Command Palette
Search for a command to run...
DARE: محاذاة وكلاء LLM مع النظام البيئي الإحصائي R عبر الاسترجاع الواعي للتوزيعات
DARE: محاذاة وكلاء LLM مع النظام البيئي الإحصائي R عبر الاسترجاع الواعي للتوزيعات
Maojun Sun Yue Wu Yifei Xie Ruijian Han Binyan Jiang Defeng Sun Yancheng Yuan Jian Huang
الملخص
يمكن لوكلاء نماذج اللغة الكبيرة (LLM) أتمتة سير عمل علم البيانات، غير أن العديد من الأساليب الإحصائية الصارمة المُطبَّقة في لغة R لا تزال غير مستخدمة على نطاق واسع، وذلك لأن نماذج اللغة الكبيرة تواجه صعوبات في استيعاب المعرفة الإحصائية واسترجاع الأدوات المناسبة. وتركز النهوج الحالية المعززة بالاسترجاع على الدلالات على مستوى الدالة، متجاهلةً توزيع البيانات، مما يُنتج مطابقات دون المستوى الأمثل. ونقترح في هذا البحث نموذج DARE (تمثيل الاسترجاع الواعي بالتوزيع)، وهو نموذج استرجاع خفيف الوزن وقابل للتشغيل الفوري، يدمج معلومات توزيع البيانات في تمثيلات الدوال لاسترجاع حزم R. وتتمثل إسهاماتنا الرئيسية في: (i) RPKB، وهي قاعدة معرفة مُحرَّرة لحزم R مُشتقَّة من 8,191 حزمة عالية الجودة من مستودع CRAN؛ (ii) نموذج DARE، وهو نموذج تضمين يدمج السمات المستندة إلى التوزيع مع元بيانات الدالة لتحسين صلة الاسترجاع؛ و(iii) RCodingAgent، وهو وكيل موجه نحو R مُصمَّم لتوليد كود R موثوق، إلى جانب مجموعة من مهام التحليل الإحصائي لتقييم منهجي لوكلاء نماذج اللغة الكبيرة في سيناريوهات تحليلية واقعية. وعلى الصعيد التجريبي، يحقق نموذج DARE قيمة NDCG@10 تبلغ 93.47%، متفوقًا على نماذج التضمين مفتوحة المصدر الأكثر تقدمًا بنسبة تصل إلى 17% في مهمة استرجاع الحزم، مع استخدام عدد أقل بشكل ملحوظ من المعاملات. كما يُفضي دمج نموذج DARE في RCodingAgent إلى مكاسب كبيرة في مهام التحليل اللاحقة. وتساهم هذه الدراسة في تضييق الفجوة بين أتمتة نماذج اللغة الكبيرة والنظام البيئي الإحصائي الناضج في لغة R.
One-sentence Summary
Researchers from multiple institutions propose DARE, a lightweight retrieval model that uniquely integrates data distribution features with function metadata to enhance R package search. This approach significantly outperforms existing methods and powers RCodingAgent, bridging the gap between LLM automation and the mature R statistical ecosystem.
Key Contributions
- LLM agents often fail to utilize rigorous R statistical methods because existing retrieval approaches ignore data distribution characteristics, leading to suboptimal tool matches and code generation errors.
- The authors introduce DARE, a lightweight embedding model that fuses data distribution features with function metadata to improve retrieval relevance, alongside RPKB, a curated knowledge base of 8,191 high-quality CRAN packages.
- Empirical results show DARE achieves an NDCG@10 of 93.47%, outperforming state-of-the-art models by up to 17% on package retrieval, while integration into the RCodingAgent boosts downstream analysis task performance by up to 56.25%.
Introduction
Large Language Model agents are increasingly used to automate data science workflows, yet they struggle to leverage the rigorous statistical methods available in the R ecosystem due to training data biases toward Python and a lack of understanding regarding statistical tool compatibility. Prior retrieval-augmented approaches fail because they rely solely on semantic similarity between queries and function descriptions, ignoring critical data distribution characteristics such as sparsity or dimensionality that determine whether a statistical method is applicable. To address this, the authors introduce DARE, a lightweight retrieval model that fuses data distribution features with function metadata to improve R package selection, alongside the RPKB knowledge base and the RCodingAgent framework for end-to-end statistical analysis.
Dataset
-
Dataset Composition and Sources The authors constructed a specialized knowledge base called RPKB by curating R packages from the Comprehensive R Archive Network (CRAN). The final repository contains 8,191 high-quality R functions indexed in ChromaDB, focusing strictly on core statistical primitives and computational algorithms while excluding generic utility functions or those with vague descriptions.
-
Key Details for Each Subset The dataset is organized at the function level and enriched with synthesized metadata. Each entry includes granular details such as function descriptions, usage, arguments, and return values. Crucially, the authors used an LLM to generate a "data profile" for every function, inferring attributes like data modality, distribution assumptions, dimensionality, and specific constraints (e.g., handling missing values or data types).
-
Model Usage and Training Strategy The authors utilize this corpus to train a semantic search engine for statistical programming. They employed a data augmentation strategy where an LLM generated 30 diverse user-style search queries for each function. These prompts were designed to describe data problems and constraints without revealing the function or package names, ensuring the model learns to retrieve tools based on analytical intent rather than keyword matching.
-
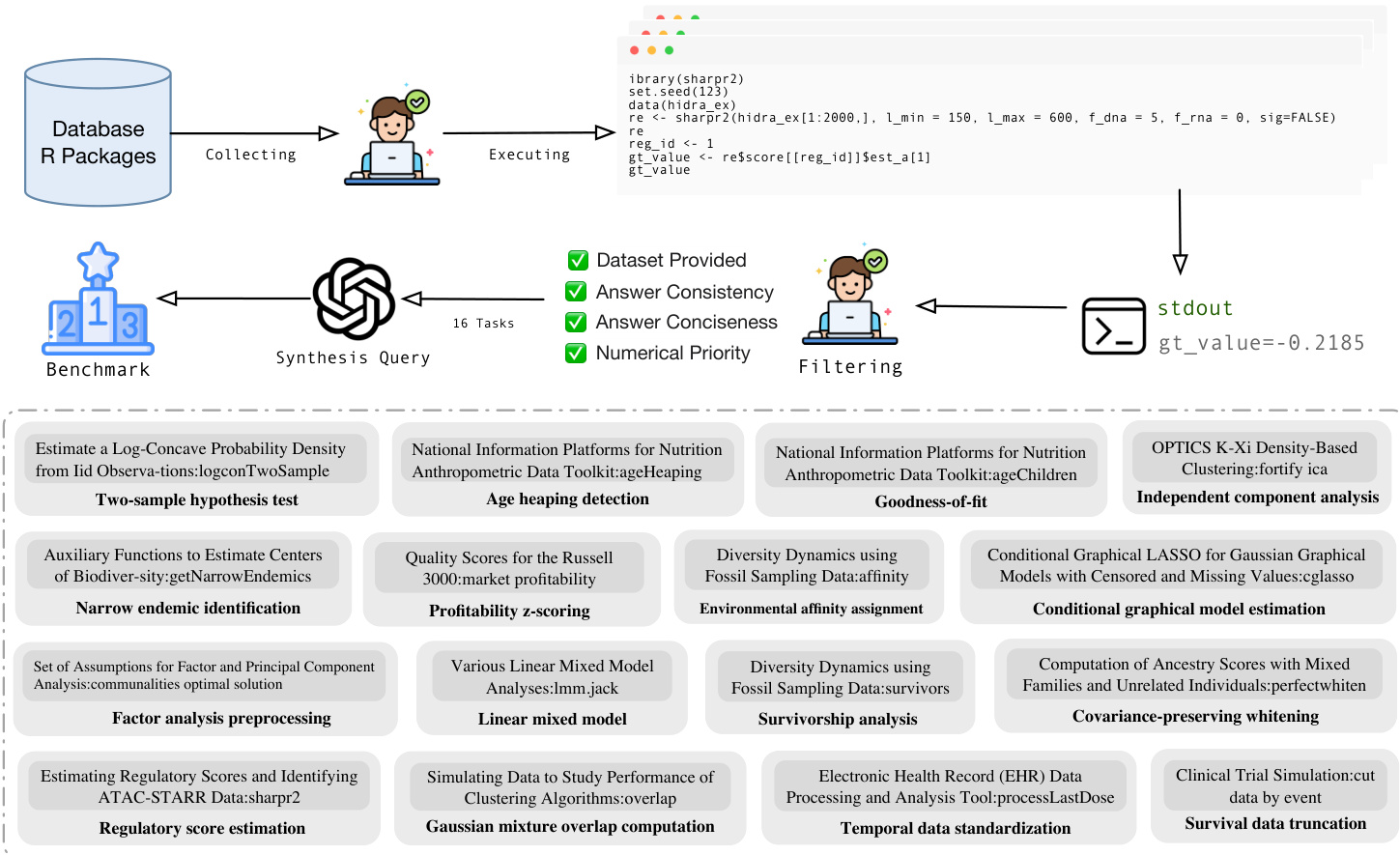
Processing and Evaluation Framework For evaluation, the team created a benchmark of 16 representative statistical analysis tasks covering domains like hypothesis testing and survival analysis. They extracted real R scripts from the repository, executed them to verify ground-truth outputs, and then prompted LLMs to generate natural language queries paired with these verified results. The evaluation queries enforce strict constraints, such as requiring a specific random seed and mandating the printing of a specific ground-truth metric to ensure reproducibility and accurate assessment of agent performance.
Method
The proposed framework, DARE, addresses the limitations of standard semantic retrieval by incorporating structured data profiles alongside natural language descriptions. As illustrated in the framework diagram, the system contrasts with traditional approaches that rely solely on function descriptions. Instead, DARE conditions the retrieval process on both the user's natural language query and a structured data profile derived from the dataset characteristics.
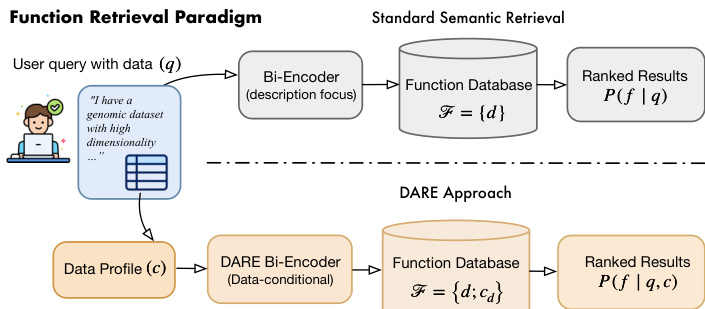
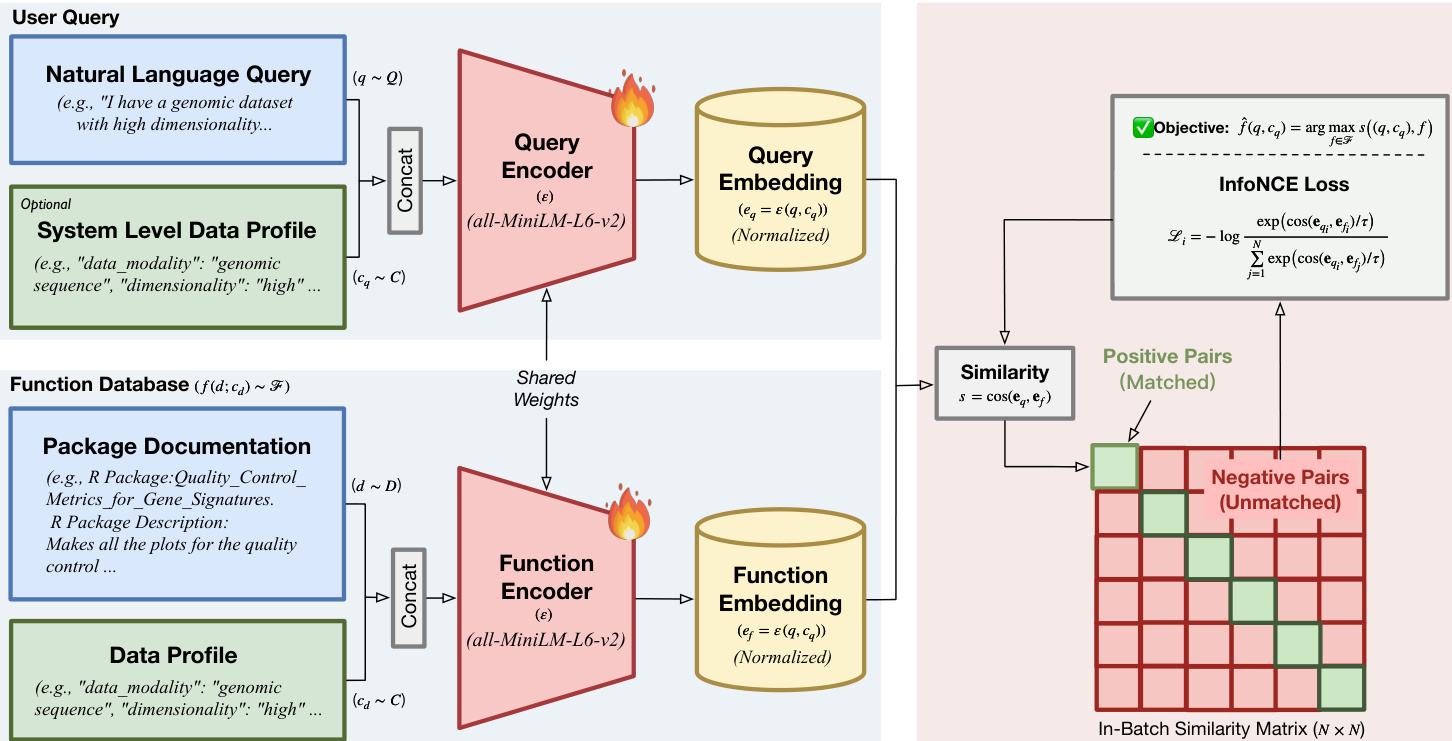
The core of the method utilizes a bi-encoder architecture with shared weights, initialized from a pre-trained sentence transformer. The authors define the shared encoder network as ε(⋅), which maps input texts into a shared vector space. For the query side, the system concatenates the natural language request q with the query-side data profile cq to generate a query embedding eq=ε([q;cq]). Similarly, for the function database, each candidate function is represented by its documentation d and its inherent data profile cd, resulting in a function embedding ef=ε([d;cd]). The relevance score is computed using cosine similarity between these representations:
s(eq,ef)=cos(eq,ef)=∥eq∥2∥ef∥2eq⊤ef.This factorization enables efficient retrieval via Maximum Inner Product Search over precomputed function embeddings. To train the model, the authors employ the InfoNCE objective with in-batch negatives. Given a mini-batch of size N, the loss function for the i-th sample treats the paired function as the positive sample and all other functions in the batch as negatives:
Li=−logj=1∑Nexp(cos(eqi,efj)/τ)exp(cos(eqi,efi)/τ),where τ is a learnable temperature parameter. As shown in the figure below, this process involves encoding both user queries and function documentation into embeddings, calculating an in-batch similarity matrix, and optimizing the objective to maximize similarity for matched pairs while minimizing it for unmatched pairs.
To facilitate end-to-end statistical analysis, the retrieval module is integrated into an LLM-based agent named RCodingAgent. The agent operates by first invoking DARE to retrieve candidate R packages and functions that satisfy both analytical intent and data compatibility constraints. The retrieved functions are returned with structured metadata, including argument specifications and usage examples, which are injected into the LLM context. This enables the agent to perform iterative reasoning, tool retrieval, and R code generation. The workflow demonstrates how the agent processes a user query, retrieves the top relevant functions, and executes coding steps to produce final observations.

The system is evaluated using a benchmark pipeline that collects R packages and synthesizes queries to test retrieval and execution capabilities. The pipeline involves collecting functions from a database, executing code to generate ground truth outputs, and filtering results based on criteria such as dataset provision, answer consistency, and numerical priority. The benchmark covers a diverse range of statistical tasks, including hypothesis testing, density estimation, and data transformation, ensuring comprehensive evaluation of the retrieval system's ability to handle complex data science workflows.
Experiment
- Synthetic query generation and retrieval benchmarking validate that DARE achieves state-of-the-art performance in identifying and ranking statistical functions, significantly outperforming larger general-purpose embedding models by effectively distinguishing between statistically similar yet distributionally distinct tools.
- Efficiency analysis demonstrates that DARE delivers superior throughput and ultra-low latency compared to heavy baselines, confirming its suitability for real-time agentic workflows where rapid tool retrieval is critical.
- Integration experiments across diverse LLM agents on statistical analysis tasks reveal that DARE substantially improves end-to-end success rates, effectively bridging the gap in tool utilization for both lightweight and frontier models by providing precise, distribution-aware retrieval signals.