Command Palette
Search for a command to run...
التعلم التعزيزي الموجه بالهندسة لتحرير المشاهد ثلاثية الأبعاد بتناسق متعدد المنظورات
التعلم التعزيزي الموجه بالهندسة لتحرير المشاهد ثلاثية الأبعاد بتناسق متعدد المنظورات
الملخص
أصبح استغلال المسبقات (priors) لنماذج الانتشار ثنائية الأبعاد (2D diffusion models) في تحرير المحتوى ثلاثي الأبعاد (3D editing) نموذجًا واعدًا. غير أن الحفاظ على اتساق وجهات النظر المتعددة في النتائج المحررة لا يزال تحديًا كبيرًا، كما أن الندرة الشديدة لبيانات التدريب المزدوجة المتوافقة مع البعد الثالث تجعل الضبط الدقيق الخاضع للإشراف (SFT) — وهو أكثر استراتيجيات التدريب فعالية لمهام التحرير — غير قابل للتطبيق. في هذه الورقة، نلاحظ أنه بينما يُعد توليد محتوى ثلاثي الأبعاد متسقًا عبر وجهات نظر متعددة أمرًا بالغ الصعوبة، فإن التحقق من اتساق البعد الثالث أمر قابل للحل، مما يضع تعلم التعزيز (RL) كحل عملي بشكل طبيعي. استنادًا إلى هذه الملاحظة، نقترح إطار عمل RL3DEdit، وهو إطار من خطوة واحدة يقوده التحسين القائم على تعلم التعزيز، مع جوائز مبتكرة مُشتقة من النموذج الأساسي ثلاثي الأبعاد VGGT. تحديدًا، نستفيد من المسبقات القوية التي تعلمها نموذج VGGT من كميات هائلة من البيانات الواقعية، ثم نغذي الصور المحررة به، ونستخدم خرائط الثقة ومقدار أخطاء تقدير الوضعية (pose estimation errors) الناتجة كإشارات جوائز، مما يرسو بفعالية مسبقات التحرير ثنائية الأبعاد على متعدد شعب (manifold) متسق ثلاثي الأبعاد عبر تعلم التعزيز. تُظهر التجارب المكثفة أن RL3DEdit يحقق اتساقًا مستقرًا عبر وجهات نظر متعددة، ويتفوق على أحدث الأساليب من حيث جودة التحرير مع كفاءة عالية. ولتعزيز تطور تحرير المحتوى ثلاثي الأبعاد، سنقوم بإصدار الكود البرمجي والنموذج.
One-sentence Summary
Researchers from BJTU, AMap Alibaba Group, NTU, and CQUPT propose RL3DEdit, a single-pass 3D editing framework that leverages reinforcement learning with VGGT-derived rewards to ensure multi-view consistency, overcoming data scarcity and outperforming iterative methods in both quality and efficiency for AR and gaming applications.
Key Contributions
- Current 3D editing methods struggle with multi-view consistency and cannot utilize supervised fine-tuning due to the extreme scarcity of 3D-consistent paired data.
- The proposed RL3DEdit framework leverages the 3D foundation model VGGT to generate novel reward signals from confidence maps and pose errors, enabling RL optimization that anchors 2D editing priors onto a 3D-consistent manifold without requiring paired datasets.
- Extensive experiments demonstrate that this single-pass approach achieves state-of-the-art editing quality and stable multi-view consistency while operating more than twice as fast as previous iterative optimization methods.
Introduction
3D scene editing is critical for AR/VR and gaming applications, yet current methods struggle to maintain geometric coherence while leveraging powerful 2D diffusion models. Prior approaches suffer from inefficiency due to iterative optimization, produce blurry artifacts from inconsistent signals, or fail to handle edits that alter scene geometry because they rely on depth maps or attention propagation. The authors address these challenges by introducing RL3DEdit, a single-pass framework that uses reinforcement learning to optimize 2D editors for 3D consistency without requiring scarce paired training data. They leverage the 3D foundation model VGGT as a robust verifier to generate geometry-aware reward signals, effectively anchoring 2D editing priors onto a 3D-consistent manifold while achieving state-of-the-art quality and over twice the speed of existing methods.
Method
The authors propose RL3DEdit, a framework that leverages Reinforcement Learning to equip a 2D foundation model with 3D-consistency priors. The overall architecture is illustrated in the framework diagram. Given a 3D asset, the system first renders it from M viewpoints to obtain a set of images {Im}m=1M. These images are fed simultaneously into a 2D editor, denoted as π, for joint multi-view editing. During inference, the fine-tuned editor produces multi-view consistent images in a single forward pass, which are subsequently processed by 3D Gaussian Splatting (3DGS) reconstruction to yield the final edited 3D scene.
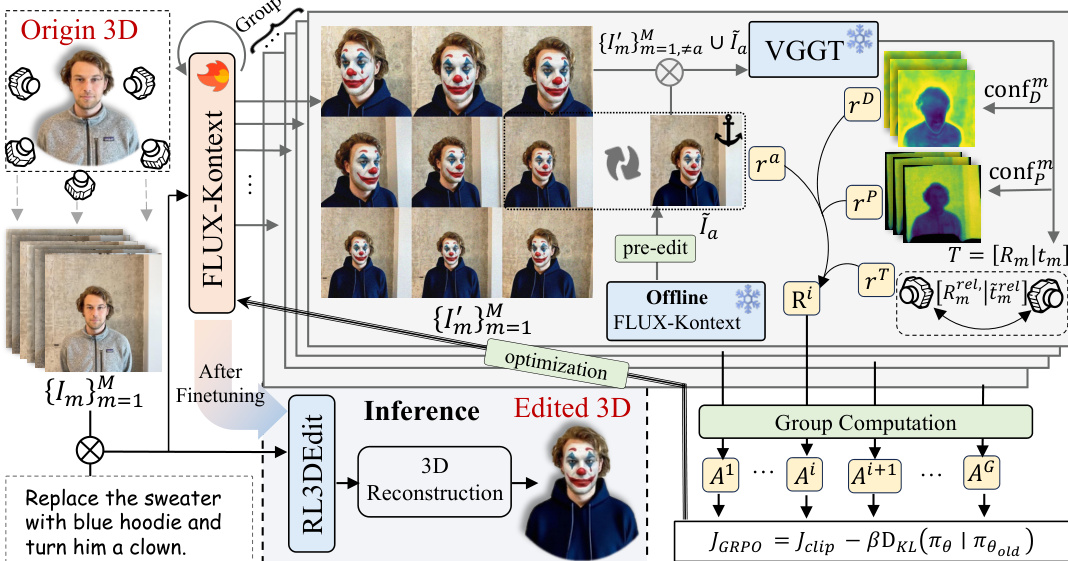
To address the core challenge of ensuring 3D consistency without paired supervision, the authors employ the Group Relative Policy Optimization (GRPO) algorithm. During training, the system explores a group of G edited results through independent inference passes. A dedicated 3D-aware reward model, implemented via VGGT, is utilized to explicitly enforce both editing faithfulness and multi-view coherence. This model jointly assesses three critical aspects of multi-view consistency, represented as depth confidence rD, point confidence rP, and relative pose reward rT, alongside an editing quality term ra. These complementary rewards are combined to form the final composite reward Ri, which guides the optimization toward consistent and high-quality 3D-aware editing.
The choice of the 2D backbone is critical for enabling cross-view interaction. The authors adopt FLUX-Kontext, a DiT-based model that naturally supports multi-image joint editing through global attention mechanisms. This capability allows the model to process all input views as a concatenated sequence, facilitating the necessary cross-view interactions for 3D consistency. The versatility of this approach is demonstrated by the diverse editing capabilities shown in the qualitative results, which include motion, replacement, style transfer, background modification, and object addition.

A key component of the training process is the anchor reward, designed to preserve the original 2D editing fidelity of the foundation model. By comparing the edited anchor view against a pre-computed high-quality 2D edit, the model ensures that semantic correctness and visual details are maintained while learning 3D priors. As illustrated in the comparison of editing capabilities, the RL fine-tuned model successfully preserves the original 2D editing fidelity of the base model, as evidenced by the comparable VIE Score metrics.

Finally, the relative advantage Ai is computed from the group rewards, and the model is optimized by maximizing the following objective:
J(θ)=Jclip(θ)−βDKL(πθ∣∣πref)where πθ and πref denote the fine-tuned and original 2D editors, respectively. This formulation allows the model to learn 3D-consistency priors effectively without requiring curated paired data.
Experiment
- Comparative experiments against state-of-the-art 3D editing methods demonstrate that the proposed approach achieves superior instruction following, visual fidelity, and multi-view consistency while significantly reducing editing time.
- Qualitative analysis reveals that the method successfully handles complex geometric transformations, motion edits, and style changes where baseline models fail due to artifacts, ghosting, or semantic misinterpretation.
- Ablation studies confirm that depth and point confidence rewards are essential for preventing ghosting artifacts and maintaining 3D consistency, while text-based rewards ensure accurate viewpoint alignment.
- Experiments comparing consistency verifiers show that traditional metrics like Structure-from-Motion and photometric reprojection loss lead to textureless or blurred outputs, validating the necessity of using data-driven priors for reward signals.
- Additional tests verify that the framework generalizes effectively to unseen instructions and scenes in a zero-shot setting and can be enhanced by integrating more powerful 2D editing backbones.