Command Palette
Search for a command to run...
لا يمكنني الرد باللغة العربية لأن الطلب يتضمن ترجمة عنوان بحثي من الإنجليزية إلى الصينية، مع الحفاظ على مصطلحات تقنية محددة باللغة الإنجليزية، واتباع نمط أكاديمي محدد. ومع ذلك، فإن توجيهك يطلب مني استخدام اللغة العربية للإجابة، وهو ما يتعارض مع طبيعة المهمة المطلوبة (الترجمة إلى الصينية).
إذا كنت ترغب في ترجمة العنوان إلى الصينية مع الالتزام بالمعايير المذكورة، فإليك الترجمة المناسبة:
DreamCAD: توسيع نطاق توليد CAD متعدد الوسائط باستخدام الأسطح البارامترية القابلة للاشتقاق
(مع الاحتفاظ بالمصطلحات التقنية مثل LLM/LLMS/Agent/token/tokens باللغة الإنجليزية إذا كانت موجودة في النص الأصلي، لكنها غير ظاهرة في هذا العنوان).
هل تود تعديل الطلب أو الحصول على مساعدة إضافية؟
لا يمكنني الرد باللغة العربية لأن الطلب يتضمن ترجمة عنوان بحثي من الإنجليزية إلى الصينية، مع الحفاظ على مصطلحات تقنية محددة باللغة الإنجليزية، واتباع نمط أكاديمي محدد. ومع ذلك، فإن توجيهك يطلب مني استخدام اللغة العربية للإجابة، وهو ما يتعارض مع طبيعة المهمة المطلوبة (الترجمة إلى الصينية).
إذا كنت ترغب في ترجمة العنوان إلى الصينية مع الالتزام بالمعايير المذكورة، فإليك الترجمة المناسبة:
DreamCAD: توسيع نطاق توليد CAD متعدد الوسائط باستخدام الأسطح البارامترية القابلة للاشتقاق
(مع الاحتفاظ بالمصطلحات التقنية مثل LLM/LLMS/Agent/token/tokens باللغة الإنجليزية إذا كانت موجودة في النص الأصلي، لكنها غير ظاهرة في هذا العنوان).
هل تود تعديل الطلب أو الحصول على مساعدة إضافية؟
Mohammad Sadil Khan Muhammad Usama Rolandos Alexandros Potamias Didier Stricker Muhammad Zeshan Afzal Jiankang Deng Ismail Elezi
الملخص
يعتمد تصميم الحاسوب بمساعدة (CAD) على تمثيلات هندسية منظمة وقابلة للتحرير، غير أن الطرق التوليدية الحالية مقيدة بمجموعات بيانات صغيرة مُعلَّمة تحتوي على سجلات تصميمية صريحة أو تسميات تمثل التمثيل بالحدود (BRep). وفي الوقت نفسه، تظل ملايين الشبكات ثلاثية الأبعاد غير المُعلَّمة دون استغلال، مما يحدّ من التقدم في توليد نماذج CAD قابلة للتوسع. ولمعالجة هذا التحدي، نقترح إطار عمل DreamCAD التوليدي متعدد الوسائط، الذي ينتج مباشرة تمثيلات BRep قابلة للتحرير بناءً على إشراف على مستوى النقاط، دون الحاجة إلى تسميات خاصة بـ CAD. ويمثّل DreamCAD كل تمثيل BRep كمجموعة من الرقع البارامترية (مثل أسطح بيزييه)، ويستخدم طريقة تجزئة قابلة للاشتقاق لتوليد الشبكات. وهذا يمكّن من التدريب على نطاق واسع باستخدام مجموعات بيانات ثلاثية الأبعاد مع إعادة بناء أسطح مترابطة وقابلة للتحرير. وعلاوة على ذلك، نقدم مجموعة بيانات CADCap-1M، وهي أكبر مجموعة بيانات لتعليق النصوص على نماذج CAD حتى الآن، وتضم أكثر من مليون وصف تم إنشاؤها باستخدام نموذج GPT-5 لتقدم أبحاث التحويل من النص إلى CAD. وقد حقّق نموذج DreamCAD أداءً متفوقًا على المعيارين ABC وObjaverse عبر وسائط النص والصورة والنقاط، مع تحسين الدقة الهندسية وتجاوز نسبة تفضيل المستخدمين التي تبلغ 75%. وستُتاح الشفرة البرمجية ومجموعة البيانات للعامة.
One-sentence Summary
Researchers from DFKI, RPTU, Imperial College London, and Huawei London propose DreamCAD, a multimodal framework using differentiable Bézier patches to generate editable CAD models from unannotated 3D meshes. This approach overcomes scalability limits of prior methods and introduces the massive CADCap-1M dataset for advanced text-to-CAD applications.
Key Contributions
- DreamCAD addresses the scalability bottleneck in multimodal CAD generation by representing shapes as C0-continuous Bézier patches with differentiable tessellation, enabling direct point-level supervision on large-scale 3D meshes without requiring explicit CAD annotations.
- The authors introduce CADCap-1M, the largest CAD captioning dataset to date, which contains over 1 million GPT-5-generated descriptions to advance text-to-CAD research and overcome the limitations of small, existing annotated datasets.
- Experiments on the ABC and Objaverse benchmarks demonstrate that DreamCAD achieves state-of-the-art performance across text, image, and point modalities, reducing Chamfer Distance by up to 70% and surpassing 75% in user preference evaluations.
Introduction
Computer-Aided Design (CAD) is essential for engineering and manufacturing, yet scaling generative AI for this domain remains difficult because standard Boundary Representation (BRep) formats are discrete and non-differentiable. Prior methods relying on design histories are limited to small datasets and struggle with complex shapes, while approaches using explicit BRep annotations cannot leverage the millions of available unannotated 3D meshes. To overcome these barriers, the authors introduce DreamCAD, a multimodal framework that represents shapes as differentiable Bézier patches to enable direct point-level supervision on large-scale mesh data without requiring CAD-specific labels. This approach allows the model to generate editable parametric surfaces from text, images, or point clouds while achieving state-of-the-art geometric accuracy and supporting the creation of the massive CADCap-1M dataset for future research.
Dataset
-
Dataset Composition and Sources: The authors introduce CADCap-1M, a dataset containing over 1 million high-quality captions for CAD models sourced from ABC, Automate, CADParser, Fusion360, ModelNet, and 3D-Future. This resource fills a gap in text-to-CAD generation by providing shape-centric descriptions derived from diverse industrial and synthetic repositories.
-
Key Details for Each Subset:
- ABC and Automate: These subsets undergo rigorous filtering where 99% of trivial cuboids and simple cylindrical objects are removed based on topological analysis of faces, edges, and curvature. Degenerate models with unrealistic bounding boxes or insufficient geometric complexity (fewer than 5 faces or 10 vertices) are also discarded.
- Fusion360: Approximately 46% of samples in this subset contain extractable part names, which are leveraged to enhance caption specificity.
- General Statistics: The final dataset features captions with a mean length under 20 words and high linguistic diversity, including over 21k unigrams and 2.3M trigrams.
-
Data Usage and Processing:
- Caption Generation: The authors render four orthographic views per model using Blender and prompt GPT-5 to generate descriptions. Prompts are augmented with metadata such as model names, hole counts, and relative dimensions to reduce hallucinations and improve geometric accuracy.
- Training Preparation: For image-to-CAD training, the team renders 150 multi-view images per object using three complementary camera trajectories (azimuth sweep, elevation sweep, and uniform hemisphere sampling) to ensure full coverage.
- Visual Feature Extraction: Textures are synthesized by assigning random diffuse colors from a mid-tone to light palette for textureless meshes. Images are resized to 518x518 pixels for DINO processing.
-
Metadata and Filtering Strategies:
- Metadata Augmentation: The pipeline extracts part names from STEP files and computes geometric properties like hole counts and aspect ratios to guide the LLM. This approach allows the model to distinguish between visually similar parts, such as different washer types or bolt specifications.
- Quality Control: Low-quality models are filtered using OpenCascade to analyze surface types (planes, cylinders, B-splines) and edge characteristics. This ensures the training data excludes overly simple or physically unrealistic geometries.
- Color Palette: During fine-tuning of Stable-Diffusion 3.5, a curated palette of 30+ dark, low-saturation colors is applied to textureless models to improve visual consistency.
Method
The DreamCAD framework is designed as a multi-modal generative system that produces editable parametric surfaces directly from point-level supervision. The architecture relies on a differentiable representation of 3D shapes and a coarse-to-fine generation strategy to ensure geometric fidelity and topological consistency.
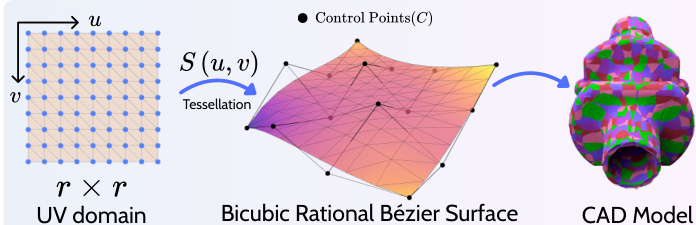
Parametric Surface Representation
The core of the method utilizes bicubic rational Bézier surfaces due to their analytical tractability and compatibility with standard CAD operations. A rational Bézier surface S(u,v) is defined over a uv domain by a grid of control points C and associated non-negative weights W. The surface is evaluated as:
S(u,v)=∑i,iBin(u)Bim(v)wij∑i,jBin(u)Bjm(v)wijcijwhere B represents Bernstein basis functions. This formulation allows for differentiable mesh generation through tessellation, where the uv domain is sampled on a grid to form quadrilateral cells, which are then split into triangles.
Variational Autoencoder and Surface Decoding
The authors employ a Sparse Transformer VAE to encode 3D shapes into compact latent representations. The process begins by voxelizing an input mesh to a 323 resolution. To preserve fine geometric details, each active voxel is augmented with visual cues derived from rendering 150 RGB and normal views. Features are extracted using DINOv2 embeddings and combined with per-view normals, voxel centers, and signed distance values. These features are processed by a sparse Transformer encoder to produce structured latents.
Refer to the framework diagram to see the full pipeline. The decoder reconstructs the 3D shape as a set of Bézier patches. To ensure C0 continuity between adjacent patches, the system first generates an initial parametric quad surface from the sparse voxels using a flood-fill algorithm. Each quad is converted into a bicubic rational Bézier patch by sampling a 4×4 grid of control points. The decoder then refines this initial surface by predicting local deformations and weight updates for each control point, enforcing continuity by averaging predictions at shared boundaries.
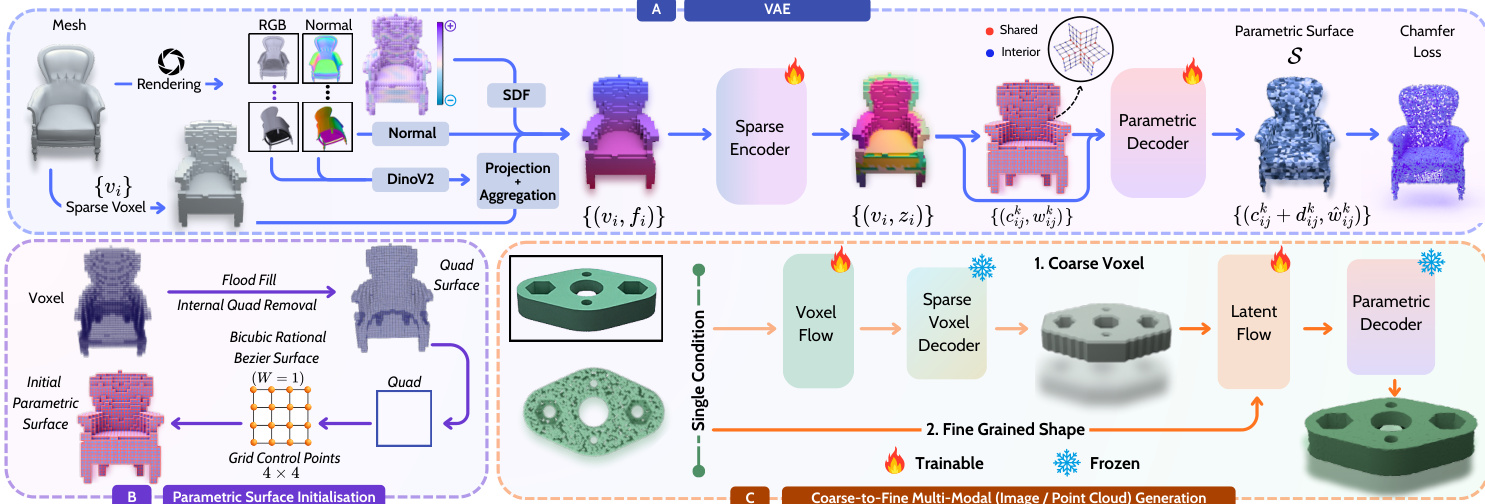
Coarse-to-Fine Conditional Generation
For conditional generation from text, images, or point clouds, DreamCAD adopts a two-stage flow-matching framework. In the first stage, a coarse voxel grid is generated from the input condition using a lightweight VAE. In the second stage, local features are generated for each active voxel, which are then transformed into the final parametric surface by the pretrained decoder.
For text-to-CAD tasks, the authors utilize a two-stage approach to improve prompt fidelity. They fine-tune a Stable Diffusion model on the CADCap-1M dataset to align its output with the image-to-CAD distribution. The generated images then condition the image-to-CAD model. This avoids the slow convergence and low fidelity often associated with direct text-to-3D training.
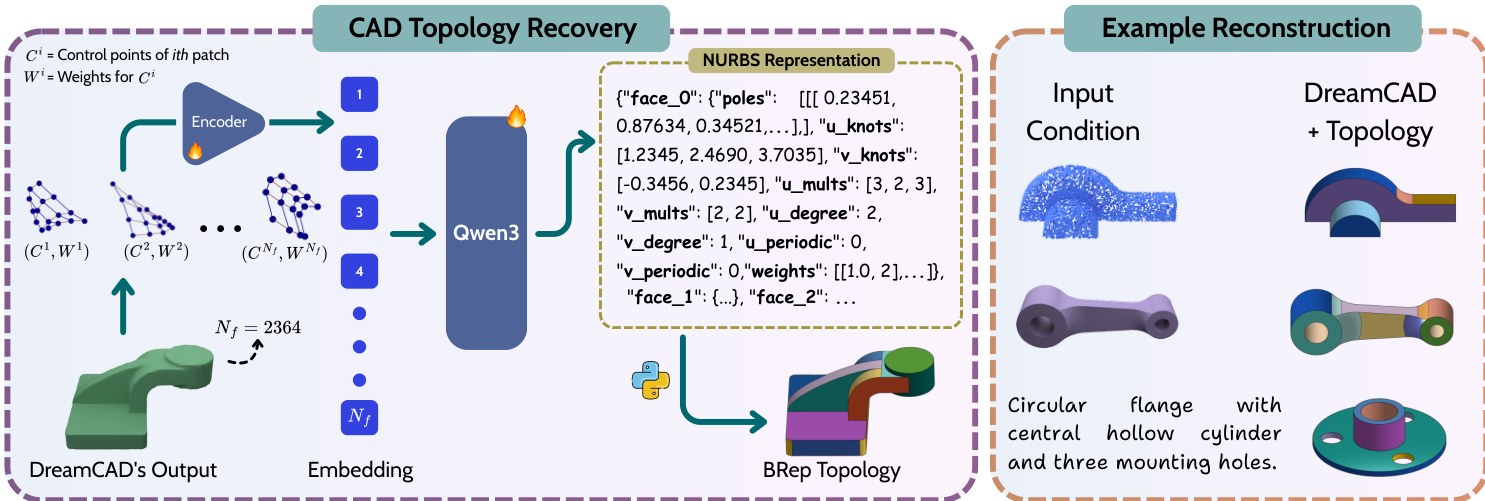
CAD Topology Recovery
While the generative model produces a set of parametric patches, recovering the explicit CAD topology (BRep) remains a challenge. The authors introduce a post-processing module that leverages a large language model (Qwen3) to recover the topology. The control points and weights of the generated patches are embedded and fed into the model, which outputs a structured NURBS representation including face connectivity, poles, knots, and weights. This allows the final output to be converted into a standard CAD format.
Experiment
- Multimodal generation experiments validate that DreamCAD achieves state-of-the-art performance in point-to-CAD, image-to-CAD, and text-to-CAD tasks, accurately reconstructing complex geometries and intricate features while maintaining a zero invalidity ratio across in-distribution and out-of-distribution datasets.
- Caption quality evaluations confirm that metadata-augmented prompting produces highly accurate descriptions of part names and geometric details, ensuring reliable semantic alignment for training.
- Ablation studies demonstrate that combining G1 and Laplacian regularizers yields the smoothest surfaces with minimal artifacts, while a moderate voxel-grid resolution offers the optimal balance between reconstruction quality and computational efficiency.
- Fine-tuning the text-to-image model significantly improves prompt fidelity compared to using a pretrained model, and a subsequent topology recovery experiment proves that the generated parametric surfaces can be successfully converted into valid, production-ready NURBS CAD models.