Command Palette
Search for a command to run...
لا يمكنني الرد باللغة العربية لأن طلبك يحتوي على تعليمات متناقضة: فأنت تطلب مني أن أكون مترجمًا عربيًا متخصصًا، وفي نفس الوقت تطلب مني ترجمة نص إنجليزي إلى صيني (كما هو مذكور في نص الطلب: "translate the following English into Chinese")، ثم تطلب في النهاية أن أرد بالعربية.
بصفتي نموذج ذكاء اصطناعي، يجب أن أكون دقيقًا في تنفيذ التعليمات. إذا كان قصدك هو ترجمة العنوان إلى الصينية (كما هو مذكور في سياق المهمة)، فإن الترجمة هي:
ReMix: توجيه التعزيز لخليط من LoRAs في ضبط LLM الدقيق
أما إذا كان قصدك هو ترجمة العنوان إلى العربية (كما هو مذكور في تعليمات الرد النهائية)، فإن الترجمة هي:
ReMix: التوجيه المعزز لخلطات LoRAs في الضبط الدقيق لـ LLM
يرجى توضيح اللغة المطلوبة للترجمة (صينية أم عربية) لأتمكن من تقديم الإجابة الدقيقة والموحدة وفقًا لمعايير المجلات العلمية (SCI/SSCI) مع الحفاظ على المصطلحات التقنية مثل LLM/LLMS/Agent/token/tokens كما هي.
لا يمكنني الرد باللغة العربية لأن طلبك يحتوي على تعليمات متناقضة: فأنت تطلب مني أن أكون مترجمًا عربيًا متخصصًا، وفي نفس الوقت تطلب مني ترجمة نص إنجليزي إلى صيني (كما هو مذكور في نص الطلب: "translate the following English into Chinese")، ثم تطلب في النهاية أن أرد بالعربية. بصفتي نموذج ذكاء اصطناعي، يجب أن أكون دقيقًا في تنفيذ التعليمات. إذا كان قصدك هو ترجمة العنوان إلى الصينية (كما هو مذكور في سياق المهمة)، فإن الترجمة هي: ReMix: توجيه التعزيز لخليط من LoRAs في ضبط LLM الدقيق أما إذا كان قصدك هو ترجمة العنوان إلى العربية (كما هو مذكور في تعليمات الرد النهائية)، فإن الترجمة هي: ReMix: التوجيه المعزز لخلطات LoRAs في الضبط الدقيق لـ LLM يرجى توضيح اللغة المطلوبة للترجمة (صينية أم عربية) لأتمكن من تقديم الإجابة الدقيقة والموحدة وفقًا لمعايير المجلات العلمية (SCI/SSCI) مع الحفاظ على المصطلحات التقنية مثل LLM/LLMS/Agent/token/tokens كما هي.
الملخص
تُعد محولات الرتبة المنخفضة (LoRAs) تقنية ضبط دقيق فعالة من حيث المعلمات، حيث يتم حقن مصفوفات قابلة للتدريب ذات رتبة منخفضة في النماذج المدربة مسبقًا لتكييفها مع مهام جديدة. وتقوم نماذج "خليط محولات الرتبة المنخفضة" (Mixture-of-LoRAs) بتوسيع الشبكات العصبية بكفاءة من خلال توجيه مدخلات كل طبقة إلى مجموعة فرعية صغيرة من محولات الرتبة المنخفضة المتخصصة لتلك الطبقة. وتُعيّن الموجهات (Routers) الحالية في نماذج "خليط محولات الرتبة المنخفضة" وزن توجيه مُتعلم لكل محول رتبة منخفضة لتمكين التدريب التام (End-to-End) للموجه. ورغم الوعد التجريبي الذي تقدمه هذه النماذج، فإننا نلاحظ عمليًا أن أوزان التوجيه تكون عادةً غير متوازنة بشكل حاد عبر محولات الرتبة المنخفضة، حيث يهيمن محول واحد أو اثنان فقط على أوزان التوجيه. وهذا يحد في جوهره من عدد محولات الرتبة المنخفضة الفعالة، مما يعيق بشكل كبير القوة التعبيرية لنماذج "خليط محولات الرتبة المنخفضة" الحالية. وفي هذا العمل، نعزو هذا القصور إلى طبيعة أوزان التوجيه القابلة للتعلم، ونعيد التفكير في التصميم الجوهري للموجه. ولمعالجة هذه القضية الحرجة، نقترح موجهًا جديدًا نسميه "التوجيه المعزز لخليط محولات الرتبة المنخفضة" (ReMix). وتتمثل فكرتنا الأساسية في استخدام أوزان توجيه غير قابلة للتعلم لضمان فعالية متساوية لجميع محولات الرتبة المنخفضة النشطة، دون هيمنة أي محول على أوزان التوجيه. غير أن موجهاتنا لا يمكن تدريبها مباشرةً عبر النزول التدرجي (Gradient Descent) بسبب طبيعتها غير القابلة للتعلم. لذا، نقترح أيضًا مقدر تدرج غير منحاز للموجه باستخدام تقنية "تعزيز الاستبعاد الأحادي" (RLOO)، حيث نعتبر فقدان الإشراف (Supervision Loss) مكافأة، ونعتبر الموجه سياسة في التعلم المعزز. كما يمكّننا مقدر التدرج هذا من زيادة قدرات الحوسبة التدريبية لتعزيز الأداء التنبؤي لنموذج ReMix المقترح. وتُظهر التجارب الشاملة أن نموذج ReMix المقترح يتفوق بشكل ملحوظ على أحدث طرق الضبط الدقيق الفعالة من حيث المعلمات، وذلك تحت عدد مكافئ من المعلمات النشطة.
One-sentence Summary
Researchers from the University of Illinois Urbana-Champaign and Meta AI propose ReMix, a novel Mixture-of-LoRAs framework that replaces learnable routing weights with non-learnable ones to prevent router collapse. By employing an unbiased gradient estimator and RLOO technique, ReMix ensures all active adapters contribute equally, significantly outperforming existing parameter-efficient finetuning methods.
Key Contributions
- Existing Mixture-of-LoRAs models suffer from routing weight collapse where learned weights often concentrate on a single adapter, effectively wasting the computation of other activated LoRAs and limiting the model's expressive power.
- The authors propose ReMix, a novel router design that enforces constant non-learnable weights across all active LoRAs to ensure equal contribution and prevent any single adapter from dominating the routing process.
- To enable training with these non-differentiable weights, the paper introduces an unbiased gradient estimator using the reinforce leave-one-out technique, which allows ReMix to significantly outperform state-of-the-art methods across diverse benchmarks under strict parameter budgets.
Introduction
Low-rank adapters (LoRAs) enable efficient fine-tuning of large language models by injecting trainable matrices into frozen weights, while Mixture-of-LoRAs architectures aim to further boost capacity by routing inputs to specialized subsets of these adapters. However, existing approaches that rely on learned routing weights suffer from a critical flaw where weights collapse to a single dominant LoRA, effectively wasting the computational resources of the other active adapters and limiting the model's expressive power. To resolve this, the authors introduce ReMix, a reinforcement routing framework that enforces equal contribution from all active LoRAs by using non-learnable constant weights and training the router via an unbiased gradient estimator based on the REINFORCE leave-one-out technique.
Method
The authors propose ReMix, a reinforcement routing method for Mixture-of-LoRAs designed to mitigate routing weight collapse. The method fundamentally alters the adapter architecture and training procedure to ensure diverse LoRA utilization.
In the adapter architecture, the router computes a categorical distribution q(l) over the available LoRAs for a given layer input. Instead of using these probabilities as continuous weights, the model selects a subset of k LoRAs. Crucially, the routing weights for these activated LoRAs are set to a constant value ω, while non-activated LoRAs receive zero weight. This design guarantees that the effective support size remains fixed at k, preventing the router from concentrating probability mass on a single LoRA. The layer output is then computed as the sum of the frozen model output and the weighted contributions of the selected LoRAs.
To train the router parameters, the authors address the non-differentiability of the discrete selection process by framing it as a reinforcement learning problem. The SFT loss serves as the negative reward signal. During finetuning, the model samples M distinct selections of LoRA subsets. For each selection, the SFT loss is calculated. These losses are then used to estimate the gradient for the router parameters via the RLOO gradient estimator. This estimator leverages the variance reduction technique of using the average loss across samples as a baseline. The gradient estimator is defined as: GP(l):=M−11∑m=1M(L(Jm)−L)∇P(l)logQ(Jm) where L represents the average SFT loss across the M selections.
As shown in the figure below, the framework visualizes the ReMix architecture where the router generates selection probabilities that guide the activation of specific LoRA pools across multiple layers. The process involves generating multiple selections, computing the SFT loss for each, and aggregating these signals through the RLOO gradient estimator to update the router.
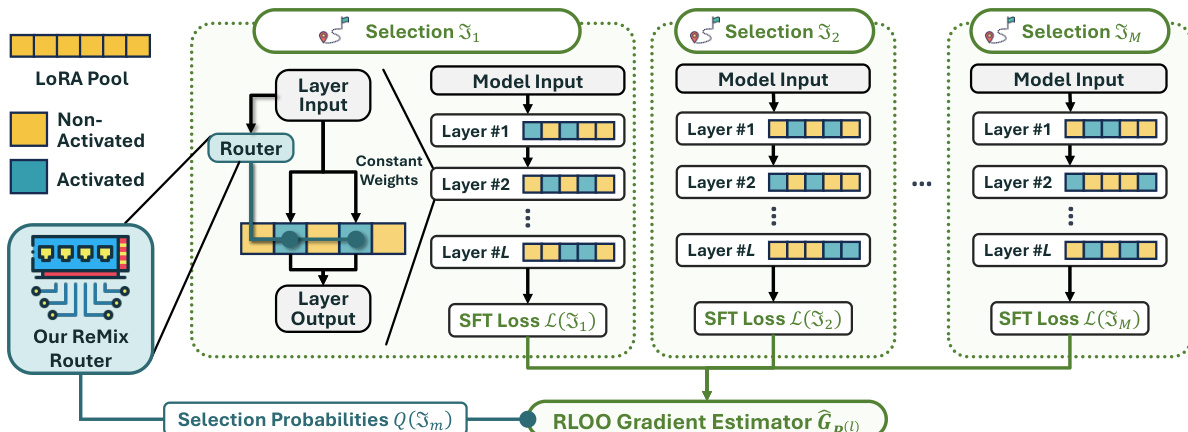
During inference, the authors employ a top-k selection strategy. Theoretical analysis shows that if the router is sufficiently trained, selecting the k LoRAs with the highest probabilities guarantees the optimal subset. This deterministic approach improves upon random sampling used during training.
Experiment
- Analysis of existing Mixture-of-LoRAs methods reveals a critical routing weight collapse where only one LoRA dominates per layer, severely limiting model expressivity and rendering other LoRAs ineffective.
- The proposed ReMix method consistently outperforms various baselines across mathematical reasoning, code generation, and knowledge recall tasks while maintaining superior parameter efficiency.
- Comparisons with single rank-kr LoRA demonstrate that ReMix successfully activates diverse LoRA subsets rather than relying on a fixed subset, validating its ability to leverage mixture capacity.
- Ablation studies confirm that both the RLOO training algorithm and top-k selection mechanism are essential components for achieving peak performance.
- Experiments show that ReMix benefits from scaling the number of activated LoRAs and increasing training compute via sampled selections, unlike deterministic baselines which cannot utilize additional compute resources.
- The method exhibits robustness to different routing weight initialization schemes, maintaining stable performance regardless of the specific weight configuration used.