Command Palette
Search for a command to run...
التخمين التخميني للديكودينغ
التخمين التخميني للديكودينغ
Tanishq Kumar Tri Dao Avner May
الملخص
تُواجه عملية فك التشفير الذاتي الانحداري (Autoregressive Decoding) عنق زجاجة ناتج عن طبيعتها المتسلسلة. وقد أصبح فك التشفير التخميني (Speculative Decoding) طريقةً قياسيةً لتسريع عملية الاستدلال (Inference) من خلال استخدام نموذج مسود سريع (Draft Model) للتنبؤ بالرموز (Tokens) القادمة من نموذج الهدف الأبطأ (Target Model)، ثم التحقق من هذه الرموز بشكل متوازي خلال تمرير واحد للأمام (Forward Pass) للنموذج الهدف. ومع ذلك، لا يزال فك التشفير التخميني نفسه يعتمد على اعتمادية متسلسلة بين عمليتي التخمين والتحقق. ولتجاوز هذا القيد، نقدم خوارزمية "فك التشفير التخميني المزدوج" (Speculative Speculative Decoding - SSD) من أجل الموازاة بين هذين العمليات. فعندما جارية عملية التحقق، يقوم نموذج المسود بالتنبؤ بالنتائج المرجحة للتحقق وإعداد تكهنات استباقية لها. وإذا كانت النتيجة الفعلية للتحقق ضمن مجموعة النتائج المتوقعة، يمكن إرجاع التخمين على الفور، مما يلغي تماماً أي عبء مرتبط بمرحلة المسودة. وقد حددنا ثلاثة تحديات رئيسية تطرحها خوارزمية فك التشفير التخميني المزدوج، واقتarnos طرقاً منهجية لحل كل منها. وقد أسفرت هذه الجهود عن تطوير خوارزمية SSD المحسّنة المسماة "ساغوارو" (Saguaro). وتُظهر تنفيذاتنا أن الخوارزمية أسرع بضعفين من الخوارزميات الأساسية لفك التشفير التخميني المحسّنة، وأسرع بخمسة أضعاف من فك التشفير الذاتي الانحداري عند استخدام محركات الاستدلال مفتوحة المصدر.
One-sentence Summary
Researchers from Stanford, Princeton, and Together AI propose SAGUARO, a speculative speculative decoding method that preempts verification outcomes to eliminate drafting overhead, achieving up to 2x speedup over prior speculative decoding and 5x over autoregressive decoding in open-source inference.
Key Contributions
- Speculative speculative decoding (SSD) breaks the sequential dependency in standard speculative decoding by pre-speculating for multiple possible verification outcomes while verification is still ongoing, enabling immediate token return if predictions match actual outcomes.
- The authors identify three key challenges in SSD design and propose SAGUARO, an optimized algorithm that scales speculation compute without increasing verifier workload, preserving correctness while enabling asynchronous operation.
- Evaluated across open-source inference engines, SAGUARO achieves up to 2x speedup over optimized speculative decoding baselines and up to 5x over autoregressive decoding, with demonstrated gains in both latency and throughput.
Introduction
The authors leverage speculative decoding to accelerate large language model inference by using a fast draft model to predict multiple tokens ahead, then verifying them in parallel with the target model. However, existing methods remain bottlenecked by sequential dependence: verification must finish before the next speculation can begin. Their main contribution is speculative speculative decoding (SSD), a framework that parallelizes drafting and verification by pre-speculating for multiple possible verification outcomes, eliminating this sequential constraint. SSD achieves up to 2x speedup over prior speculative decoding and 5x over autoregressive generation, while maintaining compatibility with advanced draft models and tree-based speculation techniques.
Method
The authors leverage speculative speculative decoding (SSD) to break the sequential dependency between drafting and verification inherent in traditional speculative decoding. In SSD, while the target model is verifying a current speculation, the draft model runs asynchronously on a separate device to predict likely verification outcomes—defined by the number of accepted tokens and the sampled bonus token—and pre-speculates token sequences for each of these outcomes in parallel. If the actual verification outcome matches one of the precomputed outcomes, the corresponding speculation is returned immediately, eliminating the need for on-the-fly drafting and reducing latency. This framework is lossless and requires the draft model to reside on distinct hardware from the target, enabling true overlap of speculation and verification.
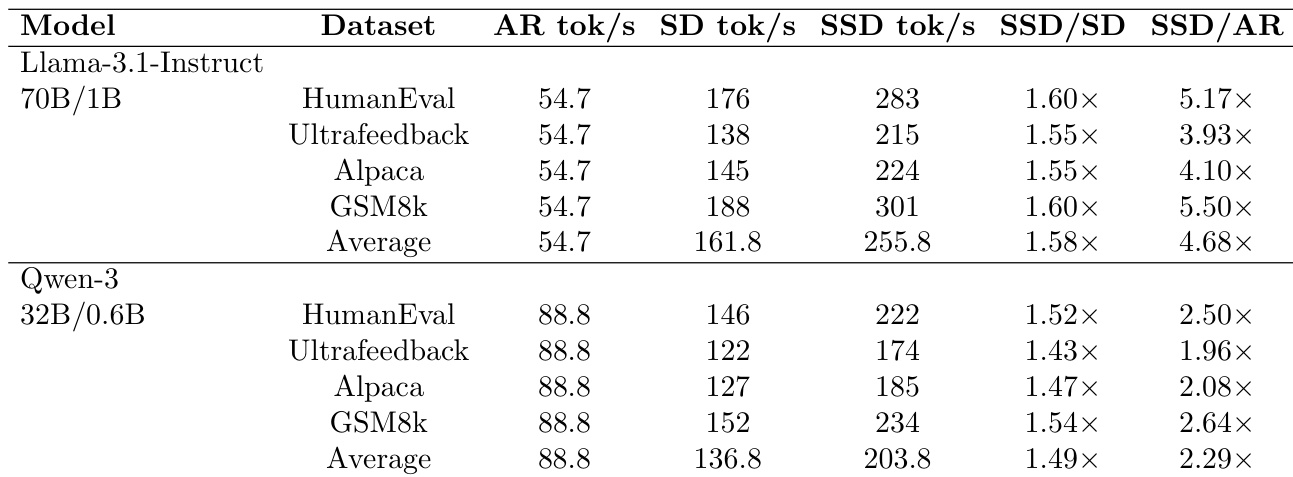
As shown in the figure below, the SSD workflow diverges from ordinary speculative decoding (SD) by decoupling the draft’s computation from the target’s verification timeline. While SD forces the draft to idle during verification, SSD allows the draft to precompute multiple speculative branches concurrently. The figure also illustrates the end-to-end performance gains: SSD achieves up to 4.0x throughput over autoregressive decoding and 2.6x over SD on Llama-3.1-70B, demonstrating the efficacy of parallelizing speculation with verification.
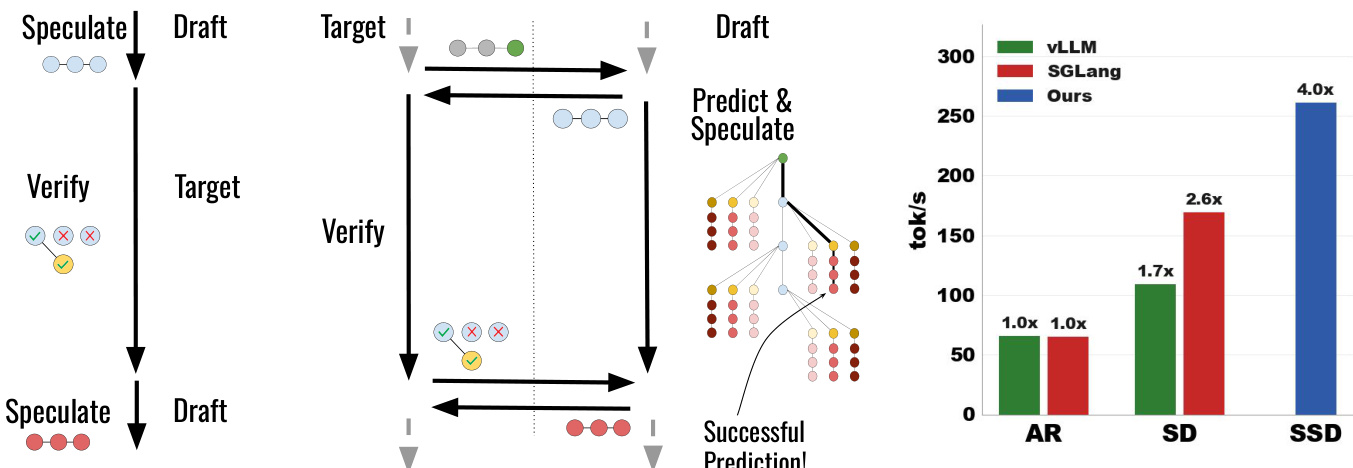
To implement this, the authors introduce SAGUARO, an optimized SSD algorithm that addresses three core challenges: predicting verification outcomes accurately, balancing cache hit rate against speculation quality, and handling cache misses efficiently. The speculation cache, a key component, maps each possible verification outcome vT=(k,t∗) to a precomputed speculation sT. During verification of round T, the draft model predicts a set of likely outcomes VT and speculates for each in parallel, storing results in the cache. Upon receiving the actual outcome, the system performs a cache lookup: if the outcome is present, the precomputed tokens are returned; otherwise, a fallback strategy is invoked.
The cache construction is guided by a geometric fan-out strategy derived from Theorem 12. Given a computational budget B, the algorithm allocates fan-out values Fk across sequence positions k∈[0,K] to maximize the probability of a cache hit. The optimal allocation follows a geometric series: Fk=F0⋅apk/(1+r) for k<K, and FK=F0⋅apK/(1+r)⋅(1−ap)−1/(1+r), where ap is the draft’s acceptance rate and r is the power-law exponent of the cache hit rate. This allocation reflects the intuition that longer verification outcomes are less likely and should receive fewer speculative resources. The figure below visualizes this strategy: for a speculation being verified at position k=2, the draft prepares F2=3 speculative branches for possible bonus tokens, while allocating only F0=1 for the case where no tokens are accepted.
To improve cache hit rates, SAGUARO introduces a novel sampling scheme that biases the draft distribution to increase residual probability mass on cached tokens. The Saguaro sampling scheme σF,C(z) downweights the top-F draft logits by a factor C∈[0,1], making the residual distribution r(⋅)∝max(ptarget(⋅)−pdraft(⋅),0) more concentrated on those tokens. This increases the likelihood that the bonus token falls within the cache, at the cost of potentially reducing the acceptance rate. The trade-off is managed via the hyperparameter C, which can be tuned to balance hit rate and acceptance.
For cache misses, SAGUARO employs a batch-size-aware fallback strategy. At small batch sizes, it uses the same high-quality draft model as the primary speculator. At larger batch sizes, where cache misses become frequent and stall the entire batch, it switches to a low-latency backup speculator to minimize latency. The critical batch size b∗ is derived analytically to maximize end-to-end speedup.
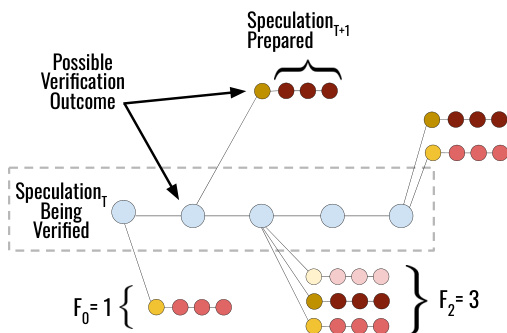
The system implementation runs the target model across 4 H100 GPUs and the draft model on a separate H100. Communication occurs once per round via NCCL, exchanging only the verification outcome (accepted token count and bonus token) and receiving precomputed speculations or fallback results. To enable parallel decoding of all B(K+1)F speculative branches, the draft uses a custom sparse attention mask. As shown in the figure below, this mask allows each branch to attend to the verified prefix (via the “Prefix Mask” block) and its own forking path (via “Tree Decode Diagonals”), while “Glue & Recurrence” ensures the branches share the same prefix context. This design enables efficient multi-query decoding but introduces memory access overhead that limits the practical lookahead K.
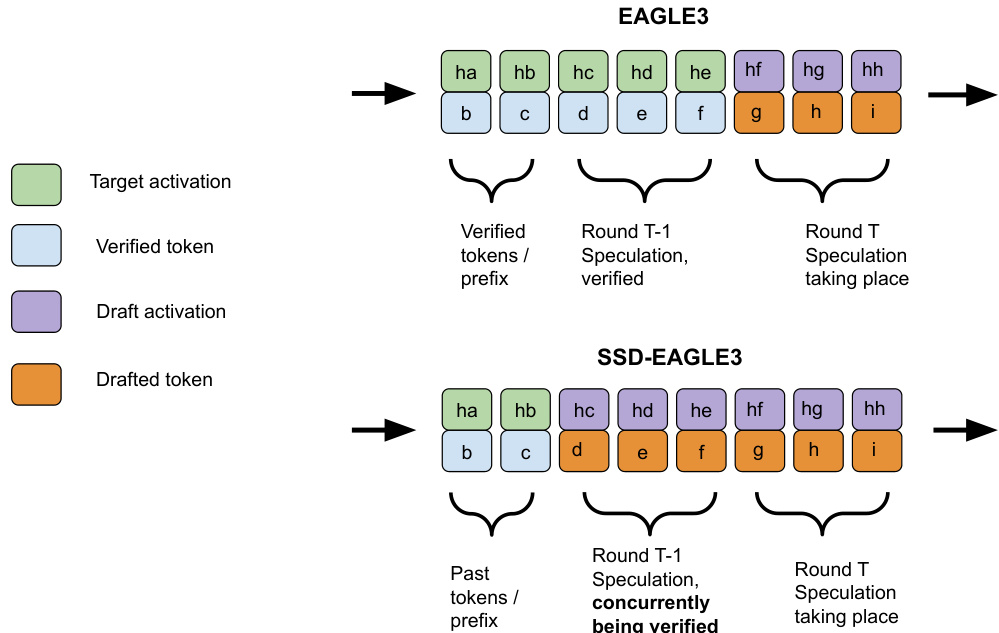
Finally, SAGUARO is compatible with advanced speculative decoding variants. For example, when combined with EAGLE-3, which conditions the draft on target activations, SSD-EAGLE-3 must substitute draft activations for unavailable target activations during pre-speculation. The figure below contrasts the two: in standard EAGLE-3, the draft conditions on verified target activations; in SSD-EAGLE-3, it conditions on its own activations for the latter half of the speculation, which may degrade quality unless the draft is trained to handle self-conditioning.
Experiment
- SAGUARO outperforms autoregressive decoding and standard speculative decoding, achieving up to 5x speedup and pushing the latency-throughput Pareto frontier, especially at low batch sizes.
- Theoretical analysis confirms SAGUARO’s speedup depends on cache hit rate, drafting efficiency, and latency hiding, with strict gains over standard speculative decoding under identical speculators.
- Geometric fan-out improves cache hit rates and decoding speed over uniform strategies, particularly at higher temperatures, with hit rates scaling predictably with cache size.
- SAGUARO sampling enables tunable trade-offs between cache hit rate and speculative acceptance by reshaping the draft distribution to favor cached tokens.
- Fast random backup speculators outperform slower neural ones at larger batch sizes, while scaling draft compute (via more GPUs) further boosts speed by expanding cache capacity.
- Results generalize across model families (Llama-3 and Qwen-3), confirming the method’s robustness across architectures and datasets.
The authors evaluate SAGUARO against autoregressive and speculative decoding baselines across multiple models and datasets, showing consistent speedups. Results show SAGUARO achieves 1.5x to 5.5x faster decoding than speculative decoding and up to 5x faster than autoregressive decoding, with gains varying by model size and dataset. The method proves effective across different model families, confirming its generalizability.