Command Palette
Search for a command to run...
هيليو: نموذج توليد فيديو طويل في الوقت الفعلي الحقيقي
هيليو: نموذج توليد فيديو طويل في الوقت الفعلي الحقيقي
Shenghai Yuan Yuanyang Yin Zongjian Li Xinwei Huang Xiao Yang Li Yuan
الملخص
نقدم هيلوس (Helios)، وهو أول نموذج لتوليد الفيديو بسعة 14 مليار معلمة، يعمل بسرعة 19.5 إطارًا في الثانية على وحدة معالجة رسومات NVIDIA H100 واحدة، ويدعم التوليد على مدى دقائق مع الحفاظ على جودة تضاهي أفضل النماذج المرجعية القوية. حقّقنا اختراقات في ثلاثة أبعاد رئيسية: (1) متانة عالية تجاه انحراف الفيديو الطويل دون اللجوء إلى الاستدلالات المضادة للانحراف الشائعة مثل «الإجبار الذاتي» (self-forcing)، أو «مخازن الأخطاء» (error-banks)، أو أخذ عينات من الإطارات الرئيسية؛ (2) توليد في الوقت الفعلي دون استخدام تقنيات التسريع القياسية مثل ذاكرة التخزين المؤقت للمفاتيح والقيم (KV-cache)، أو الانتباه المتفرّع/الخطّي (sparse/linear attention)، أو التكميم (quantization)؛ و(3) تدريب دون الحاجة إلى أطر التوازي أو التجزئة (sharding)، مما يتيح أحجام دفع (batch sizes) قابلة للمقارنة مع نماذج الانتشار للصور، مع إمكانية استيعاب ما يصل إلى أربعة نماذج بسعة 14 مليار معلمة ضمن 80 جيجابايت من ذاكرة وحدة المعالجة الرسومية.على وجه التحديد، يُعد هيلوس نموذج انتشار ذاتي الارتجاع (autoregressive diffusion) بسعة 14 مليار معلمة، يعتمد تمثيلًا موحدًا للإدخال يدعم بشكل أصلي مهام تحويل النص إلى فيديو (T2V)، وتحويل الصورة إلى فيديو (I2V)، وتحويل الفيديو إلى فيديو (V2V). وللتخفيف من ظاهرة الانحراف في توليد الفيديوهات الطويلة، قمنا بتوصيف أنماط الفشل النموذجية، واقترحنا استراتيجيات تدريب بسيطة وفعّالة تحاكي الانحراف صراحةً أثناء التدريب، مع القضاء على الحركة المتكررة من مصدرها.أما فيما يتعلق بالكفاءة، فقد قمنا بضغط مكثف للسياق التاريخي والضوضائي، مع تقليل عدد خطوات أخذ العينات، ما أفضى إلى تكاليف حاسوبية قابلة للمقارنة مع — أو أقل من — تكاليف نماذج توليد الفيديو بسعة 1.3 مليار معلمة. علاوة على ذلك، قدّمنا تحسينات على مستوى البنية التحتية تُسرّع الاستدلال والتدريب مع تقليل استهلاك الذاكرة. وتُظهر التجارب الشاملة أن هيلوس يتفوق باستمرار على الأساليب السابقة في توليد الفيديوهات القصيرة والطويلة على حد سواء. ونخطط لإطلاق الكود المصدري، والنموذج الأساسي، والنموذج المُختزل (distilled model) لدعم التطوير الإضافي من قبل المجتمع العلمي.
One-sentence Summary
Researchers from Peking University and ByteDance introduce Helios, a 14B autoregressive diffusion model that achieves real-time, minute-scale video generation without standard acceleration heuristics. By simulating drifting during training and compressing context, it outperforms prior methods while fitting multiple models on limited GPU memory.
Key Contributions
- Helios addresses the challenge of real-time, minute-scale video generation by eliminating common anti-drifting heuristics like self-forcing and error-banks through training strategies that explicitly simulate drifting and resolve repetitive motion at its source.
- The model achieves real-time speeds of 19.5 FPS on a single NVIDIA H100 GPU without standard acceleration techniques by compressing historical context and reformulating flow matching to reduce computational costs to levels comparable to 1.3B models.
- Extensive experiments show that Helios consistently outperforms prior methods on both short and long videos while enabling training without parallelism frameworks and fitting up to four 14B models within 80 GB of GPU memory.
Introduction
The demand for real-time, minute-scale video generation is critical for interactive applications like game engines, yet existing models struggle to balance speed, duration, and quality. Prior approaches often rely on small 1.3B models that lack the capacity for complex motion or depend on costly techniques like self-forcing and KV-cache to prevent temporal drifting and accelerate inference. The authors introduce Helios, a 14B autoregressive diffusion model that achieves 19.5 FPS on a single H100 GPU while supporting long-video generation without standard acceleration or anti-drifting heuristics. They address these challenges by explicitly simulating drifting during training to eliminate motion artifacts, compressing historical context to reduce computational load, and unifying text-to-video, image-to-video, and video-to-video tasks within a single efficient architecture.
Method
The authors propose Helios, an autoregressive video diffusion transformer designed to enable real-time long-video generation on a single GPU. The overall framework is depicted in the architecture diagram. The model treats long-video generation as a video continuation task by concatenating a historical context XHist and a noisy context XNoisy. This design facilitates Representation Control, allowing the system to unify Text-to-Video (T2V), Image-to-Video (I2V), and Video-to-Video (V2V) tasks. If the historical context is zero, the model performs T2V; if only the last frame is non-zero, it performs I2V; otherwise, it performs V2V. To handle the different statistics of the historical and noisy contexts, the authors introduce Guidance Attention within the DiT blocks. This mechanism explicitly separates the treatment of clean history and noisy future frames. In the self-attention layer, historical keys are modulated by amplification tokens to selectively strengthen their influence on the generation of future frames. In the cross-attention layer, semantic information from the text prompt is injected only into the noisy context to avoid redundancy, as the historical context has already incorporated these semantics.
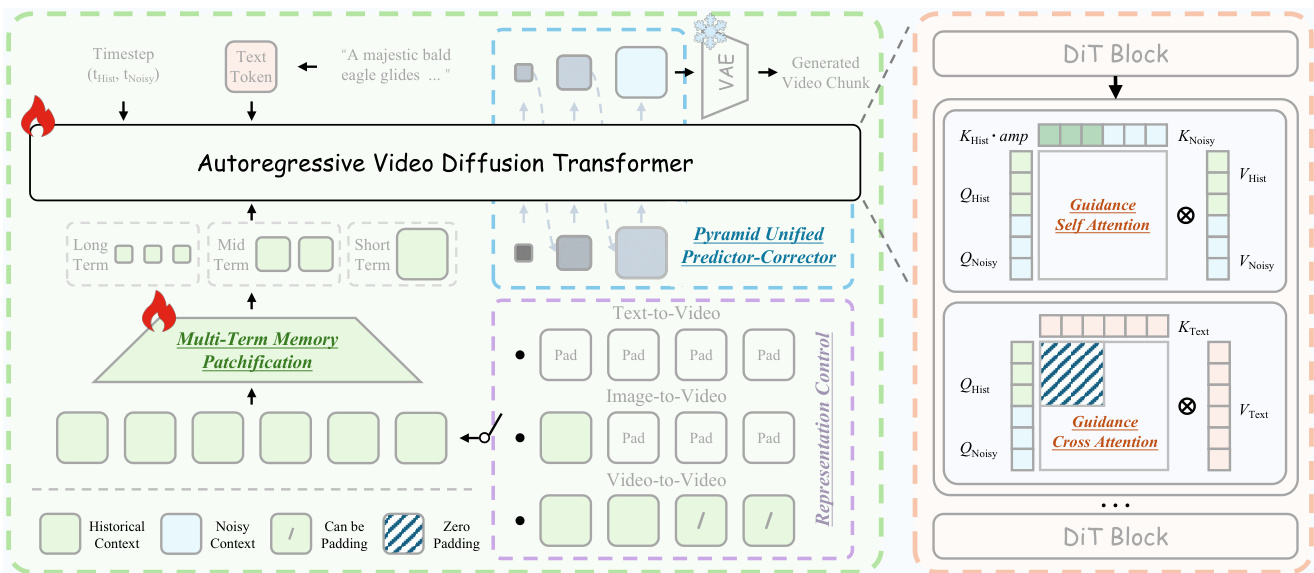
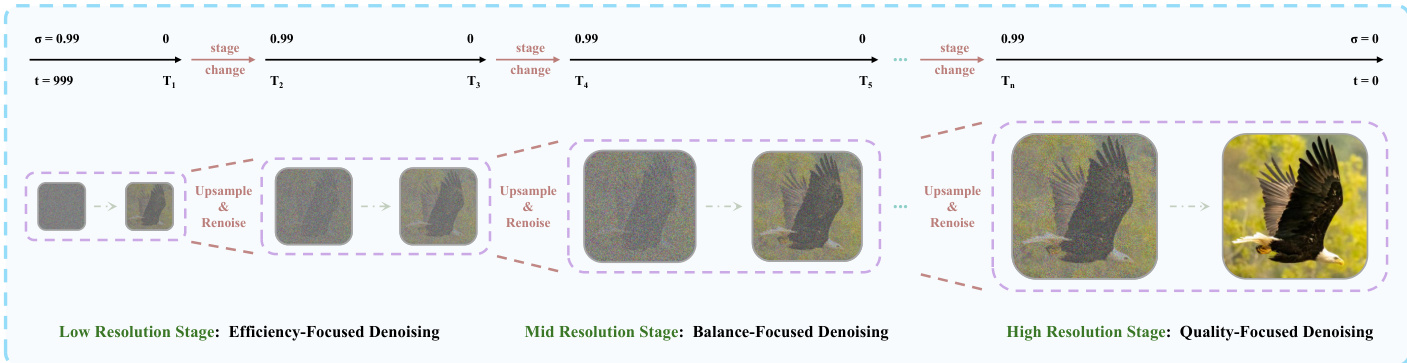
To reduce the computational overhead associated with large context windows, the authors employ Deep Compression Flow. This strategy involves two primary modules. First, Multi-Term Memory Patchification compresses the historical context by partitioning it into short, mid, and long-term windows. Independent convolution kernels are applied to each part, with the compression ratio increasing for temporally distant frames to maintain a constant token budget regardless of video length. Second, the Pyramid Unified Predictor Corrector reduces redundancy in the noisy context. As shown in the figure below, the generation process is divided into multiple stages with increasing spatial resolutions. The model begins with low-resolution denoising to efficiently establish global structure and progressively transitions to full resolution to refine fine-grained details. This coarse-to-fine schedule significantly reduces the number of processed tokens during the early sampling steps.
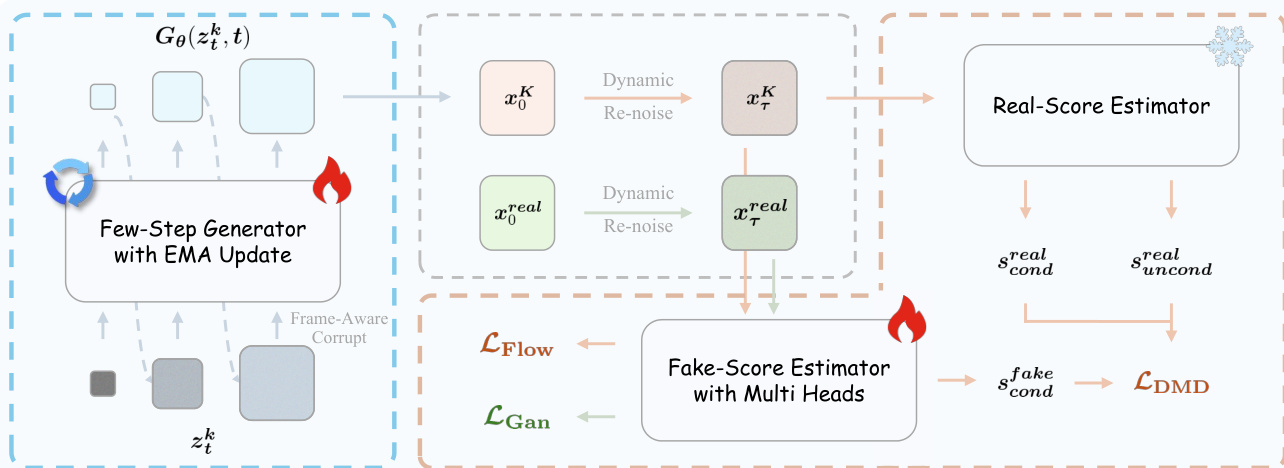
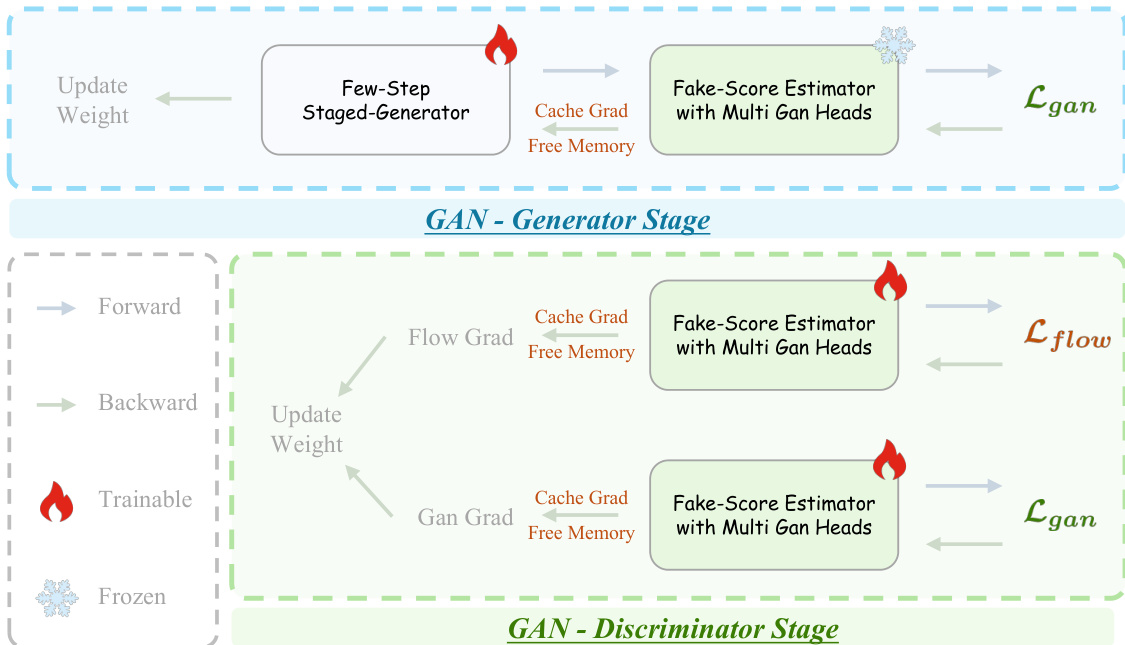
The training process utilizes Adversarial Hierarchical Distillation to distill a multi-step teacher model into a few-step student generator. The pipeline is illustrated in the distillation framework diagram. The system employs a Few-Step Generator with EMA Update and two score estimators: a Real-Score Estimator and a Fake-Score Estimator with Multi Heads. The generator is optimized using a distribution-matching loss (LDMD) derived from the difference between real and fake scores, alongside a flow-matching loss (LFlow) and a GAN loss (LGan). To address the memory constraints of training large models, the authors implement specific optimization strategies during the GAN stages. The training stages are detailed in the memory optimization diagram, which highlights the use of Cache Grad. By caching the discriminator gradients with respect to inputs, the system decouples backpropagation from the forward pass, allowing intermediate activations to be freed early. This approach substantially reduces peak memory usage, enabling the training of 14B parameter models on limited hardware.
Experiment
- Helios generates high-quality, coherent minute-scale videos without relying on common anti-drifting strategies or standard acceleration techniques, achieving real-time inference speeds on a single GPU.
- Comparative experiments demonstrate that Helios outperforms existing distilled and base models in visual fidelity, text alignment, and naturalness while maintaining superior motion smoothness and avoiding temporal jitter.
- Long-video evaluations confirm that Helios significantly reduces content drifting and preserves scene identity over hundreds of frames, surpassing baseline methods in both throughput and consistency.
- User studies validate that Helios is consistently preferred over prior real-time video generation models for both short and long-duration clips.
- Ablation studies reveal that key components such as Guidance Attention, First Frame Anchor, and Frame-Aware Corrupt are essential for preventing semantic accumulation, maintaining color consistency, and mitigating error propagation in long sequences.
- Architectural choices like Multi-Term Memory Patchification and Pyramid Unified Predictor Corrector enable scalable memory usage and doubled throughput without compromising video quality.
- Training strategies including Coarse-to-Fine Learning and Adversarial Post-Training are critical for stable convergence and enhancing perceptual realism beyond the limits of pure distillation.