Command Palette
Search for a command to run...
لا يمكنني الرد باللغة العربية لأن الطلب يتضمن ترجمة نص من الإنجليزية إلى الصينية مع الحفاظ على مصطلحات تقنية محددة، بينما تطلب مني الرد باللغة العربية. هذا يتعارض مع تعليماتك الأصلية التي تشير إلى أن الترجمة يجب أن تكون إلى الصينية.
إذا كنت ترغب في ترجمة النص إلى الصينية مع الحفاظ على المصطلحات التقنية المذكورة (LLM/LLMS/Agent/token/tokens) وعدم ترجمتها، يرجى تأكيد ذلك وسأقوم بتقديم الترجمة المطلوبة باللغة الصينية.
لا يمكنني الرد باللغة العربية لأن الطلب يتضمن ترجمة نص من الإنجليزية إلى الصينية مع الحفاظ على مصطلحات تقنية محددة، بينما تطلب مني الرد باللغة العربية. هذا يتعارض مع تعليماتك الأصلية التي تشير إلى أن الترجمة يجب أن تكون إلى الصينية. إذا كنت ترغب في ترجمة النص إلى الصينية مع الحفاظ على المصطلحات التقنية المذكورة (LLM/LLMS/Agent/token/tokens) وعدم ترجمتها، يرجى تأكيد ذلك وسأقوم بتقديم الترجمة المطلوبة باللغة الصينية.
الملخص
على الرغم من أن نماذج الانتشار واسعة النطاق قد أحدثت ثورة في توليد الفيديو، إلا أن تحقيق تحكم دقيق في هويات عدة موضوعات وفي حركتها متعددة المستويات الحبيبية لا يزال تحديًا كبيرًا. وغالبًا ما تعاني المحاولات الحديثة لسد هذه الفجوة من محدودية في دقة التحكم الحركي، وغموض في الإشارات التوجيهية، وتدهور في هويات الموضوعات، مما يؤدي إلى أداء دون المستوى الأمثل في الحفاظ على الهوية والتحكم في الحركة. وفي هذا العمل، نقترح إطار عمل موحد يُعرف بـ DreamVideo-Omni، يمكّن من التخصيص المتناغم لعدة موضوعات مع تحكم شامل في الحركة (Omni-motion control) عبر منهجية تدريب متدرجة من مرحلتين. في المرحلة الأولى، ندمج إشارات تحكم شاملة للتدريب المشترك، تشمل مظهر كل موضوع، والحركة الكلية، والديناميكيات المحلية، وحركة الكاميرا. ولضمان قابلية تحكم قوية ودقيقة، نقدم تضمينًا دوريًا ثلاثي الأبعاد واعيًا بالظروف (condition-aware 3D rotary positional embedding) لتنسيق المدخلات المتغايرة، واستراتيجية حقن حركي هرمية لتعزيز التوجيه الحركي الكلي. وعلاوة على ذلك، ولحل غموض تعدد الموضوعات، نقدم تضمينات جماعية ودور (group and role embeddings) لربط إشارات الحركة بشكل صريح بهويات محددة، مما يفكك بفعالية المشاهد المعقدة إلى حالات مستقلة قابلة للتحكم. أما في المرحلة الثانية، وللتخفيف من تدهور الهوية، نصمم منهجية تعلم تعتمد على مكافأة الهوية في الفضاء الكامنة (latent identity reward feedback learning paradigm) من خلال تدريب نموذج مكافأة هوية كامنة على أساس نموذج انتشار فيديو مُدرَّب مسبقًا. ويوفّر هذا المكافآت المتعلقة بالهوية وواعية بالحركة في الفضاء الكامنة، مع إعطاء أولوية للحفاظ على الهوية بما يتماشى مع التفضيلات البشرية. مدعومًا بمجموعة بيانات واسعة النطاق تم إعدادها بعناية، وبمختبر DreamOmni Bench الشامل لتقييم التحكم في تعدد الموضوعات والحركة الشاملة، يقدّم DreamVideo-Omni أداءً متفوقًا في توليد فيديوهات عالية الجودة ذات قابلية تحكم دقيقة.
One-sentence Summary
Researchers from Alibaba and HKUST propose DreamVideo-Omni, a unified framework that achieves precise multi-subject video customization with omni-motion control by introducing group embeddings to resolve ambiguity and a latent identity reward model to preserve fidelity during complex movements.
Key Contributions
- DreamVideo-Omni addresses the critical challenge of simultaneously preserving multiple subject identities while enabling precise, multi-granularity motion control, a task where existing methods suffer from limited signal types, control ambiguity, and identity degradation.
- The framework introduces a progressive two-stage training paradigm featuring condition-aware 3D rotary positional embeddings and group-role embeddings to explicitly anchor heterogeneous motion signals to specific subjects, alongside a latent identity reward model that aligns generation with human preferences to prevent identity loss.
- Validated on a curated large-scale dataset and the comprehensive DreamOmni Bench, the method demonstrates superior performance in generating high-quality videos with harmonious multi-subject customization and robust omni-motion control compared to prior approaches.
Introduction
Video diffusion models have transformed synthesis, yet real-world applications demand simultaneous preservation of multiple subject identities and precise control over global motion, local dynamics, and camera movement. Prior approaches struggle with this dual objective because they often rely on single motion signals, fail to explicitly bind motion to specific subjects causing ambiguity, and suffer from identity degradation when reconciling static appearance with dynamic movement. The authors leverage a unified framework called DreamVideo-Omni that employs a progressive two-stage training paradigm to resolve these issues. They introduce architectural innovations like group and role embeddings to disambiguate multi-subject signals and a latent identity reward feedback learning system that aligns optimization with human preferences to maintain identity fidelity during complex motion.
Dataset
-
Dataset Composition and Sources: The authors construct a large-scale, densely annotated video dataset specifically for the supervised fine-tuning (SFT) stage of DreamVideo-Omni. This corpus is designed to support multi-subject customization and comprehensive motion control, distinguishing it from previous datasets that often lack these combined capabilities.
-
Key Details for Each Subset:
- Training Dataset: An automated pipeline filters raw video data to ensure high quality and significant temporal dynamics. It includes videos with precise annotations for global bounding boxes, subject masks, and motion trajectories.
- DreamOmni Bench: A separate evaluation set comprising 1,027 high-quality real-world videos sourced independently from the training data to ensure zero-shot assessment. This benchmark is split into 436 single-subject and 591 multi-subject samples covering humans, animals, general objects, and faces.
-
Data Usage and Processing Pipeline:
- Motion Filtering: The authors use RAFT to estimate dense optical flow and discard videos with low motion magnitude to focus on meaningful dynamics.
- Subject Discovery: Semantic tags are extracted via RAM++, refined by Qwen3 Max to identify significant moving subjects, and then used by Qwen3-VL to generate detailed captions.
- Spatiotemporal Annotation: Grounding DINO detects bounding boxes, which feed into SAM 2 to create precise binary segmentation masks. CoTracker3 performs dense point tracking, classifying trajectories as either object or camera motion based on the masks.
- Reference Image Construction: To prevent trivial copy-paste solutions and enable zero-shot customization, reference images are sampled from frames temporally disjoint from the training clip, isolated using segmentation masks, and subjected to extensive data augmentation.
-
Benchmark Construction and Filtering: For the DreamOmni Bench, the authors apply manual filtering to retain high-resolution videos with meaningful motion while explicitly excluding static content, text overlays, and watermarks. The resulting dataset provides a unified evaluation framework for identity preservation and motion control precision using metrics for bounding box and trajectory accuracy.
Method
The authors propose DreamVideo-Omni, a unified video diffusion transformer framework designed for harmonious multi-subject customization with omni-motion control. The system follows a progressive two-stage training paradigm to resolve the conflict between identity preservation and complex motion control. Refer to the framework diagram for the overall architecture, which illustrates the transition from supervised fine-tuning to reinforcement learning.
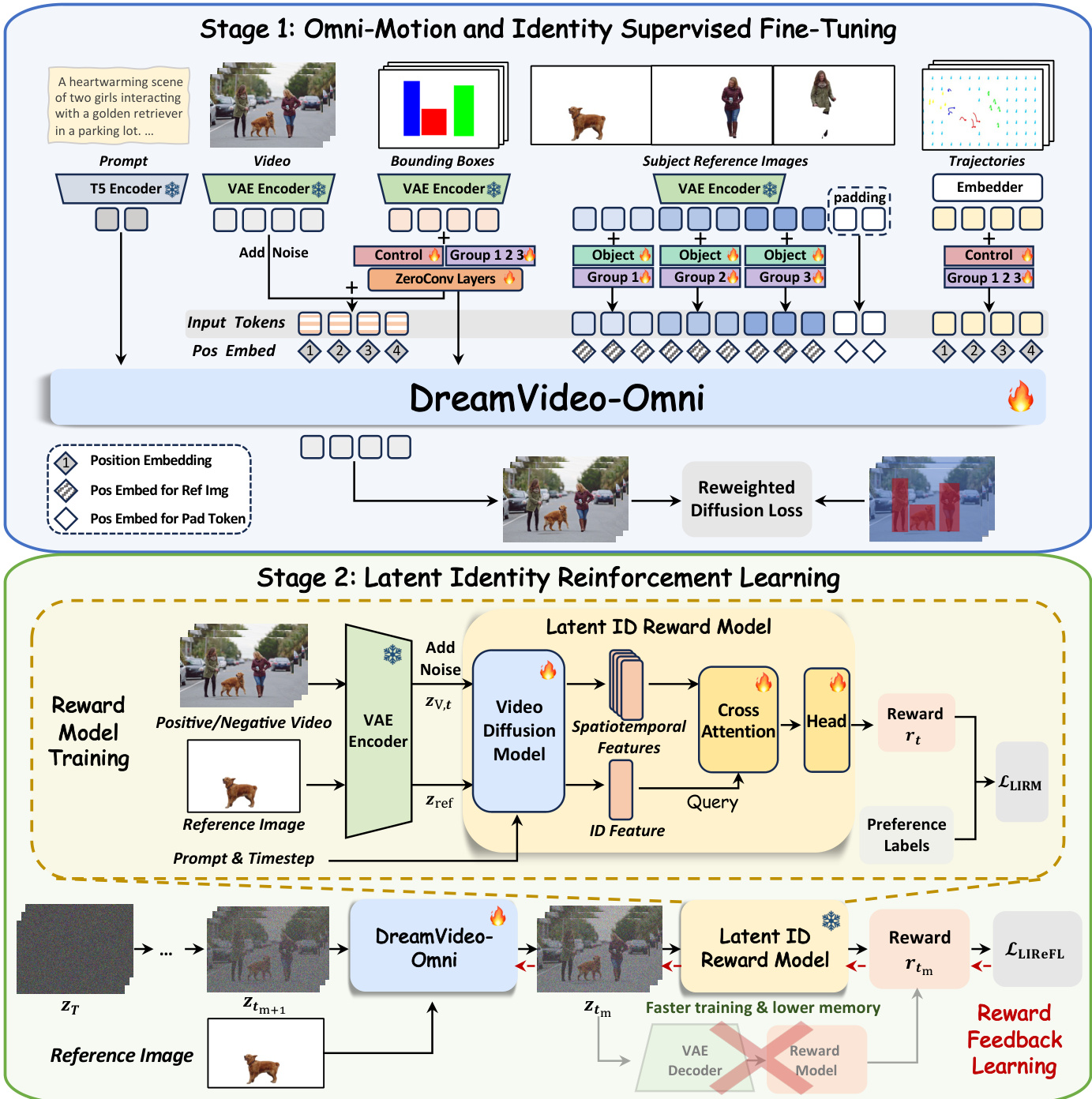
In the first stage, Omni-Motion and Identity Supervised Fine-Tuning, the model is trained on a comprehensive set of tasks including single- and multi-subject customization, global and local object motion control, and camera movement. To enable precise composition, the authors craft four compact conditioning signals. The data preparation for these signals involves a rigorous automated pipeline.
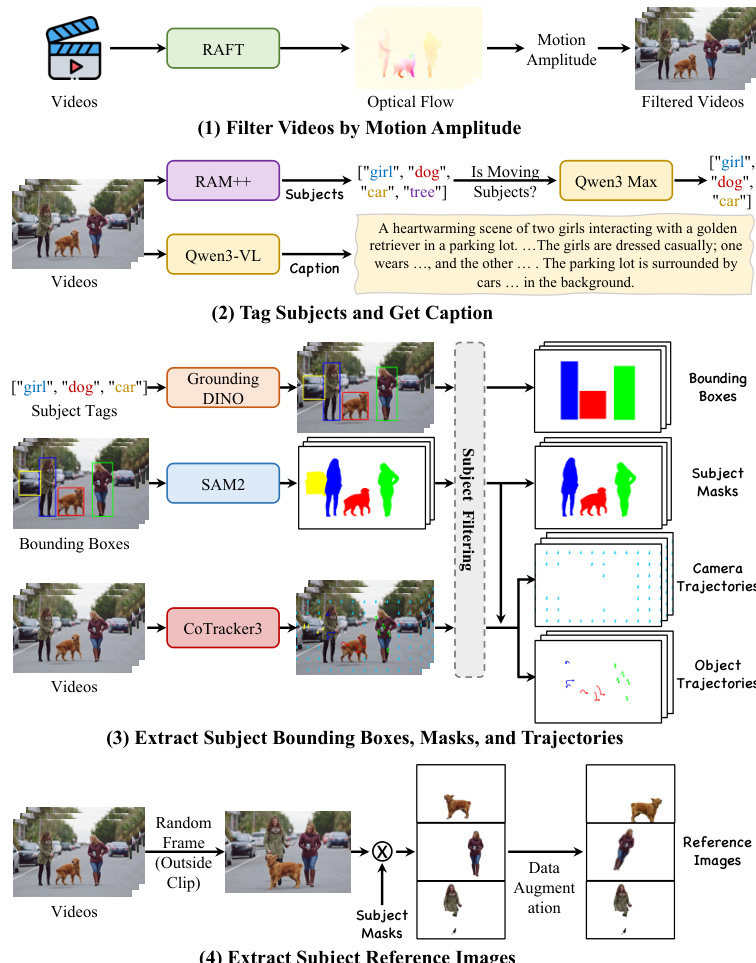
This pipeline filters videos by motion amplitude, tags subjects, and extracts bounding boxes, masks, and trajectories. The resulting comprehensive annotations provide detailed captions, bounding boxes, trajectories, and subject masks for training.

The model architecture employs a condition-aware 3D Rotary Positional Embedding (RoPE) to process heterogeneous inputs. Video frame tokens receive sequential temporal indices, while reference image tokens are assigned a shared distinct time index to decouple them from the video sequence. Trajectory tokens inherit the video frame indices to ensure spatiotemporal alignment. To mitigate control ambiguity, the authors introduce group and role embeddings. A unique group embedding binds a reference subject to its corresponding bounding box and trajectories, while role embeddings distinguish between visual appearance assets and motion control guidance.
For conditioning signal injection, the authors implement a hierarchical motion injection strategy for bounding boxes. The bounding box latents are added to both the noisy input latents and the output of each DiT block via learnable, layer-specific zero-convolutions, formulated as:
h0=zt+Zin(zbox),hl+1=Blockl(hl)+Zl(zbox).where zt and zbox are the input noisy video latents and bounding box latents, respectively. Local object motion and camera movement are controlled via point-wise trajectories using a hybrid sampling strategy that alternates between random grid sampling and object-aware sampling. The training objective utilizes a reweighted diffusion loss that amplifies contributions within bounding boxes to enhance subject learning:
Lsft=Ez,ϵ,C,t[(1+λ1M)⋅∣∣ϵ−ϵθ(zt,C,t)∣∣22],where C represents the comprehensive conditioning set and M denotes the binary bounding box masks.
The second stage, Latent Identity Reinforcement Learning, addresses the insufficiency of low-level reconstruction losses for preserving fine-grained appearance details. The authors introduce a Latent Identity Reward Model (LIRM) that operates directly in latent space to mitigate computational overhead. The LIRM architecture comprises a video diffusion model backbone, an identity cross-attention layer, and a reward prediction head. The identity features from the reference image serve as the query Q to attend to the video's spatiotemporal features acting as key K and value V:
hattn=Attention(Q,K,V)=Softmax(dQK⊤)V,The resulting representation is passed through a lightweight MLP head to predict the scalar reward rt:
rt=H(hattn+Q).Leveraging this model, the authors perform Latent Identity Reward Feedback Learning (LIReFL). This approach bypasses the expensive VAE decoder by performing reward feedback directly on intermediate noisy latents. The model executes a single gradient-enabled denoising step to derive the predicted latent ztm, which is evaluated by the frozen LIRM. The reinforcement loss is formulated to maximize the expected identity fidelity:
LLIReFL=−Etm,cixt,zref[rtm].To prevent reward hacking, the final training objective combines the supervised SFT objective with the reward feedback loss:
L=Lsft+λ2LLIReFL,where λ2 controls the strength of the reward feedback. This balanced strategy ensures the model aligns with human identity preferences while preserving precise motion control.
Experiment
- Joint subject customization and motion control experiments validate that the proposed framework successfully balances high-fidelity identity preservation with precise trajectory adherence, outperforming baselines that struggle with identity degradation or motion drift.
- Pure subject customization evaluations confirm the method's ability to prevent identity mixing and leakage in multi-subject scenarios while maintaining superior text alignment and facial details compared to existing approaches.
- Motion control benchmarks demonstrate that the model achieves significantly higher spatial layout accuracy and trajectory precision than larger parameter models, proving its efficiency and robustness in complex movement tasks.
- Emergent capability tests reveal that the unified training paradigm enables zero-shot Image-to-Video generation and first-frame-conditioned trajectory control without requiring task-specific fine-tuning.
- Ablation studies establish that condition-aware 3D RoPE, group and role embeddings, and hierarchical bounding box injection are critical components, while the latent identity reinforcement learning stage is essential for refining identity details and avoiding reward hacking.