construction to create candidate pairs and Dual-Criteria Verification to filter for difficulty and solvability. Task difficulty is a deliberate design choice controlled by tuning the subgraph size k, which calibrates reasoning complexity and information coverage to create a curriculum ranging from straightforward retrieval to multi-hop investigations.
-
Model Usage and Training Strategy: The dataset trains an agent to master long-horizon tool invocation by forcing it to predict expert-level reasoning and tool calls conditioned on raw history. The training mixture utilizes the synthesized pairs to teach the model to handle complex queries that necessitate extended chains of "Reasoning → Tool Call → Tool Response" interactions.
-
Processing and Denoising Strategy: A unique asymmetry exists between synthesis and training. During synthesis, the authors employ a retrospective summarization mechanism where raw tool responses are condensed into summarized versions to help the teacher generate high-quality reasoning. However, the final training and inference phases operate exclusively on raw tool responses to force the model to intrinsically learn denoising capabilities and extract relevant information from noisy contexts.
Method
The proposed framework operates through two distinct phases: the generative construction of complex question-answer pairs and the synthesis of denoised reasoning trajectories.
Generative Construction and Verification
The authors leverage a graph-based pipeline to construct high-quality QA pairs, as illustrated in the framework diagram below.

The process begins with the QA Generation module. To mimic natural information discovery, the system samples a seed node vseed from a web corpus and expands it by traversing outgoing edges to form a local dependency subgraph Gsub. This subgraph serves as a topologically-linked knowledge base. To reduce noise, an extraction function identifies a central theme ytheme and distills key entities into a condensed Entity Subgraph Gentity. A generator Pgen then synthesizes an initial question qinit conditioned on Gentity, enforcing a structural constraint where deriving the answer requires traversing multiple edges.
To prevent agents from exploiting specific keywords, the pipeline applies obfuscation. An obfuscation operator Φ maps concrete entities e to vague descriptions e~=Φ(e), creating a Fuzzy Entity Subgraph G~entity. The final question q~ is generated by rewriting qinit to incorporate these ambiguous descriptions while preserving the reasoning logic.
Following generation, the QA Verifier module employs a rejection sampling scheme based on two criteria. First, a difficulty check ensures the question cannot be solved by a foundation model πbase in a closed-book setting (I[πbase(q~)=y]), guaranteeing the necessity of external tools. Second, a solvability check verifies logical consistency by confirming the model can derive the answer y when provided with the full Entity Subgraph Gentity as context (I[πbase(q~∣Gentity)=y]).
Denoised Trajectory Synthesis
To address the challenge of information retention versus context window constraints in web-scale search, the authors propose a synthesis framework that decouples the generation context from the training context. This process is visualized in the trajectory synthesis diagram below.
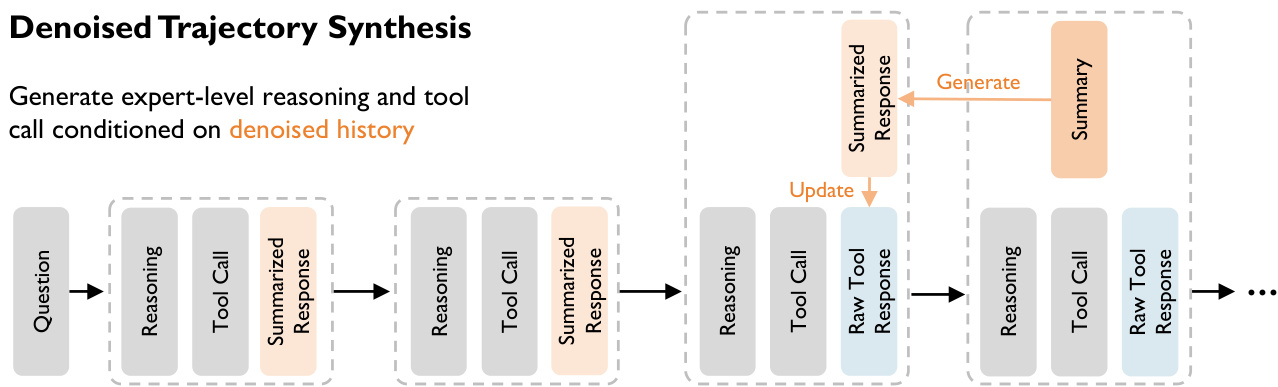
The synthesis employs a dynamic context denoising strategy using a "Summarized History + Raw Recent" protocol. At any turn t, the agent generates a reasoning and action pair (rt,at) based on a context Ht. This context includes a summarized long-term history where past observations oi are compressed into semantic summaries si, alongside the raw observation ot−1 from the immediately preceding step. This ensures the agent has access to all signals in the most recent observation while maintaining a concise memory of the past.
The framework operates in a two-phase cycle. During the decision phase, the agent utilizes the full raw observation ot−1 to inform its next move. In the subsequent compression phase, once a new observation ot is obtained, a summarizer compresses the previous observation ot−1 into st−1, which replaces the raw data in the long-term history for the next step.
Finally, the authors implement an asymmetric context training strategy to cultivate robustness. The trajectories are synthesized by a "Teacher" model using the clean, denoised context containing summaries. However, for the final training dataset, the "Student" model is supervised to predict the optimal reasoning and actions given the noisy raw context Httrain, which strips away the summaries. This forces the student model to implicitly learn the denoising and information extraction capabilities, internalizing the logic required to handle real-world unstructured data.
Experiment
- OpenSeeker, trained solely via supervised fine-tuning on a small, high-quality dataset, outperforms resource-intensive proprietary models and complex multi-stage training baselines on benchmarks testing multi-step navigation and deep research, validating that data quality surpasses training complexity.
- Comparisons with similarly sized models demonstrate that OpenSeeker's synthesized data is significantly more effective than larger, noisier datasets, proving that its denoised trajectory synthesis successfully teaches agents to extract critical information from complex web observations.
- Performance evaluations against concurrent academic and corporate works confirm that OpenSeeker achieves state-of-the-art results with full data transparency and a lean SFT-only approach, establishing that strategic data synthesis can replace massive compute and reinforcement learning cycles.
- Difficulty analysis reveals that the synthesized training data exceeds the complexity of standard benchmarks in terms of tool calls and token length, directly correlating this high-fidelity challenge with superior model performance on hard information-seeking tasks.