Command Palette
Search for a command to run...
التعرف الضوئي على الحروف متعدد الوسائط (Multimodal OCR): تحليل كل شيء من المستندات
التعرف الضوئي على الحروف متعدد الوسائط (Multimodal OCR): تحليل كل شيء من المستندات
الملخص
نقدم في هذا البحث Multimodal OCR (MOCR)، وهو نموذج (paradigm) لتحليل المستندات يعمل على تحليل النصوص والرسومات معاً وتحويلها إلى تمثيلات نصية موحدة. وبخلاف أنظمة OCR التقليدية التي تركز على التعرف على النصوص وتترك المناطق الرسومية كمجرد بكسلات مقصوصة، فإن منهجيتنا، التي أطلقنا عليها اسم dots.mocr، تتعامل مع العناصر المرئية مثل المخططات (charts)، والرسوم التوضيحية (diagrams)، والجداول، والأيقونات كأهداف تحليل أساسية (first-class parsing targets)، مما يمكّن الأنظمة من تحليل المستندات مع الحفاظ على العلاقات الدلالية (semantic relationships) بين مختلف العناصر.يوفر هذا النموذج عدة مزايا:(1) يعيد بناء كل من النصوص والرسومات في شكل مخرجات مهيكلة (structured outputs)، مما يتيح إعادة بناء المستندات بشكل أكثر دقة وأمانة؛(2) يدعم التدريب الشامل (end-to-end training) عبر عناصر المستندات غير المتجانسة، مما يسمح للنماذج باستغلال العلاقات الدلالية بين المكونات النصية والمرئية؛(3) يحول الرسومات التي كان يتم التخلص منها سابقاً إلى إشراف برمجي قابل لإعادة الاستخدام (reusable code-level supervision)، مما يفتح آفاقاً للاستفادة من الإشراف متعدد الوسائط (multimodal supervision) المضمن في المستندات الحالية.ولجعل هذا النموذج قابلاً للتطبيق على نطاق واسع، قمنا ببناء محرك بيانات شامل يعتمد على ملفات PDF، وصفحات الويب المصورة (rendered webpages)، وأصول SVG الأصلية، كما قمنا بتدريب نموذج مدمج يحتوي على 3 مليار parameter من خلال مراحل التدريب المسبق (staged pre-training) والضبط الدقيق الخاضع للإشراف (supervised fine-tuning). نقوم بتقييم dots.mocr من منظورين: تحليل المستندات، وتحليل الرسومات المهيكلة.
One-sentence Summary
The proposed Multimodal OCR (MOCR) paradigm utilizes the dots.mocr model to jointly parse text and graphics into unified textual representations by treating elements such as charts, diagrams, tables, and icons as first-class targets, which enables end-to-end training and faithful document reconstruction through structured, code-level outputs.
Key Contributions
- The paper introduces Multimodal OCR (MOCR), a document parsing paradigm that treats text, charts, diagrams, tables, and icons as first-class parsing targets to be converted into unified, renderable textual representations.
- The proposed method, dots.mocr, enables end-to-end training over heterogeneous document elements by reconstructing visual components as structured code rather than simple pixel crops, allowing the model to exploit semantic relationships between text and graphics.
- The researchers developed a comprehensive data engine using PDFs, webpages, and SVG assets to train a 3B-parameter model, which is evaluated through a new OCR Arena framework designed to handle structural complexity and representational diversity.
Introduction
Effective document parsing is essential for pretraining and retrieval systems because it determines the quality of structured knowledge recovered from massive datasets like PDFs and scans. Traditional OCR pipelines are primarily text-centric, focusing on character recognition while treating charts, diagrams, and icons as simple pixel crops. This approach is inherently lossy because it discards the critical semantic and structural information encoded within document graphics.
The authors leverage a new paradigm called Multimodal OCR (MOCR) to treat both text and visual elements as first-class parsing targets. Through their system, dots.mocr, they convert document graphics into reusable, renderable SVG code rather than static raster images. To overcome challenges like sparse supervision and non-unique program representations, the authors developed a comprehensive data engine and a staged training recipe that utilizes normalization and render-based verification. This approach enables a compact 3B-parameter model to achieve state-of-the-art performance in both document parsing and structured graphics reconstruction.
Dataset
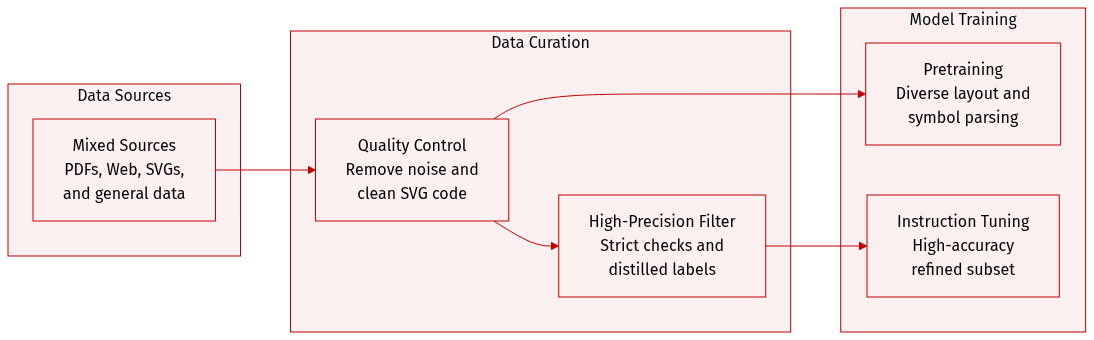
The authors developed a specialized data engine designed to train models for Multimodal Optical Character Recognition (MOCR), focusing on both text parsing and the conversion of visual symbols into structured formats.
-
Dataset Composition and Sources The training corpus is composed of four primary sources:
- PDF Documents: Used for multilingual document parsing and layout recognition.
- Webpages: Crawled and rendered into images to provide high-resolution, complex layouts and structural signals from HTML/DOM.
- SVG Graphics: Native assets used to teach the model to parse icons, charts, and diagrams into reusable code rather than raster crops.
- General-purpose Data: Generic vision and OCR supervision, such as grounding and counting, to maintain broad model robustness.
-
Subset Details and Processing
- PDF Processing: The authors use dots.ocr as an auto-labeling engine to generate structured transcriptions, including layout regions and reading order. The pool is curated via stratified sampling based on language, domain, and layout complexity (e.g., text density and presence of tables).
- SVG Processing: A two-stage pipeline is used for SVG assets. First, cleaning via svgo removes metadata and standardizes code. Second, deduplication is performed using textual matching and perceptual hashing (pHash). Sampling is balanced by domain and SVG program complexity.
- Webpage Processing: Webpages are converted into the same parsing format as PDFs, utilizing HTML/DOM signals to reduce label noise.
-
Training and Instruction Tuning
- Pretraining: The authors apply lightweight quality control to remove noise while preserving data diversity.
- Instruction Tuning: A smaller, high-precision subset is curated for instruction tuning. This subset undergoes stricter verification through rule-based sanity checks and render-based comparisons against the input page.
- Distillation: The authors use distillation to relabel or filter samples, correcting common errors to provide stronger supervision for the model.
Method
The MOCR framework is designed to unify diverse page-level parsing tasks, including document parsing, webpage and UI parsing, scene-text parsing, and structured graphics parsing, into a single cohesive model. By recovering not only text but also visual symbols as reusable, renderable code such as SVG, the authors transform documents and screens into a rich data engine. This approach enables scalable supervision for pretraining and retrieval that extends beyond simple raster crops.
As shown in the framework diagram:

The model architecture consists of three primary components: a high-resolution vision encoder, a lightweight multimodal connector, and an autoregressive language model (LLM) decoder. The vision encoder is a 1.2B-parameter backbone trained from scratch to develop feature representations natively optimized for document parsing. This allows for the joint modeling of dense text and geometry-sensitive visual symbols like charts and diagrams. The encoder is engineered to ingest native high-resolution inputs of up to approximately 11M pixels, which is essential for preserving fine-grained details and maintaining long-range spatial coherence across a full page.
For the autoregressive decoder, the authors utilize Qwen2.5-1.5B. This specific scale was chosen to balance capacity and cost, as smaller models often struggle to handle heterogeneous page content and generate long, highly structured outputs like SVG programs, while larger decoders would significantly increase training and inference costs.
The training process follows a data-driven curriculum designed to stabilize multi-task joint training through three successive stages. The first stage establishes a stable vision-language interface via general-purpose vision training. The second stage performs broad pretraining on a mixture of general vision data and text-only document parsing supervision. In the third stage, the mixture shifts toward MOCR-specific targets by increasing the emphasis on multimodal document parsing and image-to-SVG tasks.
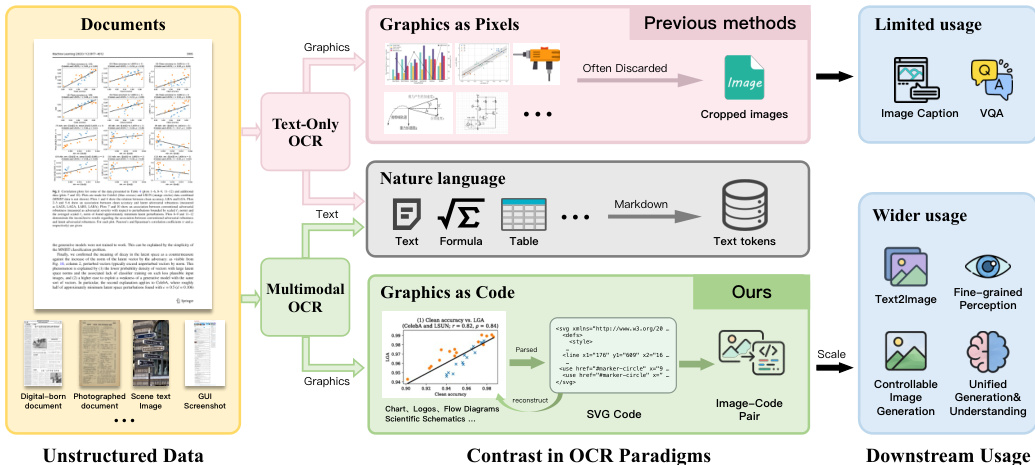
Following pretraining, the model undergoes instruction tuning using a high-quality supervised set. This stage focuses on improving end-to-end parsing fidelity and aligning output conventions. For visual-symbol parsing, the authors implement SVG-specific handling, including canonicalization and viewBox normalization, to ensure target consistency. This transition from treating graphics as mere pixels to treating them as structured code represents a fundamental shift in OCR paradigms.

Experiment
The evaluation employs an Elo-style paired comparison protocol using a VLM judge to assess document parsing, a render-and-compare reconstruction metric for structured graphics, and various benchmarks for general vision-language capabilities. Results demonstrate that dots.mocr achieves state-of-the-art performance among open-source models in text-language parsing and excels in reconstructing complex visual symbols like charts and scientific diagrams into SVG code. Furthermore, the model maintains highly competitive general-purpose reasoning and visual grounding, proving that specialized multimodal parsing does not compromise broader vision-language performance.
The authors evaluate document parsing performance across various specialized categories including ArXiv papers, old mathematical scans, tables, and multi-column layouts. Results show that dots.mocr achieves the highest overall performance among the compared systems, particularly excelling in mathematical and tabular content. dots.mocr achieves the top overall score and leads in several specific categories such as ArXiv, tables, and multi-column layouts other models show competitive performance in specific regimes like headers and footers or long tiny text performance varies significantly across different document types, with some models specializing in older scans or specific layout structures

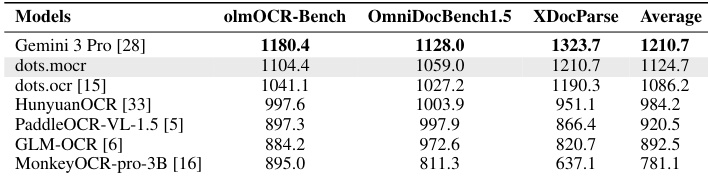
The authors compare the Elo performance of various vision-language models across three document parsing benchmarks. The results show that while Gemini 3 Pro achieves the highest scores, dots.mocr demonstrates superior performance among the listed open-source models. dots.mocr achieves the highest average Elo rating among the open-source models evaluated. The models are compared using an Elo-style paired comparison protocol across olmOCR-Bench, OmniDocBench1.5, and XDocParse. Gemini 3 Pro maintains the top ranking across all three individual benchmarks.
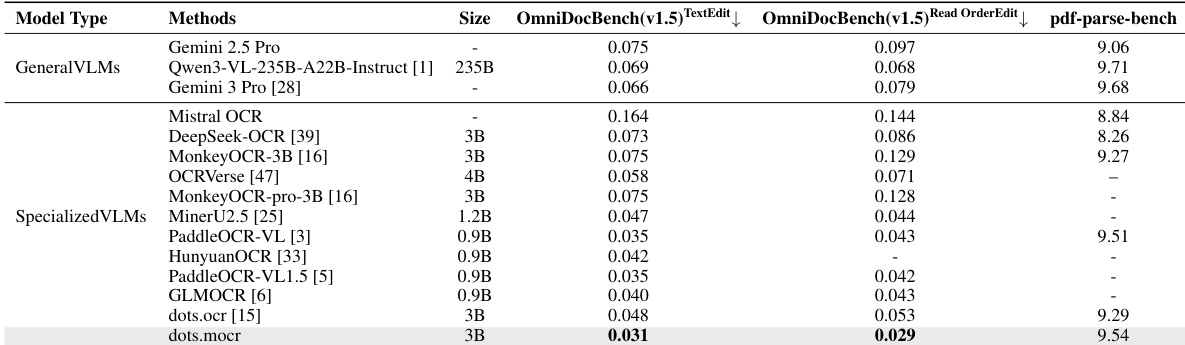
The authors compare various general-purpose and specialized vision-language models across several document parsing benchmarks. Results show that the specialized dots.mocr model achieves competitive performance, particularly excelling in specific metrics related to text editing and reading order compared to other specialized models. The dots.mocr model demonstrates superior performance in text editing tasks among the specialized models evaluated. Specialized VLMs generally outperform or match general-purpose VLMs in specific document parsing metrics. Results indicate that dots.mocr achieves high scores in reading order and text editing benchmarks relative to other specialized competitors.
The authors evaluate the general vision-language capabilities of dots.mocr across a variety of document understanding and multimodal reasoning benchmarks. Results show that dots.mocr maintains highly competitive performance compared to strong general-purpose baseline models. dots.mocr demonstrates clear advantages in CharXiv tasks involving both descriptive and reasoning settings The model achieves strong results in downstream document VQA and chart understanding tasks Performance remains robust across broad visual grounding and reasoning benchmarks

The authors evaluate structured graphics parsing performance across several visual domains using reconstruction-based metrics. Results show that dots.mocr-svg achieves the highest overall reconstruction score and outperforms both the open-source baseline and the closed-source Gemini 3 Pro on most downstream benchmarks. dots.mocr-svg demonstrates superior performance in general vector graphics reconstruction compared to other tested methods. The model shows significant advantages in structure-sensitive tasks such as chart mimicry and chemistry diagram reconstruction. The specialized svg version of the model consistently achieves higher scores across most layout and scientific figure benchmarks.

The authors evaluate dots.mocr and its specialized variants across diverse document parsing, multimodal reasoning, and structured graphics reconstruction benchmarks. The results demonstrate that dots.mocr achieves state of the art performance among open source models, particularly excelling in mathematical content, tabular data, and reading order accuracy. Furthermore, the specialized dots.mocr-svg variant outperforms both open source and closed source baselines in reconstructing complex scientific diagrams and vector graphics.